朋友圈有朋友问了,既然Coze可以本地部署,那我们平时在使用的各种大模型(例如:元宝、豆包、kimi等应用)是不是也可以本地部署呢?今天我来统一给大家解密。
其实大部分时候,大模型厂商都部署在各自的专属服务器集群上,我们每请求一次都是需要耗费GPU资源(比较昂贵)的,这也是为什么年初DeepSeek爆火之后一直"服务器繁忙"的原因。
那么我们本地能不能运行大模型呢?
答案是可以的。
只不过大模型要求配置比较高,通常我们个人电脑没有那么高的算力,大模型在发布的时候是分很多版本的,例如DeepSeek R1的7B、14B、32B、671B ,参数越高代表着机器需要的配置越高,高版本我们本地机器跑不起来,但是低版本是没有问题的。
今天我们就给大家演示下如何在本地安装部署大模型,这里以最新发布的Qwen3为举例说明。通过简单几步,把这个强大的"超级大脑"装进你自己的电脑,让它成为你专属的、完全免费的私人助理。
前提是需要装一个装载大模型的容器,今天我们就来聊一聊这个容器:Ollama。它让原本复杂的大模型部署,变得前所未有的简单。
接下来,就带你一步步揭开它的神秘面纱。
Ollama是什么?
大模型并不是像普通软件一样双击就能运行的可执行文件,它需要一个特定的环境或平台来支持它的运作,而Ollama恰好就是一个这样的平台,它是专门为大模型而设计的运行平台。可以把它想象成一个容器或数组。很多不同类型的大模型都能够在这个平台上运行。通过Ollama 我们可以更好的管理模型的输入和输出,让他接收用户的指令并且反馈结果。这样的话,我们就能够实现和大模型自然而流畅的对话了。
Ollama安装条件
硬件要求
最低配置: 8GB内存,支持CPU推理
推荐配置: 16GB以上内存,配备NVIDIA/AMD独立显卡(显存≥8GB)可启用GPU加速
存储空间: 至少20GB可用空间(具体需求根据模型大小调整,如70B参数模型需要40GB以上)
软件环境
操作系统: Windows 10及以上版本
安装包: 需从官网下载OllamaSetup.exe(约1GB大小)
网络条件: 建议稳定网络环境(官网下载速度可能较慢)
Ollama如何安装
下载地址: ollama.com/download/wi...
选择对应系统版本安装包
下载好的OllamaSetup.exe 直接双击安装,等待两三分钟。
验证是否安装成功
进入cmd命令行
Ctrl + R
css
ollama --version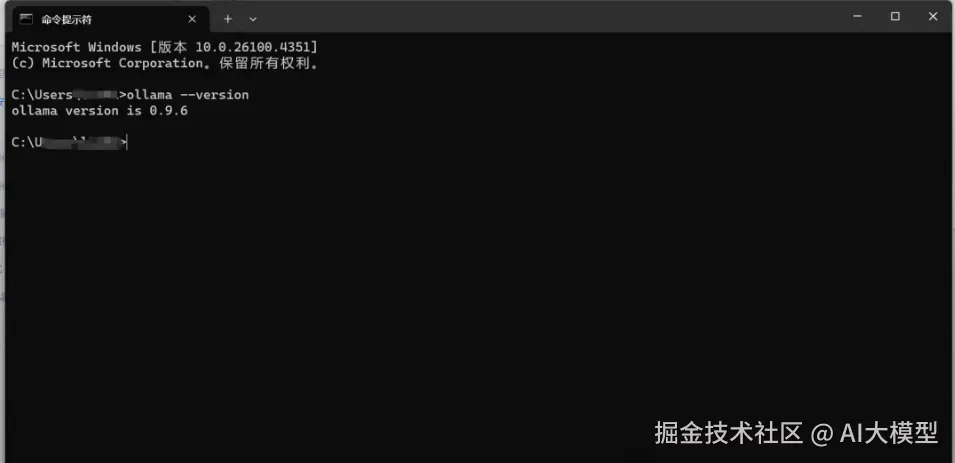
搜索对应的模型,例如qwen3
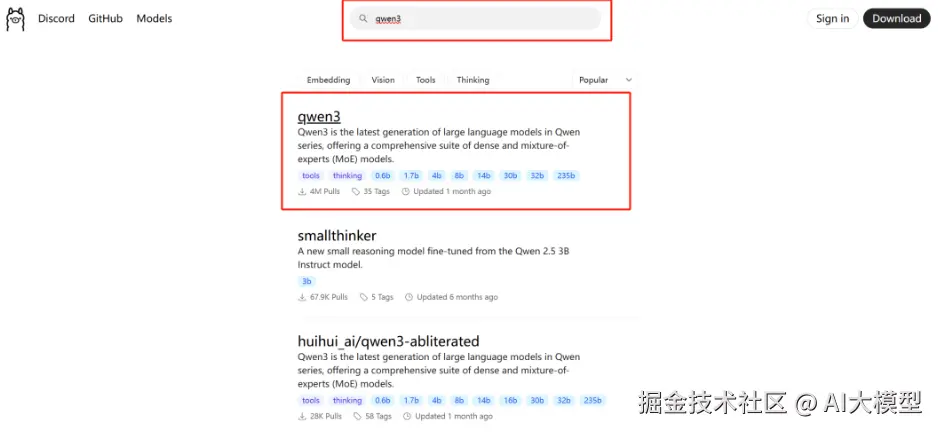
选择适合自己的版本
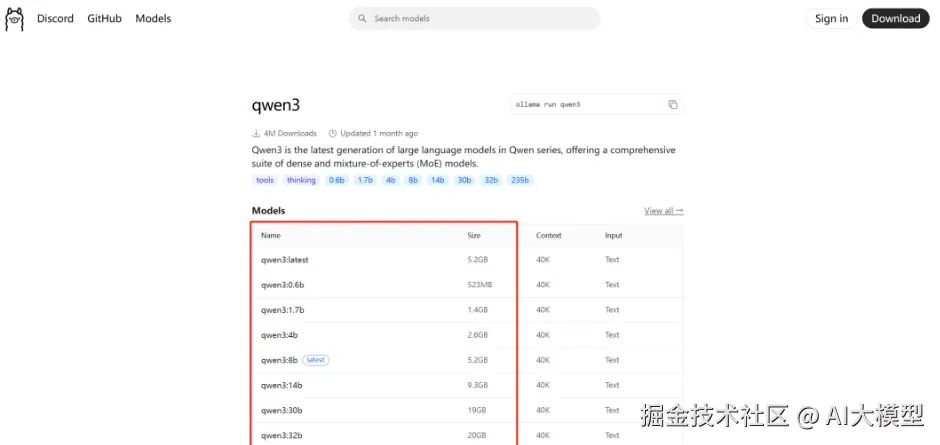
arduino
ollama run qwen3:0.6b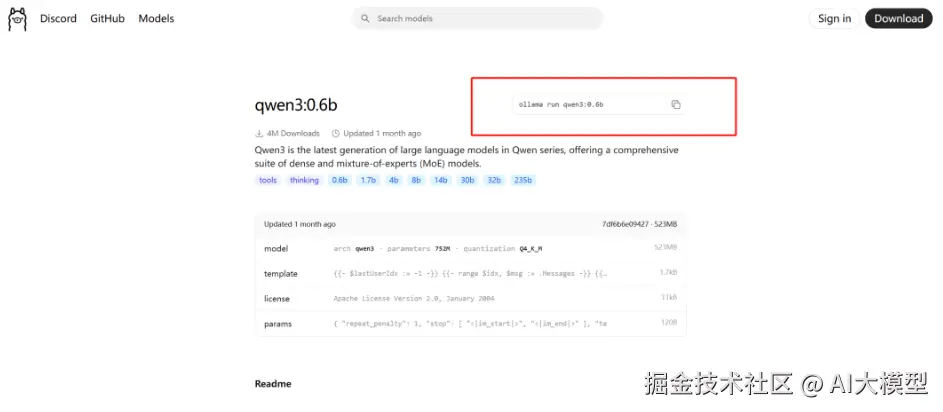
第一次运行会有一个下载的过程需要等待一下
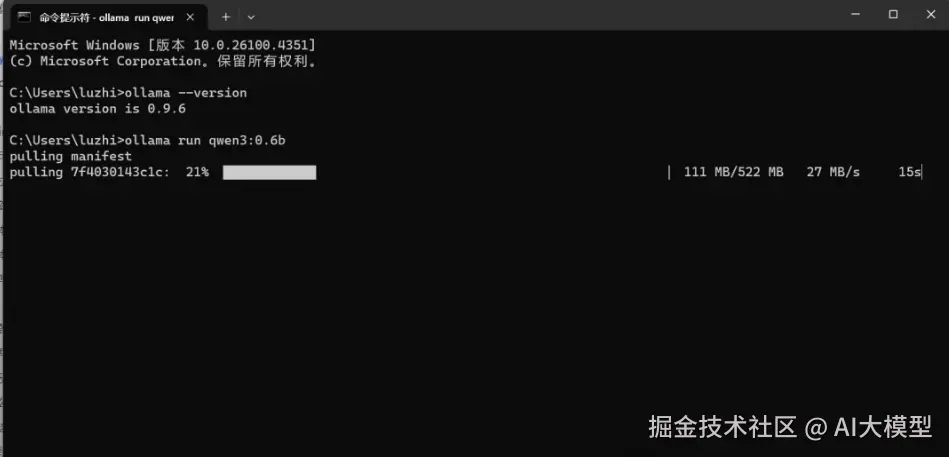
等待两三分钟后,就安装好了,我们就可以直接在这里和大模型对话了。
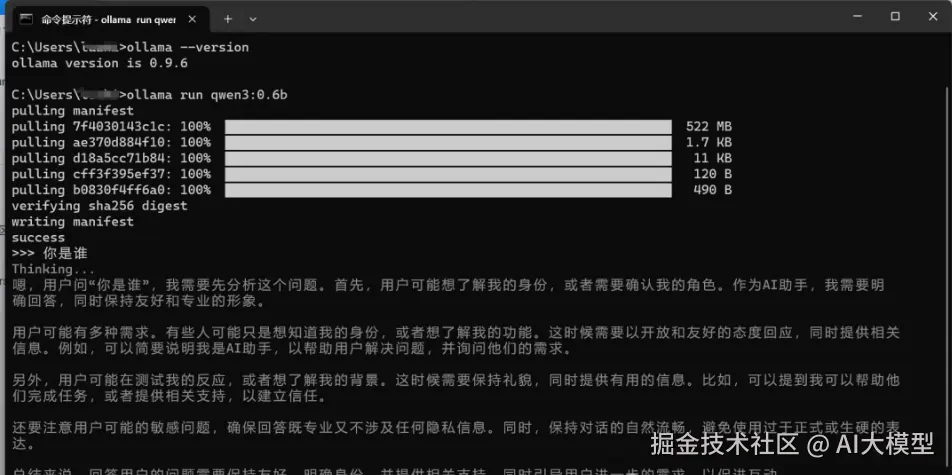
可以看到大模型正常回复了,到这里本地安装Ollama以及部署qwen3就完成了。
讲在最后
怎么样,跟着教程走下来,是不是发现把大模型"装进"自己的电脑,并没有想象中那么遥不可及?
今天,我们只是迈出了第一步,成功在本地运行了第一个大模型。但这背后开启的,是一个充满无限可能的全新世界。这意味着你可以拥有一个完全私有、7x24小时待命的专属AI助理。未来,我们可以让它连接你的本地文件,打造私人知识库;可以把它接入自动化流程,成为工作流中的智能大脑...
AI正在以前所未有的方式赋予我们普通人力量,而Ollama就是这股浪潮中,最亲民、最易上手的工具之一。它让我们与顶尖AI的距离,不再是服务器与终端的距离,而仅仅是硬盘与内存的距离。
当然,在命令行里聊天还不够优雅,大家最关心的如何链接知识库、如何拥有图形化界面等问题,别急我们下一篇继续深度开聊!
好啦!今天的内容就分享到这。