编者按: 我们今天为大家带来的这篇文章,作者提出:推动 AI 进步的核心动力不是算法创新,而是新数据源的解锁与规模化应用。
文章深入剖析了 AI 发展史上的四次重大突破 ------ 深度神经网络、Transformer + LLMs、RLHF 和推理能力的产生,揭示了每次技术跃进背后都对应着一个全新数据源的发现:从 ImageNet 图像数据库、互联网文本语料,到人类反馈标注,再到验证器数据。作者指出,这些看似革命性的技术创新,本质上都是基于监督学习和强化学习这两种在 1990 年代就已成熟的训练方法。文章还预测了下一次 AI 范式转变的可能方向 ------ YouTube 视频数据和机器人具身数据,为我们理解 AI 发展规律提供了全新的思维框架。
作者 | Jack Morris
编译 | 岳扬
大多数人都知道,AI 在过去十五年里取得了难以置信的进步 ------ 尤其是在最近的五年内。我们可能会觉得这种进步势不可挡 ------ 尽管重大的范式转变级突破并不常见,但我们依然在通过缓慢而稳健的进步继续前进。一些研究者最近提出了一种"AI 界的摩尔定律1",即计算机执行特定任务(此例中,指某些编码类任务)的能力随时间呈指数级的提升:
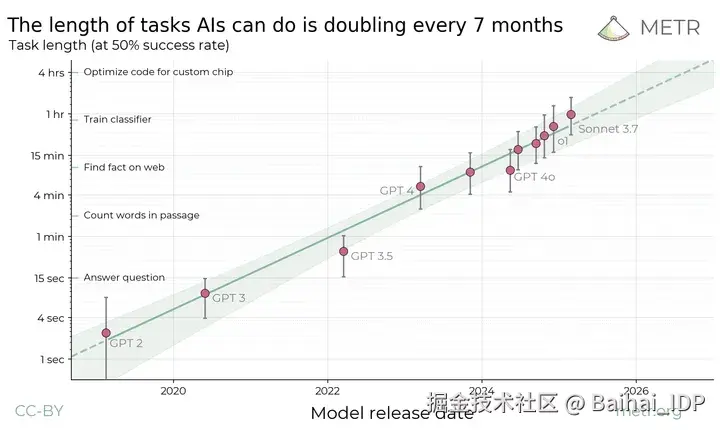
提出的"AI 摩尔定律"。(顺便说一句,任何认为在 2025 年 4 月就能让 Autonomous Agent 在没有人工干预的情况下运行一小时的人,都是在自欺欺人)
尽管出于种种原因,我并不认同这种具体的框架,但我无法否认进步的趋势。每一年,我们的 AI 都变得更聪明一点、更快一点、更便宜一点,而且看不到尽头。
大多数人认为,这种持续进步源于学术界(主要是 MIT、Stanford、CMU)和工业界(主要是 Meta、Google 及一些中国实验室)源源不断的创意供给 ------ 当然还有大量其他机构的研究成果我们无从知晓。
这些研究确实推动了行业的进步,尤其在系统架构/工程实现层面。这也正是模型成本得以不断降低的关键。让我精选近年来的几个典型案例:
- 2022 年斯坦福大学的研究者贡献了 FlashAttention2,这种提升语言模型内存利用率的方法如今已被广泛应用;
- 2023 年谷歌研究人员开发了 speculative decoding3,所有模型提供商都用它来加快推理速度(类似的技术也出现在 DeepMind4,据说是同期成果?)
- 2024 年,由一群网络极客组成的杂牌军打造出 Muon5,似乎是比 SGD 或 Adam 更好的优化器,或将成为未来语言模型训练的新标准
- 2025 年 DeepSeek 开源 DeepSeek-R16,其推理能力媲美顶尖闭源模型(特指 Google 与 OpenAI 产品)
所以,人类确实在不断探索突破。而现实情况比这更酷:我们正参与一场去中心化的全球科学实践,研究成果通过 ArXiv7、学术会议和社交媒体公开共享,人类智慧正逐月累进。
既然我们正在进行这么多重要的研究,为何有人会声称 AI 的进展放缓了?抱怨声依然不断8。最近发布的两大模型(Grok 39 与 GPT-4.510)与之前的模型相比,能力仅有微弱提升。举一个典型案例,语言模型参加最新的数学奥林匹克测试时11,得分率仅为 5%,表明近期宣传的系统能力恐有夸大之嫌12。
如果我们试图记录那些大的突破,那些真正的范式转变,它们似乎是以不同的速度发生的。让我列举几个我想到的例子。
01 LLMs 的四大突破
1)深度神经网络:在 2012 年 AlexNet13 赢得图像识别竞赛后,深度神经网络首次爆发
2)Transformers + LLMs:2017 年谷歌在《Attention Is All You Need》14提出 transformers,催生了 BERT15(Google, 2018)与初代 GPT16(OpenAI, 2018)
3)RLHF:据我所知,OpenAI 的 InstructGPT 论文17在 2022 年被首次提出
4)推理能力:2024 年 OpenAI 发布 O1,继而催生 DeepSeek-R1
粗略来看,这四大突破(DNNs → Transformer LMs → RLHF → Reasoning)几乎概括了 AI 发展的全貌。我们经历了 DNNs(主要是图像识别)、文本分类器、chatbot,现在又有了推理模型(不管它是什么)。
若想实现第五次突破,研究这些案例可能会有所帮助:究竟是什么新的研究思路促成了这些突破性事件?
认为这些突破的所有底层机制在 1990 年代(甚至更早)就已存在并非无稽之谈。我们只是在应用相对简单的神经网络架构,进行两种训练:监督学习(突破 1 和 2)或强化学习(突破 3 和 4)。
基于交叉熵(cross-entropy)的监督学习是当前预训练语言模型的主要方法,这一技术可追溯至 1940 年代 Claude Shannon 的研究。
用于 RLHF 和推理训练的强化学习是对语言模型进行后训练的主要方式,它的出现时间略晚些。其源头可追溯至 1992 年策略梯度方法(policy-gradient methods)的提出18(相关思想必然已出现在 1998 年 Sutton & Barto 编写的《Reinforcement Learning》初版教材中)。
02 若理论基础皆非创新,突破性进展的本质是什么?
我们不妨先达成共识:这些"重大突破"实则是既有知识的创新应用。首先,这告诉我们一些关于下一个突破性进展(即前文所述的"神秘的第五次突破")的信息。我们的突破不太可能源自一个全新的理论,而应是我们早已熟知的事物的再次出现。
但是,这里还缺少一个环节,这四项突破中的每一项都使我们能够从新的数据源中学习:
1)AlexNet 及其后续模型:解锁了 ImageNet19(标注了类别标签的大型图像数据库),推动了计算机视觉十五年的进步。
2)Transformers:开启了在"互联网"上的训练,以及下载、分类和解析网络上所有文本20的竞赛(当前基本完成21)。
3)RLHF:使模型能从人类标注信息中学习"优质文本"的标准(主要是学习一种感觉)。
4)推理能力:让模型能够通过"验证器22"学习 ------ 比如可以评估语言模型输出的计算器和编译器。
请记住,每一个里程碑都标志着对应数据源(ImageNet、全网文本、人类反馈、验证器)首次实现规模化应用。 每一个里程碑之后,都会掀起一场研究热潮:研究人员们争相(a)从所有可用的数据来源中榨取剩余的有效数据;(b)通过新技巧提升数据的利用效率,使系统更高效、对数据的需求更低(预计 2025-2026 年我们将见证推理模型领域的此类竞赛 ------ 研究人员争相对可验证的内容进行发掘、分类和验证)。

自我们构建 ImageNet19(当时最大的网络图像公共数据集)起,AI 的发展之势便已势不可挡。
03 新 ideas 究竟有多重要?
我们必须要承认:那些实际的技术创新在这些案例中可能并非决定性因素。 设想一下这种不符合事实的场景:若 AlexNet 未曾诞生,也许就会出现另一种可以处理 ImageNet 的架构。若 Transformers 未被发现,我们或将继续使用 LSTMs/SSMs,或者找到其他完全不同的东西来学习我们能在网上获得的大量有用的训练数据。
这与"唯数据论"不谋而合 ------ 一些研究人员注意到,相较于训练技术、模型优化技巧和超参调整方法,数据才是能带来最大变化的变量。
有这么一个典型案例,研究人员尝试用不同于 transformer 的架构开发类 BERT 模型23。他们花了一年左右的时间,以数百种不同的方式对架构进行了调整,最终成功开发出了一种不同类型的模型(这是一种状态空间模型/"SSM"),在相同的数据上进行训练时,它的表现与原始的 transformer 大致相当。
这一发现意义深远,因为它暗示我们从给定数据集中学到的东西是有上限的。世界上的所有训练技巧与模型升级,都无法绕过一个冷酷的事实:你能从给定数据集中学到的东西是有限的。
或许这正是《苦涩的教训》24的核心启示:如果数据是唯一重要的东西,为什么 95% 的人都在研究新方法?
04 下一次范式转变将从何而来?(YouTube...或许?)
显而易见,我们的下一次范式转变不会来自对 RL 的改进或一种新型神经网络。它将会出现在我们解锁一个我们以前从未接触过或尚未妥善利用的数据源时。
当前大家集中攻关的数据来源就是视频数据。某网站数据25显示,YouTube 每分钟上传约 500 小时的视频数据。视频数据规模远超全网文本的总量,且信息维度更丰富:视频数据中不仅包含语音文本,还有语气变化以及丰富的物理和文化信息 ------ 这些都是无法从文本中收集到的。
可以肯定的是,只要我们的模型足够高效,或者我们的算力足够强大,谷歌就会开始在 YouTube 数据上训练模型。毕竟坐拥丰富资源却闲置不用,实属暴殄天物。
人工智能下一个"大范式"的最后一个竞争者是具身数据采集系统(大众称之为机器人)。 目前,我们还无法以适合在 GPU 上训练大型模型的方式收集和处理来自摄像头和传感器的信息。如果我们能开发更智能的传感器,或将算力提升到能够轻松处理机器人的海量数据流,或许将开辟一种全新的应用场景。
YouTube、机器人抑或是其他领域是否会成为 AI 技术的下一站?语言模型目前虽占据主流,但我们似乎也很快就会耗尽语言数据。如果我们想在人工智能领域寻求下一次突破,或许我们应该停止追逐新理论,转而开始寻找新数据源。
END
本期互动内容 🍻
❓文章预测 YouTube 视频或机器人数据是下一个 AI 范式转变的来源。抛开这两项,你认为还有哪些未被充分利用或极具潜力的"新数据源" 能带来 AI 的下一次飞跃?
文中链接
5kellerjordan.github.io/posts/muon/
8www.lesswrong.com/posts/4mvph...
12cdn.openai.com/o1-system-c...
13www.notion.so/There-Are-N...
16cdn.openai.com/research-co...
18people.cs.umass.edu/~barto/cour...
19https//www.image-net.org/
21www.lesswrong.com/posts/6Fpvc...
22incompleteideas.net/IncIdeas/Ke...
24www.incompleteideas.net/IncIdeas/Bi...
25www.dexerto.com/entertainme...
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接: