要看如何用 keras实现RNN,我们来看一个简单的例子 (只是为了理解keras实现 RNN然后通过Excel加深我们的理解): 分类两个句子 (只有有限的3个词)。通过这个例子,我们可以更快的理解输出:
from keras.preprocessing.text import one_hot
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers.recurrent import SimpleRNN
from keras.layers.embeddings import Embedding
from keras.layers import LSTM
import numpy as np
初始化文档并编码单词:
define documents
docs = 'very good','very bad'
define class labels
labels = 1,0
from collections import Counter
counts = Counter()
for i,review in enumerate(docs):
counts.update(review.split())
words = sorted(counts, key=counts.get, reverse=True)
vocab_size=len(words)
word_to_int = {word: i for i, word in enumerate(words, 1)}
encoded_docs = \[\]
for doc in docs:
encoded_docs.append(word_to_int\[word for word in doc.split()])
填充文档到最大长度2个单词---这是保持一致,以便所有的输入相同大小:
pad documents to a max length of 2 words
max_length = 2
padded_docs = pad_sequences(encoded_docs, maxlen=max_length, padding='pre')
print(padded_docs)

编译模型
SimpleRNN函数的输入形状应该是 (时间步数,每个时间步的特征数)。另外,通常RNN使用tanh激活函数。下面的代码指明输入的形状为(2,1)因为每一个输入基于两个时间步每一时间步只有一列特征。
unroll=True indicates that we are considering previous time steps:
define the model
embed_length=1
max_length=2
model = Sequential()
model.add(SimpleRNN(1,activation='tanh', return_sequences=False,recurrent_
initializer='Zeros',input_shape=(max_length,embed_length),unroll=True))
model.add(Dense(1, activation='sigmoid'))
compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics='acc')
summarize the model
print(model.summary())
SimpleRNN(1,) 表示隐藏层有一个神经元。 return_sequences
为 false因为我们不返回任何输出序列,它是简单的输出:

一旦模型被编译,我们继续拟合模型,如下 :
model.fit(padded_docs.reshape(2,2,1),np.array(labels).reshape(max_
length,1),epochs=500)
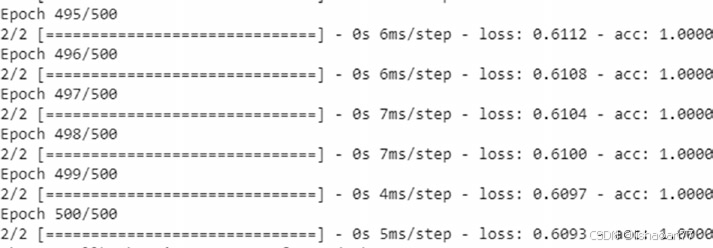
注意,我们已经改变形状 padded_docs。因为拟合进我们要转换训练数据集到如下格式: {data size, number of time steps,features per time step}。而且,标签应是数组形式,因为最后的全链接层希望输入数组。
核实RNN的输出
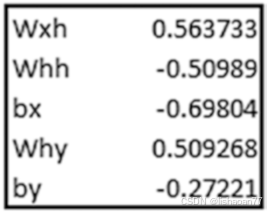
现在我们已经拟合了模型,我们用 Excel计算核实一下我们上面创建的模型。注意我们取输入为原始编码{1,2,3}---实践中我们没有取原始编码,而是独热编码或为输入创建Embeddings。我们取原始编码只是为了将keras输出与Excel手工计算比较。model.layers 指明模型中的层,且 weights给我们理解与模型相关的层:
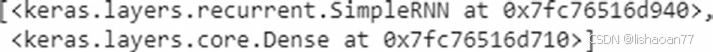
model.weights 指给我们模型里与权相关的名字:

model.get_weights() 给了我们模型里的权的值:
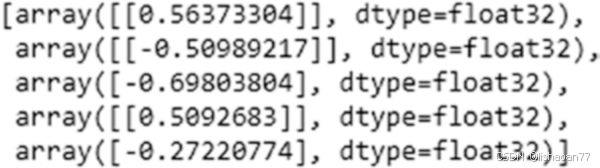
注意,权是有顺序的,即第一个权值对应于kernel:0。换句话,它与 wxh一样 , wxh是与输入相关的权*。*
recurrent_kernel:0 与 whh一样,是前一时间步隐藏层与当前时间步隐藏层相关的权。 bias:0 是与输入相关的偏置。dense_2/kernel:0 是why---即,隐藏层与输出层相关的权。 dense_2/bias:0 是隐藏层与输出层相关的偏置。我们为输入1,3证实一下预测:
padded_docs0.reshape(1,2,1)
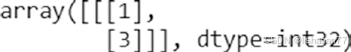
import numpy as np
model.predict(padded_docs0.reshape(1,2,1))
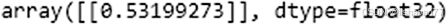
因为输入1,3的预测是0.53199,我们用 Excel证实一下相同的结果 :
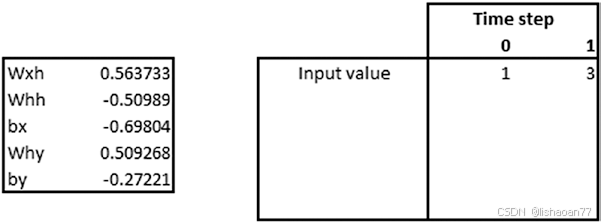
两个时间步的输入值如下:
输入和权的矩阵乘计算如下:
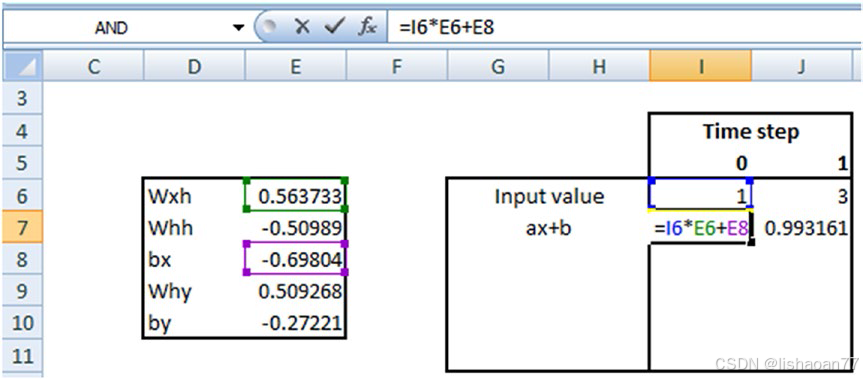
现在计算完矩阵乘,我们计算时间步0的隐藏层的值:

时间步1的隐藏层的值计算如下 :
tanh(时间步1的隐藏层的值× 与隐藏层相关的权重 (whh) + 上一隐藏层的值 )
我们先计算tanh函数的内部:

我们计算时间步1最后隐藏层的值:
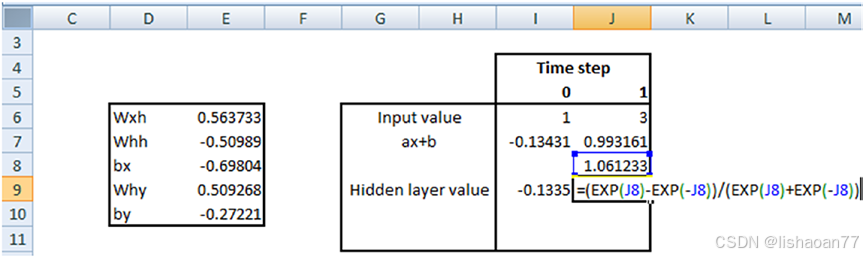
一旦计算了最后隐藏层的值,把它传给sigmoid层,所以最后输出计算如下:
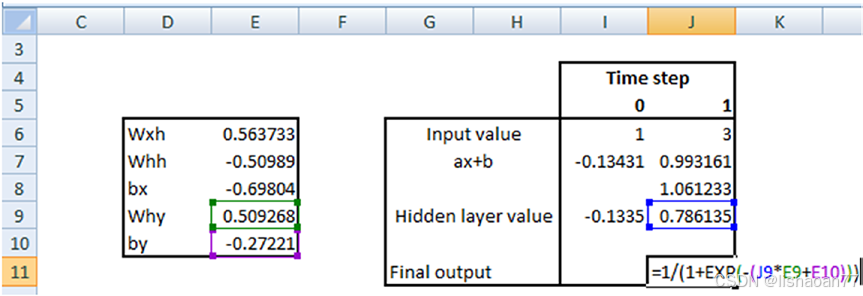
从Excel得到的最后输出与 keras的输出一样,所以证实了我们前面的公式:
