@TOC(手搓一个STL风格的vector容器)
手搓一个STL风格的vector容器
github地址
0. 前言:动态数组的工程实践
在C++标准库中,vector容器作为最核心的序列式容器,其设计融合了动态数组的高效性与安全性。本文将通过完整实现一个简化版vector容器,重点剖析迭代器失效、深拷贝控制、动态扩容等关键问题。代码实现将保持与STL兼容的接口设计。
有了之前实现string的经验,我们实现vector也就相对容易了。
1. 基础架构设计
1.1 成员变量与迭代器
- 为了和标准库中的
vector区分,我们把自己实现的vector封装在m_vector这个命名空间中 vector的底层是就是顺序表,采用顺序表的结构来实现即可,重点掌握和STL中的顺序表普通的顺序表的实现有哪些不同- 基本结构如下:

cpp
namespace m_vector {
template<class T>
class vector {
public:
//将原生指针封装为迭代器
typedef T* iterator;
typedef const T* const_iterator;
//迭代器与const对象迭代器
iterator begin() { return _start; }
const_iterator begin() const { return _start; }
iterator end() { return _finish; }
const_iterator end() const { return _finish; }
public:
// ... 一系列成员函数实现
private:
//与标准库STL中的命名风格保持一致
iterator _start; // 指向数组首元素
iterator _finish; // 指向最后一个元素的下一个位置
iterator _end_of_storage; // 指向存储空间末尾
};
}设计要点:
-
三指针架构 是
STL vector的经典实现,结合上图理解三指针架构:_start:数据起始位置_finish:有效数据结束标记_end_of_storage:容量边界标记
-
原生指针实现迭代器,保持与
STL兼容typedef T* iterator,typedef const T* const_iteratorbegin()返回_start,分别实现普通对象版本 和const对象版本end()返回_finish,分别实现普通对象版本 和const对象版本
-
模板化设计支持任意元素类型
-
成员变量设为访问权限设为
private, 对外提供public的成员函数和定义的类型,符合面向对象中封装的思想
1.2 容量获取
c++
// 指针 - 指针 得到中间的元素个数
size_t capacity() const {
return _end_of_storage - _start;
}
size_t size() const {
return _finish - _start;
}
bool empty() const {
return _start == _finish;
}-
指针 - 指针:可以实现返回两个指针中间的元素个数
_end_of_storage - _start:得到总容量个数_finish - _start:得到有效元素个数
-
==判空:==数据标记指针
_start == _finish时,表示顺序表中无数据
2. 构造与析构
2.1 默认构造与析构函数
cpp
//默认构造函数
//我们写的逻辑是 构造时暂不开空间
vector()
:_start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{ }
//析构函数
~vector() {
if (_start) {
delete[] _start;
_start = _finish = _end_of_storage = nullptr;
}
}默认构造函数
- 将指针都初始化为
nullptr - 默认构造(无需传参即可调用的构造函数),我们设计为空构造,不开辟空间
析构函数
-
_start不为空时再进行析构,即有数据时才进行析构 -
delete[] _start:清理连续的数组空间。- 若数组内为内置类型,直接清理空间
- 若数组内为自定义类型 ,
delete[]会依次调用数组内每个对象的析构函数
-
_start = _finish = _end_of_storage = nullptr:设置三指针为nullptr
2.2 深拷贝控制
这里的相较于string中的深拷贝,有着更高的要求:string中存放的是内置类型char,而vector中内置类型和自定义类型都可能存放
- 首先需要保证
vector之间互相拷贝时,vector对象本身的数据独立性 - 其次还要保证:当
vector中存放的数据是自定义类型 时,拷贝时也要为每个自定义类型实现深拷贝
- **写法1:**手动开空间,手动释放内存
cpp
// 拷贝构造函数
vector(const vector<T>& v)
: _start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{
_start = new T[v.capacity()];
//memcpy(_start, v._start, sizeof(T) * v.size()); // 不能使用memcpy,memcpy拷贝自定义类型时会出现错误
for (size_t i = 0; i < v.size(); ++i) {
_start[i] = v[i];
}
_finish = _start + v.size();
_end_of_storage = _start + v.capacity();
}-
初始化列表将待构造对象的指针初始化为
nullptr -
_start = new T[v.capacity()]:为该对象申请空间,new会为数组中的每个元素,调用类型T的默认构造函数 -
vector中既可能存放内置类型,也可能存放自定义类型,因此拷贝数据时应该实现深层次的深拷贝 。不能使用memcpy,因为memcpy进行的是值拷贝,也就是浅拷贝。浅拷贝会导致两个指针指向同一块空间,对象生命周期结束时,对同一块空间析构两次会导致报错cpp//memcpy(_start, v._start, sizeof(T) * v.size()); for (size_t i = 0; i < v.size(); ++i) { _start[i] = v[i]; // 用自定义类中的 = 重载实现深拷贝类型的拷贝 // 该写法也可以满足内置类型的拷贝的需求,内置类型本身就可以用=赋值 }- 这里使用
for循环依次赋值,调用了自定义类型的operator=来实现深拷贝。内置类型可以直接用=赋值,自定义类型的operator=应当实现深拷贝
- 这里使用
-
更新状态指针 :终地址等于起始地址 + 偏移量
_finish = _start + v.size():_finish的偏移量为已有对象的size()_end_of_storage = _start + v.capacity():_end_of_storage的偏移量为已有对象的capacity()
**写法2:**复用类中的其他函数
cpp
vector(const vector<T>& v)
:_start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{
reserve(v.capacity());
for (auto& e : v)
push_back(e);
}-
首先初始化列表,初始化当前对象为空
vector对象 -
调用
reserve开空间,同时将当前vector对象内成员变量存储的地址更新为有效地址 。reserve有两个作用:- 为数据开辟足够的空间
- 更新三指针指向非0地址,也就是有效地址
-
再将需要拷贝的数据依次尾插到当前对象中。
-
由于我们的
push_back的实现中采用的是**=赋值**,因此内置类型会直接值拷贝 ,自定义类型会调用其operator=函数,完成深拷贝。
2.3 用n个val构造和迭代器区间构造
n个val构造
cpp
// 用n个val构造 复用resize 时,三个指针应该初始化
vector(size_t n, const T& val = T())
:_start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr) // 成员变量给了缺省值时,可以不写初始化列表
{
resize(n, val);
}- 用
n个val初始化时,我们可以直接复用resize。但使用n个val初始化时,val是可以有默认值的,但如何确定参数的类型?
内置类型的默认构造函数:
resize初始化,val是可以有默认值(缺省参数)的,但如何确定缺省参数的类型?- 此时形参
T()本质是一个T类型的匿名对象 ,会调用T类型的默认构造 。因此写一个类,一定要提供默认构造 - 如果传入的是
int等内置类型resize怎么运行?理论上不能运行。但C++有了模板后,C++对内置类型进行了升级,也支持内置类型有默认构造函数
内置类型的默认构造函数使用示例:
- 内置类型的默认构造 :
int默认构造为0double默认构造为0.0- 指针类型 默认构造为
nullptr
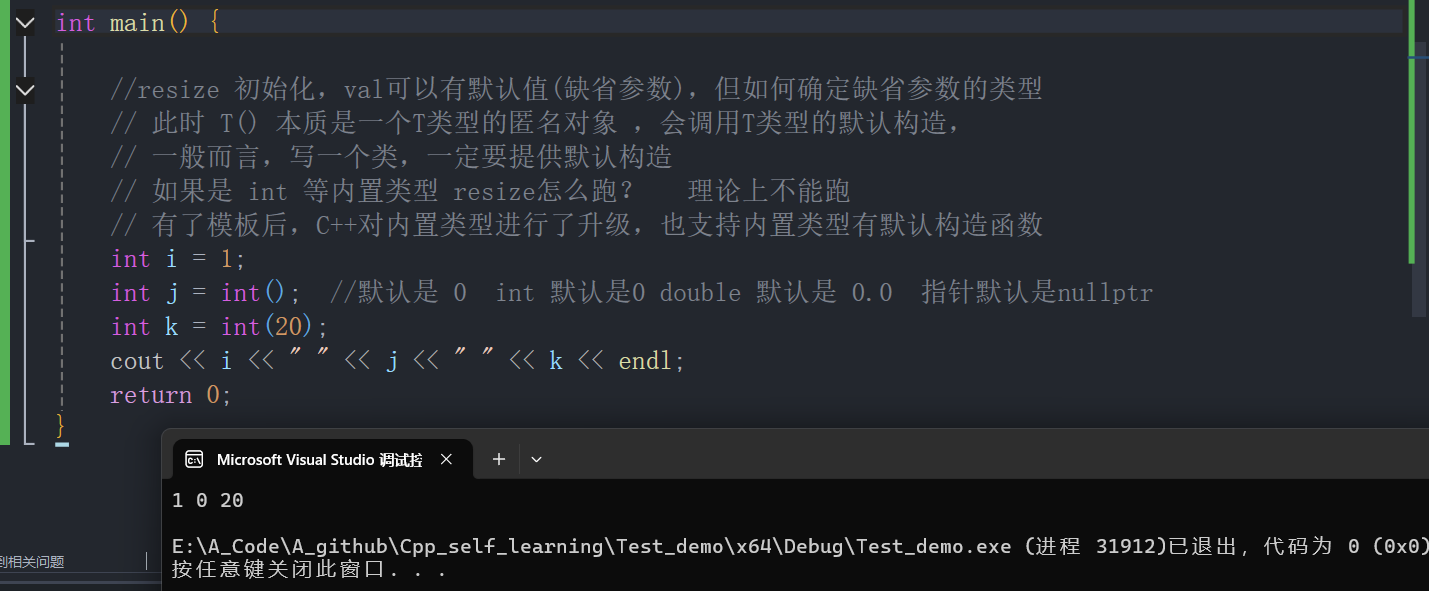
- 因此
T()匿名对象既可以满足内置类型,也可以满足自定义类型。
迭代器区间构造
- 用一个迭代器区间进行构造初始化
cpp
// 类模板内的成员函数,依然可以再是另一个模板函数
// [first, last]
template<typename InputIterator>
vector(InputIterator first, InputIterator last) {
while (first != last) {
push_back(*first); // vector<int> v(10, 1); 构造时匹配错误,匹配成了迭代器区间初始化
// 然后 int 不能解引用,因此报错
++first;
}
}-
我们的实现思路十分简单:
- 对所有支持迭代器的容器,将区间
[first, last)区间内的数据构造成为一个vector - 我们只需循环遍历区间,
push_back(*first)对每个地址的元素解引用后尾插入vector即可 。之后first指针再++
- 对所有支持迭代器的容器,将区间
-
但是当我们编译时,却发生了错误:
-
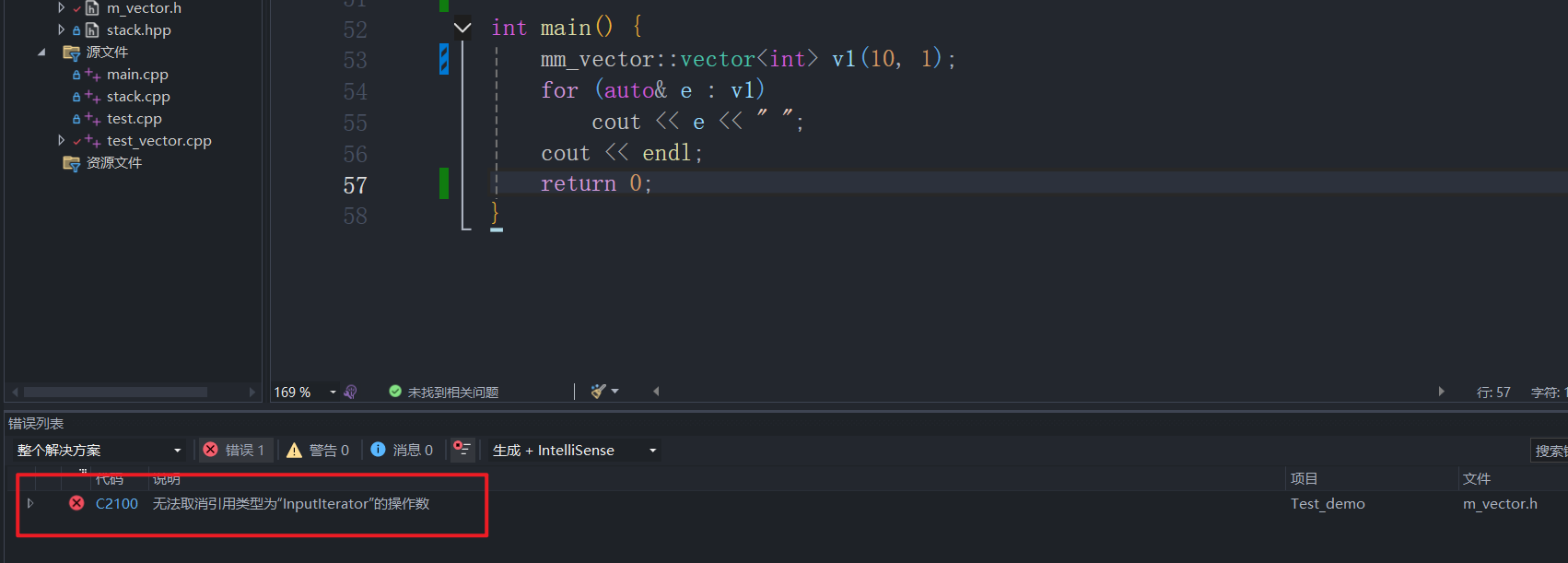
-
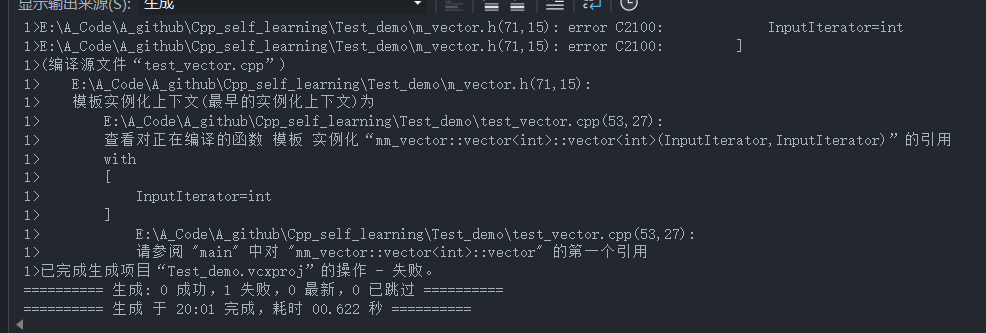
-
错误输出信息如上,我们阅读后,初步推断该报错信息与模板有关。可能是和模板的匹配有关!
-
观察我们的构造函数:
mm_vector::vector<int> v1(10, 1);参数类型为10, 1。10和1这样的字面量,在C++中默认是int。再看我们现有的构造函数:参数数量为2的构造函数只有以下两个:vector(size_t n, const T& val = T());类型为size_t, T,两参数类型不同- ``vector(InputIterator first, InputIterator last);
类型为T, T`,两参数类型想通
-
由于
v1(10, 1)两个参数的类型为int, int,类型相同,因此在模版函数匹配时,编译器自动匹配了类型更合适的T, T。而我们该构造函数的实现中,有*first行为,而int类型无法解引用,因此报错。 -
解决该问题,只需额外为
int, int类型提供一个构造函数,使int, int类型的调用不要匹配到迭代器区间初始化即可。
cpp
// mm_vector::vector<int> v(10, 1); int int 匹配 size_t int 还是 int int(T, T)
// 当然是 int int(T, T)
// mm_vector::vector<int> v1(10u, 1); unsigned int, int 匹配 size_t int 还是 int int。
// 当然是 size_t int
// mm_vector::vector<string> v2(10, "hello"); int char* 匹配 int T 更加合适
vector(size_t n, const T& val = T()) {
resize(n, val);
}
//多提供一个 int int 类型的构造
vector(int n, const T& val = T()) {
resize(n, val);
}
// 用一个迭代器区间进行初始化
// [first, last]
template<typename InputIterator>
vector(InputIterator first, InputIterator last) {
while (first != last) {
push_back(*first);
++first;
}
}- 多提供一个形参类型为
int int的构造后就不报错了
3. 容量管理
3.1 reserve扩容策略
- 我们的扩容策略是针对
capacity的,拷贝空间时,不仅拷贝[_start, _finish)之间的数据,同时拷贝[_start, _end_of_storage)之间的所有空间
cpp
void reserve(size_t newCapacity) {
if (newCapacity > capacity()) {
T* newSpace = new T[newCapacity];
size_t old_sz = size(); // 记录 _finish 相对于 _start 的偏移量
// 拷贝数据
if (_start) {
//memcpy(newSpace, _start, sizeof(T) * old_sz);
for (size_t i = 0; i < old_sz; ++i) {
newSpace[i] = _start[i]; // 用自定义类中的 = 重载实现深拷贝类型的拷贝
// 该写法也可以满足内置类型的拷贝的需求,内置类型本身就可以用=赋值
}
delete[] _start;
}
// 如果原vector无数据,但申请了更大的空间,该函数也会扩容并分配空间
_start = newSpace;
_finish = _start + old_sz;
_end_of_storage = _start + newCapacity;
}
}
// 不能用以下方法计算 _finsih, 只能通过记录偏移量的方式来计算 _finish
// _finish = _start + size(); // 该实现有问题,这样写_finish的值没变
// 上述表达式size() _start 指向新空间了,但此时_finish仍然指向旧空间思路分析与关键点:
-
异地扩容保证强异常安全
-
reserve扩容不是只给push_back用,使用需要检查是否需要扩容 -
newSpace记录新空间的起始地址。old_sz记录有效元素数量,可标识_finish相对于_start的位置,方便扩容后更新_finsih- 形参
newCapacity记录容量个数,可表示_end_of_storage相对于_start的位置,方便扩容后更新_end_of_storage
-
vector中既可能存放内置类型,也可能存放自定义类型,因此拷贝数据时应该实现深层次的深拷贝。不能使用memcpy,因为memcpy进行的是值拷贝,也就是浅拷贝cppfor (size_t i = 0; i < old_sz; ++i) { newSpace[i] = _start[i]; // 用自定义类中的 = 重载实现深拷贝类型的拷贝 // 该写法也可以满足内置类型的拷贝的需求,内置类型本身就可以用=赋值 }- 这里使用
for循环依次赋值,调用了自定义类型的operator=来实现深拷贝。内置类型可以直接用=赋值,自定义类型的operator=应当实现深拷贝
- 这里使用
-
delete[] _start释放旧空间 -
最终利用相对偏移量更新指针:
_start = newSpace;_finish = _start + old_sz;_end_of_storage = _start + newCapacity;
reserve中的其他关键实现:
cpp
void reserve(size_t newCapacity) {
if (newCapacity > capacity()) {
T* newSpace = new T[newCapacity];
size_t old_sz = size(); // 记录 _finish 相对于 _start 的偏移量
// 拷贝数据
if (_start) {
for (size_t i = 0; i < old_sz; ++i)
newSpace[i] = _start[i];
delete[] _start;
}
_start = newSpace;
_finish = _start + old_sz;
_end_of_storage = _start + newCapacity;
}
}- 关键点:
- 在该
reserve函数的实现中:如果一个空构造的vector对象(初始指针均为nullptr ),也就是该vector对象没有实际的内存空间。若该被空构造出来的对象,直接调用reserve后,对象内的三个指针就都变成了有效地址。可以大胆的对这三个指针进行解引用访问操作。
- 在该
- 原理分析:
- 空对象的
capacity()一定为0,因此调用reserve时会进入扩容逻辑。我们的reserve函数的实现,不管_start掌管的空间中是否有数据,都会开辟一段大小为newCapacity的空间 。空对象的_start指针为nullptr,不会进入拷贝数据的逻辑。之后,_start被赋值为newSpace(开辟的新空间的地址 )。_finsih和_end_of_storage经过相对偏移地址计算后,也就变成了有效地址
- 空对象的
3.2 resize弹性调整
cpp
// 初始化 n 个数据
void resize(size_t n, const T& val = T()) {
// 要求size 变小时,直接 改 _finish
if (n < size())
_finish = _start + n;
// 要求size 变大时,多出来的空间用val初始化
else {
reserve(n); // n 小于 capacity时,reserve什么都不做,大于时扩容
// 将多出来的空间用val填充
while(_finish != _start + n){
*_finish = val;
++_finish;
}
}
}双重模式思路:
- 要求
size变小时,直接修改_finish指针 - 要求
size变大时,不管n是否大于capacity,都调用reserve,多出来的空间用val初始化n是新空间中总容量的个数,_start + n表示了_end_of_storage的位置- 从
[_finish, _start + n)这块连续空间是需要用val初始化的,面对自定义类型时,采用调用operator=的方式依然可以完成深拷贝。
内置类型的默认构造函数:
resize初始化,val是可以有默认值(缺省参数)的,但如何确定缺省参数的类型?- 此时形参
T()本质是一个T类型的匿名对象 ,会调用T类型的默认构造 。因此写一个类,一定要提供默认构造 - 如果传入的是
int等内置类型resize怎么运行?理论上不能运行。但C++有了模板后,C++对内置类型进行了升级,也支持内置类型有默认构造函数
内置类型的默认构造函数使用示例:
- 内置类型的默认构造 :
int默认构造为0double默认构造为0.0- 指针默认构造为
nullptr
4. 迭代器失效专题
4.1 insert实现与失效分析
内部和外部迭代器失效
insert和erase的实现和顺序表的插入实现思路一致,这里不在细致分析。我们直接关注insert的迭代器失效问题
**迭代器失效引入:**这里我们先使push_back通过调用insert函数来实现
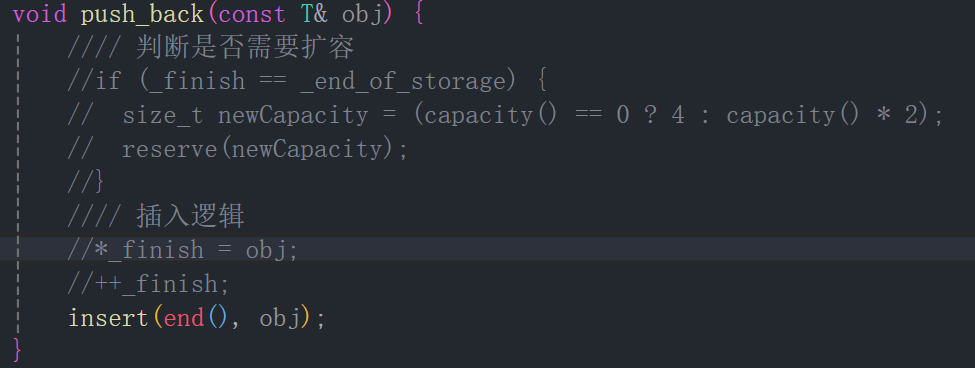
cpp
void push_back(const T& obj) {
//// 判断是否需要扩容
//if (_finish == _end_of_storage) {
// size_t newCapacity = (capacity() == 0 ? 4 : capacity() * 2);
// reserve(newCapacity);
//}
//// 插入逻辑
//*_finish = obj;
//++_finish;
insert(end(), obj);
}
// 会出现迭代器失效的insert函数
void insert(iterator pos, const T& obj) {
assert(pos >= _start && pos <= _finish); // 保证插入位置正确
// 扩容逻辑
if (_finish == _end_of_storage) {
size_t newCapacity = (capacity() == 0 ? 4 : capacity() * 2);
reserve(newCapacity);
}
// 挪动元素
iterator end = _finish - 1;
while (end >= pos) {
*(end + 1) = *end;
--end;
}
// 插入数据
*pos = obj;
++_finish;
}
// 测试迭代器失效的代码
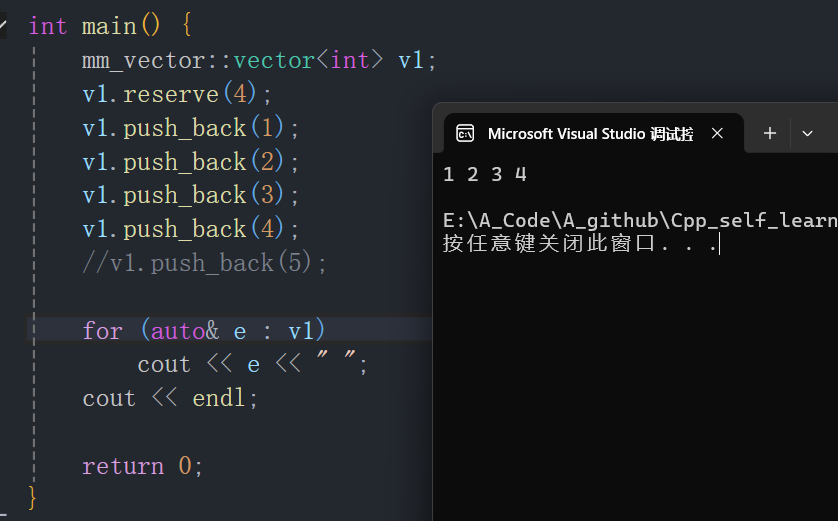
int main() {
mm_vector::vector<int> v1;
v1.reserve(4);
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
//v1.push_back(5);
for (auto& e : v1)
cout << e << " ";
cout << endl;
return 0;
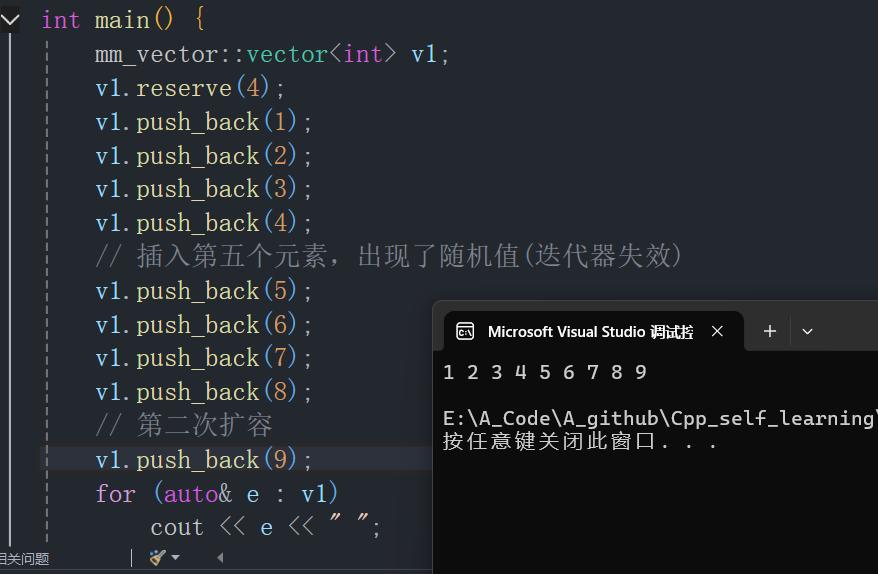
}- 将v1的空间设置为4,插入四个元素后,遍历元素,这里结果正确
-
再插入第五个元素时,第五个元素变成了随机值。
-
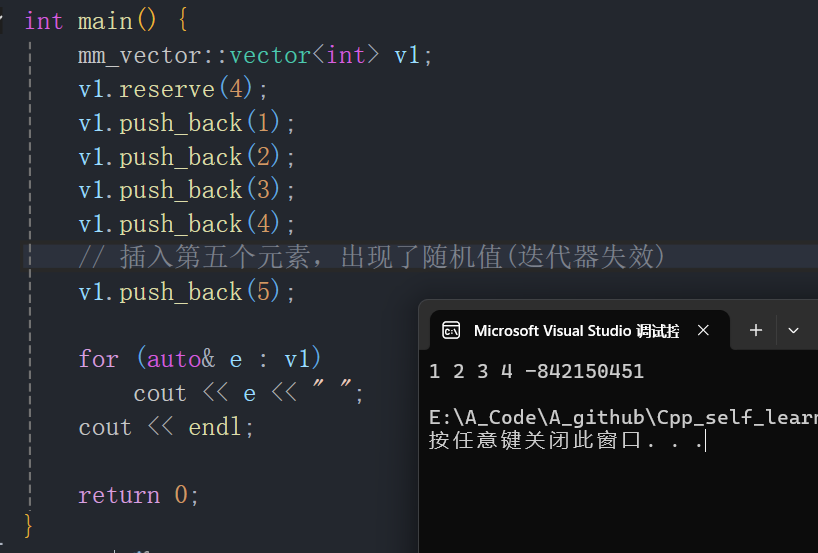
-
这就是著名的迭代器失效问题 。insert的迭代器失效主要发生在扩容时
迭代器失效与我们insert函数的实现方式有关。
- insert函数使用时,是形参pos接受一个迭代器类型的指针,在pos位置插入 。而
pos是一个指针,指向一段空间中的某个位置。 - 如果插入元素时,
vector内部的空间足够,没有发生扩容,那么不会出现迭代器失效。 - 如果因为空间不够而发生了扩容,由于我们实现的扩容策略是异地扩容 ,扩容后数据的地址发生更新,而pos的值没有更新,指向的仍然那是之前旧空间位置的地址 。由于我们扩容拷贝数据后就将之前的空间释放销毁 了,因此
pos指向的不是我们想要插入数据的位置。这样pos就失效了。这种问题被称为迭代器失效 - 上图的场景就是如此:
reserve设置vector的空间为4个,插入前四个元素时一切正常。插入的第五个元素变成了随机值,就是因为插入第五个元素时发生了扩容,原来的pos指针没有更新,产生了迭代器失效问题
迭代器失效问题的图解:
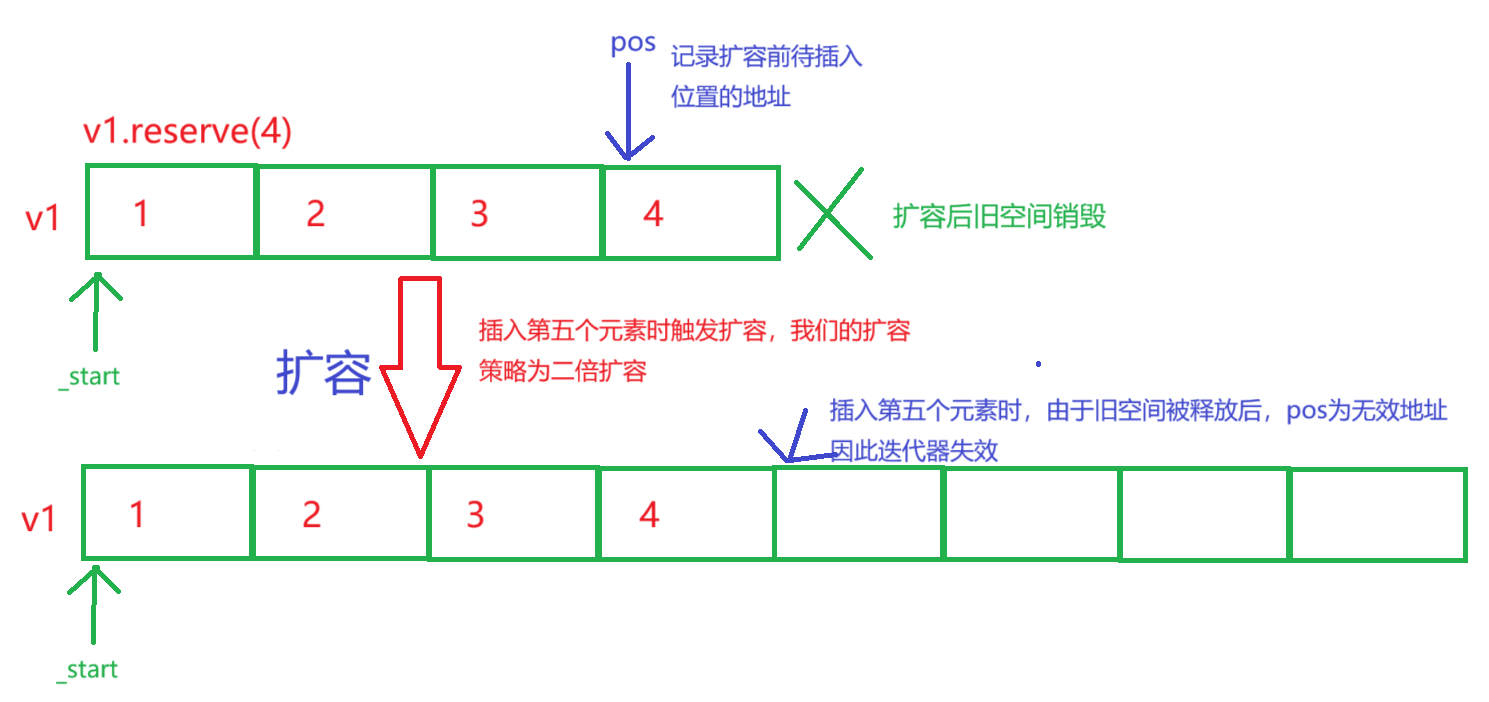
通过图解,我们可以轻松得知,迭代器失效的本质是扩容后pos指针的失效 。那么解决此类迭代器失效,只需要在扩容后,将pos的值设置正确即可解决。
pos是指针,记录的是地址。虽然扩容后pos的具体值我们不知道是多少,但是我们知道,pos相对于_start的值是不变的- 因此我们可以记录下pos相对于_start的位置,扩容后利用这个相对值,更新pos的值为正确的地址
完成更新pos值的insert函数
cpp
void insert(iterator pos, const T& obj) {
assert(pos >= _start && pos <= _finish); // 保证插入位置正确
// 扩容逻辑
if (_finish == _end_of_storage) {
size_t len = pos - _start; // 记录 pos 相对于 _start 的位置
size_t newCapacity = (capacity() == 0 ? 4 : capacity() * 2);
reserve(newCapacity);
// 扩容后更新pos的值,防止迭代器失效
pos = _start + len;
}
// 挪动元素
iterator end = _finish - 1;
while (end >= pos) {
*(end + 1) = *end;
--end;
}
// 插入数据
*pos = obj;
++_finish;
}-
可以看到,更新完pos之后,我们多插入一些数据,即便触发了两次扩容,插入结果依然是正确的
-
-
如上解决的问题,本质是解决了内部的迭代器失效 ,因为迭代器
pos的失效发生在函数内部
还有外部迭代器失效问题
-
我们不能排除有人会写出这样的代码:
cppmm_vector::vector<int>::iterator p = v1.begin() + 3; v1.insert(p, 300); for (auto& e : v1) cout << e << " "; cout << endl; *p += 100;-
完整测试用例:
cppint main() { mm_vector::vector<int> v1; v1.reserve(4); v1.push_back(1); v1.push_back(2); v1.push_back(3); v1.push_back(4); for (auto& e : v1) cout << e << " "; cout << endl; // 外部迭代器失效 // 不能排除有人会这样子调用insert函数 mm_vector::vector<int>::iterator p = v1.begin() + 3; v1.insert(p, 300); for (auto& e : v1) cout << e << " "; cout << endl; *p += 100; for (auto& e : v1) cout << e << " "; cout << endl; return 0; } -
-
对已有四个数据的
vector在进行插入,显式定义了一个迭代器p,指向第四个位置。插入之后,又对p解引用修改第四个位置的值。但由于插入时发生了扩容,插入后p已经失效 ,因此对*p的修改不会发生。
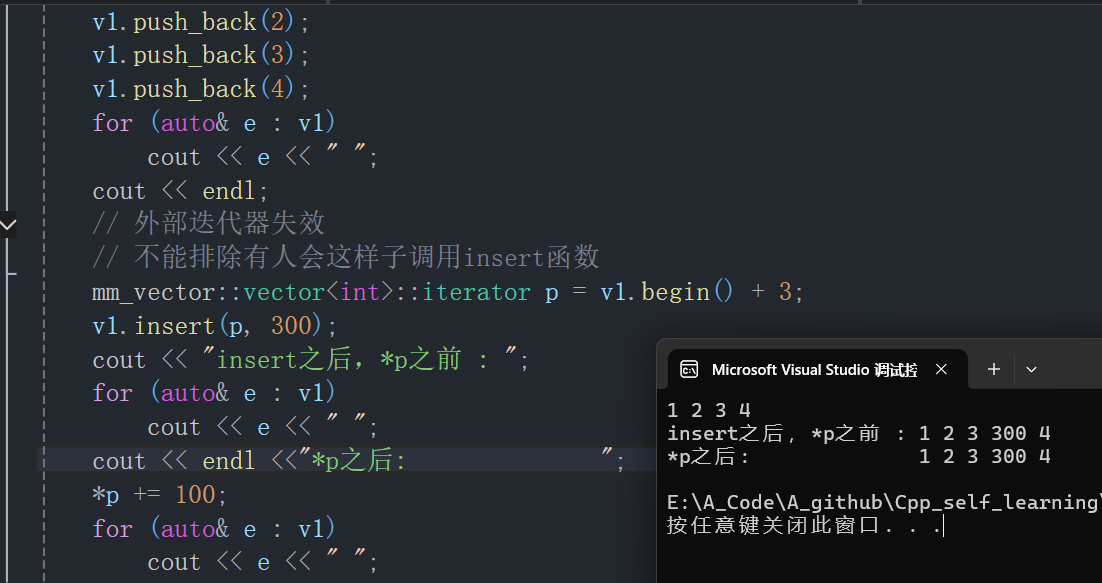
可以看到,对p位置数据的修改没有发生。这种问题被称为外部的迭代器失效问题。
-
外部的迭代器失效问题我们无法解决,因为==不同编译器平台实现的扩容策略不同,我们无法预知库中实现的vector何时发生扩容!==我们来看标准库中的应对策略。
-
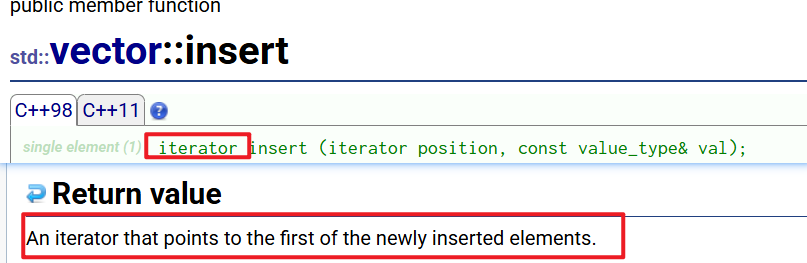
-
标准库中,返回了指向新插入元素的位置的迭代器。因此最终解决方案如下:
cpp
// 解决内部和外部迭代器的最终insert实现方案
iterator insert(iterator pos, const T& obj) {
// 保证插入位置正确
assert(pos >= _start && pos <= _finish);
// 扩容逻辑
if (_finish == _end_of_storage) {
size_t len = pos - _start; // 记录 pos 相对于 _start 的位置
size_t newCapacity = (capacity() == 0 ? 4 : capacity() * 2);
reserve(newCapacity);
// 扩容后更新pos的值,防止迭代器失效
pos = _start + len;
}
// 挪动元素
iterator end = _finish - 1;
while (end >= pos) {
*(end + 1) = *end;
--end;
}
// 插入数据
*pos = obj;
++_finish;
return pos;
}-
这样的目的在于:
- 调用
insert之后,如果想访问新插入的元素,应该通过insert函数的返回值来访问,而不是通过原来传给形参pos指针的实参来访问。
- 调用
insert总结
insert之后,迭代器有可能会失效(主要会在发生 扩容时 迭代器失效 ),但不同平台的扩容策略不同 。因此我们无法预知何时会发生扩容,也就无法预知何时迭代器会失效。insert之后,不要再使用这个实参迭代器了,因为insert后,迭代器可能失效- 正确的做法是,使用
insert返回的迭代器来访问新插入的值。
- 正确的做法是,使用
- 综上:
insert这样的接口是不安全的,因此我们应当直接认为insert后,迭代器会失效
4.2 erase实现与失效处理
有了insert失效的例子,我们很容易可以理解erase的失效问题:
cpp
iterator erase(iterator pos) {
assert(pos >= _start && pos < _finish);
// 前移覆盖元素
iterator begin = pos + 1;
while (begin < _finish) {
*(begin-1) = *begin; // 深拷贝赋值
++begin;
}
--_finish;
return pos; // 返回删除位置的新迭代器
}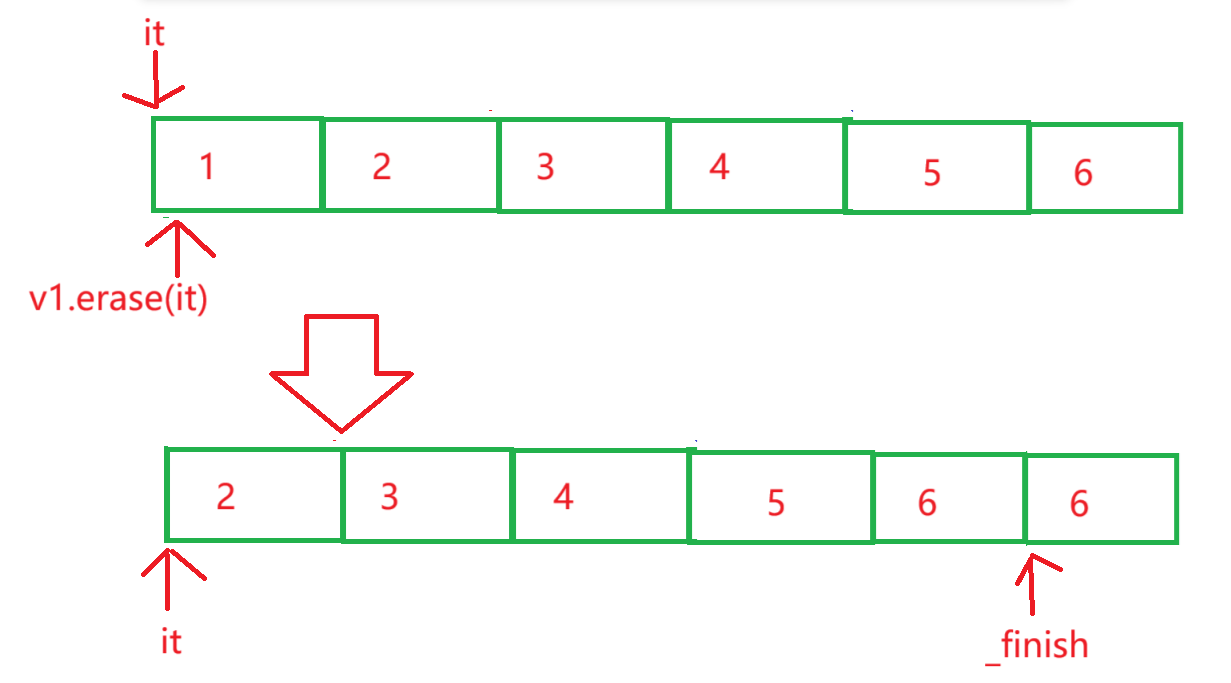
- 我们的
erase的实现是挪动数据完成覆盖,从而完成元素的删除。 erase(pos)删除pos位置的元素。当pos指向最后一个元素时,当我们通过erase(it)删除完最后一个元素,再通过迭代器去访问时,该位置可能会出现随机值。- 这是因为,我们通过
erase删除元素,会进行数据的挪动。挪动后,迭代器指向的值已经不再是删除前的值了。此时再使用迭代器访问,会导致迭代器失效 ,可能出现随机值!并且VS平台下,会对erase删除后再利用先前的迭代器访问元素进行强制报错检查!
cpp
auto it = v1.begin() + 3;
v1.erase(it);
for (auto& e : v1)
cout << e << " "; cout << endl;
*it = 100; // 报错!
cout << *it << endl;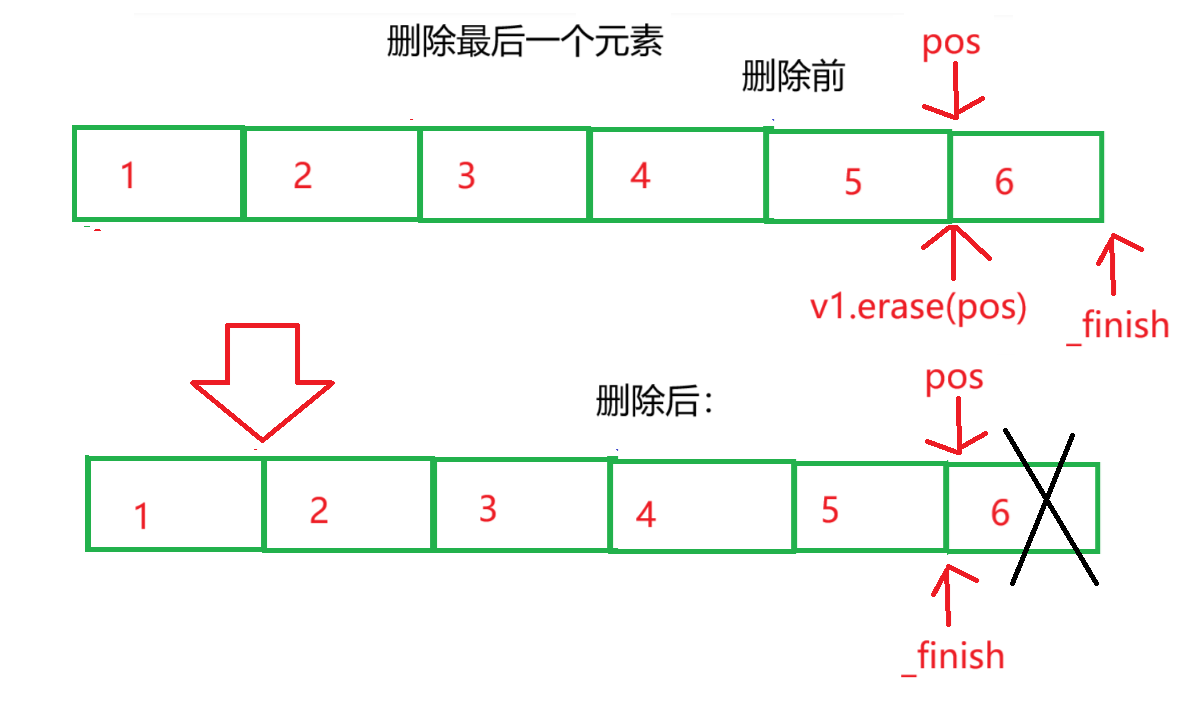
- 可以看到,删除最后一个元素后,最后一个位置的空间已经不属于我们 ,因此不能再使用
*pos访问元素了
5. 元素操作实现
push_back
cpp
void push_back(const T& obj) {
if (_finish == _end_of_storage) {
reserve(capacity() == 0 ? 4 : capacity()*2);
}
*_finish = obj; // 运算符=重载依赖
++_finish;
//insert(end(), obj);
}if (_finish == _end_of_storage):首先检查当前vector是否需要扩容reserve(capacity() == 0 ? 4 : capacity()*2):如果容器当前容量为0,那么扩容为4个空间 。如果不为0但需要扩容,那么执行二倍扩容策略
- _finish指向最后一个元素的下一个位置 :解引用,赋值,完成尾插
- 此处调用的是赋值 :内置类型 直接复制,自定义类型 会调用其
operator=,保证了自定义类型的深拷贝正确 - 赋值后
_finish++,标识有效数据个数加一
- 此处调用的是赋值 :内置类型 直接复制,自定义类型 会调用其
pop_back
cpp
void pop_back() {
erase(--end());
}-
这里的
pop_back尾删,我们直接调用erase函数即可,传入最后一个元素的位置指针 ,也就是--end() -
有兴趣的读者可以自主实现一个不依赖
erase函数的尾删
6. 运算符重载
6.1 \[\]下标访问
cpp
// 普通vector对象[]重载
T& operator[](size_t pos) {
assert(pos < size());
return _start[pos];
}
// const vector对象[]重载
const T& operator[](size_t pos) const {
assert(pos < size());
return _start[pos];
}operator[]的实现较为简单assert(pos < size())对要访问的位置进行断言强制检查,防止越界访问- 之后返回空间中
pos位置的值_start[pos] - 普通对象 返回
T&,const对象 返回const T&;
6.2 流操作符
- 流操作符,我们为了符合使用习惯,我们将
operator<<声明为友元函数
cpp
template<typename T>
class vector {
public:
template<class T1> // 模板函数,声明和定义处都要写上 template<class T1>
friend ostream& operator<<(ostream& out, const vector<T1>& v);
public:
// 其他成员函数
private:
// 成员变量
}
// 函数实现
template<class T1>
ostream& operator<<(ostream& out, const vector<T1>& v) {
for (auto& e : v)
out << e << " ";
return out;
}- 为了符合使用
<<的使用习惯,我们将operator<<声明为友元函数 - 在函数内,实现对
vector中元素的遍历 return ostream&类型的对象,满足流插入运算符<<的连续调用
6.3 operator=
operator=的实现,我们同样要实现深层次的深拷贝
cpp
// = 重载 深拷贝
// v2 = v1
// 自定义类型值传参时,会调用拷贝构造函数,我们已经实现了深拷贝
// operator= 的深拷贝
vector<T>& operator=(vector<T> tmp) {
swap(tmp);
return *this;
}
// 两个vector交换
void swap(vector<T>& v) {
std::swap(v._start, _start);
std::swap(v._finish, _finish);
std::swap(v._end_of_storage, _end_of_storage);
}- 由于我们已经有了实现
string的经验,因此实现vector的operator=最好直接采用现代写法 operator=调用时,由于参数类型为值传递,根据C++中函数参数传递的规则 :- 函数调用要先传参
- 内置类型值传参:直接拷贝
- 自定义类型值传参:调用其拷贝构造函数
- 用
v2 = v1赋值来举例,传参过后,调用swap函数之前的结果的结构图如下:
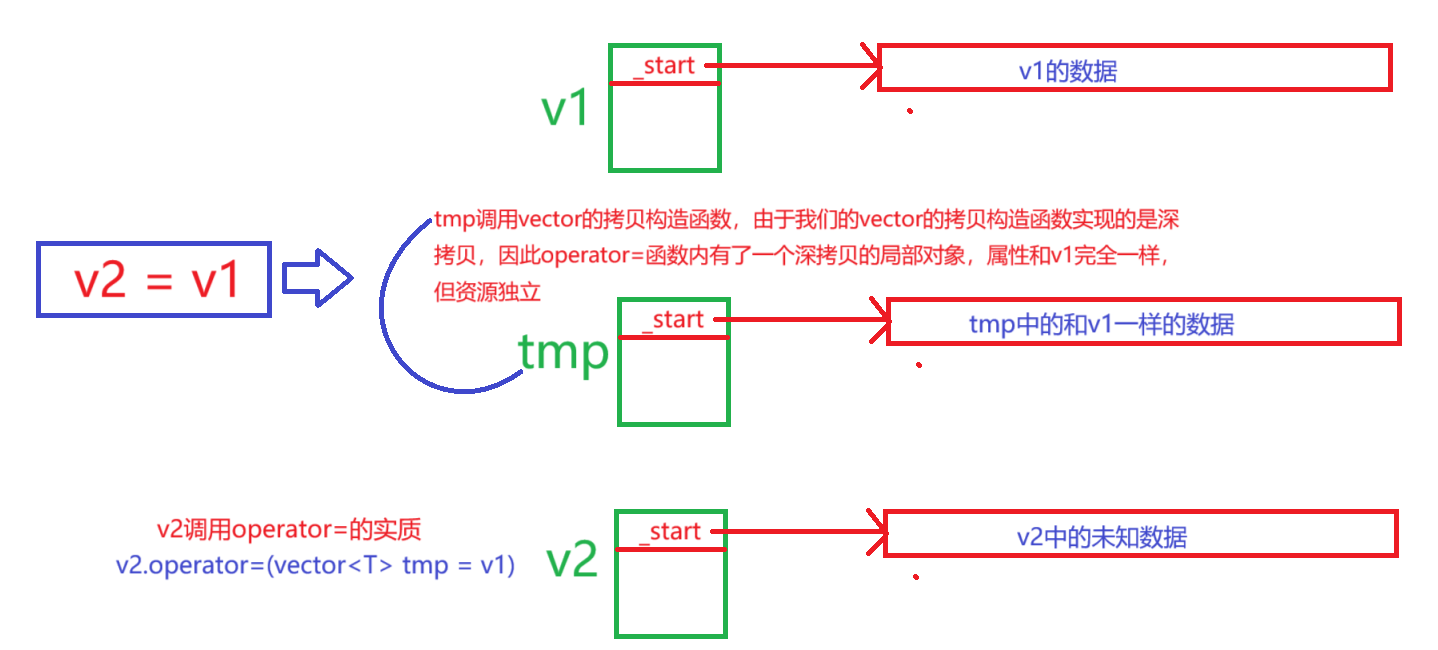
- 现在
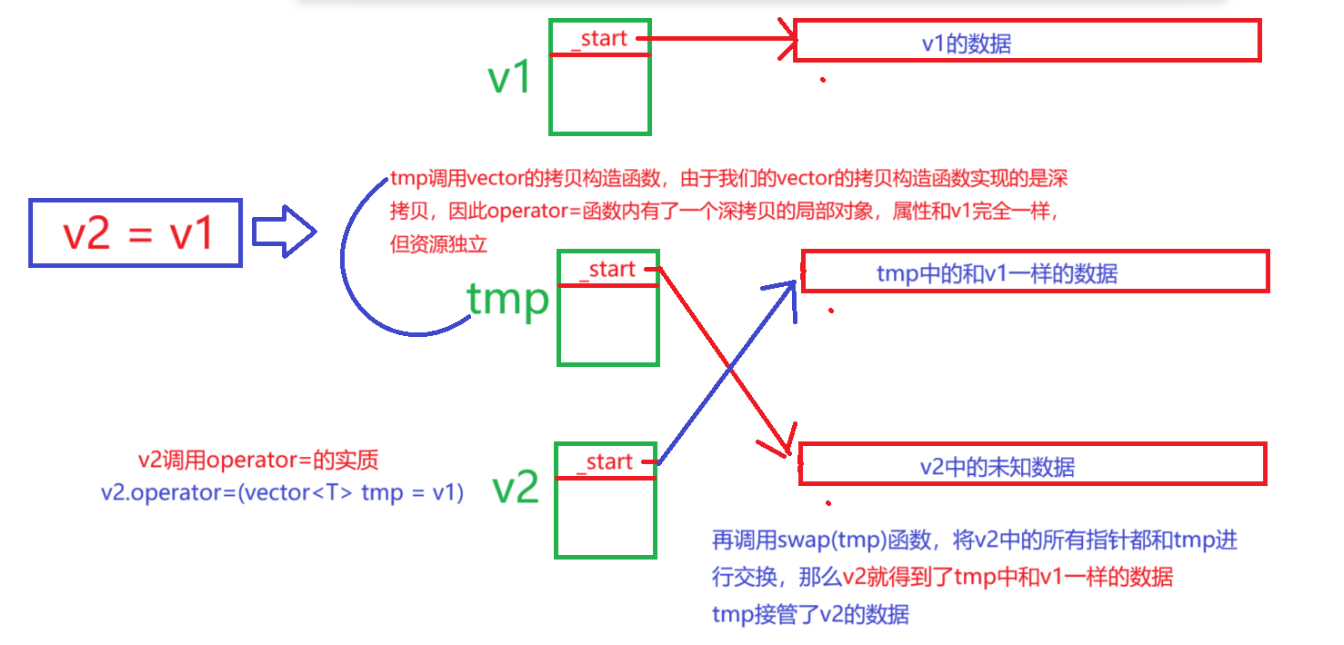
v2想要变得和v1一模一样,且要内存资源独立。我们调用swap(tmp)函数,结构图如下: - v2和tmp中的所有指针的值进行了交换:
tmp接管了v2的数据,v2拿到了tmp中的和v1完全相同的数据,同时_finsih和_end_of_storage指针也和v1的一样,这样就完成了v2 = v1,即将v1对象的值内存安全地赋值给v2- 之后由于
tmp为函数局部对象,函数调用结束后自动销毁,销毁时自动调用析构函数 ,清理接管的v2中的资源,内存完全安全。
- 这样我们就优雅地完成了
operator=的实现。
7. 成员变量缺省值与完整实现
成员变量缺省值优化初始化列表
我们知道,在C++11的更新中,成员变量可以有缺省值,用于初始化列表使用 。这一特性可以使我们的构造函数无需再写初始化列表了,只需在成员变量声明的同时定义初始缺省值即可。
cpp
class vector{
public:
// 成员函数...
private:
//成员变量命名与标准库STL中的命名风格保持一致
//可以用C++11中的 成员变量缺省值 给初始化列表使用 这样在构造函数中,就不用写初始化列表了
iterator _start = nullptr;
iterator _finish = nullptr;
iterator _end_of_storage = nullptr;
public:
// 优化后的构造函数
vector() // 默认构造
{ }
// n 个 val构造
vector(size_t n, const T& val = T()) {
resize(n, val);
}
vector(int n, const T& val = T()) { //多提供一个 int int 类型的构造
resize(n, val);
}
// 迭代器区间构造
template<typename InputIterator>
vector(InputIterator first, InputIterator last) {
while (first != last) {
push_back(*first);
++first;
}
}
// 拷贝构造函数
vector(const vector<T>& v) {
_start = new T[v.capacity()];
for (size_t i = 0; i < v.size(); ++i) {
_start[i] = v[i];
}
_finish = _start + v.size();
_end_of_storage = _start + v.capacity();
}
// 拷贝构造函数二选一即可
vector(const vector<T>& v) {
reserve(v.capacity());
for (auto& e : v)
push_back(e);
}
};优化后的完整代码实现
cpp
#pragma once
#include <iostream>
#include <vector>
#include <algorithm>
#include <assert.h>
#include <string.h>
#include <stdlib.h>
using namespace std;
namespace mm_vector {
template<typename T>
class vector {
public:
template<class T1>
friend ostream& operator<<(ostream& out, const vector<T1>& v);
typedef T* iterator;
typedef const T* const_iterator;
iterator begin() { return _start; }
iterator end() { return _finish; } // end是最后一个元素的下一个位置
const_iterator begin() const { return _start; }
const_iterator end() const { return _finish; }
// 指针 - 指针 得到中间的元素个数
size_t capacity() const {
return _end_of_storage - _start;
}
size_t size() const {
return _finish - _start;
}
bool empty() const {
return _start == _finish;
}
private:
//与标准库STL中的命名风格保持一致
//可以用C++11中的 成员变量缺省值 给初始化列表使用 这样在构造函数中,就不用写初始化列表了
iterator _start = nullptr;
iterator _finish = nullptr;
iterator _end_of_storage = nullptr;
public:
vector() // 默认构造
{ }
// n 个 val构造
vector(size_t n, const T& val = T()) {
resize(n, val);
}
vector(int n, const T& val = T()) { //多提供一个 int int 类型的构造
resize(n, val);
}
// 迭代器区间构造
template<typename InputIterator>
vector(InputIterator first, InputIterator last) {
while (first != last) {
push_back(*first);
++first;
}
}
// 拷贝构造函数
vector(const vector<T>& v) {
_start = new T[v.capacity()];
for (size_t i = 0; i < v.size(); ++i) {
_start[i] = v[i];
}
_finish = _start + v.size();
_end_of_storage = _start + v.capacity();
}
// 拷贝构造函数二选一即可
// vector(const vector<T>& v) {
// reserve(v.capacity());
// for (auto& e : v)
// push_back(e);
//}
vector<T>& operator=(vector<T> tmp) {
swap(tmp);
return *this;
}
// 两个vector交换
void swap(vector<T>& v) {
std::swap(v._start, _start);
std::swap(v._finish, _finish);
std::swap(v._end_of_storage, _end_of_storage);
}
~vector() {
if (_start) {
delete[] _start;
_start = _finish = _end_of_storage = nullptr;
}
}
T& operator[](size_t pos) {
assert(pos < size());
return _start[pos];
}
const T& operator[](size_t pos) const {
assert(pos < size());
return _start[pos];
}
void reserve(size_t newCapacity) {
if (newCapacity > capacity()) {
T* newSpace = new T[newCapacity];
size_t old_sz = size();
if (_start) {
for (size_t i = 0; i < old_sz; ++i) {
newSpace[i] = _start[i];
}
delete[] _start;
}
_start = newSpace;
_finish = _start + old_sz;
_end_of_storage = _start + newCapacity;
}
}
void resize(size_t n, const T& val = T()) {
if (n < size())
_finish = _start + n;
else {
reserve(n);
while(_finish != _start + n){
*_finish = val;
++_finish;
}
}
}
void push_back(const T& obj) {
if (_finish == _end_of_storage) {
size_t newCapacity = (capacity() == 0 ? 4 : capacity() * 2);
reserve(newCapacity);
}
*_finish = obj;
++_finish;
//insert(end(), obj);
}
void pop_back() {
erase(--end());
}
// 解决内部和外部迭代器的最终insert实现方案
iterator insert(iterator pos, const T& obj) {
// 保证插入位置正确
assert(pos >= _start && pos <= _finish);
// 扩容逻辑
if (_finish == _end_of_storage) {
size_t len = pos - _start; // 记录 pos 相对于 _start 的位置
size_t newCapacity = (capacity() == 0 ? 4 : capacity() * 2);
reserve(newCapacity);
// 扩容后更新pos的值,防止迭代器失效
pos = _start + len;
}
// 挪动元素
iterator end = _finish - 1;
while (end >= pos) {
*(end + 1) = *end;
--end;
}
// 插入数据
*pos = obj;
++_finish;
return pos;
}
// 为了解决迭代器失效问题,erase返回传入的pos的下一个位置
iterator erase(iterator pos) {
assert(pos >= _start && pos < _finish);
//删除
iterator begin = pos + 1;
//while (begin < end()) {
while (begin != _finish) {
*(begin - 1) = *begin;
++begin;
}
--_finish;
// 为了解决迭代器失效问题,erase返回传入的pos的下一个位置
// 挪动数据后,pos 就是被删除元素后面第一个元素的位置
return pos;
}
};
template<class T1>
ostream& operator<<(ostream& out, const vector<T1>& v) {
for (auto& e : v)
out << e << " ";
return out;
}
}8. 结语
在本文中,我们系统性地实现了STL风格的vector容器,深入剖析了动态数组的核心机制。通过手写代码,我们重点解决了以下几个工程实践中的关键问题:
- 三指针架构设计
采用_start、_finish、_end_of_storage三指针模型,精准控制容量边界与数据边界,为高效操作奠定基础。 - 深拷贝控制
通过new[]/delete[]配合元素级的赋值操作,实现容器与元素的双重深拷贝,确保内置类型与自定义类型的内存安全。 - 迭代器失效机制
重点剖析了insert/erase操作中的迭代器失效问题,通过相对位置计算和返回值设计,提供了标准化的解决方案。 - 现代C++特性应用
采用成员变量缺省值优化初始化逻辑,使用现代写法实现拷贝赋值,保持代码简洁高效。
核心启示:STL容器的设计精髓在于平衡效率与安全性。vector的扩容策略(异地扩容+二倍增长)既保证了O(1)的均摊时间复杂度,又通过迭代器失效机制强制规范了使用者的操作边界。
以上就是本文的所有内容了,如果觉得文章对你有帮助,欢迎 点赞⭐收藏 支持!如有疑问或建议,请在评论区留言交流,我们一起进步
分享到此结束啦
一键三连,好运连连!你的每一次互动,都是对作者最大的鼓励!
征程尚未结束,让我们在广阔的世界里继续前行!🚀