案例:鸢尾花数据集的聚类
一.聚类简介
神经网络能够从输入数据中自动提取有意义的特征,而竞争学习规则使得单层神经网络能够根据相似度将输入样本进行聚类,每个聚类由一个输出神经元代表并作为该类别的"原型",从而实现对输入模式的无监督分类与结构发现。
二.案例研究(Iris植物聚类)
i.问题陈述:
针对无法明确将数据集划分为三种鸢尾花类别的问题,设定目标为构建一个能够自主学习并完成聚类任务的智能无监督人工神经网络(ANN),选用竞争型神经网络(Competitive ANN)作为模型,并采用竞争学习(Competitive Learning)算法,使网络能够根据输入特征自动发现数据的内在类别结构并完成分类。
ii.数据集描述:
本实验数据集包含 150 个样本,分属 Setosa、Versicolor 和 Virginica 三种鸢尾花类别,每个样本由 4 个连续型特征描述,分别为萼片长度(4.3--7.9 cm)、萼片宽度(2.0--4.4 cm)、花瓣长度(1.0--6.9 cm)和花瓣宽度(0.1--2.5 cm),这些特征在数值范围和单位上存在差异,因此在模型训练前需进行归一化处理,以确保特征在聚类中的贡献均衡。
iii.测试理解问题:
本任务属于聚类应用,数据集规模为 150 个样本在 3 个类别上的共 450 条特征记录,每个样本包含 4 个变量(萼片长度、萼片宽度、花瓣长度、花瓣宽度),目标是将其划分为 Setosa、Versicolor 和 Virginica 三类,通过无监督聚类方法发现不同鸢尾花品种在特征空间中的分布规律与相似性结构。
三、核心概念与流程
1.数据准备
i.数据归一化
欧几里得距离对特征数值范围非常敏感,如果某个特征的取值范围较大,就会在距离计算中占据主导地位,掩盖其他特征的作用;同时,不同特征可能存在不同的单位和量纲(如 cm、kg、秒),直接比较不公平。通过归一化,可以将所有特征转换到同一尺度(通常是 0 到 1 的比例数据),使它们在相似度计算中权重均衡,并加快模型的训练收敛速度。
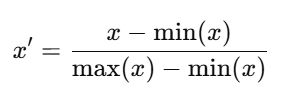
ii.数据划分(DATA PREPARATION)
在实验中,将 150 个样本随机划分为训练集和测试集,例如可分为训练集 100 个、测试集 50 个,或按 70:30、80:20 等比例进行分配,以便用于模型训练和效果评估。
2.网络结构(Iris 示例)
在该竞争学习网络中,输入层神经元数量等于特征数,即 4 个节点分别对应萼片长度、萼片宽度、花瓣长度和花瓣宽度;输出层神经元数量等于期望的聚类簇数,本例设置为 3 个神经元分别代表三种鸢尾花类别;权重矩阵的维度为 4×3,即每个输出神经元都关联一个 4 维权重向量,用于表征该类别在特征空间中的"原型"位置,并在训练过程中不断调整以贴近该簇样本的特征分布。
3.初始化
训练初期将网络权重初始化为较小的随机值(如在 0,1 区间或依据输入特征范围生成),并在训练过程中定期记录权重变化,例如比较初始权重、迭代 100 次后的权重以及 2000 次后的权重,以观察网络收敛过程和权重逐步贴近各类别特征分布的趋势。
4.激活与匹配(找 Winner)
使用 欧氏距离(Euclidean distance) 作为匹配准则:对每个输出单元 j计算, 选择距离最小者作为胜出神经元(BMU)。
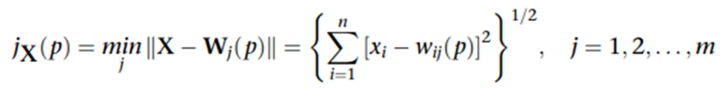
5.权重更新
对胜出神经元的权重按下式更新:
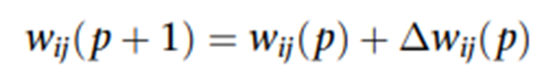
α是学习率,控制更新幅度;Λj(p)是邻域函数;
6.重复训练直至收敛
由于无监督学习中没有可直接监控的标签误差,本例采用欧氏距离准则或"权重变化不再显著"作为收敛判据,即当权重向量在多次迭代后变化幅度极小即可视为收敛。
7.簇标注(Labelling 输出神经元)
在无监督聚类中,输出单元本身没有预设类标签,因此常用的方法是在训练完成后利用带标签的测试集进行"投票"标注,即统计每个输出单元在测试集中最常赢得的真实类别,将该单元标记为该类别,从而实现输出神经元与具体类别的对应关系。