背景与核心思想简介
在LLM的长上下文推理中,KV Cache 成为影响速度和内存的关键因素。每生成一个新token,模型需要对所有先前token的键(Key)和值(Value)向量执行自注意力计算。传统方法会将所有过去的K/V向量保存在GPU上,并在每步将查询向量与整个K缓存做点积计算,然后加权累加对应的V向量。这种全量 KV 缓存方案有两个主要问题:
- 内存占用大:随着序列长度增长,KV缓存的大小线性扩张。比如支持32K上下文的LLM,每一层每个注意力头需要存储3.2万×头维度的Key和Value,模型层数多时总缓存可达数GB,占满GPU显存,限制了批量大小。
- 计算吞吐低 :每生成一个token都要与先前所有token的Key做注意力计算,时间复杂度随上下文长度线性增加(长上下文场景下接近O(n2)O(n^2)O(n2)总复杂度),导致生成速度显著下降。
一些现有方法尝试缓解上述问题,例如动态稀疏注意力 (仅保留部分重要的K/V参与计算)或者将KV缓存整体转移到CPU (节省GPU显存)。但前者往往难以充分降低内存 占用,后者则因为每步需要通过PCIe来回传输大量数据而延迟高。
ShadowKV ("影子KV")是字节跳动提出的一种高吞吐长上下文推理机制,其核心思想是:将KV缓存拆分成"小影子"和"大本营" ,把低秩表示的Key缓存保留在GPU 上(影子部分),而完整的Value缓存下放到CPU内存 (大本营部分),并辅以一种准确的KV选择策略,仅在需要时按需重建极少量的KV对 供注意力使用。通过这种机制,ShadowKV在保持模型输出几乎无损的前提下,大幅削减了GPU显存占用,并提高每步解码的并行效率。简而言之,ShadowKV让大部分KV对"隐身"在影子中,只在必要时显现,从而实现更高的推理吞吐量。
ShadowKV 的计算流程详解
ShadowKV将推理过程分为两个阶段:预填充(Pre-filling)和解码(Decoding)。下面分别介绍这两个阶段的具体计算步骤,涉及的张量形状,以及注意力过程中各操作细节。
预填充阶段:缓存压缩与建立 "影子" KV
预填充阶段在模型处理完初始长上下文(如提示或对话历史)后进行,目的是对整段上下文的KV缓存进行压缩和筛选,为后续高效解码做好准备。设批量大小为 BBB,序列总长度为 LLL,注意力头数量为 HHH,每个注意力头维度为 DDD(即隐藏层尺寸=H×D=H \times D=H×D)。对于支持多查询头(Multi-Query Attention)的模型,这里我们用 H_kH\_kH_k 表示Key/Value公用的头数 (如Llama等模型通常H_k=HH\_k = HH_k=H)。
1. 将 Value 全量缓存至CPU :模型前向计算得到初始上下文的Key、Value张量后,ShadowKV首先将所有层的 Value 缓存复制到CPU内存 中保存。这样GPU上就不再保留大体积的V缓存,从源头上缓解了显存压力。设某一层输出的Value张量形状为 [B, H_k, L, D],则在CPU中维护对应大小的 v_cache_cpu 缓存数组,用于存放该层所有批次、所有KV头的Value向量。
2. 划分最近局部块(Local Chunks) :考虑到最新的若干个token往往对后续生成贡献较大,ShadowKV将上下文序列最后的一小段保留为"局部全量缓存"。具体地,设定每层一个 chunk_size 超参数(例如8),以及 local_chunk 数量(例如4),表示保留末尾444个chunk的token。在示例中,末尾局部片段长度为 Llocal=local_chunk⋅chunk_size=4⋅8=32L_{\mathrm{local}}=\mathrm{local\_chunk}\cdot\mathrm{chunk\_size}=4\cdot8=32Llocal=local_chunk⋅chunk_size=4⋅8=32
(若LLL不能整除8,则包括余下的不满一个chunk的部分)。这最后的约32个token的Key/Value将完整保存在GPU上 ,形成高频近邻缓存。对应地,我们在GPU上为每层分配 k_cache_buffer 和 v_cache_buffer 数组,用于存放GPU驻留的K/V块。首先将末尾 LtextlocalL_{text{local}}Ltextlocal 的Key、Value拷贝到该buffer的开头位置。
3. 按固定大小分块剩余上下文 :将除最后局部块之外的前面长上下文划分为若干长度为 chunk_size 的等长块。块数可计算为:N_chunk=⌊L/chunk_size⌋−local_chunkN\_{\text{chunk}} = \lfloor L / \text{chunk\_size} \rfloor - \text{local\chunk}N_chunk=⌊L/chunk_size⌋−local_chunk(例如L=131072L=131072L=131072时,Nchunk=16384−4=16380N{\text{chunk}} = 16384 - 4 = 16380Nchunk=16384−4=16380)。对于每一块,我们计算该块中所有Key向量的平均值 ,得到一个代表此块的Landmark 向量。经过位置编码(RoPE)处理后的Key张量形状为 B,Hk,L,DB, H_k, L, DB,Hk,L,D,将其视作 B,Hk,Ntextchunk,textchunksize,DB, H_k, N_{text{chunk}}, text{chunk_size}, DB,Hk,Ntextchunk,textchunksize,D 的5维张量,则对倒数第二维求平均可得 Landmark 张量形状 B,Hk,Ntextchunk,DB, H_k, N_{text{chunk}}, DB,Hk,Ntextchunk,D,即每个KV头每块一个代表向量。这些Landmark保留了各块在Key空间的大致方向信息。
4. 检测并保留离群Token(Outliers) :虽然Landmark代表了块的整体特征,但块内某些离群token 可能与块均值差异较大,若仅用均值代表会损失它们的注意力信息。为此,ShadowKV对每个块计算各token与Landmark的余弦相似度 ,找出相似度最低的那个token作为该块的"最异"token,并记录其相似度。然后在所有块中选出相似度最低的若干块,认为这些块存在重要的离群Key 。设超参数 outlier_chunk 表示选取的离群块数量(如48),ShadowKV会挑选出最不代表性的48个块。对于这些块内的所有token,ShadowKV将它们视为outlier token并完整保留它们的Key/Value 在GPU缓存中。具体来说,从前面计算的Key张量 B,Hk,Ntextchunk,textchunksize,DB, H_k, N_{text{chunk}}, text{chunk_size}, DB,Hk,Ntextchunk,textchunksize,D 中,按照选出的块索引提取对应的所有Key向量,将它们扁平为形状 B,Hk,textoutlierchunk×textchunksize,DB, H_k, text{outlier_chunk} \\times text{chunk_size}, DB,Hk,textoutlierchunk×textchunksize,D后,复制到GPU的 k_cache_buffer 紧接局部块位置之后。同样地,这些token的Value也提取并复制到 v_cache_buffer 相应位置。经过这一步,GPU上缓存了:末尾局部L_localL\_{\text{local}}L_local token的K/V,以及484848个离群块(共48×8=38448\times 8 = 38448×8=384个token)的K/V。相比全长LLL而言,这部分token数量很小,但包含了序列中难以被均值代表的关键信息。
5. 构建Landmark "影子缓存" :将除离群块以外的其余块的Landmark保存下来,作为后续注意力查询的影子Key缓存 。具体实现是:过滤掉已选为离群的块索引,将剩余块的Landmark向量及其对应的块索引列表存入k_landmark和k_landmark_idx张量中。此时,GPU上k_landmark形状为 B,Hk,Ntextchunk−textoutlierchunk,DB, H_k, N_{text{chunk}} - text{outlier_chunk}, DB,Hk,Ntextchunk−textoutlierchunk,D,包含每个未标记为离群的块一个代表Key向量;k_landmark_idx记录了这些Landmark对应的原始块编号,形状为 B,Hk,Ntextchunk−textoutlierchunkB, H_k, N_{text{chunk}} - text{outlier_chunk}B,Hk,Ntextchunk−textoutlierchunk。
6. 低秩分解压缩 Key(可选) :为进一步压缩存储和加速计算,ShadowKV利用键矩阵的低秩特性 对所有Key进行一次SVD分解。研究发现,未经过RoPE位置编码的Key矩阵在长序列下秩值很低。ShadowKV在预填充阶段对整个序列的Key缓存 (特别是经过RoPE后的Key)进行SVD,提取出秩为rrr的近似。SVD会生成左右奇异向量UUU和VVV以及奇异值SSS;实现中将SSS和VVV预先相乘简化存储。对于每层,我们维护U和SV两个张量:U[layer]形状为 [B, L, r],存储全序列长度LLL×秩rrr的矩阵;SV[layer]形状为 B,Hk,r,DB, H_k, r, DB,Hk,r,D,存储秩rrr×Key维度DDD的信息(这里HkH_kHk维度用于区分不同KV头或头组)。这两个张量常驻GPU,提供了重构任意Key向量的"字典"。低秩Key缓存与Landmark/Outlier互为补充:Landmark用于粗粒度检索,低秩U,S,VU,S,VU,S,V用于精确重建需要的Key值。
经过以上步骤,预填充阶段完成 :此时GPU上仅保留了低秩压缩的Key表示 (U和SV)、Landmark代表Key集合 以及少量原始Key/Value(局部+离群token) ,总共占用的显存远小于完整缓存。而完整的Value缓存 由于体积庞大,已完全移至CPU内存。这样一来,GPU上的KV缓存被"瘦身"为一个影子:包含摘要信息和关键细节,准备支持后续高速的解码计算。
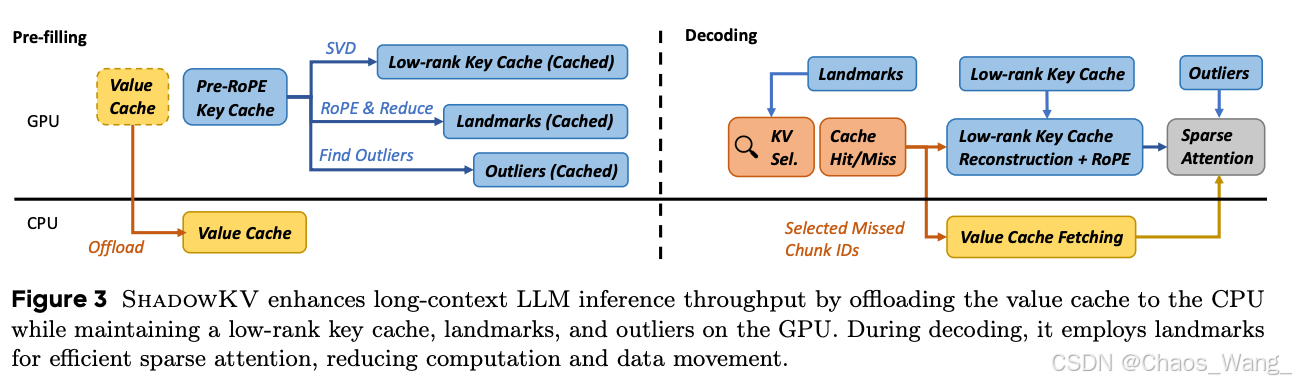
ShadowKV 预填充(左)和解码(右)阶段的机制示意图。在预填充阶段,Value缓存(黄色部分)被整体下放至CPU,Key缓存(蓝色部分)经SVD低秩压缩并结合RoPE位置编码提取出Landmark和Outlier,形成存留GPU的"影子"KV缓存。解码阶段,通过Landmark进行高效的稀疏注意力查询,仅针对Cache未命中的部分块从CPU取回对应Value,并借助低秩Key表示重建所需Key向量,在GPU上完成注意力计算。
解码阶段:按需稀疏重建与注意力计算
在解码阶段,模型开始基于先前缓存生成新token。ShadowKV的解码与标准自注意力不同之处在于引入了两级的稀疏查询与重建机制,以最小代价获取所需的KV对。下面以单个新生成token为例(查询长度为1)说明每层解码计算流程:
1. 粗粒度块级注意力 :当有新的查询向量 QQQ (形状 [B, H, 1, D])需要与过去上下文计算注意力时,ShadowKV首先利用GPU上的Landmark计算块级别 的注意力分布。具体步骤为:将查询向量与每个Landmark Key做点积,得到每个块对查询的相关性分数。因为某些模型存在多个查询头共享同一Key的情况,实现中按KV头组数 GGG 对注意力头分组处理,QQQreshape为 B,Hk,G,1,DB, H_k, G, 1, DB,Hk,G,1,D,Landmark reshape为 B,Hk,1,Nchunk(remain),DB, H_k, 1, N_{\\text{chunk(remain)}}, DB,Hk,1,Nchunk(remain),D(在计算时会自动广播组维度)。通过 Einsum 矩阵乘得到形状 B,Hk,G,1,Nchunk(remain)B, H_k, G, 1, N_{\\text{chunk(remain)}}B,Hk,G,1,Nchunk(remain) 的分数张量,随后对组维度取平均或最大(等价于不同注意力头组结果的融合,代码中对组维度应用了softmax再max等处理),最终得到 B,Hk,Nchunk(remain)B, H_k, N_{\\text{chunk(remain)}}B,Hk,Nchunk(remain) 大小的每个块的注意力权重。接下来对这些权重做一次softmax归一化(在保证数值稳定的同时通常以更高精度计算softmax)。
2. 精细选择相关块 :根据得到的块级注意力分布,ShadowKV从中选出得分最高的 KKK 个块 作为"与当前查询最相关"的块集合。这里 K=select_setsK = \text{select\_sets}K=select_sets 是根据设定的sparse_budget(GPU稀疏KV预算)决定的块数,例如sparse_budget=2048且chunk_size=8则K=2048/8=256K=2048/8=256K=2048/8=256个块。选出的块索引利用之前保存的k_landmark_idx映射回原始块编号集合,得到形如 [B, H_k, K] 的张量。这些块将被视作需重点保留的记忆 :它们涵盖了对新查询有主要影响的约 K×chunk_sizeK \times \text{chunk\_size}K×chunk_size 个历史token。
3. 从CPU取回选中块的Value :对于上一步选出的相关块,我们需要确保其对应token的Value都在GPU上,以备计算注意力输出。如果其中一些块恰好是先前已缓存为Outlier或本地块(局部块),那么它们的Key/Value已经在GPU缓冲中,可直接使用(Cache Hit )。其余大部分块此前仅以Landmark代表,没有完整缓存(Cache Miss )。对于这些Miss的块,ShadowKV现在按块批量从CPU提取它们的Value缓存 :根据块索引计算出每个块起始的token位置范围,将对应的Value片段(大小为chunk_size的连续向量段)从v_cache_cpu复制到GPU的v_cache_buffer剩余空位中(预填充时已为sparse_budget预留了这一区域空间)。由于这些选中的Value总长度不超过sparse_budget(如2048个token),复制开销相对较小。更重要的是,ShadowKV实现了一个高效的gather_copy批量拷贝CUDA kernel,将所有需传输的数据按连续内存段一次搬运,极大提高了PCIe带宽利用率。
4. 重建选中块的Key :对于Miss的相关块,还需要获得它们对应token的Key向量以计算注意力分数。然而这些Key并未显式存储在GPU或CPU内(GPU上只有Landmark代表,CPU上已不保存Key以节省空间)。ShadowKV利用预填充阶段准备的低秩Key表示(U和SV)来按需重建所需的Key 。具体而言,ShadowKV的自定义CUDA kernel会读取position_ids(所选token的全局位置列表,长度K×chunk_sizeK \times \text{chunk\_size}K×chunk_size)以及低秩矩阵U、SV,直接在GPU上计算出这些位置对应的Key向量。此外,还会将RoPE位置编码应用于这些重建的Key,以确保它们与查询Q处于相同的旋转相位。这个过程融合了"从低秩基重建+位置旋转"以及必要的张量变换操作,在GPU上高效完成,而无需恢复完整的Key缓存。
5. 稀疏注意力计算 :现在,GPU上的 k_cache_buffer 已包含了当前查询所需的全部Key向量 ,包括先前一直存留的局部+离群Key,以及刚刚重建获取的其他相关Key,总计数量约为 local+(outlier_chunk×chunk_size)+K×chunk_size\text{local}+(\text{outlier\_chunk}\times\text{chunk\_size})+K\times\text{chunk\_size}local+(outlier_chunk×chunk_size)+K×chunk_size。以典型参数为例,这可能是 32+384+2048≈246432 + 384 + 2048 \approx 246432+384+2048≈2464 个Key,远小于完整的L=32000+L=32000+L=32000+。同样,v_cache_buffer中相应保有上述Key对应的Value向量。接下来,ShadowKV对查询Q与这数千个Key计算稀疏注意力 :进行Q⋅KTQ \cdot K^TQ⋅KT点积得到注意力分数(只针对选定的小集合),然后softmax归一化,之后用权重与Value加权求和得到输出。由于K/V数量大幅减少,注意力乘加运算的开销也显著降低。此外,这一步计算也可以与前述步骤部分融合以进一步优化(例如ShadowKV将低秩重建Key和点积操作组合在同一CUDA kernel中完成)。最终得到的注意力输出与传统完整计算得到的结果几乎相同------因为ShadowKV确保了对注意力贡献最大的那些Key/Value都在这个稀疏集合中。
6. 更新缓存状态 :在生成出新token的输出后,ShadowKV会将该新token的Key和Value追加到缓存中。对于Value,新token的Value张量会追加存储到CPU端的v_cache_cpu对应位置;对于Key,新token的Key向量会存入GPU的k_cache_buffer末尾区域(属于最新的局部块一部分)。kv_offset计数会随生成token的数量递增,以反映当前缓存序列长度。如果积累的新生成token数达到一个chunk_size块的长度,ShadowKV可能会将它们标记为新的块并适时更新Landmark/Outlier信息(视实现策略决定,当前版本主要在预填充时一次性确定Landmark/Outlier)。由于新token通常逐个生成,附加的计算和数据转移量很小,不会显著影响整体吞吐。经过以上步骤,模型即可将新token送入下一层继续计算,并迭代进行下一个token的解码。
通过上述"Landmark 引导 + 按需重建"流程,ShadowKV避免了每步对全部历史K/V的重复计算和搬移,仅用极少的候选集合就重构出了接近完整注意力的信息。这种分段式注意力重计算与KV更新策略,大大降低了长上下文解码的平均计算复杂度和内存带宽开销,带来了显著的速度提升。
与传统 KV 缓存机制的对比
相比传统的KV缓存机制,ShadowKV在存储开销 和计算效率上都引入了重要的改进:
-
显存占用 :传统方案需要在GPU保留每一层、每个注意力头、每个历史token的K和V向量,空间复杂度∼O(L×H×D)\sim O(L \times H \times D)∼O(L×H×D),这对长序列非常不友好。而ShadowKV将V全部移出GPU,仅保留压缩后的Key表示和少量token的Key副本。以实际数据为例,ShadowKV在支持12.2万长度时,可将KV缓存的GPU占用减少超过6倍!这直接使得可支持的批量大小提升 :以前为避免显存溢出可能每次只能推理少数序列,而ShadowKV腾出的空间允许一次处理更多序列,实现最高6倍的批量增幅。更高的批量在服务场景中转化为更高的吞吐量。
-
注意力计算成本 :传统自注意力在解码时对每个新token都要与LLL个Key做乘法累加,时间复杂度线性随LLL增长,导致长上下文下单token生成延迟显著增大 。ShadowKV通过两级筛选,将每步参与计算的Key数量削减到∼\sim∼几千(与
sparse_budget有关,是LLL的固定小比例)。虽然在每步计算前增加了一些筛选和数据拷贝开销,但由于选择集合很小,总体计算量近似降低为原来的(sparse_budget+overhead)/L(\text{sparse\_budget}+ \text{overhead})/L(sparse_budget+overhead)/L比例,对长序列而言这个比例非常低。例如在L=122L=122L=122K时,sparse_budget=2K意味着只需约1.6%的Key参与最终计算。实测结果表明,ShadowKV在32K甚至更长上下文下的单步计算延迟远低于全量注意力,从而大幅提高了生成吞吐。 -
数据传输效率 :一种简单的思路是将全部KV缓存移至CPU,每步把所有需要的K/V取回GPU用,再扔掉。虽然省显存,但这样每生成一个token都要搬运O(L)O(L)O(L)的数据,PCIe带宽成为瓶颈,反而可能使速度极慢。ShadowKV聪明地只在需要时搬运极小部分 数据:Value只搬运选中的那2048个token左右,Key则通过数学重建避免了显式搬运。这种极小化的数据传输,结合批量连续拷贝等优化手段,使得ShadowKV即使在PCIe受限的环境下依然高效。另外,GPU上的低秩Key和Landmark也支持并行处理:Landmark注意力的计算复杂度O(N_chunk)O(N\_{\text{chunk}})O(N_chunk)约为原始LLL的1/chunk_size1/\text{chunk\_size}1/chunk_size(如1/8),其Softmax等操作开销相对可以忽略。总的来说,ShadowKV将原本分散的访存和计算集中为少数几次大块操作与矩阵乘法,使GPU硬件的吞吐潜力得到更充分发挥。
-
输出质量保持 :稀疏/压缩方法常面临准确率下降的问题,而ShadowKV通过合理选择Landmark、补充Outlier并动态调整选取策略,保证了几乎零精度损失。实验显示,无论是问答、代码还是长文理解等任务,ShadowKV与完整注意力的输出一致性极高。这意味着研究者和工程师在使用ShadowKV加速时,无需牺牲模型效果。
综上,ShadowKV通过在GPU维护"影子"KV缓存并利用精细的选择策略,实现了更小的存储、更快的计算和几乎不变的性能,为长上下文LLM的实际部署提供了一种高效方案。
KV_Cache 类源码解析(传统缓存实现)
为了更清楚地理解ShadowKV的特殊之处,我们来看ShadowKV仓库中提供的一个基准实现类------KV_Cache。这个类实现了传统的全量KV缓存逻辑 ,用于对比或在不启用Shadow机制时使用。下面附上KV_Cache类的代码,并逐行添加中文注释解释其结构、成员变量含义和主要方法的执行逻辑:
python
class KV_Cache:
"""Full Attention"""
def __init__(self,
config :object,
batch_size :int = 1,
max_length :int = 32*1024,
device :str = 'cuda:0',
dtype = torch.bfloat16) -> None:
# 初始化 KV 缓存类,设定配置、批次大小、最大支持长度、设备和数据类型(默认为 BF16)
self.config = config
self.max_length = max_length
self.device = device
self.dtype = dtype
# 分配用于存储 Key 缓存的张量 (保存在CPU上),形状: [层数, batch_size, KV头数, max_length, 头维度]
self.k_cache = torch.zeros(
config.num_hidden_layers,
batch_size,
config.num_key_value_heads,
max_length,
config.hidden_size // config.num_attention_heads,
device='cpu',
dtype=self.dtype
)
# 分配用于存储 Value 缓存的张量 (同样在CPU上),形状与 k_cache 相同
self.v_cache = torch.zeros(
config.num_hidden_layers,
batch_size,
config.num_key_value_heads,
max_length,
config.hidden_size // config.num_attention_heads,
device='cpu',
dtype=self.dtype
)
# 保存层数和初始化偏移
self.num_layers = config.num_hidden_layers
self.kv_offset = 0 # 当前已经缓存的序列长度偏移(初始为0)
# 批次预填充记录
self.prefilled_batch = 0 # 已经预填充完成的 batch 数计数
self.batch_size = batch_size
def update_kv_cache(self,
new_k_cache :torch.Tensor,
new_v_cache :torch.Tensor,
layer_idx :int
):
# 将某层的新 Key/Value 张量添加到缓存中。
# new_k_cache, new_v_cache 形状: [bsz, KV头数, incoming, 头维度], incoming为新加入的token数
bsz, _, incoming, _ = new_v_cache.shape # 提取当前更新的批大小和新token长度
if bsz == self.batch_size:
self.prefilled_batch = 0 # 如果本次更新的批大小等于总batch_size,说明开始处理新一批序列,将prefilled计数清0
# 将新Key复制到对应层的缓存位置:
# 在第 layer_idx 层,针对本批次(prefilled_batch 起始位置),将缓存张量从 kv_offset 开始连续 incoming 长度的区域填入 new_k_cache
self.k_cache[layer_idx][self.prefilled_batch:self.prefilled_batch + bsz, :, self.kv_offset:self.kv_offset + incoming].copy_(new_k_cache)
# 将新Value复制到缓存
self.v_cache[layer_idx][self.prefilled_batch:self.prefilled_batch + bsz, :, self.kv_offset:self.kv_offset + incoming].copy_(new_v_cache)
# 获取当前批次在该层的完整Key/Value缓存切片(从序列开头到最新添加位置)
key = self.k_cache[layer_idx][self.prefilled_batch:self.prefilled_batch + bsz, :, :self.kv_offset + incoming]
value = self.v_cache[layer_idx][self.prefilled_batch:self.prefilled_batch + bsz, :, :self.kv_offset + incoming]
if incoming > 1: # 若本次添加的incoming长度超过1,表示在进行预填充(而非生成单token)
key = key.to(self.device) # 则将这一整段Key缓存提前转移到GPU,方便后续注意力计算
value = value.to(self.device)
# 如果到达最后一层:
if layer_idx == self.num_layers - 1:
# 更新已处理的批计数
self.prefilled_batch += bsz
# 若该批次所有层均已填充完(prefilled_batch达到了batch_size)
if self.prefilled_batch == self.batch_size:
# 则整体缓存偏移kv_offset增加incoming长度,表示序列累积长度扩张
self.kv_offset += incoming
# 返回当前层最新的Key和Value张量(并确保在GPU上)
return key.to(self.device), value.to(self.device)
def print_stats(self):
# 打印当前KV缓存状态,包括最大长度、数据类型和已缓存长度
print(f"KVCache | max_length {self.max_length} | dtype {self.dtype} | cached {self.kv_offset}")
def H2D(self):
# Host to Device:将缓存从CPU转移到GPU的方法(需要先清理显存,防止占用过多)
gc.collect()
torch.cuda.empty_cache()
torch.cuda.synchronize()
self.k_cache = self.k_cache.to(self.device) # 将Key缓存tensor搬到GPU
self.v_cache = self.v_cache.to(self.device) # 将Value缓存tensor搬到GPU
def clear(self):
# 清空缓存索引(不实际释放tensor内存,只重置计数)
self.kv_offset = 0
self.prefilled_batch = 0
def get_kv_len(self):
# 获取当前缓存的总长度(已经存储的token数量)
return self.kv_offset上面的代码展示了传统KV缓存的工作原理:KV_Cache在初始化时为每层分配足够长度的张量来容纳所有Key/Value,并采用kv_offset追踪当前存储到的位置。update_kv_cache方法会在每生成新token或预填充一批序列时调用,将新产生的K/V复制到相应位置,并在最后一层时更新全局偏移。可以看到,该实现中默认将缓存保存在CPU ,只有在需要计算或预取时才调用.to(self.device)挪到GPU------这是因为在超长序列场景下,缓存可能过大以至于GPU放不下,需要依赖CPU内存。ShadowKV正是基于类似思路发展而来,但它更加智能 :并不简单地把整个缓存都留在CPU、也不全放GPU,而是精挑细选一部分放GPU,其他放CPU,从而在速度和内存之间取得平衡。
通过对比可以发现,ShadowKV相比这个基础实现主要多了:Landmark/Outlier筛选、低秩分解以及按需的增量更新策略。这些额外逻辑虽然复杂,但带来了巨大的性能优势。
实验结果与内存优化补充
ShadowKV在作者的实验中取得了非常亮眼的结果。在多个长上下文基准测试上,它在A100 GPU 上实现了最高约3倍的生成吞吐提升 ,并且在支持更大批量 的同时几乎没有准确率下降。例如,对于122K长度的序列批处理,ShadowKV将批大小从传统方案的4提升到了24,吞吐从80 tokens/s提高到245 tokens/s左右,而生成结果与完整注意力计算完全一致。这些收益源于ShadowKV出色的内存管理和访存优化。
在实现细节上,ShadowKV为提升效率做出了多种内存访问优化 策略。例如,采用块对齐的存储布局 (8个token一组),使得选中块的Value可以整块拷贝;使用自定义CUDA Kernel实现如gather_copy和batch_gemm_rotary_pos_emb等操作,将数据整理、复制和运算融合,减少中间临时数据和冗余内存读写;利用CUDA流和异步拷贝,在CPU-GPU传输Value的同时GPU可并行进行部分计算,最大化流水线利用。据作者测算,ShadowKV有效利用了GPU高带宽,在A100上相当于每秒7TB以上的数据处理能力,逼近硬件理论峰值。
总而言之,ShadowKV通过巧妙地将 "大而全"的KV缓存拆解为"精而简"的影子缓存,在长上下文LLM推理中实现了存储与计算的双重优化。对于研究者而言,这一机制提供了新的思路:在保证模型性能的前提下,可通过矩阵分解、稀疏选择等手段大幅提升推理效率。