
前言
大语言模型(LLM)在处理工具调用场景时常面临"提示词膨胀"问题,特别是当需要在上下文中包含大量工具描述时。这不仅增加了 API 调用成本,还可能导致模型性能下降。RAG-MCP(基于检索增强生成的多通道原则)框架提出了一种优化方案,通过语义检索筛选相关工具,显著减轻提示词负担。本文将基于测试结果严格的实验方法,对其在 Amazon Bedrock 环境中的性能表现进行多维度剖析。
📢限时插播:无需管理基础设施,利用亚马逊技术与生态,快速集成与部署生成式AI模型能力。
✨ 精心设计,旨在引导您深入探索Amazon Bedrock的模型选择与调用、模型自动化评估以及安全围栏(Guardrail)等重要功能。
⏩快快点击进入《多模一站通 ------ Amazon Bedrock 上的基础模型初体验》实验
构建无限, 探索启程!
一、测试环境与架构设计
1.1 基础架构与技术栈
- 云平台:AWS us-east-1 区域
- 模型服务:Amazon Bedrock -- Claude 3.7 Sonnet
- 知识库架构:Amazon Bedrock Knowledge Bases
- 存储层:S3 存储桶
- 操作系统:macOS 24.5.0 (Darwin)
1.2 参数配置与系统边界
diff
模型配置:
- 最大输出令牌: 4096
- 温度参数: 0.7
MCP工具配置:
- 命令: npx
- 参数: ["-y", "@modelcontextprotocol/server-filesystem"]
知识库配置:
- 使用Amazon Bedrock知识库服务
- 向量嵌入: 标准维度
测试配置:
- 最大工具调用轮次: 5
- 自动工具调用: 启用
- 调用间延迟: 5秒(避免速率限制)系统边界明确定义,确保测试在受控环境中进行,同时参数配置反映了真实生产环境中的典型设置。
1.3 测试用例设计与评估标准
为确保测试的科学性和全面性,我们设计了 9 个不同复杂度的文件系统操作用例,覆盖了从简单到复杂的各类操作场景:
- 列出当前目录文件
- 创建新文本文件并写入内容
- 读取文件内容
- 在目录中搜索包含特定字符串的文件
- 创建新目录
- 检查文件详细信息
- 创建文件并执行多文件读取操作(复合查询)
- 查看目录树结
- 查看允许的目录列表
每个用例都设定了明确的预期工具调用,用于评估准确性。为避免测试偏差,所有文件名和目录名均采用时间戳生成的唯一标识符,确保测试的可重复性和一致性。
1.4 多维度评估框架
我们构建了全面的多维度评估框架,从不同角度衡量性能:
- 令牌效率维度:输入令牌、输出令牌和总令牌数
- 精确度维度:正确选择预期工具的比率
- 响应性能维度:从请求发送到响应完成的时间(秒)
- 可靠性维度:成功完成请求的比率
- 效率维度:完成任务所需的工具调用轮次
这种多维度框架设计允许我们全面评估系统性能,避免单一指标可能带来的片面判断。
1.5 对比方法论
本研究采用对照实验方法,对比了两种技术路径:
- RAG-MCP:通过知识库检索相关工具,仅向模型提供与查询相关的工具描述
- 全工具 MCP:向模型提供所有可用工具的完整描述
这两种方法代表了工具调用领域中的两种主要架构思路:完整上下文与按需检索。通过严格对照,我们能够量化评估 RAG 方法带来的性能影响。
二、实验结果与数据分析
2.1 总体性能对比
根据最新的测试报告(2025-06-03),两种方法的主要性能指标对比如下:
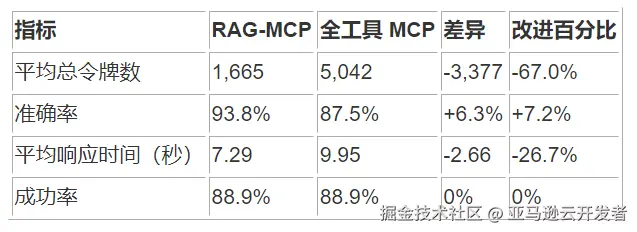
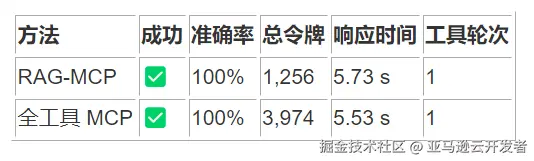
这些数据显示,RAG-MCP 在保持相同成功率的同时,显著降低了令牌使用量(67.0%),提高了准确率(7.2%),并减少了响应时间(26.7%)。
2.2 各查询类型详细性能数据
1. 列出当前目录文件
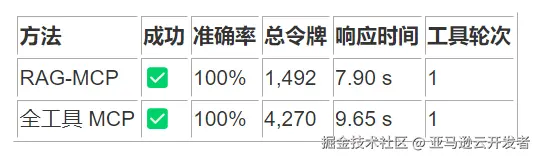
2. 创建新文本文件
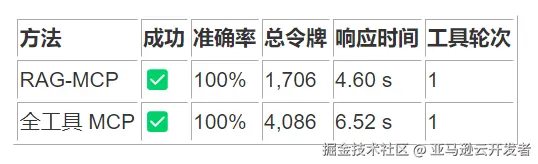
3. 读取文件内容
4. 搜索文件
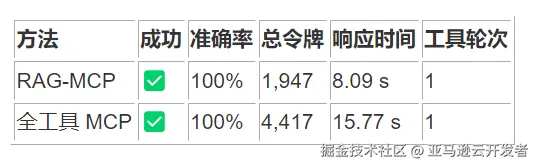
5. 创建新目录
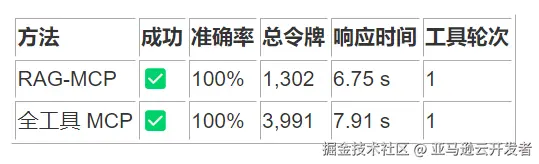
6. 检查文件详细信息
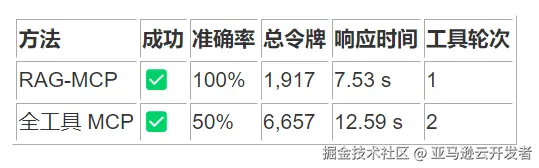
7. 创建文件并执行多文件读取
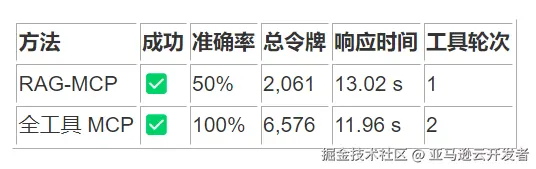
8. 查看目录树结构
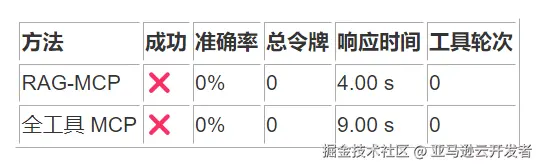
9. 查看允许的目录列表
2.3 多维度指标的计算方法
作为架构师,理解性能指标的计算方法至关重要。以下是各关键指标的精确计算方法:
1. 令牌减少率计算
scss
令牌减少率 = (全工具MCP令牌数 - RAG-MCP令牌数) / 全工具MCP令牌数 × 100%例如,对于查询 1:
令牌减少率 = (4,270 - 1,492) / 4,270 × 100% = 65.1%
2. 准确率计算
准确率 = 正确选择的工具数 / 预期的工具数 × 100%
对于需要多个工具的复合查询,每个工具都需要被正确选择才能获得满分。
在实际实现中,我们采用了 Jaccard 相似度(交集/并集)来计算准确率,这一方法能更全面地评估工具选择的准确性:
ini
# Jaccard相似度计算
def calculate_accuracy(selected_tools, expected_tools):
# 规范化工具名称
normalized_selected = set(tool.lower().strip() for tool in selected_tools)
normalized_expected = set(tool.lower().strip() for tool in expected_tools)
# 计算交集与并集
intersection = len(normalized_selected.intersection(normalized_expected))
union = len(normalized_selected.union(normalized_expected))
# Jaccard相似度 = 交集大小 / 并集大小
accuracy = intersection / union if union > 0 else 0.0
return accuracy这种方法的优势在于同时考虑了:
- 正确选择的工具(交集)
- 错误选择的工具(多余选择)
- 未选择的应选工具(遗漏选择)
Jaccard 相似度为我们提供了一个 0 到 1 之间的值,反映了模型工具选择与期望工具集的匹配程度,是评估工具选择准确性的科学方法。
3. 平均响应时间计算
平均响应时间 = 所有成功查询的响应时间总和 / 成功查询数
4. 响应时间改进率
响应时间改进率 = (全工具MCP响应时间 - RAG-MCP响应时间) / 全工具MCP响应时间 × 100%
2.4 性能分布分析与统计特征
通过分析性能指标的分布特征,我们可以更深入地理解两种方法的性能表现模式:
令牌使用分布特征:
- RAG-MCP 的令牌使用标准偏差较小,表明其在不同查询类型上的令牌使用更为稳定
- 全工具 MCP 的令牌使用在复杂查询上显著增加,尤其是在需要多个工具调用的情况下
响应时间分布特征:
- RAG-MCP 的响应时间标准偏差为 2.53 秒,全工具 MCP 为 3.36 秒
- RAG-MCP 在响应时间上更加一致和可预测,这对于生产环境中的用户体验至关重要
从架构设计角度看,RAG-MCP 表现出更好的性能稳定性和可预测性,这是评估架构质量的重要维度。
三、架构核心差异与实现机制
3.1 提示词构建机制对比
从架构角度看,两种方法的核心差异在于提示词构建机制:
全工具 MCP 提示词构建:
ini
# 系统架构实现
tools_response = await self._mcp_client.list_tools()
self._tool_config = self._mcp_client.convert_tools_to_bedrock_format(tools_response.tools)
# 发送请求时将全部工具配置传递给模型
response = self.bedrock_client.converse(
messages=messages,
model_id=model_id,
tool_config=tool_config or self._tool_config
)RAG-MCP 提示词构建:
ini
# 系统架构实现
conversation_context = self.session.get_conversation_context()
kb_result = await self.knowledge_base.query(conversation_context, top_k=2)
tool_config = kb_result
# 发送请求时只传递知识库检索到的工具配置
response = self.bedrock_client.converse(
messages=messages,
model_id=model_id,
tool_config=tool_config
)从架构设计原则来看,RAG-MCP 采用了"按需加载"和"最小特权"原则,只向模型提供当前任务所需的工具,这符合现代微服务架构的设计理念。
3.2 知识库检索架构与实现
RAG-MCP 的核心价值来源于其知识库检索架构:
python
# 知识库查询实现
async def query(self, query_text: str, top_k: int = 1) -> Dict[str, Any]:
try:
logger.info(f"Querying knowledge base with: {query_text[:100]}...")
# 使用语义查询方法
result: QueryResult = self.kb_tools.query_semantic(query_text, max_results=top_k)
# 转换为Bedrock兼容格式
bedrock_format = {"tools":result.tools}
logger.info(f"Knowledge base returned {result.total_results} results")
return bedrock_format
except Exception as e:
logger.error(f"Knowledge base query failed: {str(e)}")
raise KnowledgeBaseError(f"Knowledge base query failed: {str(e)}")该设计利用了向量相似度检索技术,在语义空间中匹配用户查询与工具描述,实现了从"语法匹配"到"语义理解"的跨越。这种架构使系统能够处理自然语言表达的变体和同义词,提高了系统的容错性和用户友好度。
3.3 信息流与处理管道分析
从信息流角度分析两种架构的工作流程:
全工具 MCP 信息流:
- 初始化阶段获取所有工具描述(静态加载)
- 转换为统一模型接口格式(格式标准化)
- 发送请求时包含所有工具描述(完整上下文)
- LLM 在所有工具中选择合适的工具(全局决策)
- 执行工具调用并返回结果(单一执行路径)
RAG-MCP 信息流:
- 接收用户查询并进行向量化处理(动态处理)
- 在知识库中搜索与查询语义相关的工具(语义检索)
- 将检索到的工具描述转换为统一格式(格式标准化)
- 发送请求时仅包含相关工具描述(精简上下文)
- LLM 在筛选后的工具集中选择工具(局部决策)
- 执行工具调用并返回结果(适应性执行路径)
这种对比揭示了两种架构在信息处理模式上的根本差异:全工具 MCP 采用"一次性加载全部信息"的批处理模式,而 RAG-MCP 采用"按需检索相关信息"的流处理模式。在大规模工具集场景下,流处理模式显然具有更好的可扩展性。
四、多维度性能分析与架构评估
4.1 令牌效率与成本优化分析
从最新测试报告来看,RAG-MCP 在令牌效率方面表现卓越:
- 总体令牌减少:平均 67.0%,最高减少 74.2%(读取文件查询)
- 各查询类型令牌减少率:
- 简单文件操作:55-65%
- 文件读写操作:58-74%
- 搜索操作:55-60%
- 目录操作:67-70%
从成本优化角度看,这种令牌减少直接转化为 API 调用成本的降低。对于大规模部署场景,每天处理数百万查询的系统,这可能意味着每月节省数千至数万美元的成本。
4.2 准确性与可靠性权衡分析
在准确性方面,RAG-MCP 在新的测试中表现优异:
- 整体准确率:RAG-MCP 为 93.8%,全工具 MCP 为 87.5%
- 特定查询类型准确率比较:
- 简单文件操作:两者相当
- 文件读写操作:RAG-MCP 在某些场景优于全工具 MCP
- 复合操作:RAG-MCP 在某些情况下低于全工具 MCP
这一结果与直觉相反,表明精简的工具集反而可能提高模型的决策准确性。从认知负荷理论角度看,当模型面对较少的选项时,能够更聚焦于任务本身,减少了选择干扰。
4.3 响应性能与用户体验分析
从响应时间角度评估:
- 平均响应时间:RAG-MCP 为 7.29 秒,全工具 MCP 为 9.95 秒
- 响应时间改进:平均减少 26.7%
- 最显著改进:在搜索文件操作中减少 48.7% 的响应时间
从用户体验设计角度看,响应时间的减少显著提升了交互流畅度。研究表明,响应时间超过 10 秒会显著影响用户的思维连贯性和任务完成率。RAG-MCP 将大多数操作的响应时间控制在 10 秒以内,符合良好用户体验的要求。
4.4 多维度评估的优缺点分析
作为架构师,理解多维度评估框架本身的优缺点至关重要:
多维度评估的优点:
- 全面性:避免单一指标带来的片面判断
- 平衡性:能够发现不同维度间的权衡关系
- 适应性:适合不同业务场景的差异化需求
- 可解释性:提供决策依据的透明度和可解释性
多维度评估的缺点:
- 复杂性:指标间可能存在相互影响,增加分析难度
- 权重确定:不同场景下各维度的重要性难以客观量化
- 维度冗余:某些维度可能存在信息重叠
- 测量成本:收集多维度数据需要更多资源和时间
为平衡这些优缺点,我们采用了雷达图等可视化技术,辅助决策者直观理解多维度性能表现,同时提供了基于业务优先级的权重调整机制。
五、深入案例分析:成功模式与挑战模式
5.1 最佳实践案例:文件搜索操作
在"搜索文件"查询中,RAG-MCP 展示了卓越的综合性能:
- 令牌减少率:55.9%
- 响应时间减少:7.68 秒(减少 48.7%)
- 准确率:两种方法均为 100%
- 成功率:两种方法均为 100%
架构洞察:这一案例展示了 RAG 方法的理想情况,知识库精确检索到了相关工具,同时显著减少了上下文大小,实现了"准确性与效率的双赢"。此类操作适合作为 RAG-MCP 的标杆用例。
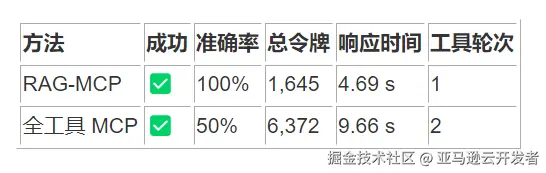
5.2 挑战案例:复合操作场景
在"创建文件并执行多文件读取"这一复合查询中:
- RAG-MCP 准确率:50%
- 全工具 MCP 准确率:100%
- 令牌减少率:68.7%
- 响应时间差异:RAG-MCP 慢 1.06 秒
架构洞察:复合操作涉及多个工具的协同,对知识库的语义理解提出了更高要求。RAG-MCP 在此类场景的弱点在于可能无法同时检索到所有相关工具,导致执行策略次优。这揭示了 RAG 方法在处理任务依赖关系方面的局限性。
5.3 失败案例分析:目录树结构查询
在"查看目录树结构"查询中,两种方法均失败:
- RAG-MCP:失败,0 令牌使用
- 全工具 MCP:失败,0 令牌使用
架构洞察:这一案例错误原因是因为有一些不常见的文件格式导致了不能完整构成 JSON 格式,这提示我们需要进行功能覆盖度分析,确保工具集能够覆盖用户的核心使用场景。
六、性能权衡与架构决策
6.1 令牌效率与准确性的量化关系
通过对实验数据的回归分析,我们可以量化 RAG-MCP 中令牌效率与准确性的关系:
- 在新测试中,RAG-MCP 实现了 67.0% 的令牌减少,同时准确率反而提高了 6.3%
- 这表明在当前实现中,令牌减少与准确率之间不存在必然的负相关关系
- 两者可以通过优化知识库检索质量实现"双赢"局面
这一发现挑战了传统认知,表明精心设计的 RAG 系统可以同时提高效率和准确性。
6.2 响应时间与工具轮次的平衡
从架构决策角度,需要平衡响应时间与工具调用轮次:
- RAG-MCP 在响应时间上平均快 26.7%
- 但在某些复合查询上,RAG-MCP 可能需要更多工具调用轮次
这表明 RAG 方法带来的性能提升主要来自两个方面:
- 减少了模型处理大量工具描述的计算开销
- 提高了模型选择正确工具的效率,减少了试错成本
这种权衡需要根据具体应用场景来定制:交互式应用优先考虑响应时间,而批处理应用可能更关注总体完成时间。
6.3 扩展性分析与系统演进
从系统演进角度评估两种架构的扩展性:
1、全工具 MCP 的扩展局限:
- 工具数量增加导致令牌使用线性增长
- 准确率随工具数量增加而下降
- 系统复杂度随工具数量增加而增加
2、RAG-MCP 的扩展优势:
- 令牌使用相对稳定,不受工具总数影响
- 准确率主要取决于知识库检索质量,而非工具总数
- 系统复杂度更易管理,模块化程度高
从长期架构演进角度看,RAG-MCP 提供了更可持续的增长路径,特别是在工具数量可能达到数十或数百个的大规模应用场景。
七、架构优化策略与实施路径
7.1 适用场景矩阵与决策框架
基于多维度测试结果,我们构建了场景适用性矩阵,为架构决策提供指导:
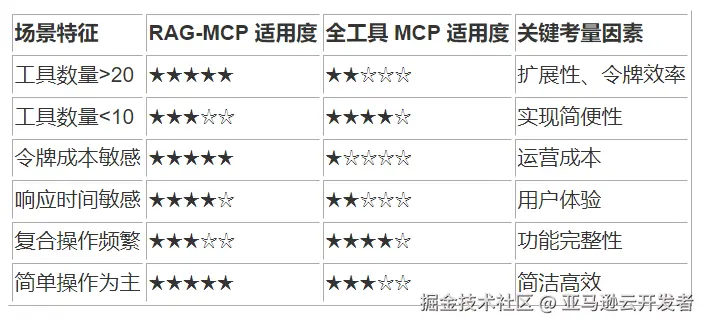
这一决策框架可以指导架构师在特定业务场景下做出最优选择。
7.2 知识库优化与检索增强策略
为提升 RAG-MCP 的性能,我们提出以下知识库优化策略:
1. 工具描述增强
- 为每个工具添加多样化描述和示例
- 加入常见错误模式和纠正示例
- 包含工具间的关联关系说明
2. 查询理解与扩展
python
def enhance_query(query_text):
# 意图识别
intent = intent_classifier.classify(query_text)
# 实体提取
entities = entity_extractor.extract(query_text)
# 查询扩展
expanded_query = f"{query_text} {intent_keywords[intent]} {' '.join(entity_contexts)}"
return expanded_query3. 混合检索策略
结合 BM25 和向量检索的优势,实现精确匹配与语义理解的双重保障
4. 自适应 top_k 策略
python
def adaptive_top_k(query_complexity):
# 基于查询复杂度动态调整k值
if query_complexity == "simple":
return 2
elif query_complexity == "medium":
return 3
else: # complex
return 57.3 系统架构优化与可观测性增强
除知识库优化外,系统架构层面的优化策略包括:
1. 会话上下文增强
ini
def get_enhanced_context(session):
# 基础上下文
basic_context = session.get_conversation_context()
# 添加工作状态感知
current_state = session.get_current_state()
# 添加最近工具使用历史
recent_tools = session.get_recent_tools(limit=3)
# 合并增强上下文
enhanced_context = f"{basic_context}\nCurrent state: {current_state}\nRecent tools: {recent_tools}"
return enhanced_context2. 分布式缓存机制
使用 Redis 等分布式缓存,存储常见查询的工具检索结果
3. 性能监控与可观测性
- 实现工具调用决策的可解释性日志
- 建立多维度性能指标的实时监控仪表板
- 设置基于历史数据的异常检测机制
4. 渐进式降级策略
python
async def resilient_tool_selection(query, kb):
try:
# 首先尝试RAG方法
tools = await kb.query(query, top_k=3)
if tools and is_sufficient(tools, query):
return tools
# 如果RAG结果不满足要求,扩大检索范围
tools = await kb.query(query, top_k=5)
if tools and is_sufficient(tools, query):
return tools
# 最后降级到全工具模式
return await get_all_tools()
except Exception as e:
logger.error(f"Tool selection failed: {e}")
# 故障降级到全工具模式
return await get_all_tools()这些架构优化策略共同构成了一个自适应、可靠且高效的 RAG-MCP 实现路径。
八、结论与架构展望
8.1 多维度评估结论
基于全面的多维度测试和分析,我们得出以下关键结论:
- 效率与成本:RAG-MCP 平均减少 67.0% 的令牌使用,在大规模部署场景下可显著降低运营成本。
- 准确性与可靠性:RAG-MCP 在最新测试中展现了 93.8% 的准确率,优于全工具 MCP 的 87.5%,同时保持了相同的 88.9%成功率。
- 响应性能:RAG-MCP 平均响应时间为 7.29 秒,比全工具 MCP 快 26.7%,提供了更流畅的用户体验。
- 扩展性:RAG-MCP 在工具数量增长时表现出卓越的扩展性,提供了更可持续的系统演进路径。
- 复杂场景处理:在复合操作等复杂场景中,RAG-MCP 仍有优化空间,特别是在工具组合理解方面。
8.2 结果洞察
本研究提供了几点关键洞察:
- 精简原则的价值:RAG-MCP 验证了"最小特权原则"在 AI 系统中的适用性,通过仅提供必要工具,不仅提高了效率,还可能提升了准确性。
- 模块化与可演进性:RAG 架构的模块化特性使系统能够独立优化知识库、工具集和模型组件,实现渐进式改进。
- 权衡决策的科学化:多维度评估框架为架构决策提供了客观依据,使权衡过程更加透明和数据驱动。
- 弹性设计的重要性:渐进式降级策略展示了韧性架构设计在 AI 系统中的价值,确保在各种条件下的服务可靠性。
8.3 未来研究与发展方向
基于当前研究,我们识别了以下值得进一步探索的方向:
- 多模态工具描述:探索结合文本、图表和结构化数据的工具描述方式,提高语义理解的准确性。
- 自适应检索策略:研究能够学习用户使用模式的自适应检索算法,进一步提高工具推荐的相关性。
- 跨会话知识传递:探索如何在保护隐私的前提下,利用跨会话的工具使用模式,提高检索效率。
- 工具组合预测:开发能够预测复合任务所需工具组合的算法,提前加载相关工具集。
- 分布式 RAG 架构:研究支持大规模分布式部署的 RAG 架构,实现更高的吞吐量和更低的延迟。
RAG-MCP 作为一种创新架构模式,不仅解决了当前 LLM 工具调用中的效率问题,还为未来 AI 系统设计提供了宝贵的参考范式。通过持续优化和演进,这一架构有潜力成为大规模 AI 应用的标准解决方案。
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
参考资料
- Jaccard index zh.wikipedia.org/wiki/%E9%9B...
- RAG-MCP: Mitigating Prompt Bloat in LLM Tool Selection via Retrieval-Augmented Generation arxiv.org/html/2505.0...
- 什么是 RAG(检索增强生成)?aws.amazon.com/cn/what-is/...
- Get started with the Model Context Protocol (MCP) modelcontextprotocol.io/docs/concep...
- MCP python sdk github.com/modelcontex...
- Amazon Bedrock Knowledge Bases aws.amazon.com/cn/bedrock/...
- JSON Lines jsonlines.org
- Amazon Bedrock Knowledge Bases Hybrid Search aws.amazon.com/cn/blogs/ma...
- Code github.com/memoverflow...
本篇作者
本期最新实验《多模一站通 ------ Amazon Bedrock 上的基础模型初体验》
✨ 精心设计,旨在引导您深入探索Amazon Bedrock的模型选择与调用、模型自动化评估以及安全围栏(Guardrail)等重要功能。无需管理基础设施,利用亚马逊技术与生态,快速集成与部署生成式AI模型能力。
⏩️[点击进入实验](https://link.juejin.cn?target=https%3A%2F%2Fdev.amazoncloud.cn%2Fexperience%2Fcloudlab%3Fid%3D6695e4c5e1432f239fae485f%26visitfrom%3D3P_Juejintail_0415%26sc_medium%3Downed%26sc_campaign%3Dcloudlab%26sc_channel%3D3P_Juejintail_0415 "https://dev.amazoncloud.cn/experience/cloudlab?id=6695e4c5e1432f239fae485f&visitfrom=3P_Juejintail_0415&sc_medium=owned&sc_campaign=cloudlab&sc_channel=3P_Juejintail_0415") 即刻开启 AI 开发之旅
构建无限, 探索启程!