------从 CNN 的局限出发,看 AI 如何学会"全局思考"
作者:Weisian | AI探索者 · 软件工程师

上一篇我们聊了 CNN(卷积神经网络) ------这个支撑现代计算机视觉长达十年的"功臣"。它凭借"局部感知 + 权重共享"的设计哲学,教会了 AI 如何"看局部";今天,我们要讲一个更强大的模型:Transformer------它让 AI 学会了"看整体"。
从 LeNet-5 的手写数字识别,到 AlexNet 引爆深度学习热潮,再到 ResNet 用残差连接突破深层网络瓶颈,CNN 一步步将图像任务的精度推向新高度。我们每天使用的手机人脸解锁、相册智能分类,背后都是 CNN 在默默发力。
但你有没有想过一个问题:
既然 CNN 已经这么好用,为什么近几年的 AI 大模型(比如 GPT-4V、DALL·E 3),核心动力却变成了 Transformer?
甚至在纯视觉任务中,如今最顶尖的模型也大多是 "CNN + Transformer" 的混合架构,或是纯 Transformer(如 ViT)?
答案很简单:
CNN 虽强,却有绕不开的"天生局限";而 Transformer 带来的"注意力机制",正好补上了这个短板,开启了 AI 从"看懂图片"到"理解场景"的新篇章。
今天,我们就从 CNN 的局限说起,一步步搞懂:
✅ Transformer 到底是什么?
✅ 它为什么能超越 CNN?
✅ 又如何成为现在 AI 大模型的核心骨架?
一、问题引入:CNN 很强,但它也有"视野盲区"
你有没有想过这样一个问题:
如果一张图里有两只猫,一只在左上角,一只在右下角,CNN 能理解它们之间的关系吗?
答案是:很难。
因为 CNN 的"眼睛"始终盯着一小块区域。即使通过多层堆叠扩大了"感受野",它对长距离依赖(long-range dependencies)的建模依然非常弱。比如:
- 判断"这张图整体是室内还是室外";
- 理解"左边的人正在和右边的狗互动";
- 捕捉"天空的颜色影响了地面的光影"。
这些需要全局上下文理解的任务,恰恰是 CNN 的短板。
而更关键的是------CNN 是为图像设计的,那文字呢?语音呢?
文字不像图像那样有固定的空间结构。一句话里,"主语"可能在开头,"谓语"在结尾,中间隔了十几个词。传统 RNN 虽然能处理序列,但速度慢、难并行;CNN 也能强行套用(比如用一维卷积处理文本),但依然受限于局部窗口。
AI 需要一种既能"看全局",又能高效处理任意序列数据的新范式。
2017 年,一篇划时代的论文给出了答案:
《Attention Is All You Need》 ------ Transformer 诞生了。

二、回顾与铺垫:CNN 的"软肋",藏在它的优势里
上一篇我们说过,CNN 的核心优势是"局部感知"和"权重共享"------这让它能高效提取图像的局部特征(边缘、纹理、部件),同时控制参数数量。
但恰恰是这两个优势,造就了它的局限。
我们再拿"认猫"的例子复盘一下:
CNN 认猫时,是从局部边缘(胡须、耳朵轮廓)→ 局部部件(眼睛、鼻子)→ 整体猫脸,一步步"自下而上"拼接特征。这个过程里,它有三个绕不开的问题:
1. 感受野有限,抓不住"全局关联"
CNN 的每个神经元只能关注输入图像的一个局部区域(即"感受野")。哪怕是深层网络,感受野的大小也是有限的------比如一张 1024×1024 的大图,深层神经元的感受野可能也就几百个像素,很难覆盖整个图像。
这就导致 CNN "只见树木,不见森林"。
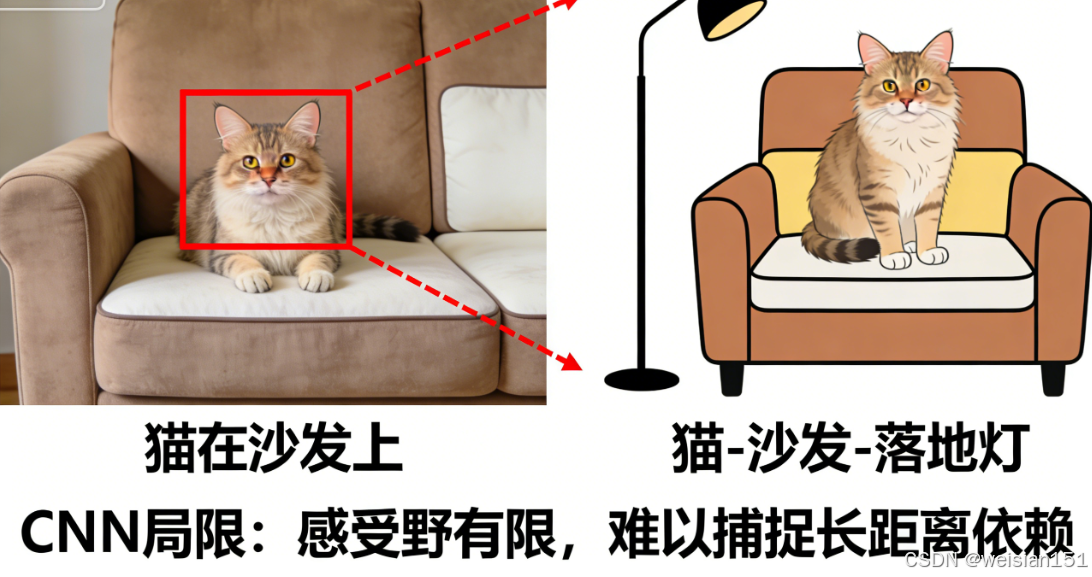
例如一张"猫坐在沙发上,旁边有个落地灯"的图片,CNN 能轻松认出"猫""沙发""落地灯"这些单个物体,但很难理解它们之间的关系:"猫在沙发上""落地灯在沙发旁边"。
再比如,判断一张图片是"室内"还是"室外",需要关注整个画面的全局特征(有没有天花板、窗户、天空),而 CNN 的局部感知模式,处理这种任务就很吃力。
2. 静态权重,无法"动态关注重点"
CNN 的卷积核是"静态"的------训练好之后,不管输入什么图片,卷积核都会以固定的方式滑动、提取特征。但现实中,不同图片的重点区域是不一样的。
比如两张图:
- 一张是"猫占满整个画面";
- 另一张是"猫很小,藏在一堆杂物里"。
对人类来说,我们会自动把注意力集中在猫身上;但 CNN 的卷积核会"一视同仁"地扫描整个画面,不管猫在哪里,都用同样的力度提取特征------这会导致有用的猫的特征被大量杂物的无关特征淹没,识别精度下降。
简单说:CNN 没有"注意力",不会主动"盯重点"。
3. 对长距离依赖"不敏感"
图像中有些特征的关联是"长距离"的。
比如一张"人举着苹果"的图片,"手"和"苹果"可能相隔很远,但它们是"手持苹果"的关联特征。CNN 靠卷积核一步步传递特征,长距离的关联信息很容易在传递过程中丢失,导致它无法准确捕捉这种"远距离依赖"。
这三个局限,让 CNN 停留在"识别物体"的层面,很难实现更高阶的"场景理解""逻辑推理"------而这正是 AI 走向更智能的关键。
就在 CNN 的局限逐渐显现时,2017 年,Google 发表了一篇划时代的论文《Attention Is All You Need》,提出了一种全新的网络架构------Transformer 。
它完全抛弃了 CNN 的卷积操作,靠"注意力机制"解决了上述所有问题。虽然最初是为自然语言处理(NLP)设计的,但后来被证明在视觉任务中同样强大。

三、Transformer 的初心:跳出"局部思维",拥抱"全局关联"
如果说 CNN 的哲学是 "分而治之" (先看局部,再拼整体),
那么 Transformer 的哲学就是 "万物互联"(每个元素都与其他元素对话)。
在正式拆解之前,我们先给 Transformer 一个最直白的定义(不用记专业术语):
Transformer 是一种靠"注意力机制"实现全局信息交互的神经网络架构。它的核心思想不是"局部拼接特征",而是"全局关联所有信息",然后根据任务需求,动态关注重点信息。
🌰 用生活化例子理解
- CNN 认图像"拼图":先把零散的拼图块(局部特征)拼起来,再看整体是什么;
- Transformer 认图像"看地图找目标":先把整个地图(整张图片)的所有信息都装进脑子里,然后根据"找猫"这个目标,直接把注意力集中在猫所在的区域,同时还能记住猫和周围环境(沙发、落地灯)的关系。

CNN 式的处理会逐字逐句提取特征,很难确定"它"指的是"苹果";
而 Transformer 会通过注意力机制,直接关联"它"和"苹果"的位置,轻松理解这种指代关系------这就是"全局关联"的优势。
⚠️ 这里要强调一个关键点:
Transformer ≠ 注意力机制 。注意力机制早在 2014 年就出现了,而 Transformer 是第一个把"注意力"作为核心,完全抛弃卷积、循环结构的架构------这也是它能实现"全局思考"的关键。
它的核心思想极其简洁却强大:
不要预设结构,不要滑动窗口,直接让输入中的每一个词(或像素)都能"看到"其他所有位置,并根据重要性动态分配注意力。
这种机制,叫做 自注意力(Self-Attention)。
🌰 再举一个经典例子
想象你在读这句话:
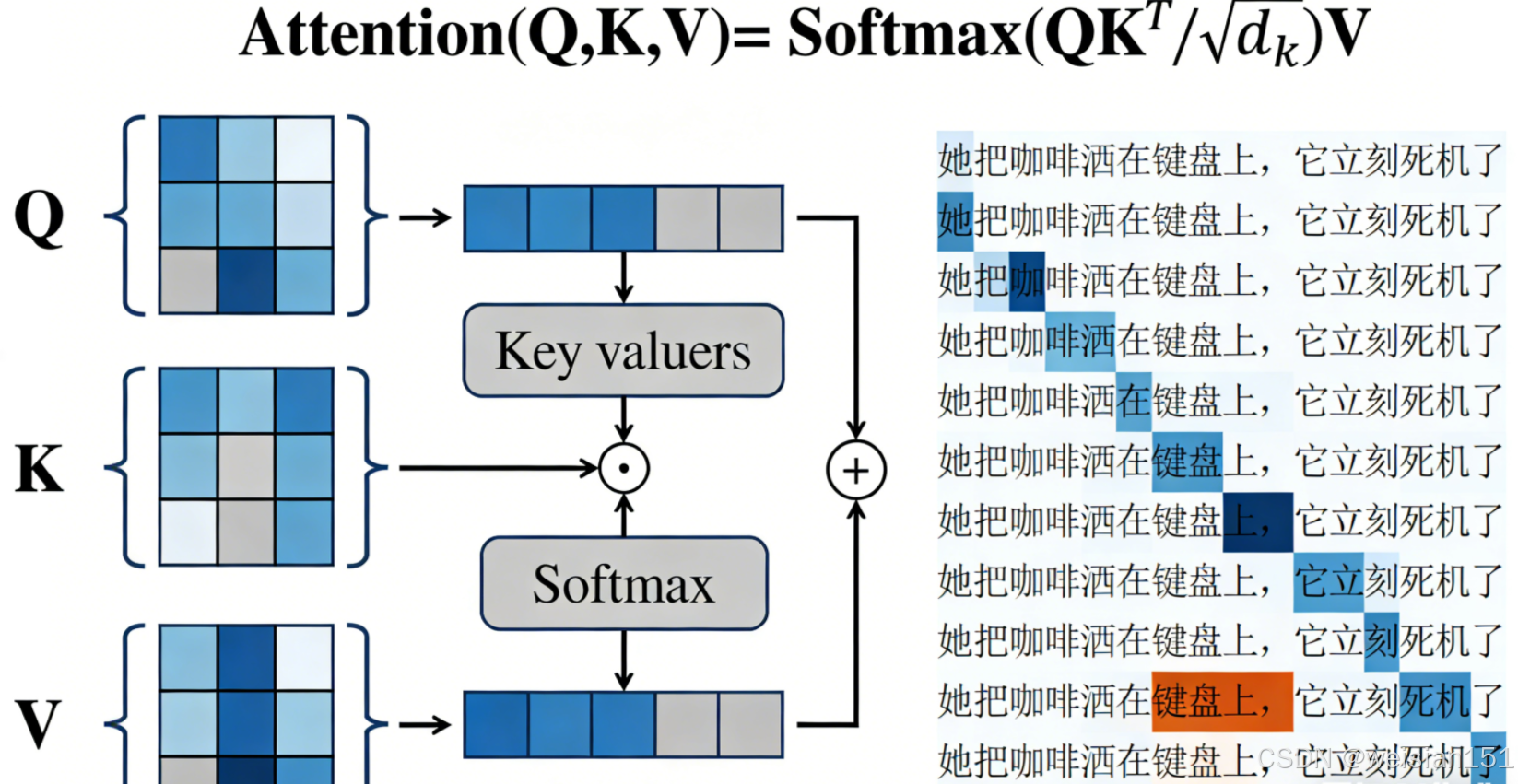
"她把咖啡洒在键盘上,它立刻死机了。"
你一眼就知道,"它"指的是"键盘",而不是"咖啡"。
为什么?因为你同时看到了整句话,并在脑中建立了词与词之间的关联。
而 CNN 或 RNN 就像戴着隧道视野的眼镜:
- RNN:从左到右逐字读,读到"它"时,可能已经忘了"键盘";
- CNN:只看"它"前后几个词,可能误判为"咖啡"。
但 Transformer 一上来就把整句话摊开,让"它"直接和"键盘""咖啡""死机"对话,然后说:
"哦,'死机'通常和'键盘'相关,所以'它'=键盘。"
✅ 这就是 全局建模 + 动态聚焦 的力量。
四、Transformer 的核心:自注意力机制(Self-Attention)
要理解 Transformer,必须搞懂 自注意力。别被名字吓到,它其实是一个"智能配对系统"。
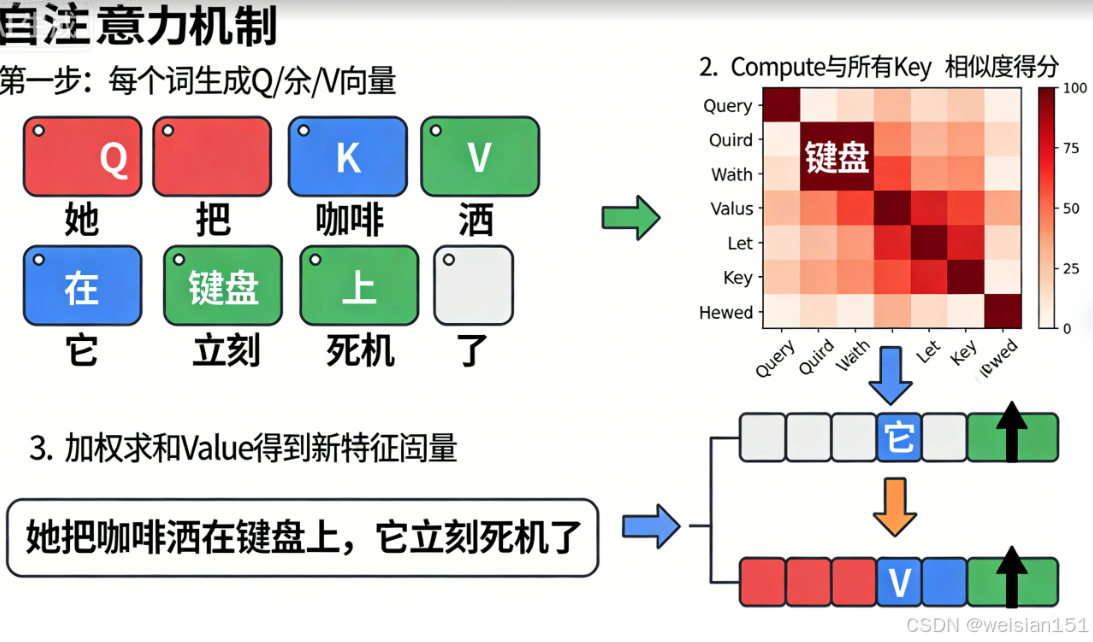
步骤 1:给每个词三个身份卡 ------ Query, Key, Value
假设输入是一句话,包含 n 个词。Transformer 会给每个词生成三组向量:
- Query(查询):代表"我想找什么";
- Key(键):代表"我能提供什么";
- Value(值) :代表"我的实际内容"。

类比:就像社交软件上的个人资料。
- Query = 你的择友标准("想找爱读书的人");
- Key = 别人的标签("我爱读书");
- Value = 别人的真实信息(头像、简介、动态)。
步骤 2:计算"匹配度" → 得到注意力权重
对于词 A,它会拿自己的 Query 去和所有词的 Key 做点积(相似度计算),得到一组分数。
分数越高,说明越相关。
然后通过 Softmax 把这些分数变成概率权重(总和为 1)。

步骤 3:加权求和 → 输出"融合上下文"的新表示
用这些权重,对所有词的 Value 做加权平均,得到词 A 的新向量表示。
这个新向量,已经融合了整句话的信息,并且重点突出了与 A 最相关的词。
💡 关键优势:
- 并行计算:所有词可以同时做上述操作(不像 RNN 必须顺序处理);
- 长距离建模:无论两个词相隔多远,都能直接建立联系;
- 动态聚焦:不同任务、不同上下文,注意力分布自动调整。
五、拆解 Transformer 核心:从"输入"到"输出",三步看懂工作流程
Transformer 的架构看起来比 CNN 复杂,但核心逻辑很清晰。
我们以"用 Transformer 识别一张猫的图片"为例,把它的工作流程拆解成三个核心步骤,每个步骤都用通俗的类比说明。
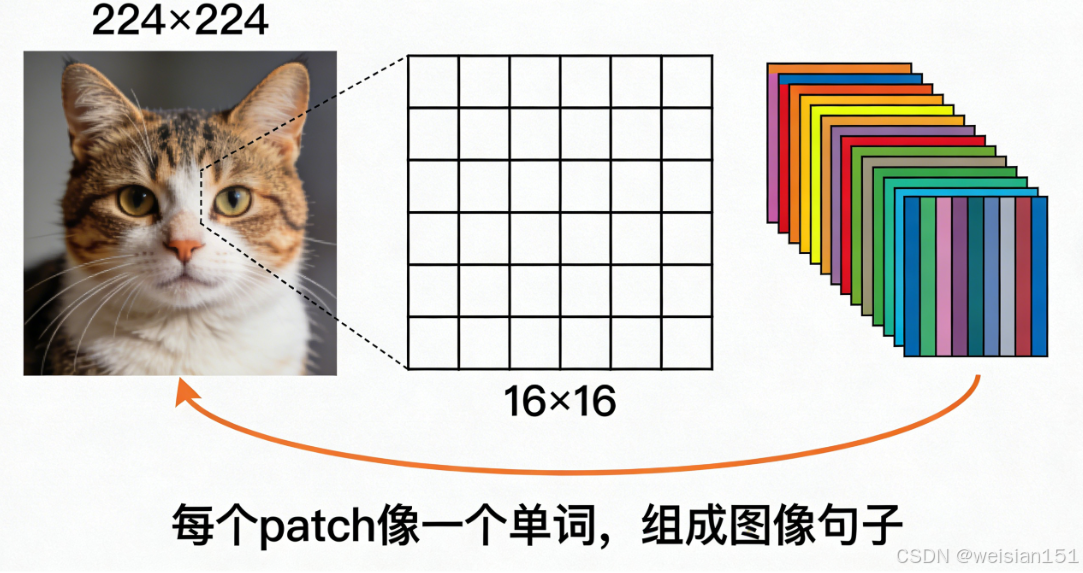
前提 :Transformer 本身是为"序列数据"(如文字)设计的,而图像是"网格数据"。
所以在视觉任务中,需先做一步 "图像转序列" :
把 224×224 的图像切成 16×16 的小 patches(补丁),每个 patch 展平后映射为向量。
这样,整张图片就变成了一个 patch 向量序列(如 14×14 = 196 个向量)。
第一步:嵌入层(Embedding)+ 位置编码(Positional Encoding)
------给"小照片"贴标签、记位置
这一步的核心是两个工作:
-
嵌入层(Embedding) :
把每个 patch 向量(比如"这是一块有毛的区域")升级成更高维的"特征描述"(如"灰色、毛茸茸、边缘不规则")。
通过全连接层,将低维 patch 向量转换为高维嵌入向量(如 768 维 → 1024 维),承载更多信息。
-
位置编码(Positional Encoding) :
Transformer 本身没有"顺序感"。如果不加位置信息,它会把 196 个 patch 当成无序集合------就像打乱拼图块再拼,永远拼不出原图。
位置编码通过为每个 patch 添加一个"位置向量"(由其在序列中的索引决定),让模型知道每个 patch 在原始图像中的位置。
📌 位置编码是关键!
没有它,Transformer 会认为 "猫追狗" 和 "狗追猫" 是一回事。
第二步:多头注意力层(Multi-Head Attention)
------Transformer 的"核心大脑",实现全局关联
这是 Transformer 最核心的部分。

1. 注意力机制:给每个 patch "找关系、分权重"
逻辑如下:
- 对于某个 patch(如"猫耳朵",作为 Query Q),
与所有 patch 的 Key(K)计算相关性分数; - 分数高的(如"猫眼睛""猫脸轮廓")获得高权重;
- 用权重对所有 Value(V)加权求和,得到"猫耳朵"的新特征。
✅ 结果:新特征不仅包含"猫耳朵"本身,还融合了与之相关的全局信息。
2. 多头注意力:多维度"找关系",更全面
"多头"就是重复多次注意力机制(如 8 次、12 次),每次关注不同维度的相关性:
- 头1:关注形状关联;
- 头2:关注纹理关联;
- 头3:关注位置关联......
最后将所有头的输出拼接融合,得到更丰富、更全面的表示。
✅ 类比:你问 8 个不同领域的专家同一个问题,综合他们的意见做决策。
第三步:前馈网络(Feed-Forward Network)+ 归一化(Normalization)
------优化特征,输出结果
-
前馈网络(FFN) :
两个全连接层 + ReLU 激活函数,对每个 patch 的全局特征做非线性变换,实现"精加工"。
-
归一化(LayerNorm) :
将特征数值调整到同一范围,提升训练稳定性。
此外,Transformer 架构中还包含:
-
残差连接(Residual Connection) :
输入直接加到输出上,避免深层网络梯度消失,便于训练上百层模型。
-
编码器 vs 解码器:
- 编码器:理解输入(如图像、文本);
- 解码器 :生成输出(如文字、图像)。
视觉任务(如图像分类)通常只用编码器;文生图等任务则需编码器+解码器。
-
掩码注意力(Masked Attention) :
用于解码器,防止模型"偷看未来"(如生成第3个词时不能看到第4个词)。
🔧 这些工程技巧,是 Transformer 能大规模训练的关键。
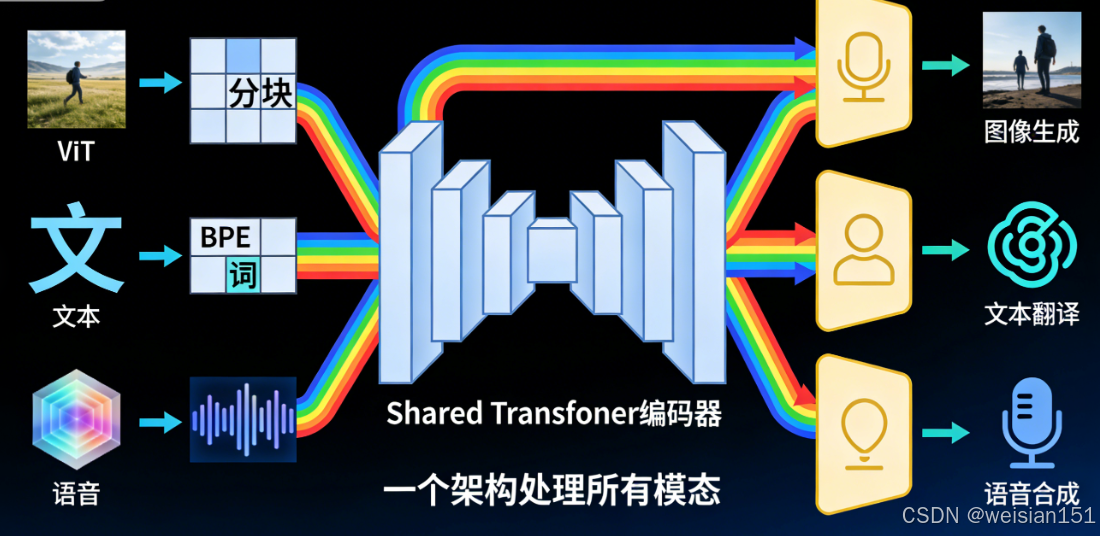
六、从 NLP 到 CV:Transformer 如何"跨界"成功?
Transformer 最初是为机器翻译设计的,但它很快证明了自己是一种通用序列建模工具。
📚 在自然语言处理(NLP)中
- BERT(2018):仅用编码器,通过掩码语言建模预训练,刷新多项 NLP 任务纪录;
- GPT 系列:仅用解码器,通过自回归生成,开启大语言模型时代;
- 如今,几乎所有主流 NLP 模型都是 Transformer 的变体。
🖼️ 在计算机视觉(CV)中
2020 年,一篇《An Image is Worth 16x16 Words 》震惊学界------
研究者把图像切成 16×16 的小块,当成"词"输入 Transformer,结果在 ImageNet 上媲美甚至超越 CNN!
这就是 Vision Transformer(ViT)。
✅ ViT 的成功说明:只要数据够多,Transformer 不需要 CNN 那样的归纳偏置,也能学会"看图"。
但现实是:ViT 在小数据集上表现不如 CNN(因为缺乏局部先验)。于是,混合架构兴起:
- ConvNeXt:用 CNN 的结构,注入 Transformer 的训练技巧;
- Swin Transformer:引入"局部窗口注意力",兼顾效率与性能;
- MobileViT:为移动端优化的轻量 ViT。
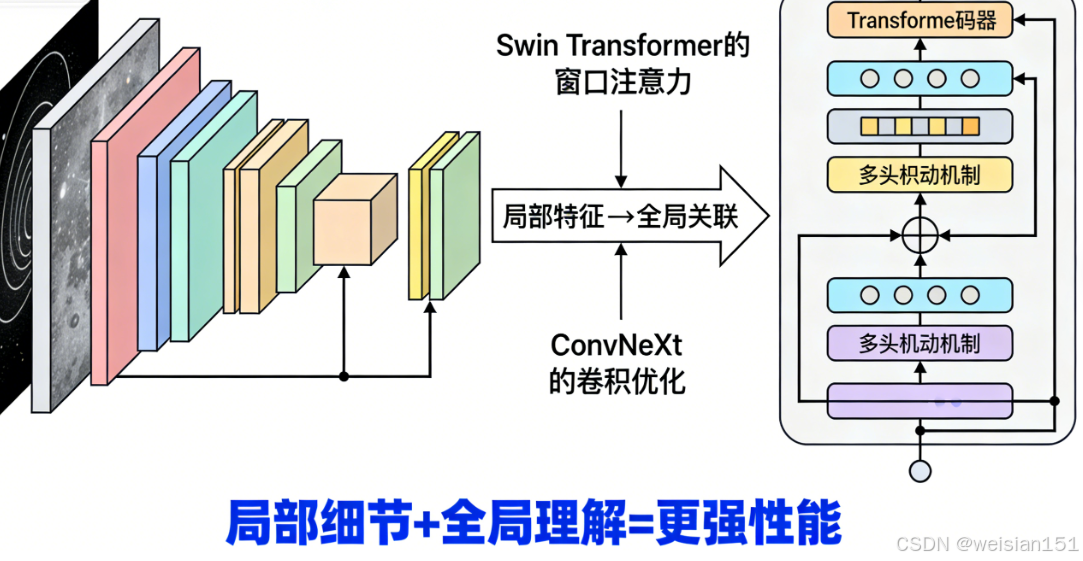
🔄 今天,CNN 和 Transformer 不再是对立,而是互补共存。
七、Transformer 为什么这么强大?四大核心优势
| 优势 | 说明 | 对比 CNN / RNN |
|---|---|---|
| 全局建模能力 | 任意两个元素可直接交互,无距离限制 | CNN 感受野有限,RNN 信息衰减 |
| 动态注意力 | 根据输入内容自动聚焦重点区域 | CNN 卷积核静态,无法自适应 |
| 高度并行化 | 所有位置同时计算,训练速度极快 | RNN 必须顺序处理,无法并行 |
| 通用性 | 可处理文本、图像、音频、代码等任何序列 | CNN 专精网格数据,RNN 适合短序列 |
💡 更重要的是:Transformer 提供了一种统一的建模范式 。
无论是写诗、画图、编程、还是控制机器人,底层都可以是同一个架构。

八、Transformer 的典型应用场景
你每天接触的 AI,很多都运行在 Transformer 之上:
- 智能助手:Siri、小爱同学背后的语音识别与语义理解;
- 机器翻译:Google Translate、DeepL 的核心引擎;
- 内容生成:ChatGPT、文心一言、通义千问等大模型;
- 搜索推荐:抖音、淘宝的个性化推荐系统;
- 代码辅助:GitHub Copilot 自动生成代码;
- 多模态理解:CLIP 模型能同时理解图和文,实现"以图搜文"或"以文生图"。

具体领域应用
1. 基础视觉任务
- 图像分类:ViT、DeiT、Swin Transformer;
- 目标检测:DETR 直接用 Transformer 预测边界框,省去复杂后处理;
- 语义分割:SETR 等模型实现端到端像素级预测。
2. 多模态任务
- 图文对齐:CLIP 实现跨模态检索;
- 文生图:DALL·E 3、MidJourney 用 Transformer 编码文本、解码图像;
- 图文问答(VQA):GPT-4V 能回答"这张图片里的猫在做什么"。
3. 工业界落地
- 自动驾驶:理解道路场景逻辑("行人正在过马路");
- 医疗影像:结合 CT 图像与病历文本辅助诊断;
- 智能安防:识别异常行为("翻越围墙""聚集斗殴")。
🌐 Transformer 已成为 AI 时代的"通用处理器"。
九、Transformer 的局限与未来:它不是 CNN 的"替代品",而是"互补品"
尽管强大,Transformer 也面临现实瓶颈:
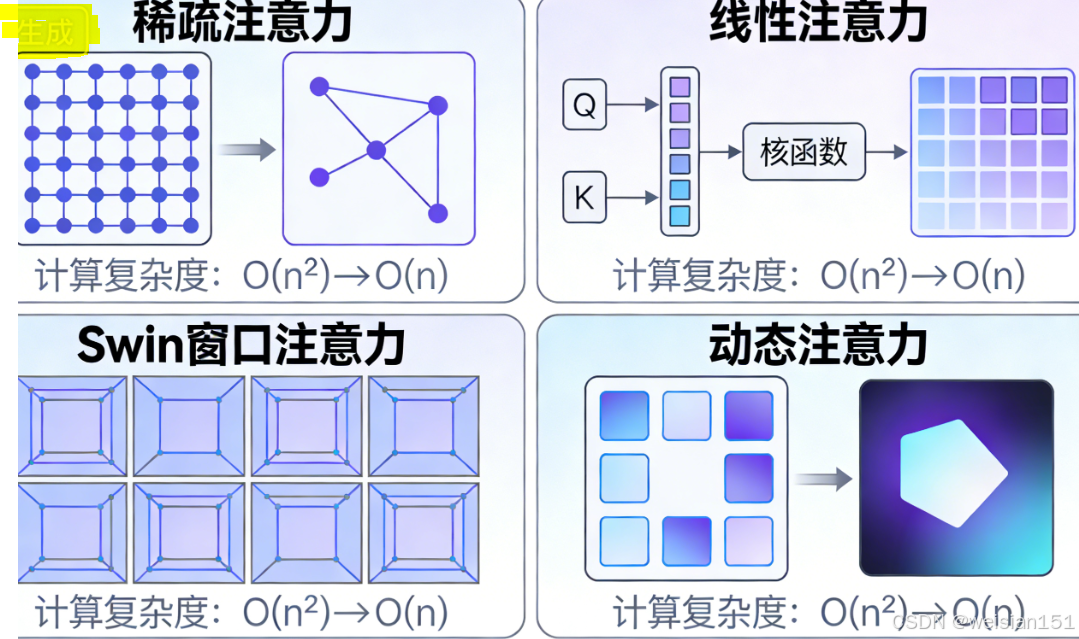
❗ 1. 计算复杂度高
- 自注意力的计算量是 O(n²),n 是序列长度;
- 图像若按 ViT 切成 196 个 patch,注意力矩阵就有 196×196 = 38,416 个元素;
- 对长视频、高分辨率图像,成本极高。
→ 解法:稀疏注意力(Longformer)、局部窗口(Swin)、线性注意力(Performer)。
❗ 2. 缺乏归纳偏置
- CNN 天然知道"邻近像素相关",Transformer 一切从零学起;
- 小数据场景下,容易过拟合或学偏。
→ 解法:混合架构(CNN + Transformer)、引入结构先验。
❗ 3. 位置编码的局限
- 原始正弦位置编码难以泛化到比训练时更长的序列;
- 新方法如 RoPE(旋转位置编码)正在改善这一点。
🔮 未来方向:
- 更高效的注意力机制;
- 多模态统一建模(文本+图像+音频+3D);
- 与记忆、推理、规划模块结合,迈向通用人工智能(AGI)。
十、给初学者的学习建议
如果你已经理解了 CNN,再学习 Transformer 会轻松很多。结合我的经验,给新手朋友以下建议:
1. 先巩固 CNN 基础,再理解"为什么需要 Transformer"
- 回顾 CNN 的核心原理与局限;
- 思考"全局依赖"在哪些任务中至关重要(如指代消解、场景理解)。
2. 从 ViT 入手,复现简单模型
- ViT 是 Transformer 在视觉领域的入门模型;
- 推荐用 PyTorch 复现基础 ViT,熟悉"图像→patch→嵌入→注意力→分类"全流程。
3. 深入理解注意力机制的数学原理
- 掌握 Q、K、V 的计算、点积、Softmax 归一化;
- 数学其实很简单,理解后能真正明白"为何能捕捉关联"。
4. 结合多模态任务实践
- 尝试用 CLIP 做"以文搜图",用 DETR 做目标检测;
- 体验 Transformer 的通用架构优势。
5. 善用工具与资源
- 精读《Attention Is All You Need》;
- 使用 BertViz 查看注意力热力图;
- 用 Hugging Face 的
transformers库,几行代码调用 BERT、ViT,快速微调。
十一、总结:从 CNN 到 Transformer,AI 的"思考方式"在进化
Transformer 不仅仅是一个神经网络架构,它代表了一种新的 AI 设计哲学:
用统一的、数据驱动的机制,替代手工设计的归纳偏置。
- CNN 教会了 AI 如何观察,
- Transformer 则教会了 AI 如何思考。
前者像一个专注的画家,一笔一画勾勒细节;
后者像一个沉思的哲人,俯瞰全局,洞察关联。
它们不是取代关系,而是认知层次的跃迁。

正如人类既需要显微镜看清细胞,也需要望远镜眺望星空------
未来的 AI 系统,必将融合局部感知 与全局推理,走向更强大的通用智能。
从 CNN 到 Transformer,不是"谁替代谁"的革命,
而是 AI "思考方式"的进化------
从"局部拼接"到"全局关联",
从"单一模态"到"多模态融合"。
正是这种进化,让 AI 从"识别物体"走向了"理解场景",最终支撑起现在的大模型时代。
如果你看完这篇文章,能对着一张图片说:
"哦,Transformer 大概是先把图片剪成小 patches,再让每个小 patch 都和其他 patch 交流,最后找到重点区域并理解它们的关系吧!"
那你就已经真正理解 Transformer 的核心了。
我是 Weisian,持续为你拆解 AI 背后的逻辑。
如果你觉得这篇文章帮你真正理解了 Transformer,欢迎点赞、收藏,或转发给正在学习深度学习的朋友。
有任何问题,也欢迎在评论区留言交流!