引言:数据驱动的零售决策新时代
在电商崛起与零售业快速发展的背景下,精准的销售预测已成为企业库存管理、供应链优化和营销策略制定的核心能力。本文基于真实Kaggle竞赛数据集(2013-2015年历史销售记录),分享一套完整的预测流程,涵盖数据探索、模型构建与性能对比全流程。
一、数据全景扫描与特征工程
1.1 数据架构解析
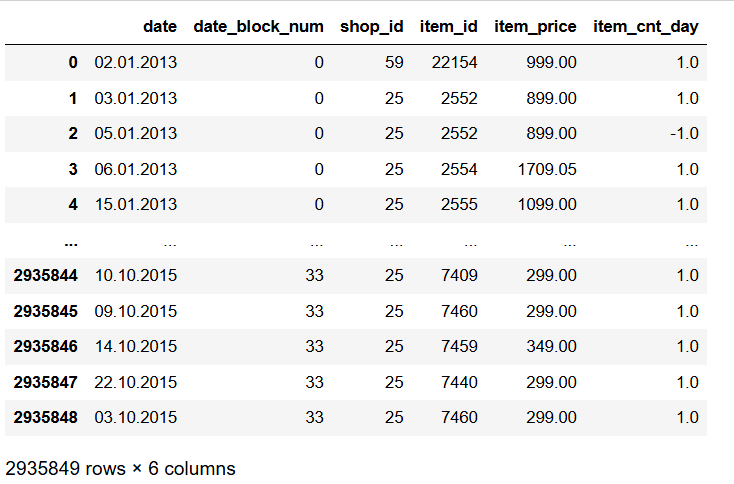
使用的数据集来源于Kaggle官网中,该数据集中包含了每日的历史销售数据,旨在预测测试集中每个商店销售的产品总量。sales_train.csv训练集,包含从2013年1月到2015年10月的每日历史数据。test.csv测试集,需要预测2015年11月这些商店和产品的销售量。
数据集包含5个核心文件:
-
sales_train.csv:293万条日粒度销售记录(2013.1-2015.10) -
辅助表:商店/商品/商品类别元数据
-
关键字段:
-
date_block_num:时序编码(2013年1月=0,每月+1) -
item_cnt_day:日销售量(预测目标) -
item_price:动态价格特征 -
数据字段:ID:表示测试集中的(商店,产品)元组的ID。shop_id:商店的唯一标识符。item_id:产品的唯一标识符。item_category_id:产品类别的唯一标识符。item_cnt_day:销售的产品数量。预测的目标是该度量的月度总量。item_price:产品的当前价格。date:日期,格式为dd/mm/yyyy。date_block_num:一个连续的月份编号,便于处理。2013年1月为0,2013年2月为1,...,2015年10月为33。item_name:产品名称。shop_name:商店名称。item_category_name:产品类别名称。
-
1.2 数据融合与清洗
由于上述表格较多,表之间相互关联,因此对表进行合并。第一步将sales_train_df和shops_df两个数据框按照shop_id列进行左连接(left join)。这样做的目的是将训练集中的商店信息与商店数据框进行合并,将商店的补充信息添加到训练集中的每一行。第二步将第一步合并后的数据框train_df与items_df数据框按照item_id列进行左连接。这样做的目的是将产品信息与训练集合并,将产品的补充信息添加到训练集的每一行。第三步将第二步合并后的数据框train_df与item_categories_df数据框按照item_category_id列进行左连接。这样做的目的是将产品类别信息与训练集合并,将产品类别的补充信息添加到训练集的每一行。最终,train_df数据框将包含训练集的所有信息,包括销售数据、商店信息、产品信息和产品类别信息,最终表中共计2935849行10列数据信息。
python
train_df = sales_train_df.merge(shops_df, on='shop_id', how='left')
train_df = train_df.merge(items_df, on='item_id', how='left')
train_df = train_df.merge(item_categories_df, on='item_category_id', how='left')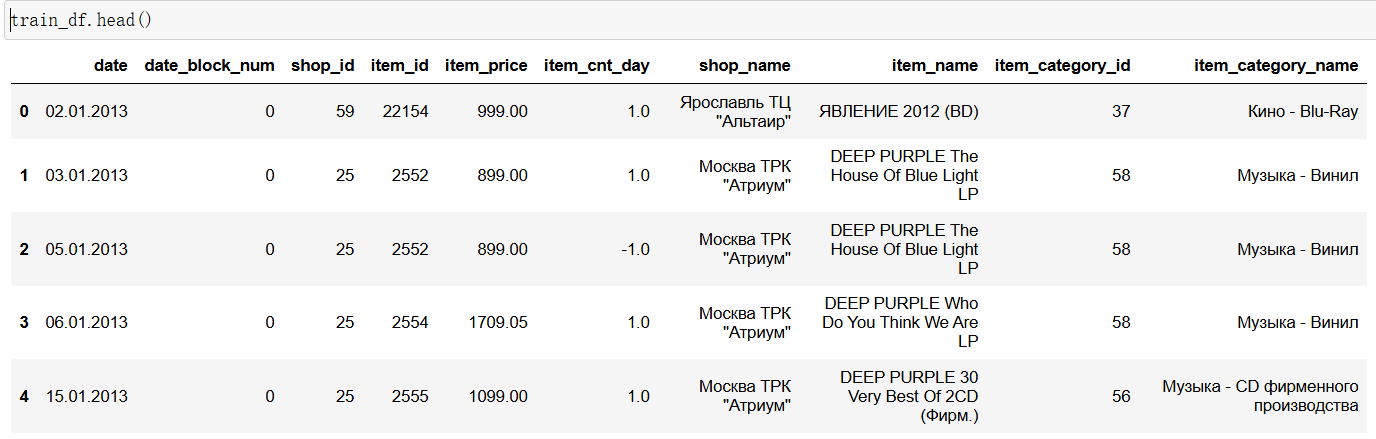
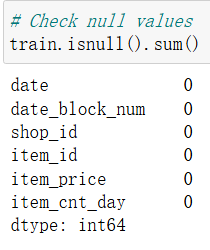
- ① 缺失值检测:全字段无缺失(见图1)
- ② 异常值处理:通过3σ原则过滤价格异常点;排除了位于阈值范围之外的数据点,这些数据点被认为是异常值。箱线图可以显示数据的分布情况以及异常值的存在。
python
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
# Target column chart with outliers
sns.boxplot(train["item_price"])
plt.title("Boxplot graph - With outliers")
plt.grid(False)
plt.show()
### Outlier removal
# interest column
Q1 = train['item_price'].quantile(0.25)
Q3 = train['item_price'].quantile(0.75)
IQR = Q3 - Q1
# Set the thresholds to consider a point as an outlier
lower_bound = Q1 - 0.3 * IQR
upper_bound = Q3 + 0.3 * IQR
# Remove outliers
data = train[(train['item_price'] >= lower_bound) & (train['item_price'] <= upper_bound)]
# Calculate the limits for each variable
def remove_outliers(train, column, m=3):
mean = np.mean(train[column])
std_dev = np.std(train[column])
lower_bound = mean - m * std_dev
upper_bound = mean + m * std_dev
return lower_bound, upper_bound
# Define the variables of interest
columns = ["date_block_num","shop_id","item_id", "item_cnt_day","item_price"]
# Set a standard deviation threshold multiplied by m
m = 3
# Calculate limits for each variable and remove outliers
for columns in columns:
lower_bound, upper_bound = remove_outliers(data, column, m)
data = train[(train[column] >= lower_bound) & (train[column] <= upper_bound)]
# Reset the index
data.reset_index(drop=True, inplace=True)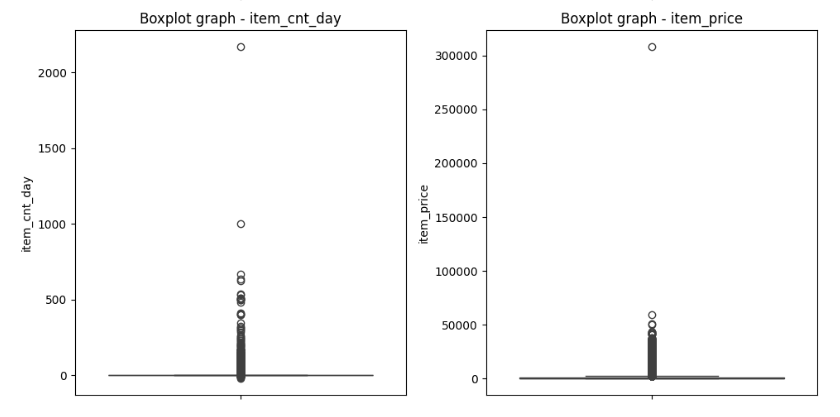
- ③ 将时间列转为年月类型:首先,将日期列转换为日期时间格式,并从中提取出月份和年份信息。然后,按照年份、月份、商店和产品对销售数据进行分组,并计算每月每个商店和产品的销售总量。最终的结果是生成了一个包含月度销售总量的数据框,这将作为模型的训练数据,用于分析销售趋势和模式。

-
④ 将数据进行标准化。该数据集属于大数据集,标准化具有以下好处:
-
消除尺度差异:大数据集中的不同特征可能具有不同的尺度范围,例如某些特征可能取值在几十到几百之间,而其他特征可能在几千到几百万之间。这种尺度差异可能会影响某些机器学习算法的性能,导致对取值范围较大的特征给予过多权重。通过标准化,可以将所有特征转换为相同的尺度,消除尺度差异,确保每个特征对模型的贡献平衡。
-
提高算法的收敛速度:数据标准化可以加快算法的收敛速度,使优化过程更快地达到最优解。
二、关键业务洞察可视化
1. 周期性规律挖掘
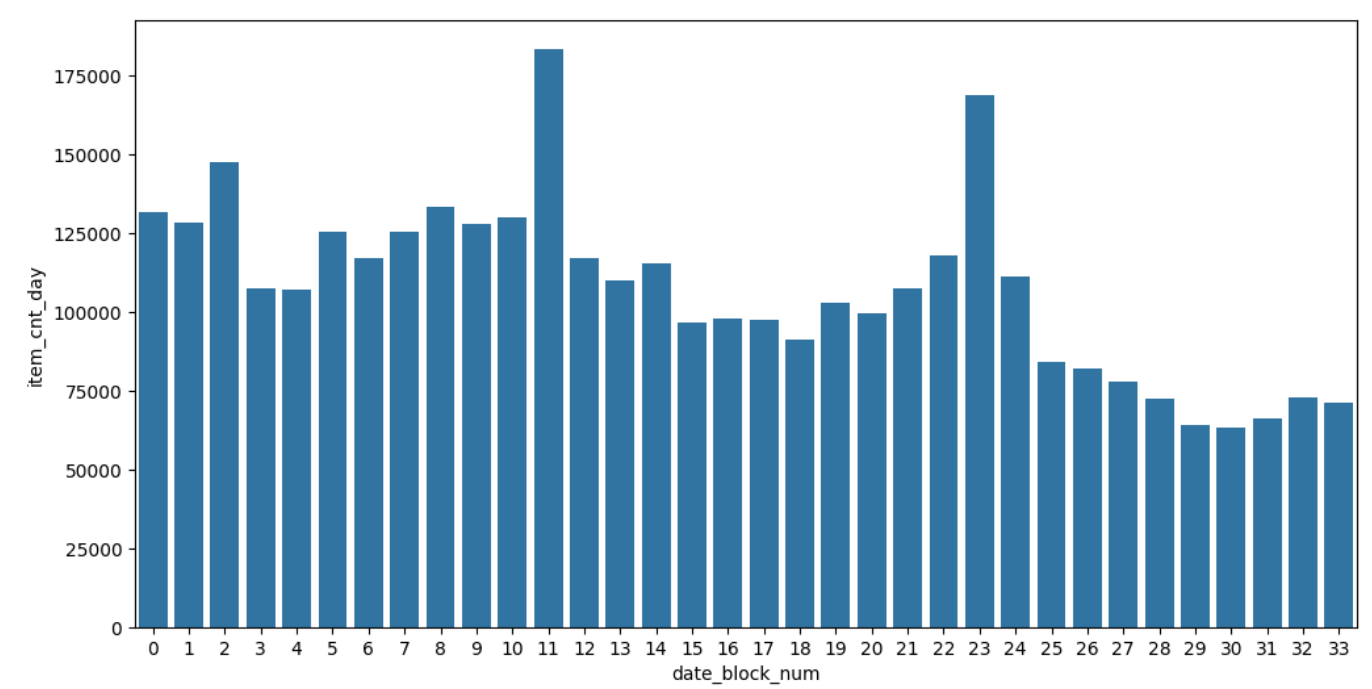
-
显著峰值:每年12月(假日经济效应)
-
稳定基线:非年末月份销量波动≤15%
2. 渠道与品类分析
python
figure, ax = plt.subplots()
figure.set_size_inches(12, 6)
group_shop_sum_df = train_df.groupby('shop_id').agg({'item_cnt_day': 'sum'})
group_shop_sum_df = group_shop_sum_df.reset_index()
group_shop_sum_df = group_shop_sum_df[group_shop_sum_df['item_cnt_day'] > 10000]
sns.barplot(x='shop_id', y='item_cnt_day', data=group_shop_sum_df)
ax.tick_params(axis='x', labelrotation=90)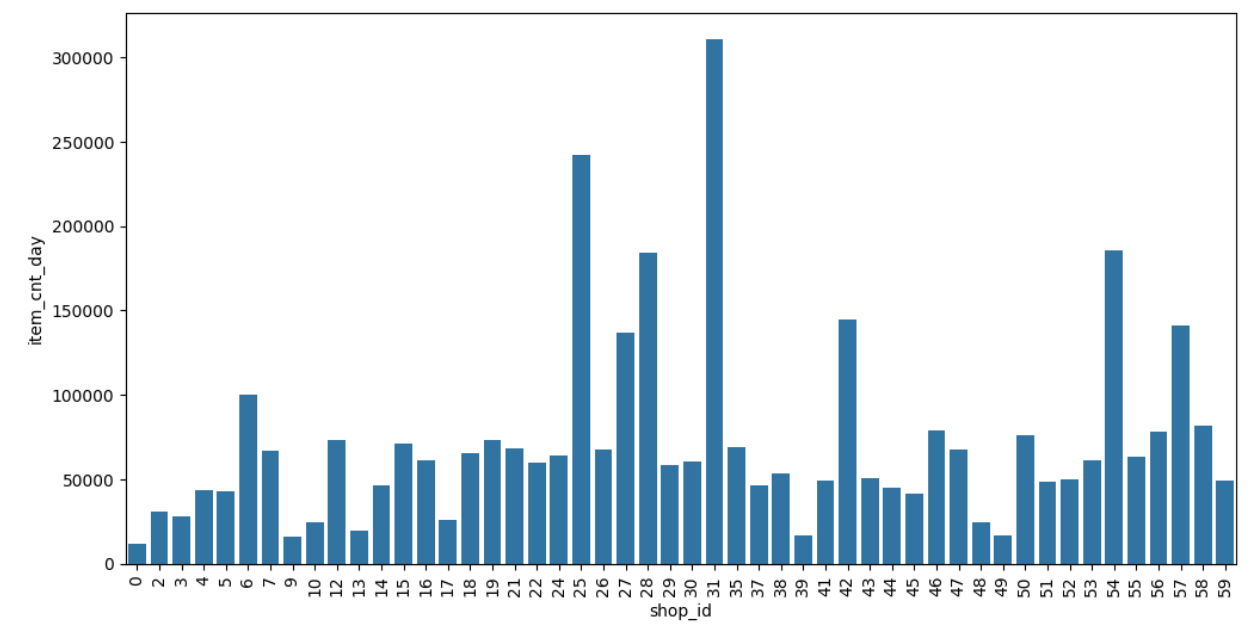
-
头部商店:莫斯科ТРК "Атриум"(25)、ТЦ "Семеновский"(31)
-
长尾分布:60%商店贡献<10%总销量
三、多模型对比实验
1. 四类模型架构
| 模型类型 | 核心参数 |
|---|---|
| LSTM | 2层LSTM(50神经元)+Dropout(0.2) |
| 随机森林 | sklearn默认参数 |
| 决策树 | sklearn默认参数 |
| XGBoost | 默认参数 |
2. 性能对比结论
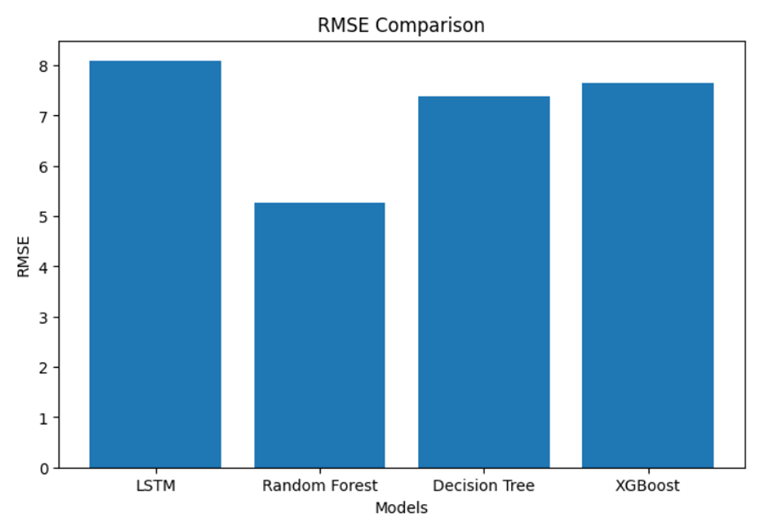
由图中可知:
- 冠军模型 :随机森林(RMSE=5.273)
- 时序模型表现 :LSTM未达预期(RMSE=8.089),需增加训练轮次
- 效率排序:决策树 > XGBoost > 随机森林 > LSTM
随机森林RMSE值更低,表示在四种模型中,其效果最好,而针对于时序处理的LSTM模型效果没有随机森林好,可能是由于数据集过大,只训练了20轮,未能使模型充分训练,因此效果较差。
四、未来优化方向
-
特征增强
-
引入外部数据:天气/促销活动/宏观经济指标
-
构建滞后特征(lag features)捕捉短期依赖
-
-
模型升级
python
# 深度集成方案
ensemble_model = StackingRegressor([
('rf', RandomForestRegressor()),
('xgb', XGBRegressor()),
('lstm', KerasRegressor(build_lstm_model))
])