知识点回顾
- 规范的文件命名
- 规范的文件夹管理
- 机器学习项目的拆分
- 编码格式和类型注解
如何把一个文件,拆分成多个具有着独立功能的文件,然后通过import的方式,来调用这些文件。这样具有几个好处:
1. 可以让项目文件变得更加规范和清晰
2. 可以让项目文件更加容易维护,修改某一个功能的时候,只需要修改一个文件,而不需要修改多个文件。
3. 文件变得更容易复用,部分通用的文件可以单独拿出来,进行其他项目的复用。
零基础 Python 学习:文件的规范拆分和写法
你可以把写 Python 项目想象成整理自己的房间:文件命名是给物品贴标签,文件夹管理是给物品分区域,机器学习项目拆分是给复杂家具分部件,编码格式和类型注解是给物品写使用说明。接下来我会用最通俗的话,拆成一个个小知识点,配具体例子和代码,保证你能看懂。
一、规范的文件命名:给文件贴 "好认的标签"
首先要明确:Python 里的文件命名不是随便起的,就像你不会把 "牙刷" 标成 "毛巾" 一样,好的文件名能让你(或别人)一眼知道文件是干啥的,还能避免电脑 "认不出" 文件的问题。
核心规则(5 条,每条都配例子 + 原因)
1. 全用小写字母 ,别用大写
- 原因 :不同操作系统(比如 Windows 和 Linux)对大小写的识别不一样,比如
Data.py和data.py,Linux 会当成两个文件,Windows 却当成一个,容易乱套。 - 正确例子 :
data_process.py(处理数据的文件) - 错误例子 :
DataProcess.py、DATA.PY
2. 多个单词用下划线_ 分隔,别用空格 / 横线
- 原因 :Python 里如果文件名有空格,导入文件时会报错(比如
image recognition.py,导入时写import image recognition会被当成两个模块);横线-在 Python 里是减号,也会出错。 - 正确例子 :
model_train.py(训练模型的文件) - 错误例子 :
image recognition.py(空格)、model-train.py(横线)
3. 别用 Python 的 "专用词"(关键字)
- 原因 :Python 有自己的 "保留字"(比如
def、class、if、for),这些词是 Python 自己用的,用它们当文件名会导致代码报错。 - 常见关键字 :
def、class、if、else、while、import等(不用记全,遇到报错再查就行) - 正确例子 :
func_calculate.py(计算函数的文件) - 错误例子 :
def.py、class.py
4. 别用特殊字符(!@#$%^&*() 等)和中文
- 原因 :特殊字符在不同系统里可能被当成 "非法字符",中文在某些老环境里会显示成乱码(比如
数据处理.py可能变成????.py)。 - 正确例子 :
user_info.py(存储用户信息的文件) - 错误例子 :
数据处理.py(中文)、calc!num.py(特殊字符)
5. 见名知意:从名字能猜到文件功能
- 原因 :比如你半年后再看代码,看到
calculate_average.py就知道是计算平均值的,不用打开文件看内容。 - 正确例子 :
log_print.py(打印日志的文件)、model_evaluate.py(评估模型的文件) - 错误例子 :
test1.py、file.py(啥也看不出来)
总结:文件命名口诀
小写字母为主,下划线连单词,避开关键字和特殊符,见名知意就对了
二、规范的文件夹管理:给文件分 "区域放"
如果把项目比作你的卧室,文件夹就是衣柜、书架、抽屉:衣服放衣柜,书放书架,袜子放抽屉,找东西才快。如果所有文件都堆在一个文件夹里,就像把衣服、书、袜子混在地上,找的时候能急哭。
第一步:先懂 "项目根目录"
一个项目的所有文件都放在一个根文件夹 里(比如叫my_python_project),这是项目的 "总大门",所有子文件夹都在里面。
第二步:通用项目的文件夹结构(新手必学)
不管是普通 Python 项目还是简单小工具,都可以按这个结构来,绝对不会乱:

每个文件夹的 "大白话作用"
| 文件夹名 | 作用(通俗版) | 举个例子 |
|---|---|---|
| src | 放核心代码,项目的 "心脏" | main.py(总开关)、各种业务代码 |
| src/utils | 放通用工具,代码的 "螺丝刀" | 计算、日志、数据转换等能重复用的代码 |
| data/input | 放原始数据,"原材料仓库" | 从网上爬的、用户上传的原始数据 |
| data/output | 放运行结果,"成品仓库" | 代码计算后生成的文件、图表 |
| docs | 放使用说明,"产品说明书" | 告诉别人怎么运行你的项目 |
| tests | 放测试代码,"质检工具" | 检查代码有没有 bug,比如计算函数是否算错 |
新手实操:怎么创建这个结构?
- 在电脑桌面新建一个文件夹,命名为
my_python_project(根目录); - 在里面新建
src、data、docs、tests四个文件夹; - 在
src里新建utils文件夹和main.py文件; - 在
data里新建input和output文件夹; - 剩下的文件(比如
data_utils.py)可以后续写代码时新建。
这样一来,你的项目就像 "整理得井井有条的房间",再也不会乱了。
三、机器学习项目的拆分:给复杂项目 "拆成零件"
机器学习项目比普通项目复杂(要处理数据、做特征、训练模型、评估模型),就像组装一台电脑,要把主板、CPU、显卡、内存分开装,不能混在一起。
核心思路:按 "机器学习流程" 拆分
机器学习的基本流程是:加载原始数据 → 处理数据(特征工程) → 训练模型 → 评估模型 → 保存模型,我们就按这个流程来分文件夹和文件。
机器学习项目的标准结构(新手简化版)

每个文件的 "协作流程"(用代码伪代码 + 通俗解释)
我们以 "学生成绩预测" 为例,看main.py怎么调用其他文件:
1. src/config.py(配置文件:存参数,改起来方便)
python
# -*- coding: utf-8 -*-
# 配置参数:学习率、训练次数、数据路径
LEARNING_RATE = 0.01 # 学习率(模型训练的速度)
TRAIN_EPOCHS = 100 # 训练次数
RAW_DATA_PATH = "data/raw/student_scores.csv" # 原始数据路径
PROCESSED_DATA_PATH = "data/processed/cleaned_scores.csv" # 处理后数据路径
MODEL_SAVE_PATH = "models/saved_models/score_model.pkl" # 模型保存路径2. data/data_loader.py(加载数据的文件)
python
# -*- coding: utf-8 -*-
import pandas as pd # 处理CSV数据的库(新手先知道有这个库就行)
def load_raw_data(data_path):
"""加载原始数据"""
data = pd.read_csv(data_path) # 读取CSV文件
print("成功加载原始数据,数据行数:", len(data))
return data
def save_processed_data(data, save_path):
"""保存处理后的数据"""
data.to_csv(save_path, index=False)
print("成功保存处理后的数据到:", save_path)3. features/feature_extraction.py(特征提取文件)
python
# -*- coding: utf-8 -*-
def process_features(data):
"""处理数据:去掉空值、提取有用特征"""
# 去掉空值(比如有的学生缺考,分数是空的)
data = data.dropna()
# 提取特征:比如只保留"数学分数""英语分数"作为预测特征
features = data[["math_score", "english_score"]]
# 提取目标:要预测的"总分"
target = data["total_score"]
return features, target4. models/model_train.py(训练模型的文件)
python
# -*- coding: utf-8 -*-
from sklearn.linear_model import LinearRegression # 线性回归模型(新手先知道就行)
import pickle # 保存模型的库
def train_model(features, target, save_path):
"""训练模型并保存"""
model = LinearRegression() # 创建模型
model.fit(features, target) # 用特征和目标训练模型
# 保存模型到指定路径
with open(save_path, "wb") as f:
pickle.dump(model, f)
print("模型训练完成并保存到:", save_path)
return model5. models/model_evaluate.py(评估模型的文件)
python
# -*- coding: utf-8 -*-
def evaluate_model(model, features, target):
"""评估模型:计算预测准确率(R²分数,越接近1越好)"""
score = model.score(features, target)
print("模型评估分数:", score)
return score6. src/main.py(总入口:一键运行所有步骤)
python
# -*- coding: utf-8 -*-
# 导入配置
from config import *
# 导入数据加载模块
from data.data_loader import load_raw_data, save_processed_data
# 导入特征提取模块
from features.feature_extraction import process_features
# 导入模型训练和评估模块
from models.model_train import train_model
from models.model_evaluate import model_evaluate
# 第一步:加载原始数据
raw_data = load_raw_data(RAW_DATA_PATH)
# 第二步:处理特征
features, target = process_features(raw_data)
# 第三步:训练模型
model = train_model(features, target, MODEL_SAVE_PATH)
# 第四步:评估模型
evaluate_model(model, features, target)
print("整个项目运行完成!")通俗总结:机器学习项目拆分
按 "数据→特征→模型→评估" 的流程,把每个步骤的代码放在单独的文件 / 文件夹里,总入口main.py负责调用所有步骤,就像工厂的流水线,每个工位只做一件事,效率高还不容易出错。
四、编码格式和类型注解:给代码加 "通用翻译" 和 "标签"
这部分是代码的 "基础保障":编码格式保证中文不乱码,类型注解让你知道 "变量 / 函数是干啥的"。
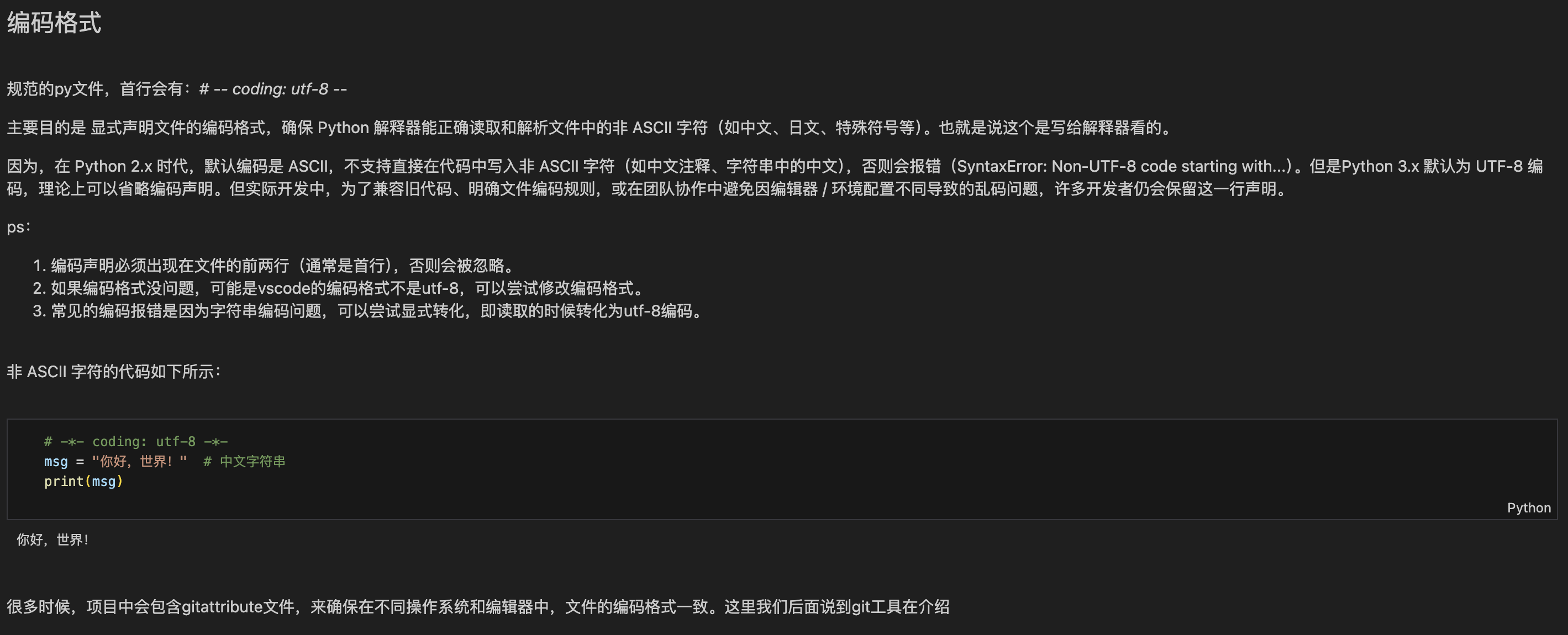
第一部分:编码格式:让电脑 "看懂" 中文
你可以把编码格式想象成"翻译规则":电脑只认识 0 和 1,要把中文(比如 "你好")转换成 0 和 1,就需要翻译规则。
1. 最常用的编码格式:UTF-8
UTF-8 是 "通用翻译规则",支持中文、英文、日文等所有语言,是 Python 的首选。
2. 如何声明编码格式?
在 Python 文件的第一行 (如果第一行是#!/usr/bin/env python3,就放在第二行)加上:
python
# -*- coding: utf-8 -*-3. 实际例子(为什么要加?)
python
# -*- coding: utf-8 -*-
print("你好,Python!") # 用UTF-8编码,中文能正常显示如果不加,在某些老环境里,运行代码会出现乱码 (比如��好,Python!)。现在很多 Python 环境默认用 UTF-8,但加上声明更保险,尤其是处理中文时。
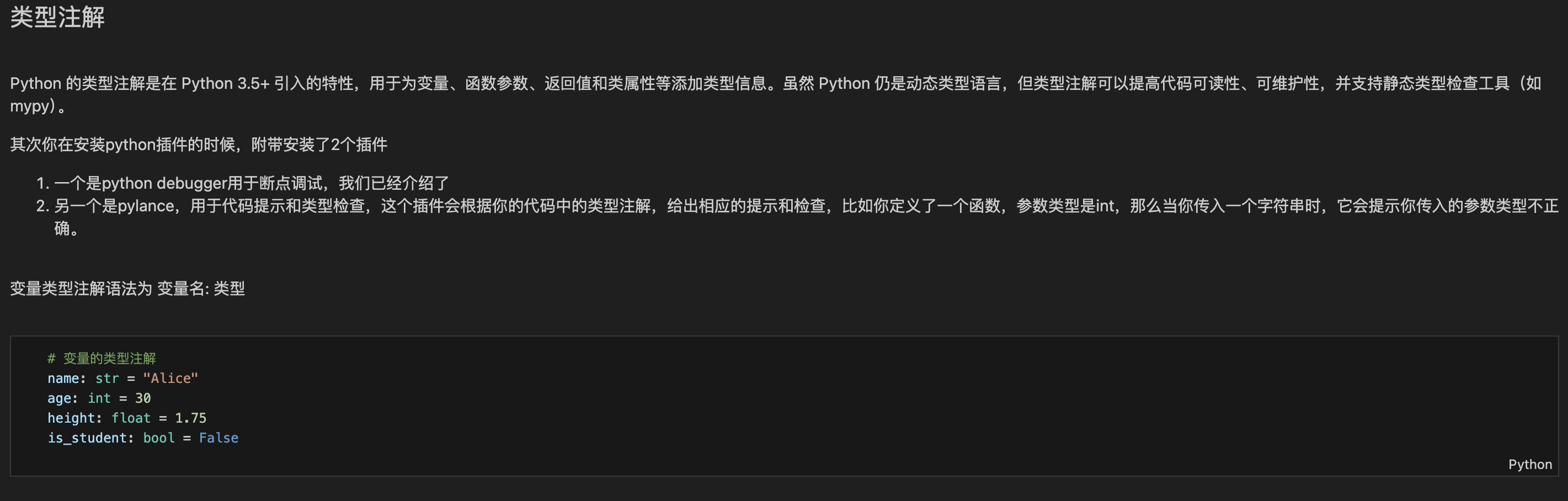
第二部分:类型注解:给代码贴 "标签"
你可以把类型注解想象成给物品贴标签:比如给苹果贴 "水果",给水杯贴 "日用品",别人一看就知道这是什么。代码的类型注解就是给变量、函数贴 "类型标签",让你(或 IDE)一眼知道变量是啥类型,函数要传啥参数。
1. 变量的类型注解(最简单)
格式:变量名: 类型 = 值
常见类型:str(字符串)、int(整数)、float(浮点数)、bool(布尔值)、list(列表)等。
python
# -*- coding: utf-8 -*-
# 字符串类型
name: str = "小明"
# 整数类型
age: int = 18
# 浮点数类型
height: float = 1.75
# 布尔类型
is_student: bool = True
# 列表类型(里面装整数)
scores: list[int] = [90, 85, 95]
print(name)
print(age)2. 函数的类型注解(最常用)
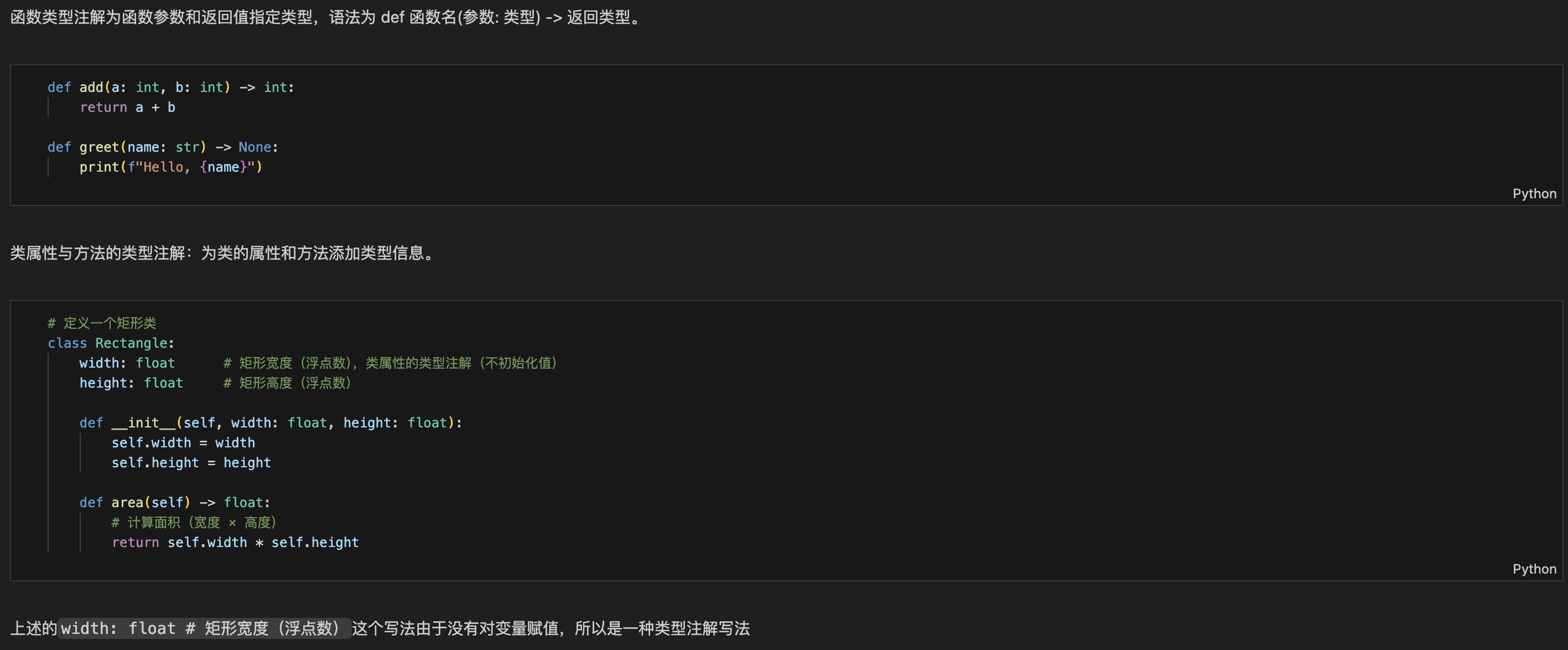
格式:def 函数名(参数1: 类型, 参数2: 类型) -> 返回值类型:
作用:不用看函数内部代码,就知道要传啥类型的参数,返回啥类型的值。
python
# -*- coding: utf-8 -*-
# 定义一个加法函数:参数a和b是整数,返回值也是整数
def add(a: int, b: int) -> int:
return a + b
# 调用函数:传两个整数
result: int = add(3, 5)
print(result) # 输出8
# 如果传错类型(比如传字符串),IDE会提示错误(比如PyCharm会标红)
# add("3", 5) # 这行代码会被IDE提示错误,因为参数类型不对3. 类型注解的好处(新手必知)
- 易读:别人看你的代码,一眼就知道变量 / 函数的类型,不用猜;
- 易查错:IDE(比如 PyCharm)会根据类型注解提示错误,比如你给需要整数的函数传了字符串,会直接标红;
- 方便维护:半年后你自己看代码,也能快速回忆起变量的类型。
注意:类型注解不是 "强制要求"
Python 是 "动态类型语言",就算你写了类型注解,传错类型也能运行(比如add("3", "5")会返回"35"),但 IDE 会提示你,这是一种 "提醒",不是 "强制限制"。
整体总结
今天学的四个知识点,其实都是为了让你的代码 "整洁、好懂、好维护":
- 文件命名:给文件贴好认的标签;
- 文件夹管理:给文件分区域放;
- 机器学习项目拆分:按流程拆分成独立模块;
- 编码格式和类型注解:保证中文不乱码,代码有 "说明"。
你可以先从简单的项目开始练手(比如 "学生成绩计算"),按今天的规范来写,慢慢就会形成习惯了。
今日的示例代码包含2个部分
- notebook 文件夹内的ipynb 文件,介绍下今天的思路
- 项目文件夹中其他部分:拆分后的信贷项目,学习下如何拆分的,未来你看到的很多大项目都是类似的拆分方法
该信贷违约预测项目的文件夹拆分方式遵循了模块化、职责分离的设计原则,是大型项目常用的组织结构。以下从核心模块、拆分逻辑、设计优势三个维度进行规范整理,方便理解大项目的拆分思路:
一、项目核心模块结构(排除 notebooks)

二、拆分逻辑(按 "数据→处理→模型→可视化" 的流程拆分)
数据层(data/)
按数据 "原始状态" 和 "处理后状态" 拆分:
raw/:存储未经过任何处理的原始数据(如data.csv),作为项目的 "数据源",保证数据可追溯。processed/:存储经过清洗、编码后的最终数据,供模型直接调用,避免重复处理。
核心代码层(src/)

辅助文件
requirements.txt:统一管理项目依赖(如pandas、scikit-learn、shap等),确保环境一致性。README.md:提供项目全景说明(结构、使用步骤、模块功能),降低协作成本。
三、设计优势(大项目通用的拆分价值)
- 低耦合高内聚:每个模块只做一件事(如数据处理不涉及模型训练,可视化不涉及数据加载),修改某一模块不影响其他模块。
- 可扩展性 :新增功能时只需在对应模块添加代码(如增加新的特征工程逻辑,只需在
src/data/下新增feature_engineering.py)。 - 可维护性 :代码位置清晰(找数据处理看
src/data,找模型训练看src/models),便于后期 debug 或迭代。 - 协作友好:多人开发时可按模块分工(一人处理数据,一人训练模型,一人做可视化),减少代码冲突。
总结
该项目的拆分逻辑可概括为:按数据流向和功能职责划分模块,每个模块专注单一任务,通过清晰的文件结构和接口(如函数调用)实现模块间协作。这种方式是大型项目的通用设计模式,核心是 "让每个文件 / 文件夹都有明确的存在意义"。
如何根据项目需求进行合理的文件夹拆分?
合理的文件夹拆分核心是"按流程 / 职责划分、降低耦合、提升可维护性",需要结合项目的核心目标、流程环节和团队协作需求来设计。以下是具体的拆分思路和步骤,结合信贷违约预测项目案例说明:
一、先明确项目核心流程,确定 "必须有的模块"
任何项目的文件夹拆分都应从"项目要做什么"出发,梳理核心流程环节,每个环节对应一个基础模块。以信贷违约预测项目为例,核心流程是:原始数据 → 数据处理 → 模型训练 → 结果评估 → 可视化展示因此必须包含对应模块:data/(数据存储)、src/data/(数据处理)、src/models/(模型训练评估)、src/visualization/(可视化)。
二、按 "职责单一原则" 拆分模块,每个文件夹只做一件事
每个文件夹 / 模块应专注于单一任务,避免功能混杂(即 "高内聚")。具体可分为以下几类核心模块:
1. 数据层:按 "数据状态" 拆分(data/)
数据是项目的基础,需按 "生命周期状态" 拆分,确保数据可追溯、不混乱:
data/raw/:存储未修改的原始数据(如信贷项目的data.csv),作为 "数据源",禁止直接修改,保证可复现性。data/processed/:存储清洗、编码后的最终数据(如处理后的特征表),供模型直接调用,避免重复处理。- (可选)
data/interim/:若数据处理步骤复杂(如多轮清洗),可增加中间数据文件夹,存放临时结果。
2. 代码层:按 "功能职责" 拆分(src/)
核心代码需按 "做什么" 而非 "怎么做" 拆分,每个子模块对应一个功能环节:
src/data/:仅负责数据处理(加载、清洗、编码、特征工程等),如信贷项目的preprocessing.py实现数据加载和缺失值处理。src/models/:仅负责模型生命周期(训练、评估、保存 / 加载),如train.py中的train_model和evaluate_model函数。src/visualization/:仅负责结果可视化(图表绘制、解释性可视化等),如plots.py中的特征重要性和混淆矩阵绘制。- (可选扩展)根据项目复杂度新增:
src/config/:存放配置文件(如模型参数、文件路径),避免硬编码(如信贷项目若参数复杂,可新增config.yaml)。src/utils/:存放通用工具函数(如日志记录、路径处理),供各模块复用。
3. 辅助层:支撑项目运行的 "基础设施"
requirements.txt:记录所有依赖库及版本(如pandas>=1.3.0),确保环境一致性,别人部署时一键安装。README.md:说明项目结构、运行步骤、模块功能(如信贷项目的 "快速开始" 部分),降低协作成本。- (可选)
models/:单独存放训练好的模型权重(因文件较大,可像案例中用使用说明.txt标注存储方式)。 - (可选)
logs/:存放运行日志(替代 print 语句),便于调试和追踪问题。
三、根据项目规模灵活调整,避免过度设计
- 小型项目(如单文件脚本):无需复杂拆分,可简化为 "数据文件夹 + 主脚本 + 依赖文件"。
- 中型项目(如信贷预测项目):按 "数据 + 核心功能模块 + 辅助文件" 拆分(如案例结构),满足可维护性。
- 大型项目 (如工业级应用):需更细粒度拆分,例如:
- 模型模块拆分为
src/models/train/、src/models/evaluate/、src/models/inference/(推理); - 新增
src/api/(接口层)、src/tests/(测试用例)、docs/(详细文档)等。
- 模型模块拆分为
四、拆分的核心原则总结
- 可追溯 :数据和代码的位置明确(找数据去
data/,找模型去src/models/)。 - 低耦合 :模块间通过 "函数调用" 而非 "直接修改数据" 交互(如信贷项目中
train.py调用data/preprocessing.py的函数,而非直接修改数据文件)。 - 可扩展 :新增功能时只需在对应模块添加代码(如增加新特征工程,只需在
src/data/下加feature_engineering.py)。 - 协作友好:多人可按模块分工(数据处理、模型训练、可视化分别由不同人负责)。
通过这种方式拆分后,项目结构会像 "搭积木" 一样清晰:每个文件夹有明确用途,代码逻辑一目了然,无论是自己维护还是团队协作,都能大幅提升效率。





作业:尝试针对之前的心脏病项目 ipynb,将他按照今天的示例项目整理成规范的形式,思考下哪些部分可以未来复用。
心脏病预测项目规范结构整理(基于 IPython Notebook 拆分)
结合之前学习的文件命名规范、文件夹管理、机器学习项目拆分、编码格式与类型注解 知识,我们将心脏病预测的.ipynb文件拆解为模块化、可复用、易理解 的项目结构。核心思路是:把 Notebook 中的探索性代码按 "功能职责" 抽离为可复用的 Python 模块,保留 Notebook 作为探索性分析入口,同时明确各模块的复用价值。
一、项目整体规范结构
首先给出最终的项目目录结构(符合机器学习项目的通用拆分逻辑),每个文件夹 / 文件都有明确的职责:



二、各模块的功能与代码实现(通俗版 + 可复用性说明)
下面针对核心模块,给出简化的代码示例 (带编码格式和类型注解),并标注哪些部分可复用。
1. 配置模块:src/config/config.py
作用:集中存储所有硬编码参数(如数据路径、模型超参数),避免在代码中到处写死,方便修改和复用。
可复用性:仅需修改路径和参数,即可直接复用于其他机器学习项目。
python
# -*- coding: utf-8 -*- # 编码格式声明
"""项目配置文件:存储所有路径和参数"""
# 数据路径
RAW_DATA_PATH: str = "data/raw/heart.csv"
PROCESSED_DATA_PATH: str = "data/processed/processed_heart_data.csv"
# 模型参数
MODEL_TYPE: str = "random_forest" # 可替换为"logistic_regression"等
RANDOM_STATE: int = 42 # 随机种子(保证结果可复现)
TEST_SIZE: float = 0.2 # 测试集比例
N_ESTIMATORS: int = 100 # 随机森林树的数量
# 模型保存路径
SAVED_MODEL_PATH: str = "saved_models/heart_disease_model.pkl"
# 可视化参数
PLOT_STYLE: str = "seaborn-v0_8"
PLOT_DPI: int = 1002. 工具模块:src/utils/common_utils.py
作用 :存放跨项目可复用的通用工具函数,比如路径检查、日志记录、数据验证等。
可复用性:完全可复用于任何 Python 项目,无需修改。
python
# -*- coding: utf-8 -*-
"""通用工具函数:跨项目复用"""
import os
import logging
from typing import Optional
# 配置日志(方便调试和运行记录)
def setup_logger(name: str = "heart_disease_logger", log_file: Optional[str] = "logs/heart_disease.log") -> logging.Logger:
"""
配置日志记录器
:param name: 日志器名称
:param log_file: 日志文件路径
:return: 配置好的日志器
"""
# 检查日志文件夹是否存在,不存在则创建
if log_file and not os.path.exists(os.path.dirname(log_file)):
os.makedirs(os.path.dirname(log_file))
logger = logging.getLogger(name)
logger.setLevel(logging.INFO)
# 避免重复添加处理器
if not logger.handlers:
# 控制台处理器
console_handler = logging.StreamHandler()
# 文件处理器
file_handler = logging.FileHandler(log_file, encoding="utf-8") if log_file else None
# 日志格式
formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
console_handler.setFormatter(formatter)
if file_handler:
file_handler.setFormatter(formatter)
# 添加处理器
logger.addHandler(console_handler)
if file_handler:
logger.addHandler(file_handler)
return logger
# 检查文件是否存在
def check_file_exists(file_path: str) -> bool:
"""
检查文件是否存在
:param file_path: 文件路径
:return: 存在返回True,否则False
"""
if os.path.exists(file_path):
return True
else:
setup_logger().error(f"文件不存在:{file_path}")
return False3. 数据处理模块
(1)src/data/data_loader.py:数据加载
作用:封装数据加载逻辑,支持不同格式的数据源(CSV、Excel 等)。
可复用性:仅需修改文件格式相关代码,即可复用于其他项目的数椐加载。
python
# -*- coding: utf-8 -*-
"""数据加载函数:加载原始数据和处理后数据"""
import pandas as pd
from typing import DataFrame
from src.config.config import RAW_DATA_PATH, PROCESSED_DATA_PATH
from src.utils.common_utils import check_file_exists, setup_logger
logger = setup_logger()
def load_raw_data(file_path: str = RAW_DATA_PATH) -> DataFrame:
"""
加载原始数据
:param file_path: 原始数据路径
:return: 原始数据DataFrame
"""
if not check_file_exists(file_path):
raise FileNotFoundError(f"原始数据文件不存在:{file_path}")
try:
data = pd.read_csv(file_path)
logger.info(f"成功加载原始数据,数据形状:{data.shape}")
return data
except Exception as e:
logger.error(f"加载原始数据失败:{e}")
raise
def load_processed_data(file_path: str = PROCESSED_DATA_PATH) -> DataFrame:
"""
加载处理后的数据
:param file_path: 处理后数据路径
:return: 处理后数据DataFrame
"""
if not check_file_exists(file_path):
raise FileNotFoundError(f"处理后数据文件不存在:{file_path}")
try:
data = pd.read_csv(file_path)
logger.info(f"成功加载处理后数据,数据形状:{data.shape}")
return data
except Exception as e:
logger.error(f"加载处理后数据失败:{e}")
raise(2)src/data/preprocessing.py:数据清洗与特征工程
作用:实现心脏病数据的清洗(缺失值、异常值)和特征工程(编码、标准化等)。
可复用性 :特征工程的通用逻辑(如分类特征编码、数值特征标准化)可复用,仅需修改针对心脏病数据的特殊处理逻辑。
python
# -*- coding: utf-8 -*-
"""数据预处理:清洗、特征工程"""
import pandas as pd
import numpy as np
from typing import Tuple, DataFrame
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from src.config.config import PROCESSED_DATA_PATH, TEST_SIZE, RANDOM_STATE
from src.utils.common_utils import setup_logger
logger = setup_logger()
def preprocess_data(raw_data: DataFrame) -> Tuple[DataFrame, DataFrame, DataFrame, DataFrame]:
"""
数据预处理:清洗+特征工程+划分训练集/测试集
:param raw_data: 原始数据DataFrame
:return: X_train, X_test, y_train, y_test
"""
# 1. 数据清洗:处理缺失值(心脏病数据集通常缺失值较少,这里示例处理)
data = raw_data.copy()
data = data.dropna() # 删除缺失值(可替换为填充策略)
data = data[data["age"] > 0] # 过滤异常值(年龄不能为负)
logger.info("数据清洗完成")
# 2. 特征工程:分离特征和目标变量
X = data.drop("target", axis=1) # target是是否患心脏病的标签
y = data["target"]
# 3. 数值特征标准化(针对连续型特征,如age、trestbps等)
scaler = StandardScaler()
numeric_features = ["age", "trestbps", "chol", "thalach", "oldpeak"]
X[numeric_features] = scaler.fit_transform(X[numeric_features])
logger.info("特征标准化完成")
# 4. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=TEST_SIZE, random_state=RANDOM_STATE
)
# 5. 保存处理后的数据
processed_data = pd.concat([X, y], axis=1)
processed_data.to_csv(PROCESSED_DATA_PATH, index=False)
logger.info(f"处理后的数据已保存至:{PROCESSED_DATA_PATH}")
return X_train, X_test, y_train, y_test4. 模型模块
(1)src/models/model_train.py:模型训练与保存
作用:封装模型训练逻辑,支持不同模型的切换。
可复用性 :模型训练的通用框架(加载数据、训练、保存)可完全复用,仅需修改模型类型和超参数。
python
# -*- coding: utf-8 -*-
"""模型训练:训练并保存模型"""
import pickle
from typing import Any, DataFrame
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from src.config.config import MODEL_TYPE, SAVED_MODEL_PATH, RANDOM_STATE
from src.data.preprocessing import preprocess_data
from src.data.data_loader import load_raw_data
from src.utils.common_utils import setup_logger, check_file_exists
logger = setup_logger()
def train_model() -> Any:
"""
训练模型并保存
:return: 训练好的模型
"""
# 1. 加载原始数据
raw_data = load_raw_data()
# 2. 预处理数据
X_train, X_test, y_train, y_test = preprocess_data(raw_data)
# 3. 选择模型(可灵活切换)
if MODEL_TYPE == "random_forest":
model = RandomForestClassifier(n_estimators=100, random_state=RANDOM_STATE)
elif MODEL_TYPE == "logistic_regression":
model = LogisticRegression(random_state=RANDOM_STATE)
else:
raise ValueError(f"不支持的模型类型:{MODEL_TYPE}")
logger.info(f"开始训练{MODEL_TYPE}模型")
# 4. 训练模型
model.fit(X_train, y_train)
logger.info("模型训练完成")
# 5. 保存模型
with open(SAVED_MODEL_PATH, "wb") as f:
pickle.dump(model, f)
logger.info(f"模型已保存至:{SAVED_MODEL_PATH}")
return model
def load_model(file_path: str = SAVED_MODEL_PATH) -> Any:
"""
加载训练好的模型
:param file_path: 模型保存路径
:return: 训练好的模型
"""
if not check_file_exists(file_path):
raise FileNotFoundError(f"模型文件不存在:{file_path}")
with open(file_path, "rb") as f:
model = pickle.load(f)
logger.info(f"成功加载模型:{file_path}")
return model(2)src/models/model_evaluate.py:模型评估
作用:实现模型的多维度评估(准确率、精确率、召回率、混淆矩阵等)。
可复用性 :分类模型的评估指标计算逻辑可完全复用于任何分类项目(如癌症预测、信贷违约预测)。
python
# -*- coding: utf-8 -*-
"""模型评估:计算评估指标并输出结果"""
from typing import Any, DataFrame, Dict
import pandas as pd
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
from src.data.preprocessing import preprocess_data
from src.data.data_loader import load_raw_data
from src.utils.common_utils import setup_logger
logger = setup_logger()
def evaluate_model(model: Any) -> Dict[str, float]:
"""
评估模型性能
:param model: 训练好的模型
:return: 评估指标字典
"""
# 加载数据并预处理
raw_data = load_raw_data()
X_train, X_test, y_train, y_test = preprocess_data(raw_data)
# 预测
y_pred = model.predict(X_test)
# 计算评估指标
metrics = {
"accuracy": accuracy_score(y_test, y_pred),
"precision": precision_score(y_test, y_pred),
"recall": recall_score(y_test, y_pred),
"f1": f1_score(y_test, y_pred)
}
# 打印评估结果
logger.info("模型评估结果:")
for metric, value in metrics.items():
logger.info(f"{metric}: {round(value, 4)}")
# 打印混淆矩阵
cm = confusion_matrix(y_test, y_pred)
logger.info(f"混淆矩阵:\n{cm}")
return metrics5. 可视化模块:src/visualization/plots.py
作用:绘制数据探索和模型结果的可视化图表(如特征分布、特征重要性、混淆矩阵)。
可复用性 :可视化的通用函数(如特征分布直方图、混淆矩阵热力图)可完全复用,仅需修改图表标题、颜色等个性化参数。
python
# -*- coding: utf-8 -*-
"""可视化函数:绘制数据和模型相关图表"""
import matplotlib.pyplot as plt
import seaborn as sns
from typing import DataFrame, Any
from src.config.config import PLOT_STYLE, PLOT_DPI
from src.data.data_loader import load_raw_data
# 设置绘图样式
plt.style.use(PLOT_STYLE)
plt.rcParams["dpi"] = PLOT_DPI
def plot_feature_distribution(feature_name: str) -> None:
"""
绘制单个特征的分布(按目标变量分组)
:param feature_name: 特征名称
"""
data = load_raw_data()
plt.figure(figsize=(10, 6))
sns.histplot(data=data, x=feature_name, hue="target", kde=True)
plt.title(f"特征{feature_name}的分布(按是否患心脏病分组)")
plt.xlabel(feature_name)
plt.ylabel("频次")
plt.savefig(f"plots/{feature_name}_distribution.png")
plt.show()
def plot_feature_importance(model: Any, feature_names: list) -> None:
"""
绘制随机森林模型的特征重要性
:param model: 训练好的模型
:param feature_names: 特征名称列表
"""
importance = model.feature_importances_
feature_importance = pd.Series(importance, index=feature_names).sort_values(ascending=False)
plt.figure(figsize=(10, 6))
sns.barplot(x=feature_importance, y=feature_importance.index)
plt.title("特征重要性排名")
plt.xlabel("重要性得分")
plt.ylabel("特征名称")
plt.savefig("plots/feature_importance.png")
plt.show()6. 辅助文件
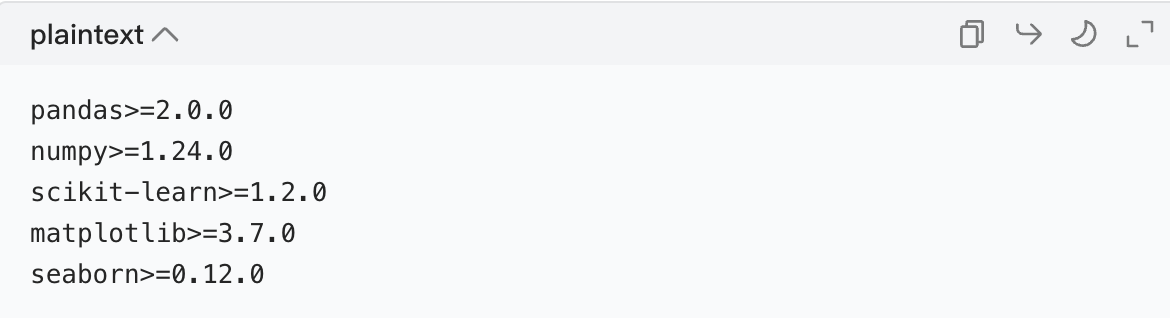
(1)requirements.txt:依赖管理
作用:记录项目所需的所有第三方库及版本,确保环境一致性。
可复用性:仅需增删库名,即可复用于其他机器学习项目。
(2)README.md:项目文档
作用:说明项目结构、使用步骤、复用说明,方便自己和他人理解。

三、可复用部分的梳理与总结
整个项目中,可复用的代码主要分为三类,方便未来在其他项目中直接使用:
| 模块 / 函数 | 复用类型 | 复用场景 | 修改点 |
|---|---|---|---|
src/utils/common_utils.py |
完全复用 | 所有 Python 项目 | 无需修改 |
src/data/data_loader.py |
少量修改复用 | 其他 CSV/Excel 数据加载的项目 | 仅修改文件格式(如read_excel) |
src/models/model_evaluate.py |
完全复用 | 所有分类项目(如信贷违约、癌症预测) | 无需修改 |
src/visualization/plots.py |
少量修改复用 | 其他机器学习项目的可视化 | 仅修改图表标题、保存路径 |
src/config/config.py |
少量修改复用 | 其他机器学习项目 | 仅修改路径和参数 |
requirements.txt |
少量修改复用 | 其他机器学习项目 | 增删库名和版本 |
四、项目的使用流程(简化版)
- 准备数据 :将心脏病原始数据集放入
data/raw/heart.csv; - 安装依赖 :执行
pip install -r requirements.txt; - 训练模型 :运行
python src/models/model_train.py,模型会自动保存到saved_models/; - 评估模型 :运行
python src/models/model_evaluate.py,查看评估指标; - 可视化 :调用
src/visualization/plots.py中的函数,绘制特征分布和特征重要性; - 探索分析 :打开
notebooks/heart_disease_eda.ipynb,进行交互式分析。
五、核心设计思路回顾
- 职责单一 :每个文件夹 / 文件只做一件事(如
model_train.py只负责训练模型); - 可复用性:将通用逻辑抽离为独立模块,避免重复写代码;
- 易维护性:参数集中在配置文件,修改时无需改动核心代码;
- 符合规范:文件命名用小写 + 下划线,编码格式为 UTF-8,关键函数加类型注解。
这种结构是工业级机器学习项目的通用设计,掌握后可以轻松应对各种数据科学项目的拆分和管理。