一、FlashAttention
1、Tile-Based计算
将q,k,v分块为小块,每次仅处理一小块:
- 利用gpu的片上SRAM完成QK^T和softmax
- 避免中间结果写入HBM
标准attention的计算算法如下:

标准attention实现大量中间结果需要频繁访问HBM,而HBM的访问速度远远低于GPU的SRAM。因此FlashAttention通过"tile计算+显存访问优化"方案,减少了对HBM的依赖,提高了整体执行效率。
softmax计算公式如下:
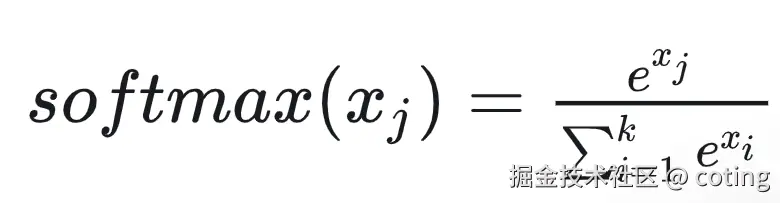
为了数值稳定性,FlashAttention采用Safe Softmax,对于向量x
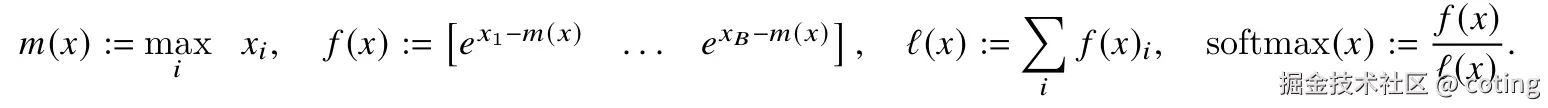
同理,对于向量x=x1,x2,softmax可以分解计算:
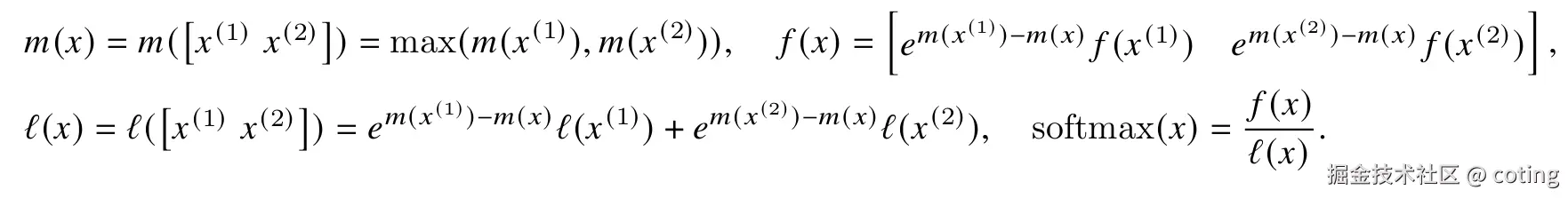
这就说明即使q,k,v被分成块也可以计算softmax的。
2、Recomputation strategy
为了节省存储中间的softmax权重,FlashAttention在需要时重新计算部分内容,避免保存完整矩阵。
标准attention的反向传播算法如下,其中P代表softmax(QKTdk)softmax(\frac{QK^T}{\sqrt{d_k}})softmax(dk QKT),即注意力权重矩阵。
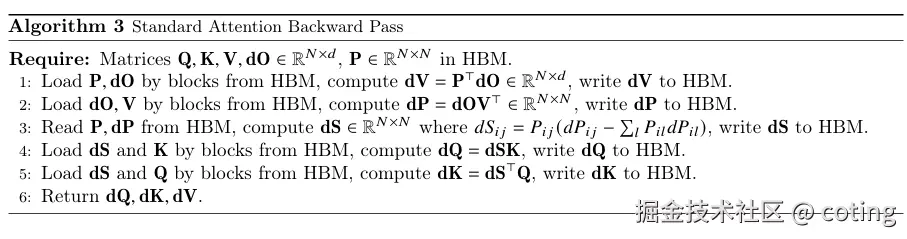
在标准attention的实现中,为了完成前向传播和反向传播,需要保存如下中间结果:
- QKTQK^TQKT
- softmax权重
- attention output(最终结果)
这些矩阵很大,尤其是在处理长序列时,显存消耗会非常高。
FlashAttention为了降低显存占用,采取了一种策略:
在前向传播时不保留中间矩阵,而是到了反向传播阶段再把它们重新计算出来。
以softmax的attention score为例:
- 标准方法
QKTQK^TQKT -> softmax -> 换存在显存中 ->用于乘v和反向传播
- FlashAttention
QKTQK^TQKT -> softmax -> 直接用于乘V,不缓存
...
后面反向传播要用到softmax->再计算一次QKTQK^TQKT和softmax
3、代码
python
for i in range(0, N, block_size): #外层循环:按block_size步长遍历所有token(处理query的分块)
q_block = q[:, i:i+block_size] #取出当前query块[batch_size, block_size,dim]
max_score = None #初始化当前query块的最大注意力分数(用于数值稳定)
row_sum_exp = None #初始化当前query块的指数和(用于softmax分母)
acc = torch.zeros_like(q_block) #初始化累积结果张量
for j in range(0, N, block_size): #内层循环:遍历所有k/v的分块
k_block = k[:, j:j+block_size]
v_block = v[:, j:j+block_size]
# 1.计算原始注意力分数
scores = torch.bmm(q_block, k_block.transpose(1,2)) * scale #[batch, block_size, block_size]
#bmm表示批量矩阵乘法,scale是缩放因子(通常为1/sqrt(dim))
# 2.数值稳定处理(减去最大值后做指数计算)
block_max = scores.max(dim=-1, keep_dims=True).values #当前块每行的最大值 [batch, block_size, 1]
scores = scores - block_max
exp_scores = socres.exp() #计算指数[batch, block_size, block_size]
# 3.可选dropout
if dropout_p > 0.0:
exp_scores = F.dropout(exp_scores, p=dropout_p,training=True)
# 4.累积加权和(注意力权重 x value)
acc += torch.bmm(exp_scores,v_block)
# 5.维护softmax分母(log-sum-exp技巧)
block_sum = exp_scores.sum(dim=-1,keep_dims=True) #当前块的指数和 [batch, block_size, 1]
if row_sum_exp is None: #第一次处理该query块时
row_sum_exp = block_sum #直接保存
max_score = block_max #保存当前最大值
else:
row_sum_exp += block_sum
max_socre = torch.max(max_socre, block_max)
output[:, i:i+block_size] = acc / (row_sum_exp + 1e-6)
return output4、总结
(1)FlashAttention的关键设计
- 将q/k/v分成小块,在SRAM中进行attention的计算
- 在计算softmax的过程中使用log-sum-exp技巧,确保数值稳定
- 将softmax后与V的乘法也集成进tile内的计算流程,避免生成大矩阵
- 利用recompilation:不存储softmax权重P,而是在反向传播时重算QKTQK^TQKT,换取显存节省。
(2)FlashAttention的不足
- 线程并行效率不高:使用的是"1warp对应1Q行"的划分方式,warp内线程空闲率高
【注:
在gpu并行计算中,warp是NVIDIA GPU的基本执行单位,通常由32个线程组成。这些线程在gpu上以SIMT(single instruction, multiple threads)方式执行,即所有线程在同一时刻执行相同指令,但可以处理不同的数据。
FlashAttention中的"1 warp对应1Q行"问题是指每个warp负责计算1行Q的注意力分数。但由于Q的行维度(seq_len)通常远小于32,导致:
-
线程利用率低:32个线程中,只有少数线程真正在计算,其余线程空闲
-
并行效率不高:gpu的SIMT架构要求所有线程执行相同指令,但部分线程没有实际工作,造成浪费。
】
- split-K导致频繁HBM读写:每次分块操作都要访问Q和O,存在冗余累加
- 不支持MQA/GQA等高效注意力结构:仅适用于标准MHA
- 实现依赖Triton编译器:对部属平台要求高,难以在pytorch,tensorflow等框架中原生集成
- 反向传播内核较少优化:精度和性能兼顾方面还有改进空间。