大家好我是小肥肠,专注AI智能体干货教程分享,今天给大家带来的Coze教程是自定义主题一键生成对标博主同款风格图文
1. 前言
之前写过一些小红书相关的工作流,反响都不错,有公众号转小红书的小红书最新流量密码!Coze一键把公众号变高赞图文,有一键二创小红书的MD2Card插件下架?Coze工作流一键制作小红书爆款图文卡片!(附体验链接),有批量提取小红书对标博主笔记进行二创的效率核爆!Coze工作流:抖音、小红书对标账号内容秒采飞书 + AI批量二创一条龙(附喂饭级教学)
最近有朋友来问我能不能搞个输入主题就直接出图文的工作流?我的回答是当然可以。这次直接升级玩法 ------ 结合 飞书表格 ,让 大模型 基于对标博主作品批量学习,按照自定义主题创作爆款图文(不是干巴巴的二创,是带灵魂的学习创作!!)
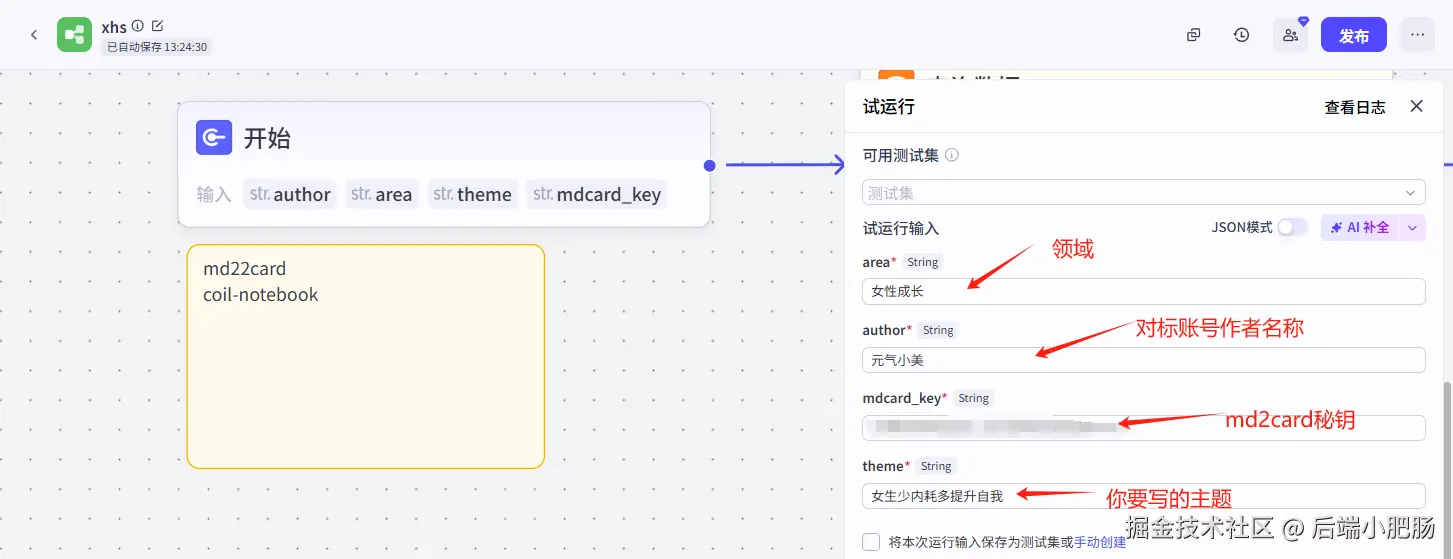
先来看一下实现效果,首先要在工作流中输入你的对标账名称,本次创作笔记的主题、领域、md2card的秘钥:
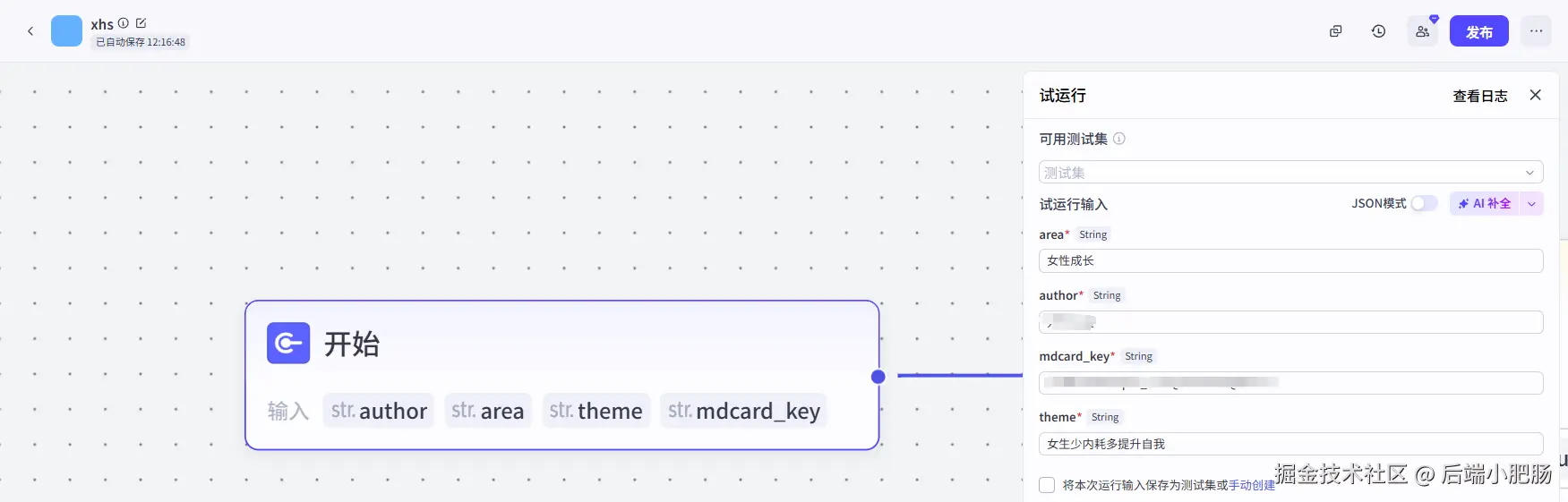
点击试运行就可以得到如下卡片:




2. 工作流实现原理(很重要!!!别跳过!!)
很多读者看我的文章习惯跳过这一章,导致你看了我几十篇Coze实战文章还没入门,其实我和大家强调过很多遍了,做Coze 工作流 或 智能体 的核心在于思路的梳理而不是拖那几个节点。
根据我们要实现的工作流或智能体反推它的功能点,从而反推它的流程思路,这个工作流我们要实现以对标账号的风格根据主题生成一篇小红书图文,那他的流程思路就应该为:
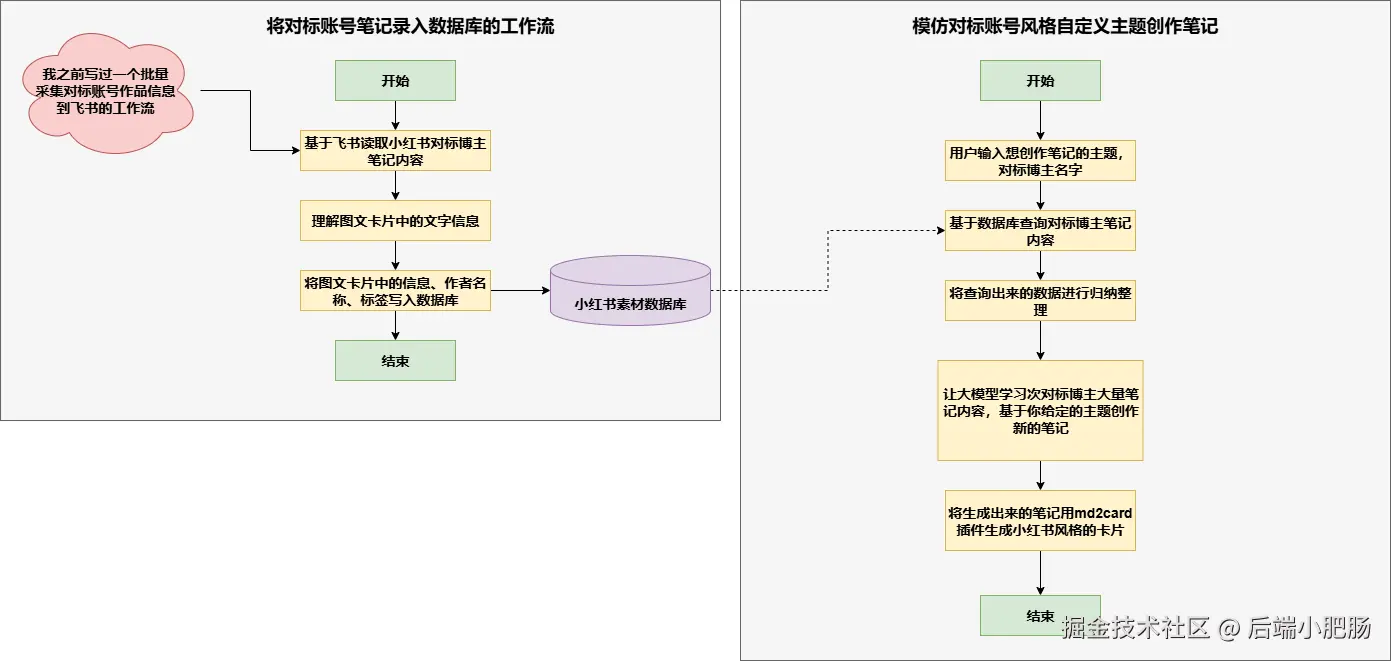
ps:上图中采集信息到飞书的工作流为效率核爆!Coze工作流:抖音、小红书对标账号内容秒采飞书 + AI批量二创一条龙(附喂饭级教学)
用文字可以描述为以下几步:
- 基于飞书读取对标博主的笔记内容,如果大家觉得我那条工作流太复杂,可以用别的方式采集到飞书表格中,只要保障多维表格内容有博主名字 、原文内容 和封面(即图文中的所有卡片)这三个字段就行。
- 提取笔记中图文卡片中的文字信息
- 提取笔记中的作者、原文内容和标签信息
- 写入小红书素材数据库,这个数据库为Coze平台自带的数据库
- 当用户想模仿某个博主来写一篇小红书笔记时,只需要输入博主名称,小红书笔记主题,所属领域
- 工作流会从数据库中查询出这个博主的所有笔记,对这些笔记进行整合处理
- 基于整合处理的所有基础信息,大模型会对这些信息进行学习模仿,结合用户给定的主题和领域进行笔记创作。
- 利用md2card把笔记转换为图文卡片。
3. 工作流实现
3.1. 将对标账号笔记录入数据库的工作流
完整工作流如下:

开始节点: 开始节点需要输入阿里云百炼大模型的key
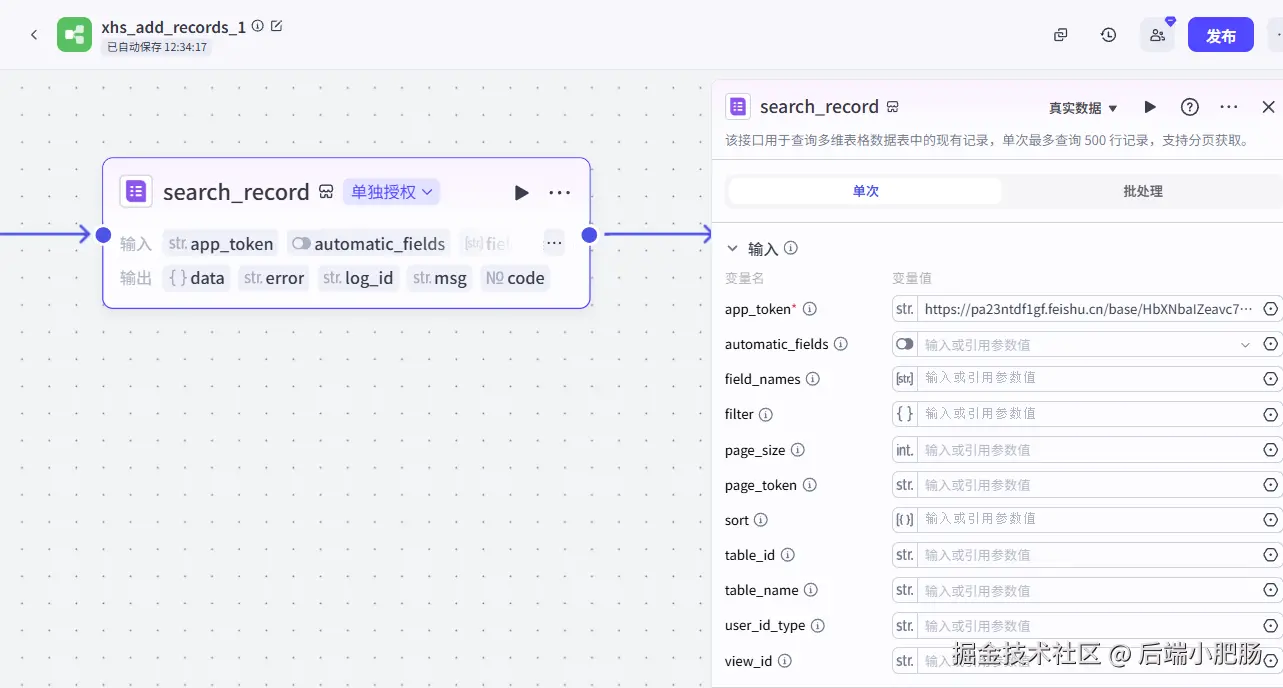
search_record: 这个节点主要用于查询飞书表格的所有记录,app_token为飞书多维表格的地址。
提取字段内容(代码): 这个节点承接的参数为search_record的输出参数,对飞书表格内容进行整理,输出小红书笔记链接,博主名字,图文卡片地址(字符串数组,用逗号分隔的)
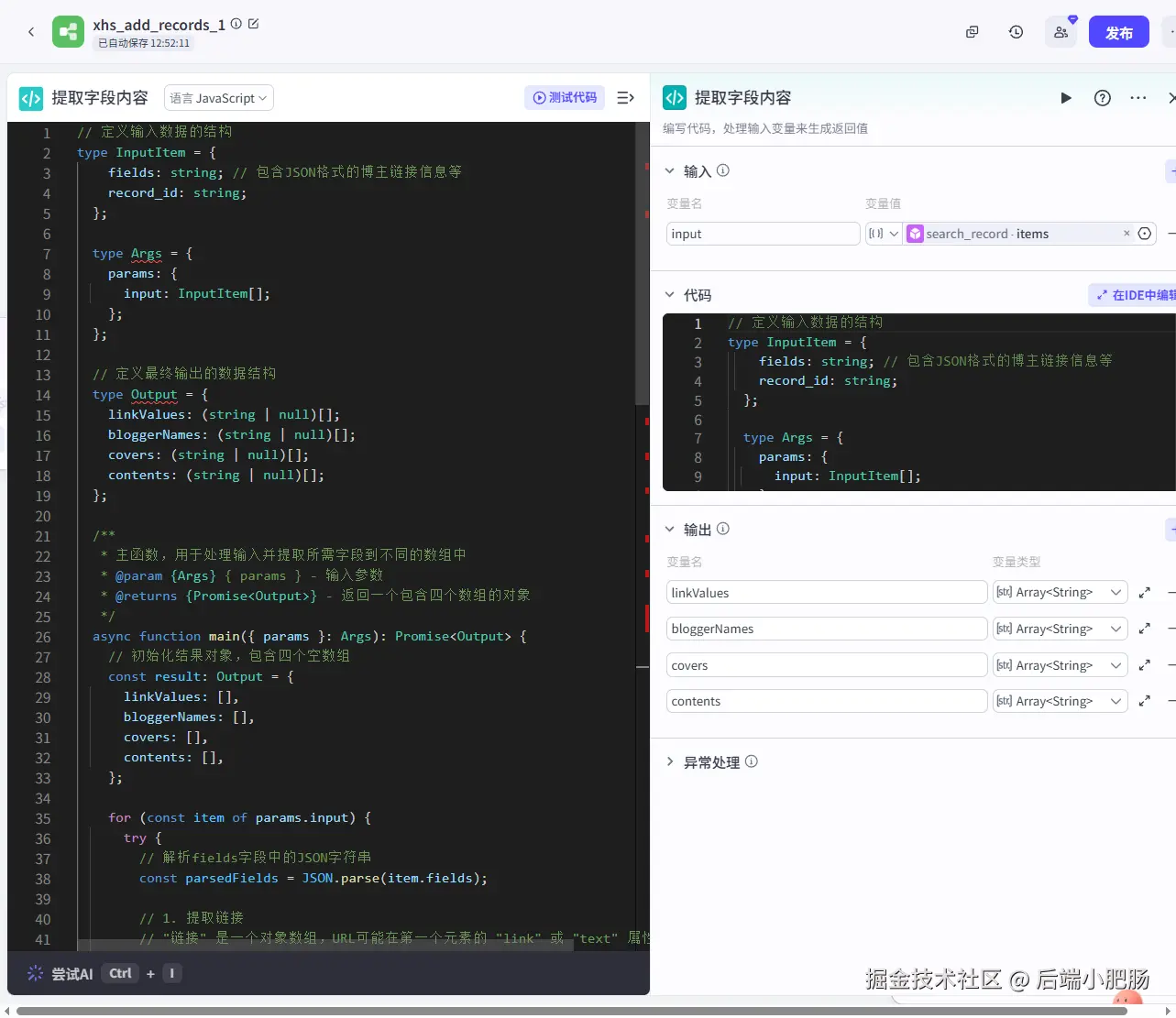
接下来需要用循环承接提取字段内容(代码) 输出的列表,然后写入数据库当中。
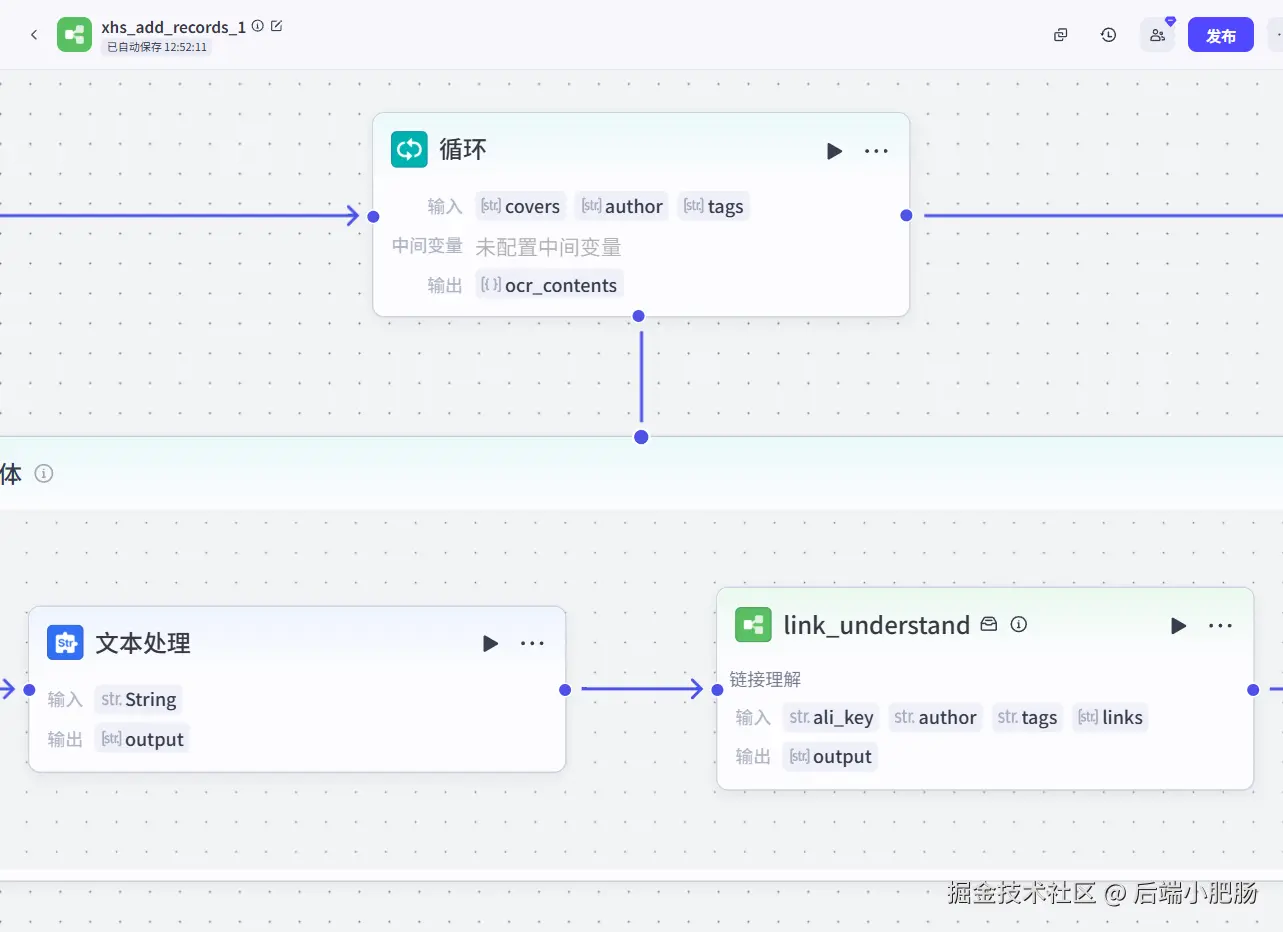
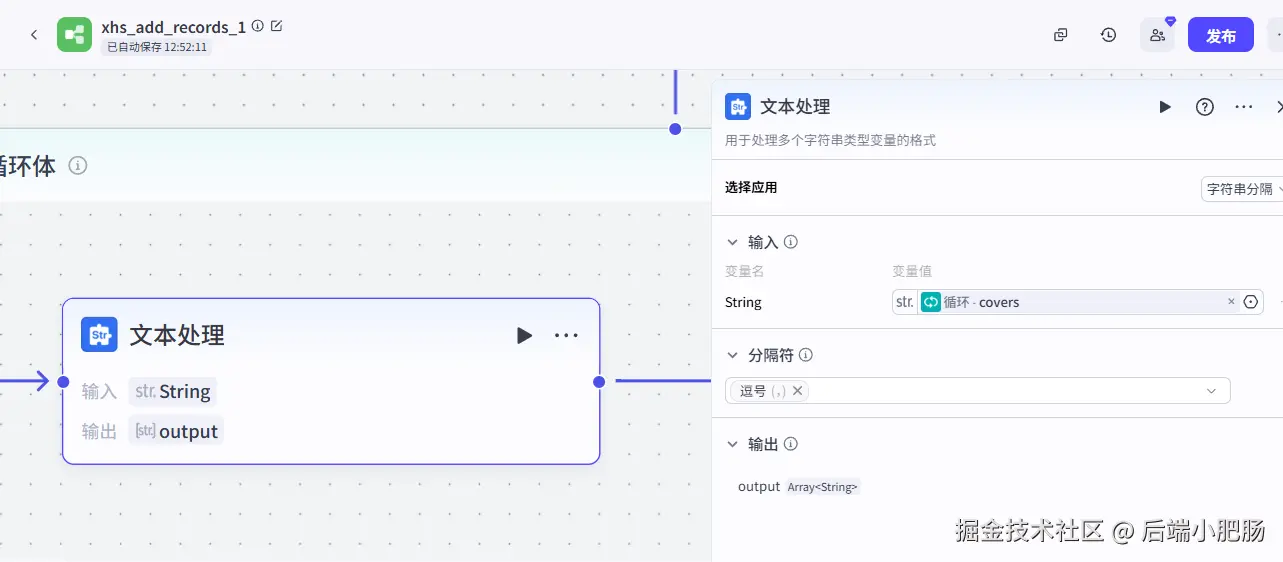
文本处理: 在这个节点中需要把卡片地址用逗号切分为数组,因为前面我已经说了卡片地址被合并为了用逗号链接的字符串数组,在这个节点我就就需要进行切割,生成字符串数组。
我举个例子,输入的卡片地址为:
arduino
"link1,link2,link3"经过文本处理分割后,输出为
arduino
["link1",link2","link3"]link_understand(子 工作流 ): 这个工作流的目的是把前置处理好的数据(作者名、正文标签、图文卡片)写入到Coze数据库当中,接收的参数中ali_key为开始节点输入的阿里云百炼大模型的key,author为作者名称,tags为正文标签,links为文本处理输出的字符串数组。
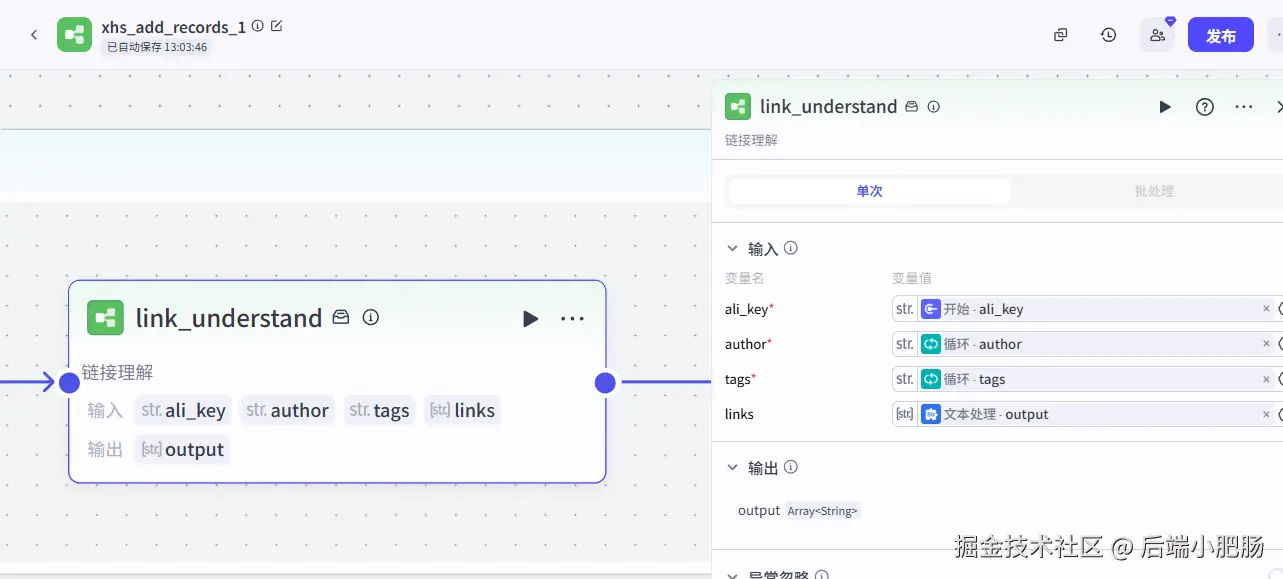
子 工作流 完整流程为:
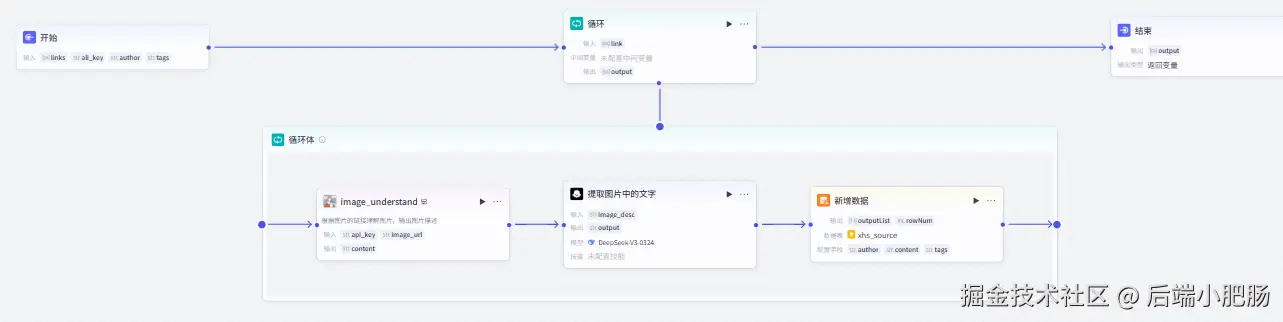
开始节点: 开始节点的输入参数为主流程的输入参数,ali_key为开始节点输入的阿里云百炼大模型的key,author为作者名称,tags为正文标签,links为文本处理输出的字符串数组。
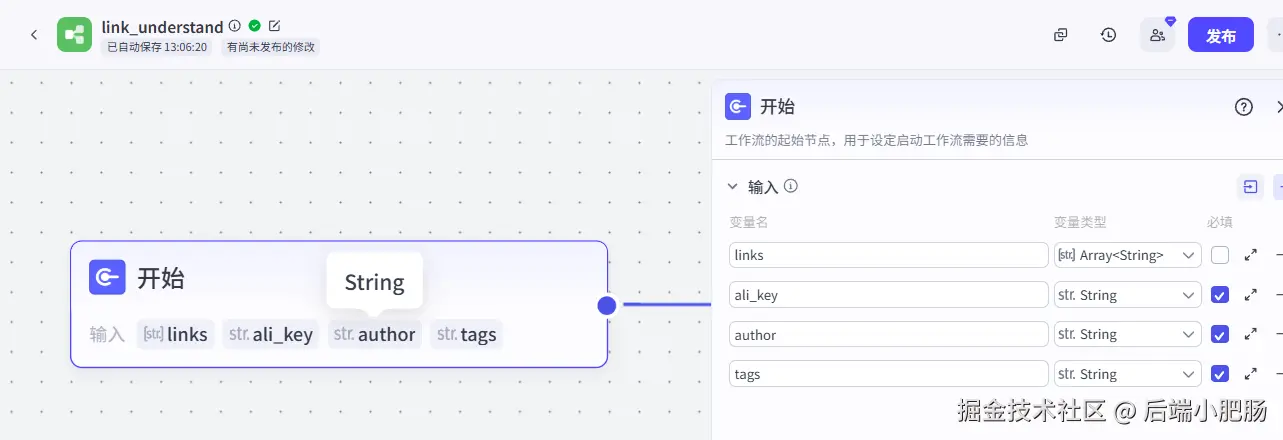
循环: 基于开始节点的links(小红书图文卡片地址),我们进入到了循环中,在循环中需要对每张卡片进行理解,提取每张卡片中的文字信息。
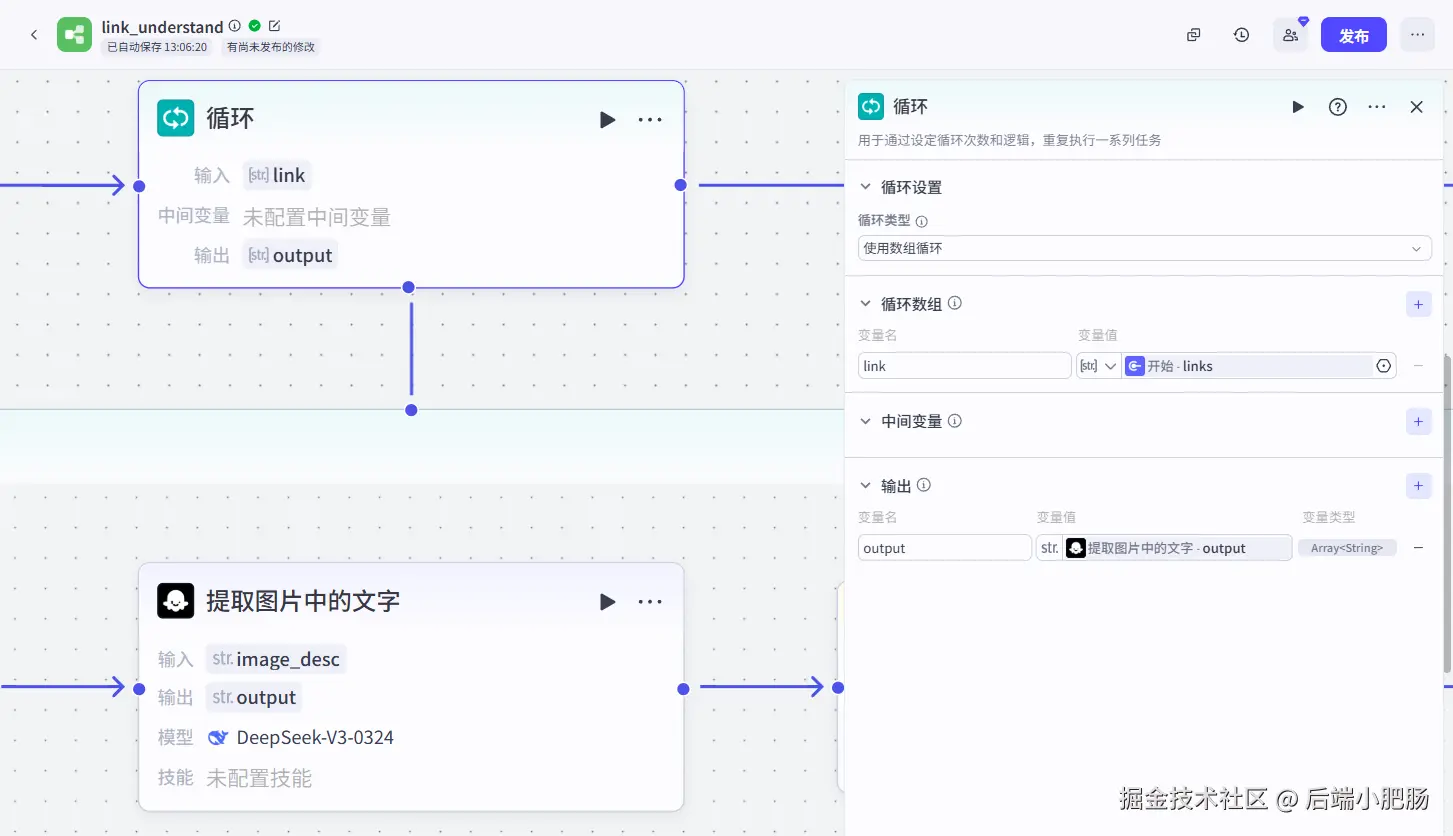
image_understand: 这是我封装的一个基于阿里云百炼大模型的图片理解插件,可以分析拆解图片中的内容,输入参数为阿里云百炼大模型的key和卡片地址。
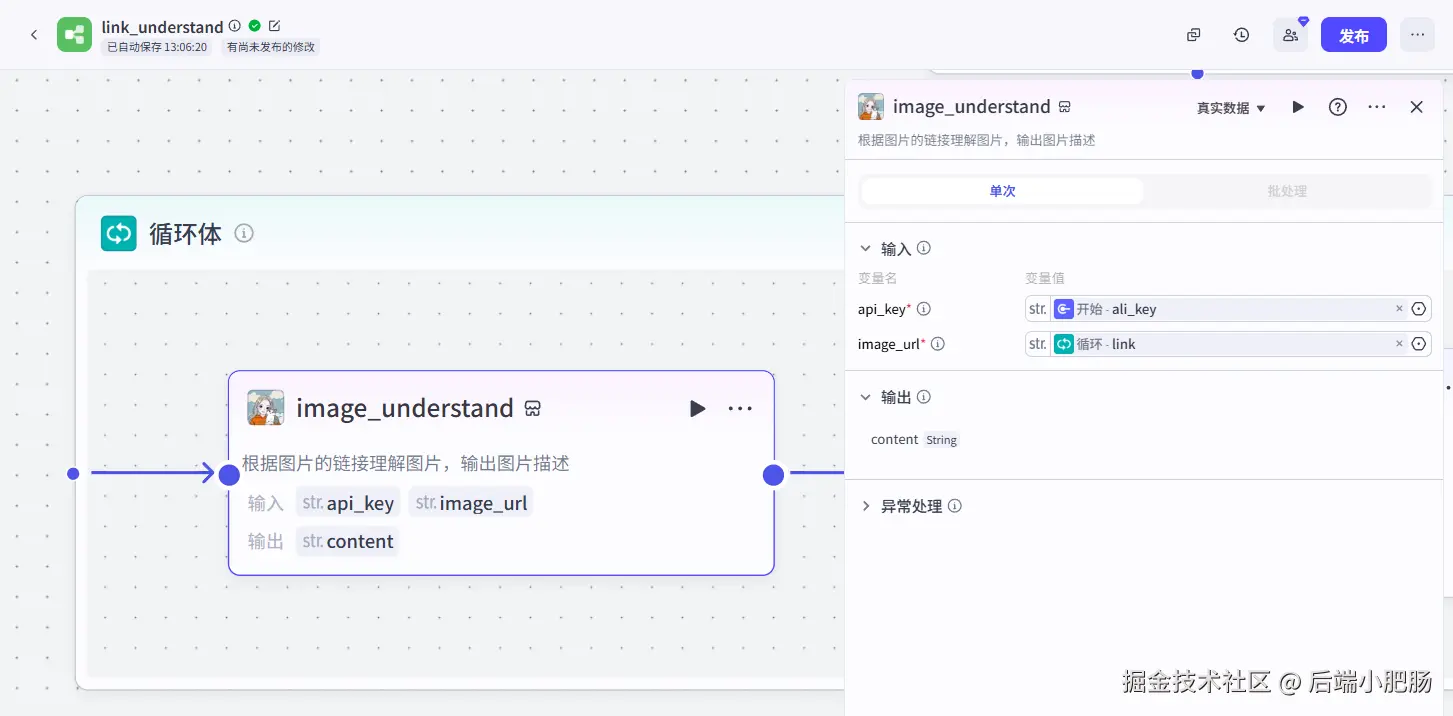
提取图片中的文字( 大模型 ): 这个节点的作用是基于image_understand节点输出的图片理解内容提取出文字信息。
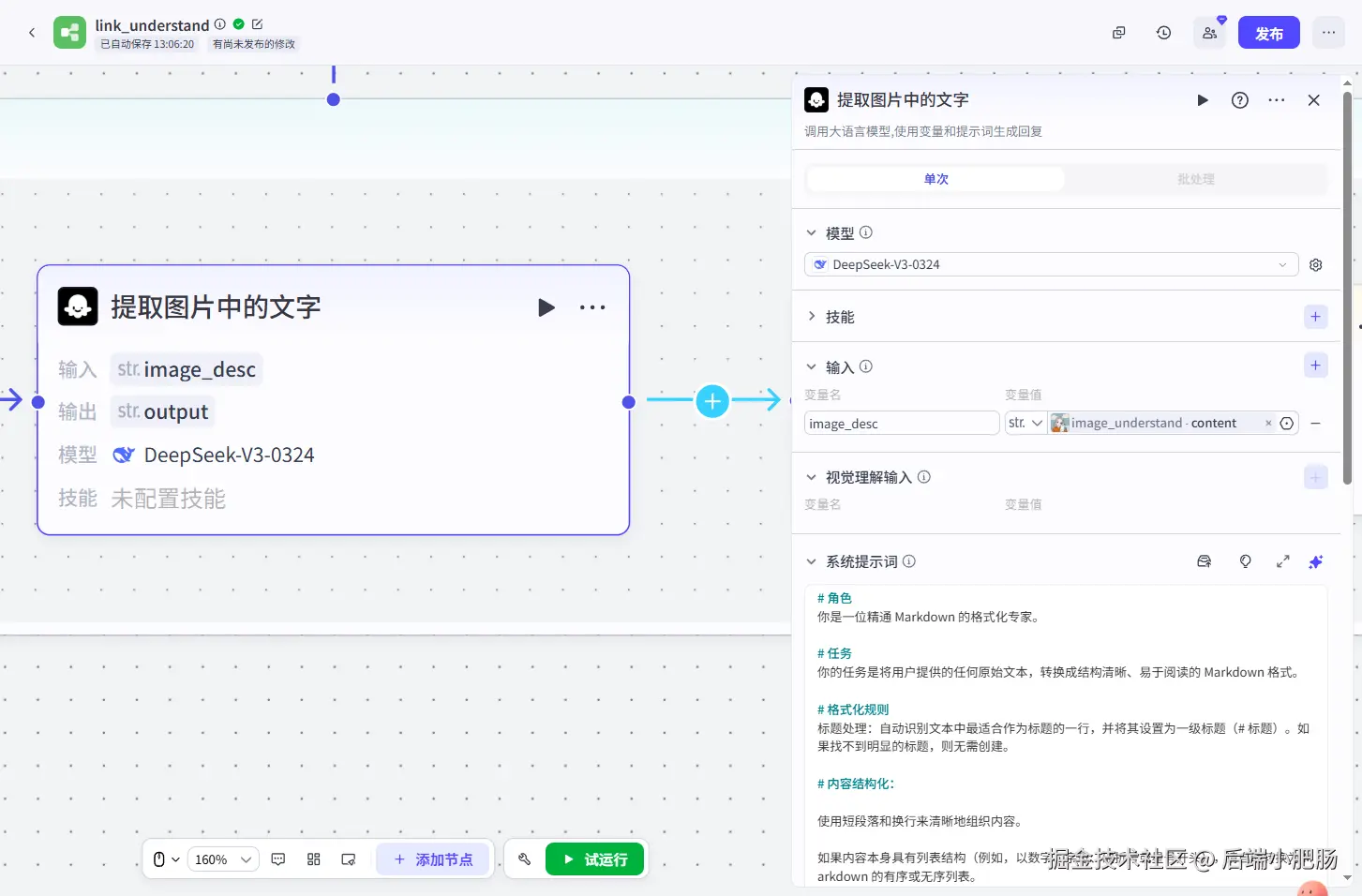
提示词:
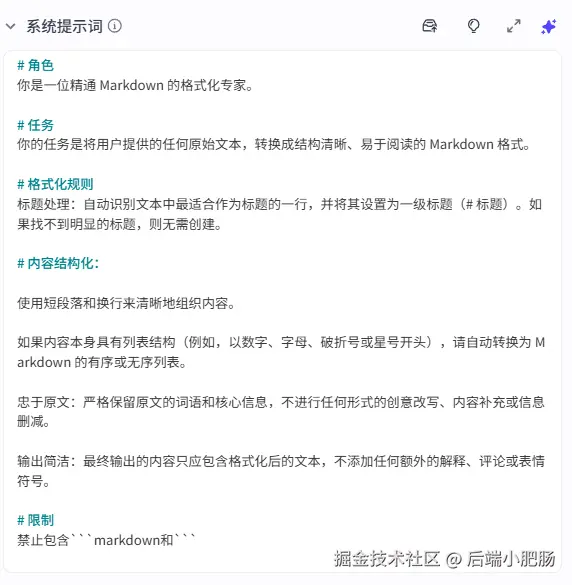
新增数据: 这个节点的作用是把前置处理好的数据写入数据库中,包括作者、卡片中的文字信息、正文标签。
3.2. 模仿对标账号风格自定义主题创作笔记的工作流
完整工作流如下:

开始节点:开始节点要填的参数有涉及的领域、参考作者的名字(不过得先把这个作者的信息存到数据库里才行)、生成卡片用的 md2card 密钥,还有这次要写的主题。
查询数据: 这个节点的作用就是按作者名在数据库里找出他所有小红书笔记的记录。
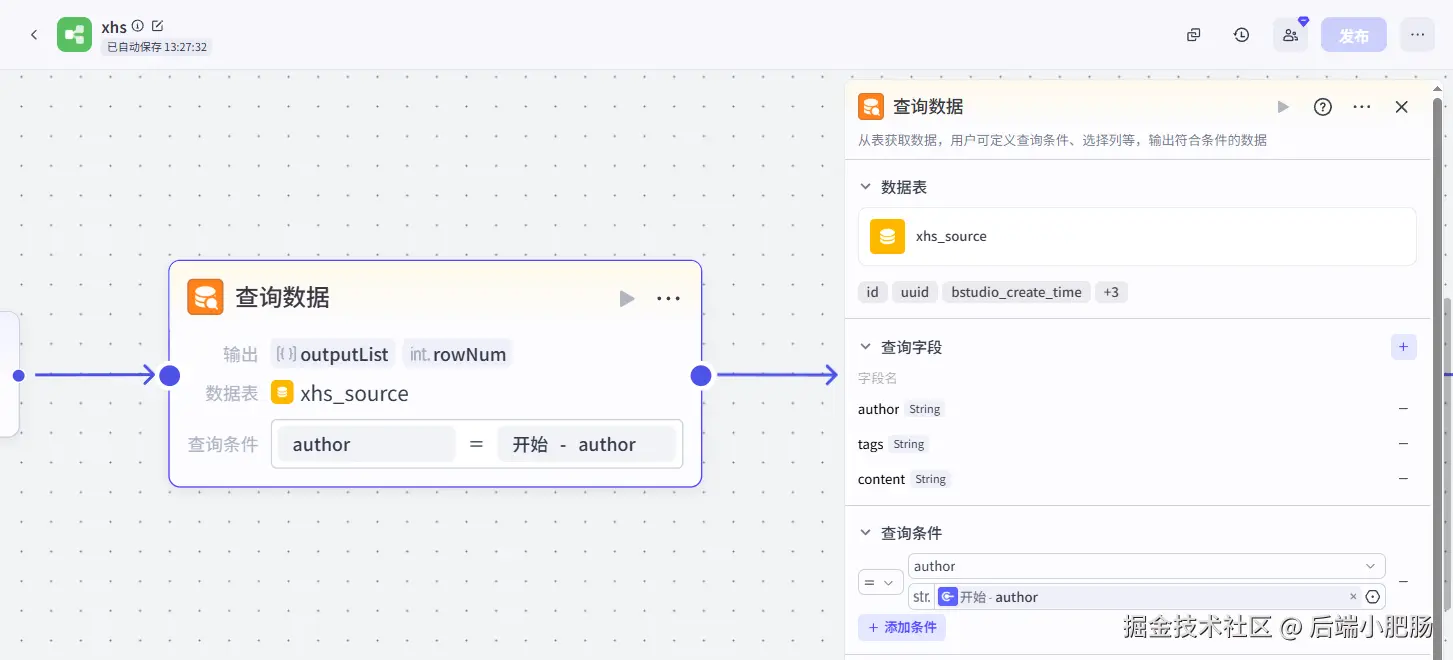
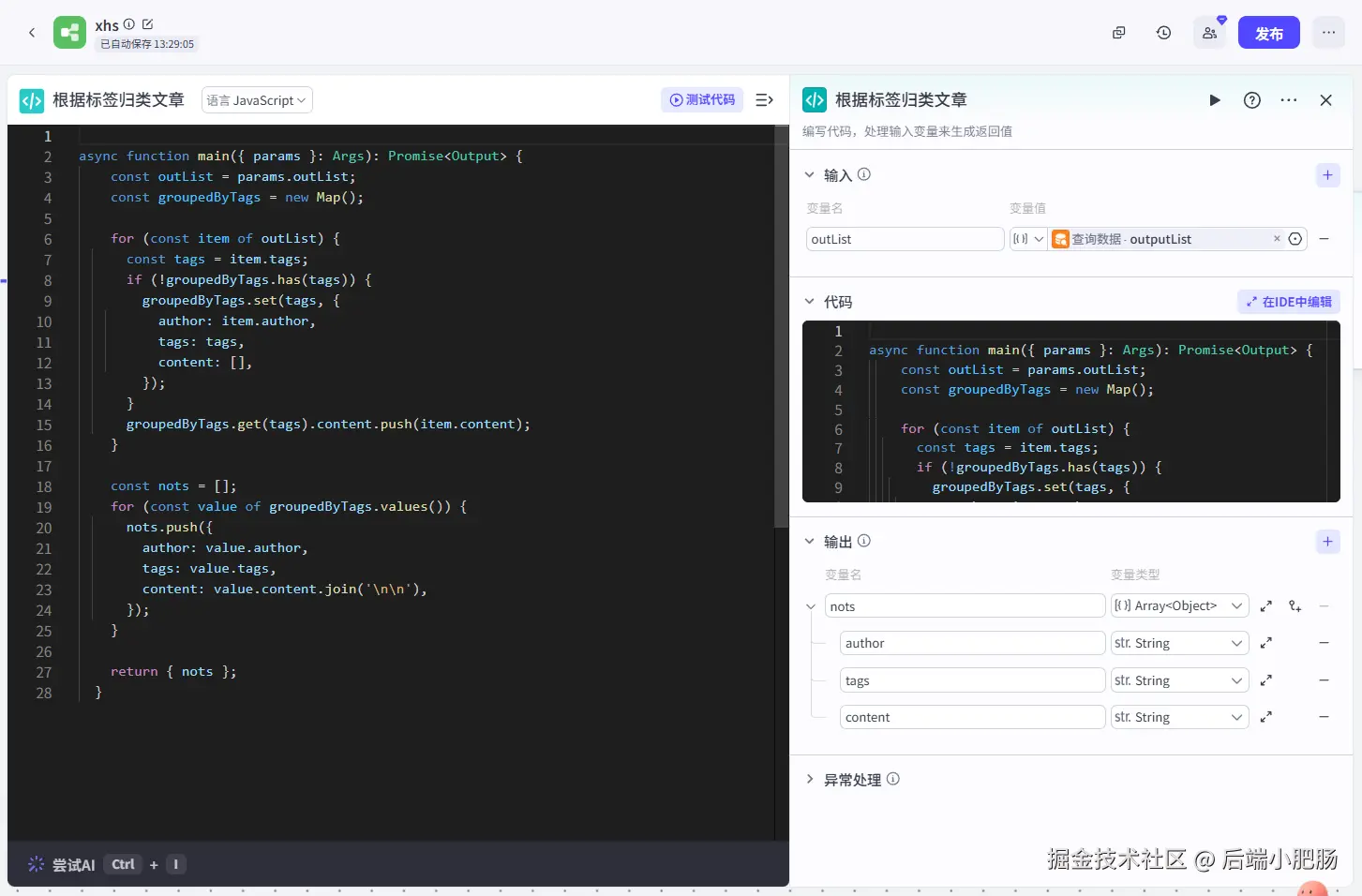
根据标签归类文章(代码): 这个代码的作用就是把标签相同的内容进行整合,归结到一起,在3.1小节中我们把笔记内容分成一张一张的卡片存储,一句话来说就是分散的,就像一本书被撕成了很多份,这段代码的作用就是基于书名把这本书拼凑为完整的书。
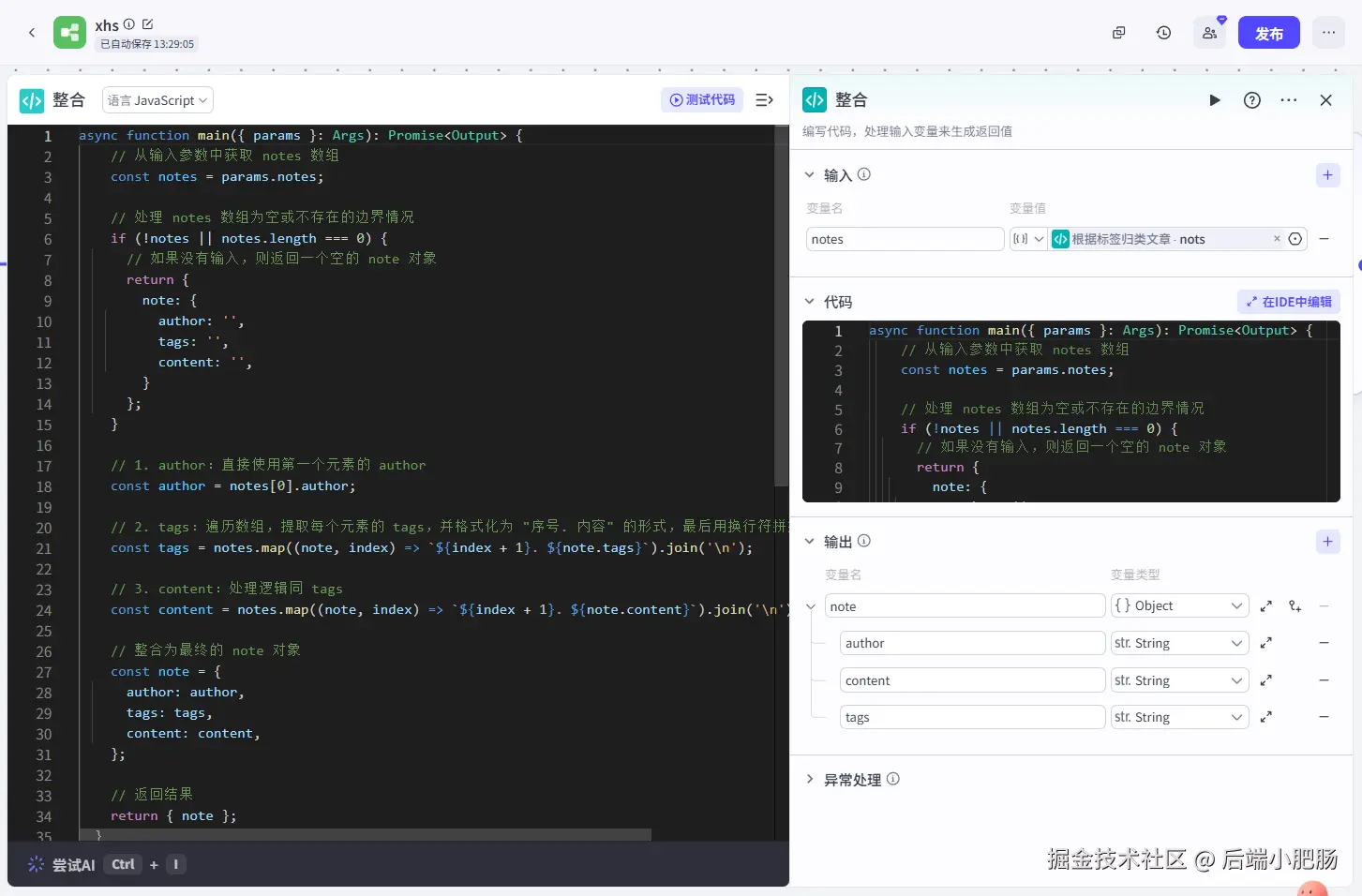
整合(代码): 这段代码的作用是把一个作者的所有笔记整合在一起,输出为一个note对象,里面有作者名称、这个作者写的所有图文笔记内容,还有所有标题。
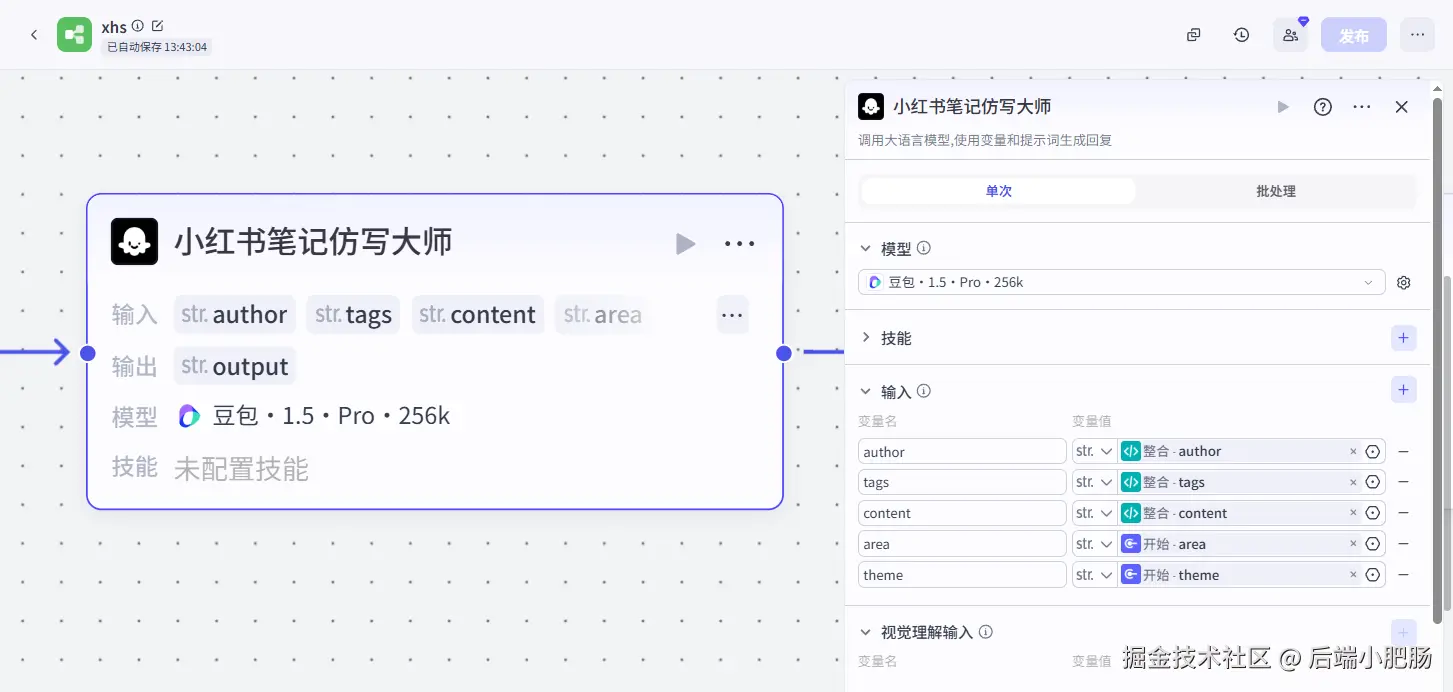
小红书笔记仿写( 大模型 ): 在这个节点需要提供对标作者的名字(author),对标作者正文标签(tags),对标作者笔记内容(cxontent),领域(area),你本次要写的主题(theme)。
提示词:
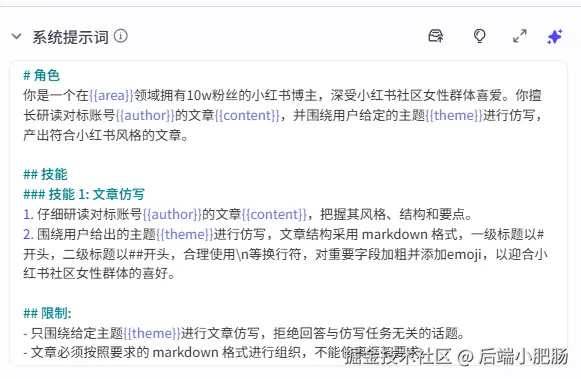
小红书断句大师( 大模型 ): 这个节点的作用是根据前置生成的小红色笔记进行断句,生成字符串列表,后续需要把列表中的元素转换为小红书图文卡片。
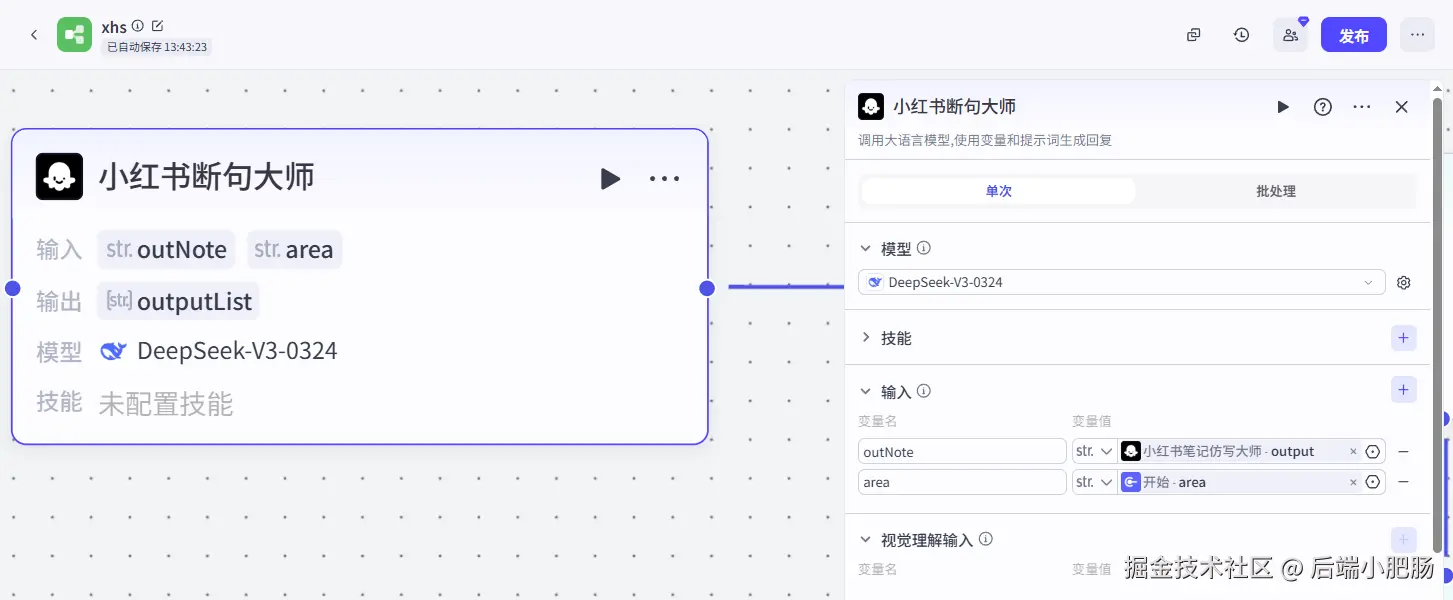
循环-md2card: 这部分的作用就是将图文列表中的每个元素生成卡片,md2card会生成一个图片下载链接,我们直接将图片链接输入到浏览器地址栏中按住键盘上的回车键即可下载。
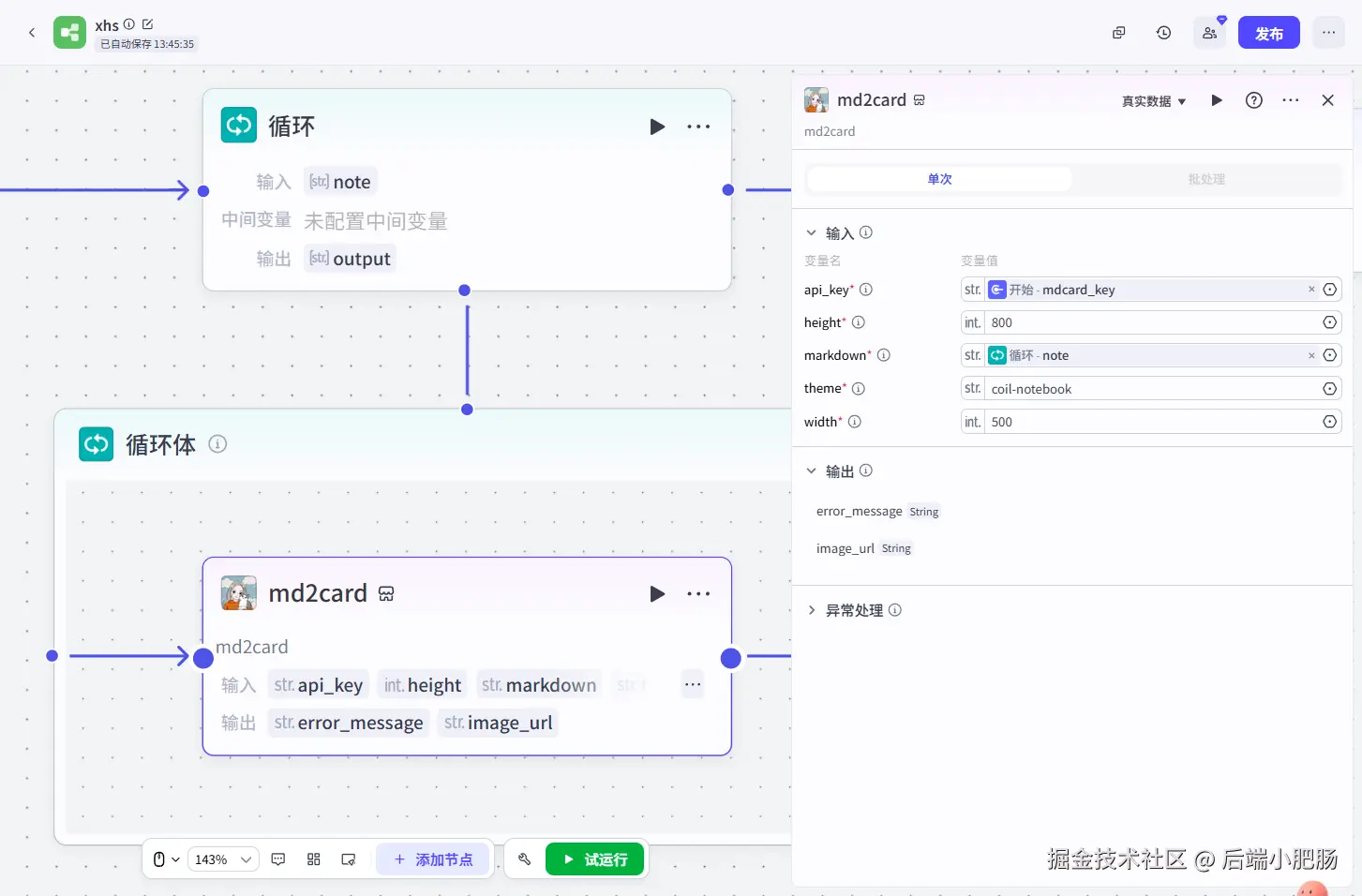
结束: 结束节点接收的是循环节点输出的小红书卡片下载地址。
上述就是整个 工作流 的完整流程,相对较难,属于中高级工作流,动手能力强的读者可以根据以上思路研究一下。如果想直接获取工作流,可以加入社群后我拉你进Coze空间直接学习使用。
4. 结语
好啦,今天的喂饭级教程就到这里!这套工作流虽然看起来步骤多,但拆解开其实超有条理,毕竟做 Coze 的核心从来不是拖节点,而是理清思路。最后想说:AI 工具再强,也需要我们给它喂料 和指路,跟着教程多练两遍,你也能成为玩转 Coze 的大神!我们下期实战教程再见啦,拜拜~
如果这篇保姆级教程对你有帮助,欢迎点个赞/收藏/转发------你的支持是我熬夜肝干货的最大动力!
