演示视频
香橙派RK3588部署千问大模型Qwen2-VL-2B推理视频
一、场景假设
视频输入为一条网络流,利用大模型对视频中的图像帧进行推理。由于大模型推理耗时长,无法对每帧都进行推理,因此采用跳帧推理的方式:当推理完一帧后,期间会跳过若干帧,然后立即推理最新的一帧。
二、处理流程
1. 拉流
-
使用 ffmpeg 拉取 rtsp 流,进行解封装得到 h264。
-
为保证传输稳定,配置为 rtsp over tcp。
2. 视频解码
通过 mpp 解码 h264,得到 nv12 图像。
3. 图像转换
利用 rga 将 nv12 图像进行放缩和转 rgb 操作,此过程采用 letterbox 方式,主要目的是保持宽高等比放缩。
4. 图像编码
使用 rknn 将 rgb 图像编码成大模型能够理解图像所用的图像向量。
5. 推理
借助 rknn 将提示词和图像向量输入大模型进行推理,推理结果直接打印出来。
6. 渲染
将用于推理的图像(即图像编码前的图像),通过 qt 适配 qwidget 和 opengles 的方式进行渲染。
三、使用模型
-
Qwen2-VL-2B_llm_w8a8_rk3588.rkllm -
Qwen2-VL-2B_vision_rk3588.rknn
四、主要耗时
-
图像编码模型加载:5s
-
大模型加载:7s
-
图像编码:3s
-
大模型推理:5s
注意:模型加载仅在程序开始时进行一次即可。
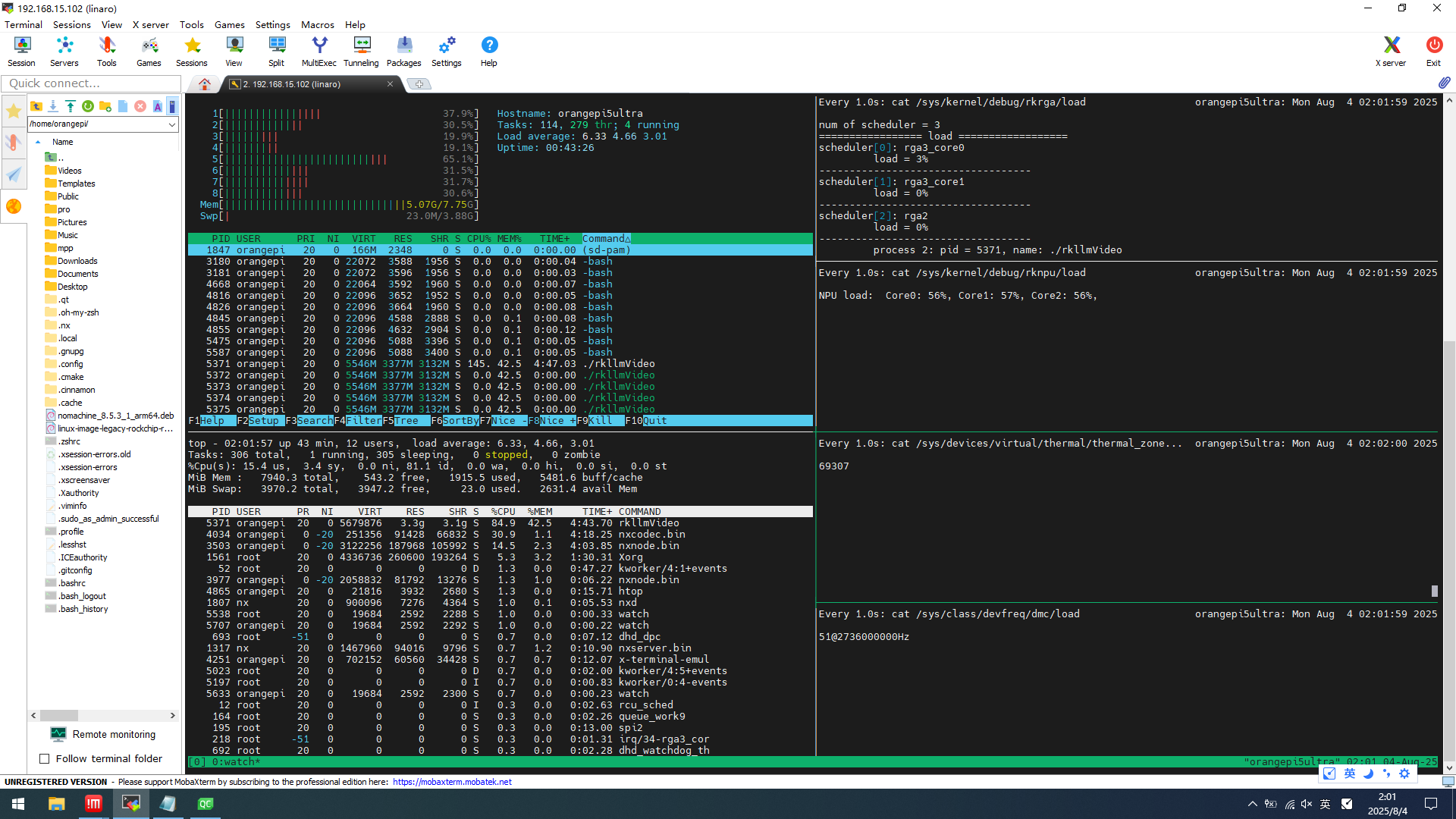
五、资源占用
-
CPU:145%(满载 800%)
-
内存:5GB
-
NPU:50%~99%
-
温度:69℃