什么是 GraphRAG?
一句话来说,GraphRAG 是对检索增强生成(retrieval-augmented generation)的一种增强,它利用了图结构。
它有多种实现方式,这里我们重点介绍微软的方案。其主要可分为两个步骤:图构建(即索引构建)和查询(查询有三种方式:本地搜索、全局搜索和漂移搜索)。
我将通过一个真实案例,带大家了解图构建、本地搜索和全局搜索的过程。闲话不多说,我们就用 GraphRAG 对巴勃罗·里韦罗(Pablo Rivero)的《Penitencia》一书进行索引构建和查询。
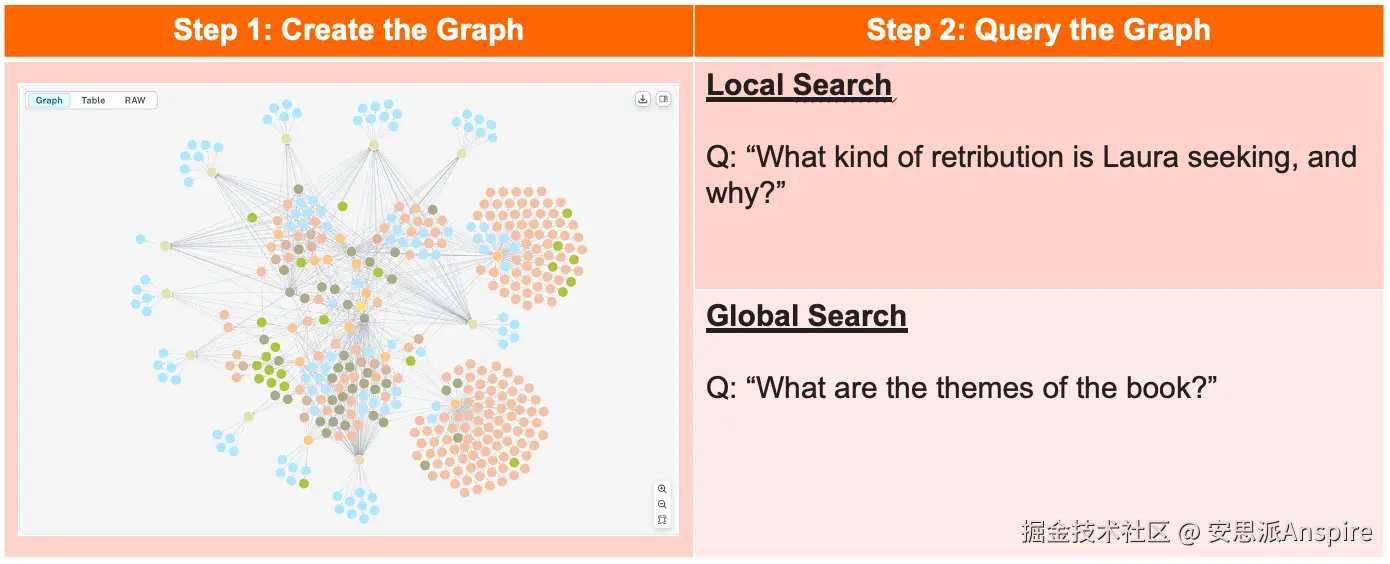
GraphRAG 的关键步骤:图构建和图查询
设置
GraphRAG 的文档会指导你完成项目设置。初始化工作区后,你会在 ragtest 目录中找到一个配置文件(settings.yaml)。
项目结构
我已将《Penitencia》一书添加到 input 文件夹中。在本文中,我未修改配置文件,使用默认设置和索引构建方法(IndexingMethod.Standard)。
图构建
要构建图,请运行:
bash
graphrag index --root ./ragtest这会触发两个关键操作:从源文档中提取实体,以及将图划分到社区,这两个操作在 GraphRAG 项目的 workflows 目录的模块中定义。
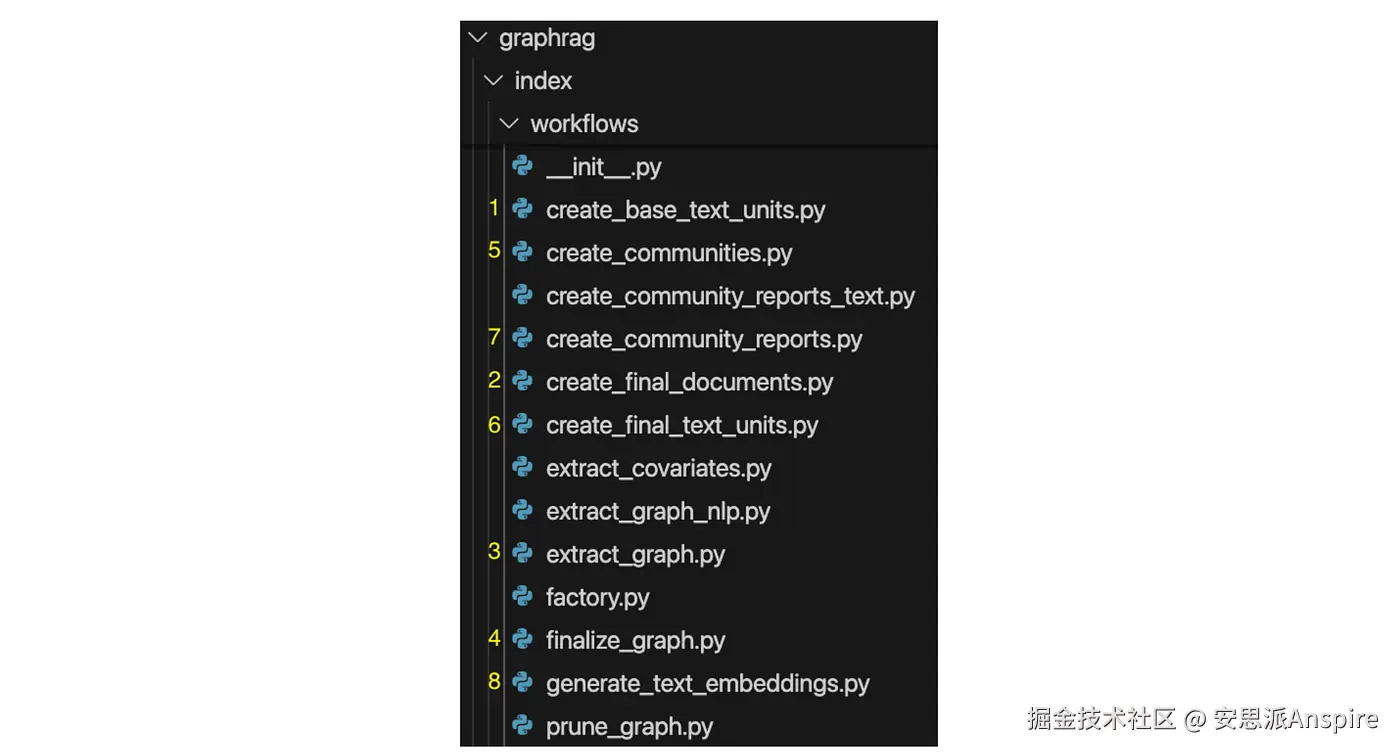
以上用于实现实体提取和图社区划分的模块,数字(黄色)表示执行顺序。
实体提取
- 在create_base_text_units模块中,文档会被分割成N个token的较小块。

《Penitencia》一书的前五个块。每个块长1200个token,并有唯一ID。
- 在create_final_documents模块中,会创建一个查找表,用于将文档映射到其关联的文本单元。每一行代表一个文档,由于我们只处理一个文档,因此只有一行。

按ID展示所有文档的表格。对于每个文档,所有关联的块(即文本单元)都按其ID列出。
- 在extract_graph模块中,每个块会通过LLM(来自OpenAI)进行分析,在该提示词的引导下提取实体和关系。
在此过程中,可能会出现重复的实体和关系。例如,主角Jon在82个不同的文本块中被提及,因此他被提取了82次------每个块一次。
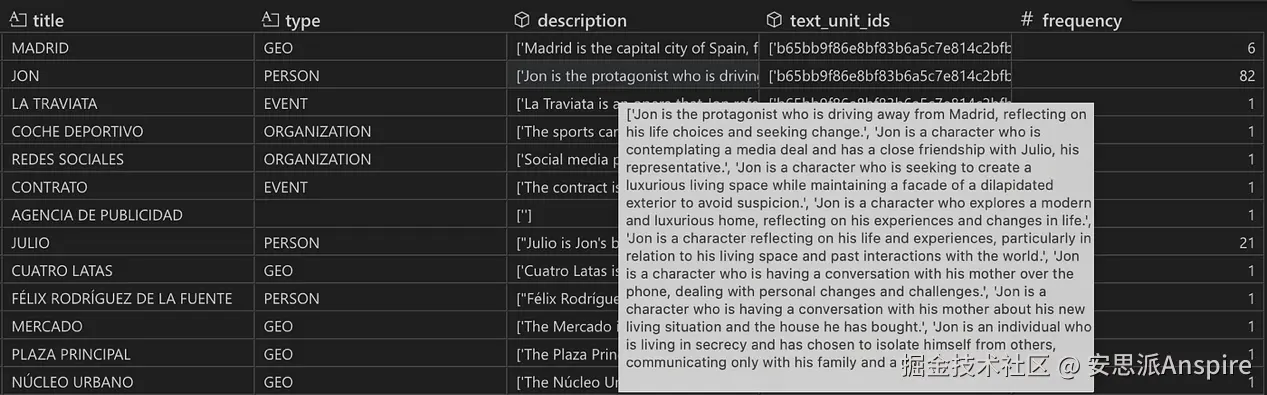
实体表快照。实体按实体名称和类型分组。从频率列可以看出,实体Jon被提取了82次。text_unit_ids列和description列分别包含82个ID和描述的列表,显示Jon在哪些块中被识别和描述。默认情况下,有四种实体类型(地理、人物、事件和组织)。
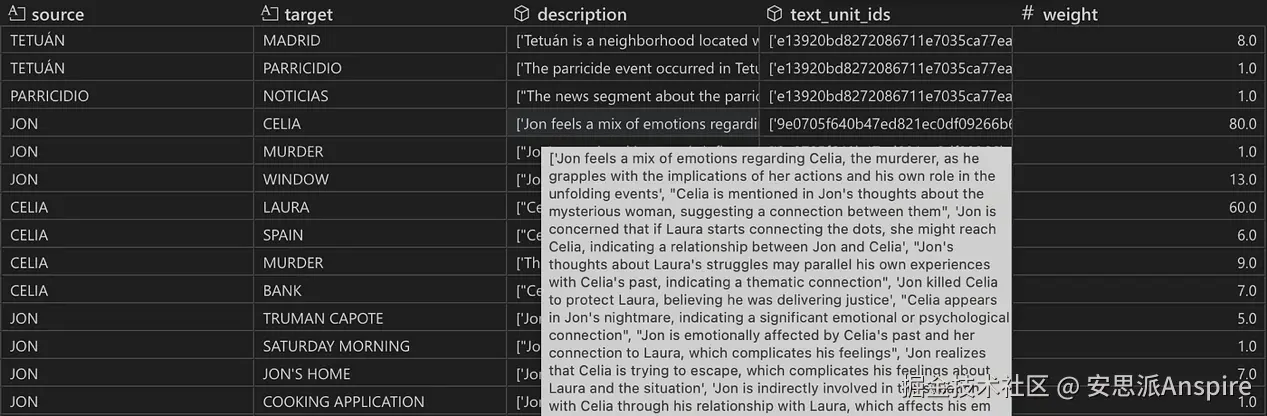
关系表快照。关系按源实体和目标实体分组。对于Jon和Celia,description列和text_unit_ids列各包含14个条目的列表,表明这两个角色在14个不同的文本块中被识别出存在关系。weight列显示LLM分配的关系强度之和(权重不是源节点和目标节点之间的连接数量!)。
通过根据实体的标题和类型对实体进行分组,以及根据关系的源节点和目标节点对关系进行分组,尝试进行去重。然后,通过分析所有出现的较短描述,提示LLM为每个唯一实体和唯一关系编写详细描述(参见提示词)。
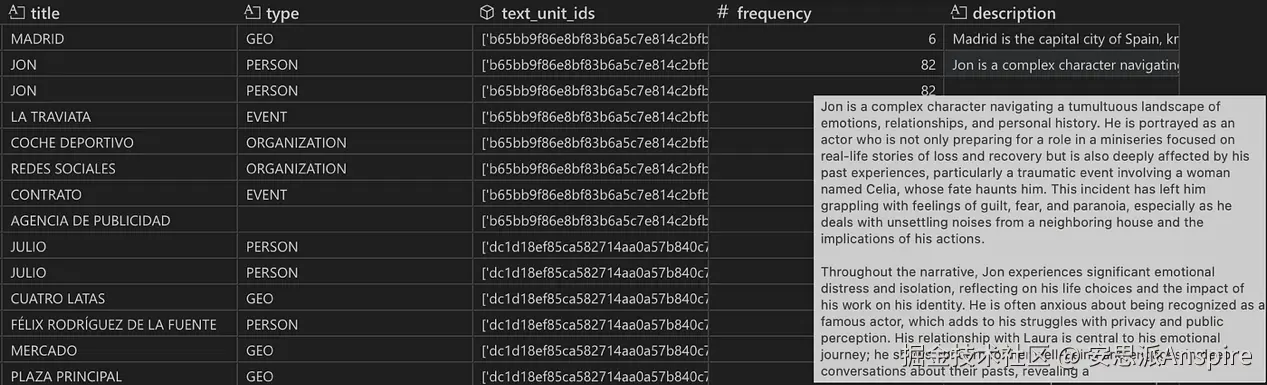
带有最终实体描述(由所有提取的短描述组合而成)的实体表快照。
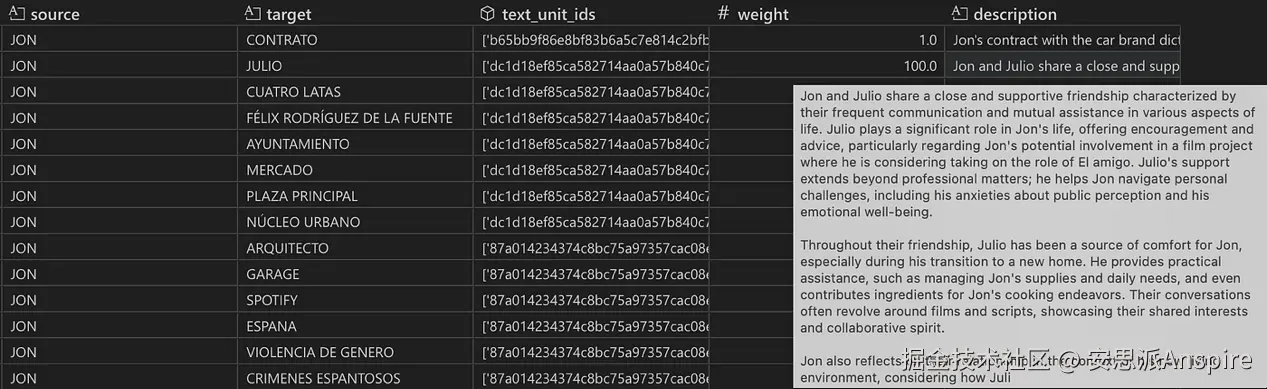
带有最终关系描述(由所有提取的短描述组合而成)的关系表快照。
如你所见,去重有时并不完美。此外,GraphRAG不处理实体消歧(例如,Jon和Jon Márquez尽管指的是同一个人,也会是不同的节点)。
- 在finalize_graph模块中,使用NetworkX库将实体和关系表示为图的节点和边,包括节点度数等结构信息。

最终实体表快照,其中每个实体代表图中的一个节点。节点的度数是其拥有的边数(即它连接的其他节点数量)。

最终关系表快照,其中每个关系代表图中的一条边。边的combined_degree表示源节点和目标节点度数之和。combined_degree高的边很重要,因为它连接了高度连通的节点。
我发现直观地查看图有助于理解,因此我使用Neo4j(笔记本)将结果可视化:

使用Neo4j可视化的《Penitencia》一书的图
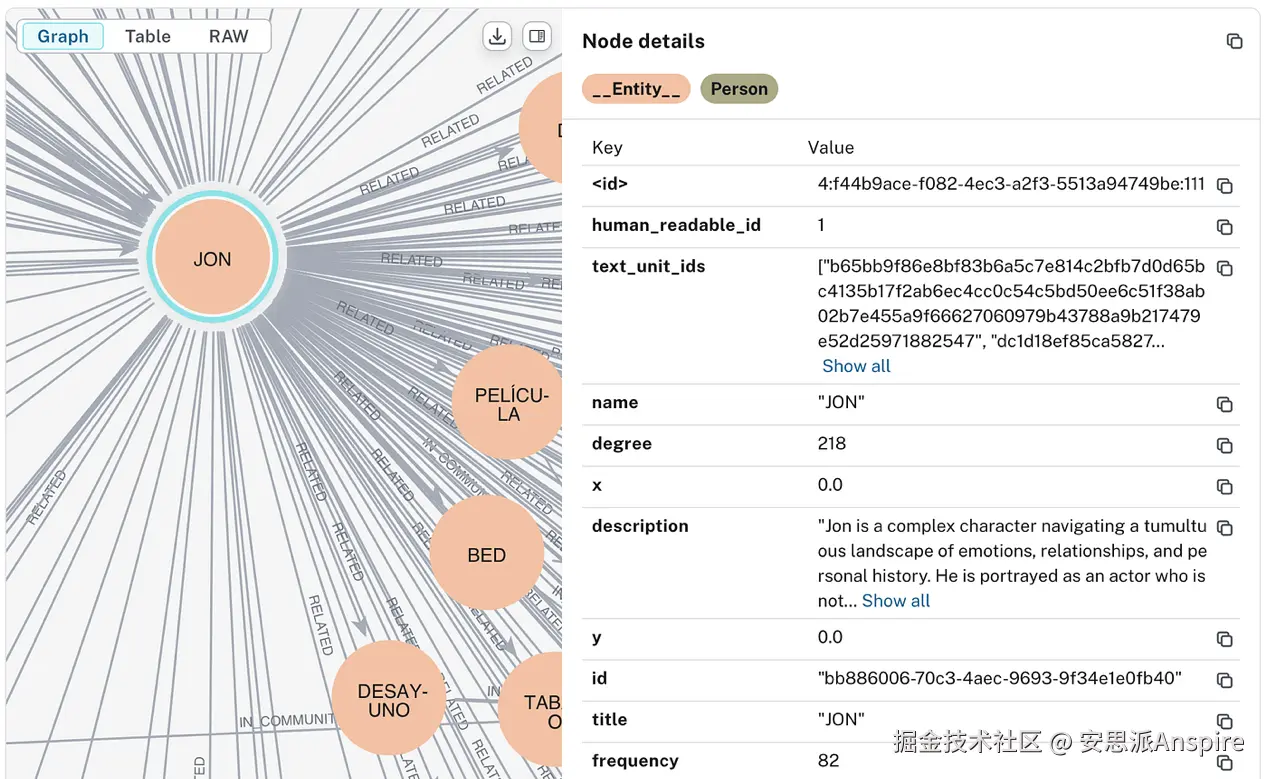
使用Neo4j可视化的实体Jon及其关系
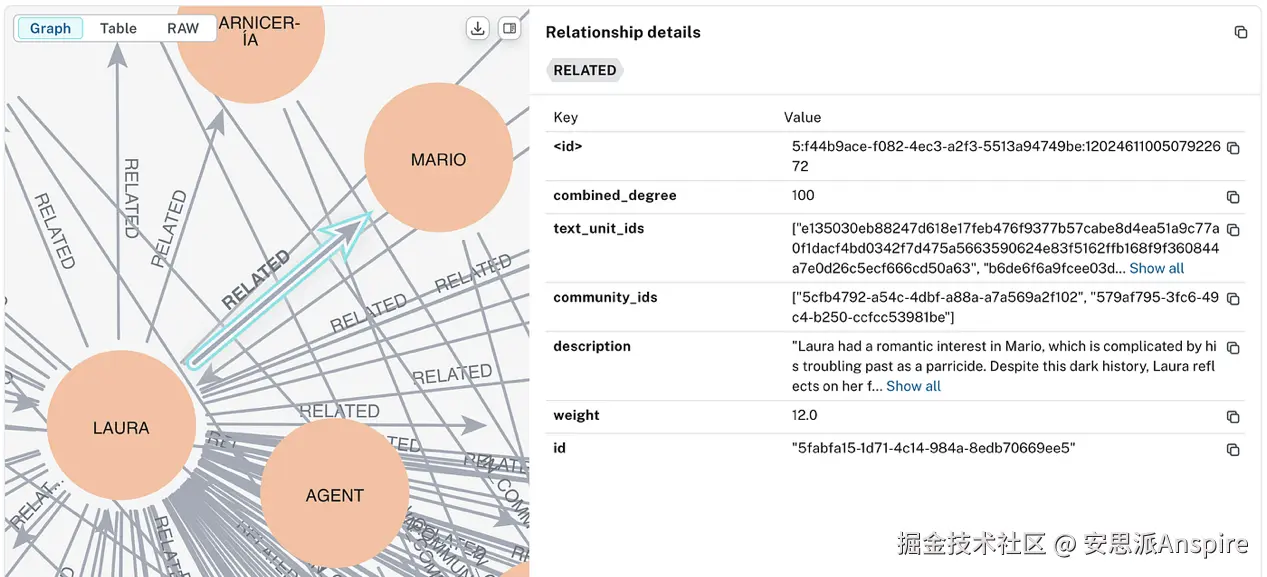
使用Neo4j可视化的Laura和Mario之间的关系(作为图的一条边)
图的社区划分
- 在create_communities模块中,使用Leiden算法(一种层次聚类算法)将图划分成多个社区。
社区是一组节点的集合,这些节点彼此之间的关联性比与图中其他节点的关联性更强。Leiden算法的层次特性使其能够检测出具有不同具体程度的社区,这体现在社区的层级(level)上。层级越高,社区的具体性越强(例如,层级3的社区相当具体,而层级0的社区是根社区,非常通用)。

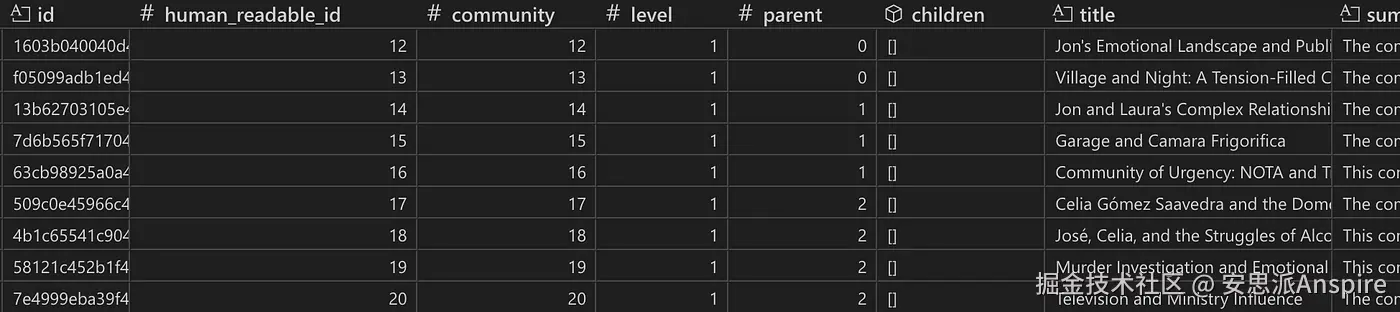
社区表快照。社区0是层级0的社区,因此是根社区(没有父社区)。从子社区(children)列可以看出,它有两个子社区。该社区包含的所有关系、文本单元和实体分别在相应列中列出。大小(size)列显示该社区由131个实体组成。
如果我们将每个社区可视化为一个节点(包括属于该社区的实体),就能看到明显的聚类。

过滤出IN_COMMUNITY关系后,《Penitencia》的图显示出15个根层级社区(红色圆圈)
社区的价值在于其能够整合来自多种来源的信息(如实体和关系),从而提供宏观层面的见解。对于书籍而言,社区可以揭示文本中的核心主题或话题,这一点我们将在第8步中看到。
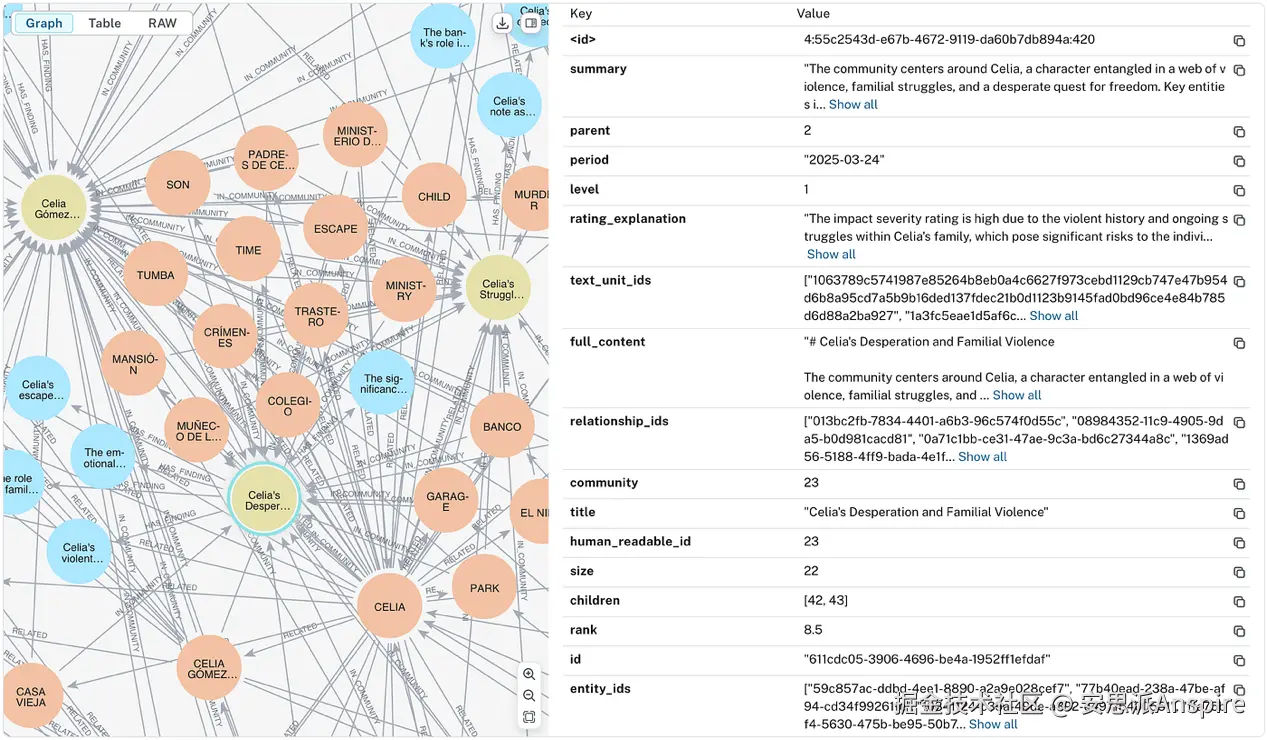
三个层级相连的社区的Neo4j可视化:社区2(Celia Gómez与Tetuán事件)---父社区→社区23(Celia的绝望与家庭暴力)---父社区→社区42(Celia与Laura的冲突)。排名(Rank)是LLM为社区分配的重要性评分,范围从1(最低重要性)到10(最高重要性)。
- 在create_final_text_units模块中,第1步得到的文本单元表会将实体ID、关系ID和协变量ID(如有)映射到每个文本单元ID,以便于查找。

最终文本单元表快照
协变量本质上是一些断言。例如,"Celia谋杀了她的丈夫和孩子(疑似)"。LLM会在该提示词的引导下,从文本单元中推导出这些协变量。默认情况下,协变量不会被提取。
- 在create_community_reports模块中,LLM会为每个社区生成一份报告,详细说明其主要事件或主题,并给出报告摘要。LLM在该提示词的引导下,接收该社区的所有实体、关系和断言作为上下文。
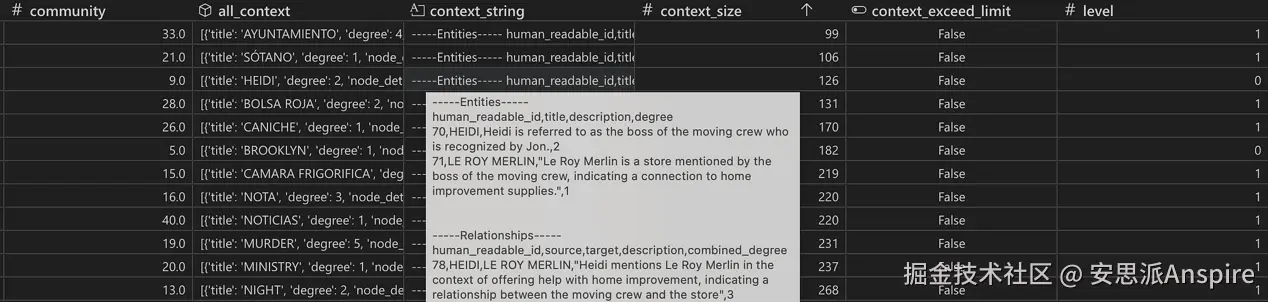
报告生成前中间步骤的表格快照。对于每个社区,所有实体和关系都会被收集起来,然后整理成一个字符串,作为上下文传递给LLM。context_exceed_limit列会在context_string需要缩短时向算法发出警报。
对于大型社区,上下文字符串(包括实体、关系,可能还有协变量)可能会超过配置文件中指定的max_input_length。出现这种情况时,算法会采用一种方法来减少上下文中的文本量,包括层次替换(Hierarch Substitution),必要时还会进行裁剪(Trimming)。
在层次替换中,实体、关系、断言的原始文本会被子社区的社区报告所替代。
例如,假设社区C(层级0)有子社区S1和S2(均为层级1)。社区S1的规模(实体数量)大于S2。在这种情况下,C中同时属于S1的所有实体、关系和断言都会被S1的社区报告替代。这优先考虑最大程度减少token数量。如果经过此操作后上下文长度仍超过max_input_length,则会使用S2来替代C中相关的实体和关系。
如果经过层次替换后,上下文仍然过长(或者该社区根本没有子社区),那么上下文字符串就需要进行裁剪------直接排除相关性较低的数据。实体和关系会分别按其节点度数和组合度数排序,移除那些数值最低的实体和关系。
最终,LLM会利用提供的上下文字符串生成关于该社区的发现(5-10条关键见解的列表)和摘要。这些内容会被合并,形成社区报告。

图为包含LLM生成的报告(full_content列)和报告摘要(summary列)的社区表快照。报告文本是摘要(红色)和发现(蓝色)的组合。rank列和rating_explanation列分别包含LLM为该社区分配的重要性值(1到10之间)以及对所选数值的理由说明。
- 最后,在generate_embeddings模块中,会使用配置文件中指定的OpenAI嵌入模型,为所有文本单元、实体描述以及完整内容文本(社区标题 + 社区摘要 + 社区报告 + 排名 + 评分说明)生成嵌入向量。这些向量嵌入使得基于用户查询对图进行高效语义搜索成为可能,这在本地搜索和全局搜索中是必需的。
以上是本篇的全部内容,在下一次的文章中,我们将进入"查询"步骤,欢迎持续关注我们!