学习途径:尚硅谷
前言
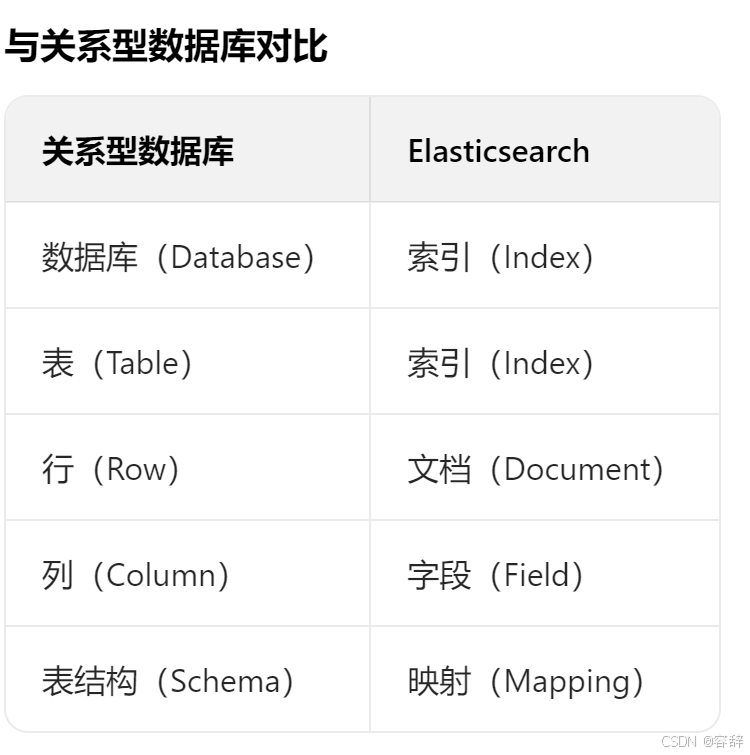
数据类型:
- 结构化数据:关系型数据库,表结构
- 非结构化数据:视频、图表等复杂的,保存在非关系型数据库
- 半结构化数据:xml、txt文档等,保存在非关系型
ELK:
- ElasticSearch:存储和搜索数据
- Beats:采集数据
- Logstash:传输数据
- Kibana:展示数据
Lucene:lucene不能独立使用,需要在其基础上搭建服务器框架才可。ES和solr基于lucene开发。选es的原因:除了搜索外还需要进行分析查询;集群下es更好扩展、性能好;es会暴露更多关键性指标
安装:官网,启动bin目录下的.bat文件,9300端口为es集群间组件的通信端口,9200为访问的http协议的restful端口,访问:http://localhost:9200。
概述
ES是一个开源的高扩展的分布式全文搜索引擎,优势在于灵活的分布式架构和强大的检索能力,但不适合强事务场景(如金融交易)。在实际应用中,常与数据库配合使用(数据库存核心数据,ES 存检索副本)。
典型使用场景:
- 日志与监控:收集、存储和分析系统日志(如 ELK 栈)。
- 全文检索:实现网站搜索、文档检索等功能。
- 数据分析:通过聚合功能进行实时统计分析(如用户行为分析)。
- 业务系统:替代传统数据库实现高并发的复杂查询。
底层采用倒排索引:所以是分词拆解,模糊匹配

语法
索引创建&修改
索引创建:
- 在 Postman 中,向 ES 服务器发 PUT 请求 :http://127.0.0.1:9200/shopping
- 向 ES 服务器发 POST 请求:http://127.0.0.1:9200/shopping/_doc,需传输请求体JSON内容,请求结果可以看到id,我们也可以在路径上指定id(注意不指定id前不能用put因为put时幂等性的,指定id后才可以用put),http://127.0.0.1:9200/shopping/_doc/1
js
{
"title": "小米14",
"category": "小米",
"images": "https://cdn.cnbj0.fds.api.mi-img.com/b2c-shopapi-pms/pms_1698304477.56836008.png",
"price": 3999.00
}索引修改:
- 全量修改 PUT 请求:http://127.0.0.1:9200/shopping/_doc/1
- 局部修改 POST 请求:http://127.0.0.1:9200/shopping/_update/1。
索引查询
索引查询:GET 请求
javascript
http://127.0.0.1:9200/_cat/indices?v //查询所有库
http://127.0.0.1:9200/shopping/_search //查询指定库中所有
http://127.0.0.1:9200/shopping/_doc/1 //查询指定行条件查询和分页查询
http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
javascript
//如品牌输入"小华",返回结果带回品牌有"小米"和华为的。
{
"query": {
"match": {
"category": "小华" //条件查询
}
}
}
==========================================
{
"query":{
"match_all":{} //查询全部
},
"_source":["title"], //指定查询想要的字段
"from": 0, //每页起始位置=(页码-1)* size
"size": 1, //每页显示多少条
"sort": { //排序
"price": {
"order": "desc"
}
}
}多条件查询
must为必须全部满足,should满足一个即可
javascript
{
"query": {
"bool": { //条件查询
"should": [
{
"match": {
"category": "小米"
}
},
{
"match": {
"category": "华为"
}
}
],
"filter": { //过滤条件
"range": { //范围查询
"price": {
"gt": 5000
}
}
}
}
}
}精准匹配和高亮
javascript
{
"query": {
"match_phrase": { //精准匹配
"category" : "小华" //这样就查不到了
}
},
"highlight": {
"fields": {
"category": {} // <----高亮此字段
}
}
}聚合查询
javascript
{
"aggs": { // 聚合操作
"price_group": { // 名称,随意起
"terms": { // 分组
"field": "price" // 分组字段
}
}
},
"size": 0 // 排除原始数据结果
}
===========================================
{
"aggs": {
"price_avg": {
"avg": { // 平均值
"field": "price"
}
}
},
"size": 0
}映射关系
PUT http://127.0.0.1:9200/user新增数据库
javascript
PUT http://127.0.0.1:9200/user/_mapping
{
"properties": {
"name": {
"type": "text", // 支持全文检索,即分词
"index": true //支持索引查询
},
"sex": {
"type": "keyword", // 需要完全匹配
"index": true
},
"tel": {
"type": "keyword", // 需要完全匹配
"index": false //这个就不能查询
}
}
}java API
依赖
xml
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.8.0</version>
</dependency>
<!-- elasticsearch 的客户端 -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
</dependency>基本功能语句
java
public class ESTest_Client {
public static void main(String[] args) throws Exception {
// 创建ES客户端
RestHighLevelClient esClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http"))
);
/**========================创建索引===================================**/
CreateIndexRequest request = new CreateIndexRequest("user");
CreateIndexResponse createIndexResponse =
esClient.indices().create(request, RequestOptions.DEFAULT);
// 响应状态
boolean acknowledged = createIndexResponse.isAcknowledged();
System.out.println("索引操作 :" + acknowledged);
/**=========================查看索引====================================**/
GetIndexResponse getIndexResponse =
esClient.indices().get(request, RequestOptions.DEFAULT);
System.out.println(getIndexResponse.getAliases());
System.out.println(getIndexResponse.getMappings());
System.out.println(getIndexResponse.getSettings());
/**=========================删除索引===================================**/
DeleteIndexRequest request = new DeleteIndexRequest("user");
AcknowledgedResponse response =
esClient.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(response.isAcknowledged());
/**=========================新增数据====================================**/
IndexRequest request = new IndexRequest();
request.index("user").id("1001");
User user = new User();
user.setName("zhangsan");
user.setAge(30);
user.setSex("男");
// 向ES插入数据,必须将数据转换位JSON格式
ObjectMapper mapper = new ObjectMapper();
String userJson = mapper.writeValueAsString(user);
request.source(userJson, XContentType.JSON);
IndexResponse response =
esClient.index(request, RequestOptions.DEFAULT);
System.out.println(response.getResult());
/**=========================修改数据====================================**/
UpdateRequest request = new UpdateRequest();
request.index("user").id("1001");
request.doc(XContentType.JSON, "sex", "女");
UpdateResponse response =
esClient.update(request, RequestOptions.DEFAULT);
System.out.println(response.getResult());
/**=========================查看数据====================================**/
GetRequest request = new GetRequest();
request.index("user").id("1001");
GetResponse response =
esClient.get(request, RequestOptions.DEFAULT);
System.out.println(response.getSourceAsString());
/**=========================删除数据====================================**/
DeleteRequest request = new DeleteRequest();
request.index("user").id("1001");
DeleteResponse response =
esClient.delete(request, RequestOptions.DEFAULT);
System.out.println(response.toString());
/**=========================批量插入数据================================**/
BulkRequest request = new BulkRequest();
request.add(new IndexRequest().index("user").id("1001").source(XContentType.JSON, "name", "zhangsan", "age",30,"sex","男"));
request.add(new IndexRequest().index("user").id("1002").source(XContentType.JSON, "name", "lisi", "age",30,"sex","女"));
request.add(new IndexRequest().index("user").id("1003").source(XContentType.JSON, "name", "wangwu", "age",40,"sex","男"));
BulkResponse response =
esClient.bulk(request, RequestOptions.DEFAULT);
System.out.println(response.getTook());//花费时间
System.out.println(response.getItems());
/**===================================================================**/
// 关闭ES客户端
esClient.close();
}
}高级查询
java
public class ESTest_Client {
public static void main(String[] args) throws Exception {
// 创建ES客户端
RestHighLevelClient esClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http"))
);
SearchRequest request = new SearchRequest();
request.indices("user");
//查询全部数据
SearchSourceBuilder builder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());
builder.from(0); //分页
builder.size(3);
builder.sort("age", SortOrder.DESC);//排序
String[] excludes = {"age"}; //排除字段
String[] includes = {}; //包含字段
builder.fetchSource(includes, excludes); //过滤
request.source(builder);
//条件查询
//request.source(new SearchSourceBuilder().query(QueryBuilders.termQuery("age", 30)));
SearchResponse response =
esClient.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
System.out.println(hits.getTotalHits());//总条数
System.out.println(response.getTook());//执行时间
for ( SearchHit hit : hits ) {
System.out.println(hit.getSourceAsString());//数据
}
}
}组合查询、范围查询、高亮
java
public class ESTest_Client {
public static void main(String[] args) throws Exception {
// 创建ES客户端
RestHighLevelClient esClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http"))
);
SearchRequest request = new SearchRequest();
request.indices("user");
SearchSourceBuilder builder = new SearchSourceBuilder();
/**=========================组合查询====================================**/
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//boolQueryBuilder.must(QueryBuilders.matchQuery("age", 30));
//boolQueryBuilder.must(QueryBuilders.matchQuery("sex", "男"));
//boolQueryBuilder.mustNot(QueryBuilders.matchQuery("sex", "男"));
boolQueryBuilder.should(QueryBuilders.matchQuery("age", 30));
boolQueryBuilder.should(QueryBuilders.matchQuery("age", 40));
builder.query(boolQueryBuilder);
/**=========================范围查询和高亮===============================**/
RangeQueryBuilder rangeQuery = QueryBuilders.rangeQuery("age");
rangeQuery.gte(30);
rangeQuery.lt(50);
//高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("<font color='red'>");
highlightBuilder.postTags("</font>");
highlightBuilder.field("name");
builder.highlighter(highlightBuilder);
builder.query(rangeQuery);
/**=========================模糊查询====================================**/
//差异不超过两个字符的都可以查出来
builder.query(QueryBuilders
.fuzzyQuery("name", "wangwu").fuzziness(Fuzziness.TWO));
/**=========================聚合查询====================================**/
AggregationBuilder aggregationBuilder =
AggregationBuilders.max("maxAge").field("age");//最大年龄
/**AggregationBuilder aggregationBuilder =
AggregationBuilders.terms("ageGroup").field("age");*/
builder.aggregation(aggregationBuilder);
/**====================================================================**/
request.source(builder);
SearchResponse response =
esClient.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
for ( SearchHit hit : hits ) {
System.out.println(hit.getSourceAsString());//数据
}
}
}springData集成ES,通过ElasticsearchRepository(蕊抛自tory) 操作数据
windows集群配置
windows下:创建 elasticsearch-cluster 文件夹,在内部复制三个 elasticsearch 服务。修改集群文件目录中每个节点的 config/elasticsearch.yml 配置文件。
检测集群状态:http://127.0.0.1:1001/_cluster/health
yaml
#集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
#节点名称,集群内要唯一
node.name: node-1001
node.master: true
node.data: true
#ip 地址
network.host: localhost
#http 端口
http.port: 1001
#tcp 监听端口
transport.tcp.port: 9301
# 注释里面的在node2和node3里面需要配置,这是节点之间的关系
#discovery.seed_hosts: ["localhost:9301", "localhost:9302"]
#discovery.zen.fd.ping_timeout: 1m
#discovery.zen.fd.ping_retries: 5
#跨域配置
http.cors.enabled: true
http.cors.allow-origin: "*"es系统架构
分片(shard):类似数据库的分表,提高吞吐量
副本(replicas):某个节点/分片宕掉,就需要副本来保证数据不丢失
分配:将分片分配给某个节点过程,包括分配主分片或者副本(他俩不能在一台机器)
执行PUT http://127.0.0.1:1001/users 设置分片和副本。
javascript
{
"settings":{
"number_of_shards":3,
"number_of_replicas":1
}
}使用浏览器扩展插件elasticsearch-head 查看集群情况。创建之初设置好了分片就不可以再改,后面可以改副本数量 http://127.0.0.1:1001/users/_settings
路由策略:存储数据猜出哈希算法,读数据可以任意节点,会找到对应节点,或者可以轮询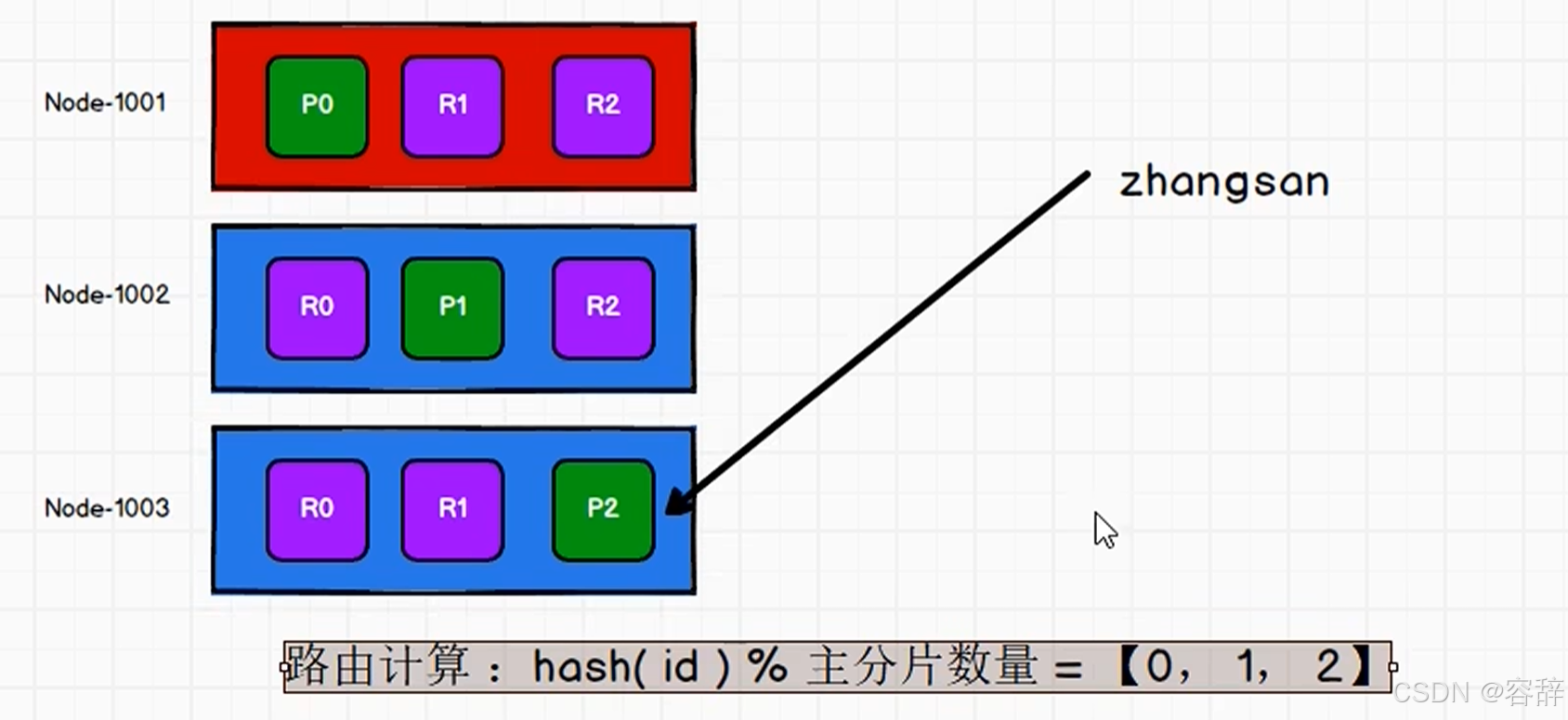
整体步骤:
- 客户端请求集群任意节点
- 协调节点通过路由策略将请求转换到指定节点
- 主分片将数据保存
- 主分片将数据发送给副本
- 副本保存成功后反馈给主分片
- 主分片给客户端反馈
consistency参数:参数值可以设为 one (只要主分片状态 ok 就允许执行写操作),all(必须要主分片和所有副本分片的状态没问题), 默认值为 quorum , 即大多数的分片副本状态没问题就ok。
倒排索引:先去词典查找词条---存在找到倒排列表,取文档id
- 词条:索引中最小存储和查询单元
- 词典:字典-词条的集合,B+、HashMap。key是词条,value存储倒排列表位置指针(该词条对应倒排列表的内存地址或磁盘偏移量)
- 倒排表:关键词出现位置、频率、文档id
优化
-
合理设置分片数量:需考虑node数量,一般都设置分片数不超过节点数的 3 倍
-
推迟分片分配:对于节点瞬时中断的问题,默认情况,集群会等待一分钟来查看节点是否会重新加入,减少 ES 在自动再平衡可用分片时所带来的极大开销。
-
优化硬件存储设备:ES 是一种密集使用磁盘的应用(段合并)
-
合理使用段合并: ES 默认采用较保守的策略,让后台定期进行段合并
-
减少 Refresh 的次数:延迟写入的策略,默认 1 秒触发一次 Refresh,然后 Refresh 会把内存中的的数据刷新到操作系统的文件缓存
-
加大 Flush 设置:Flush 的主要目的是把文件缓存系统中的段持久化到硬盘,当 Translog 的数据量达到 512MB 或者 30 分钟时,会触发一次 Flush
-
减少副本的数量:每个副本也会执行分析、索引及可能的合并过程,所以 Replicas 的数量会严重影响写索引的效率。当写索引时,需要把写入的数据都同步到副本节点,副本节点越多,写索引的效率就越慢。
文档
文档搜索
建立大的倒排索引并写入磁盘,倒排索引不可变。那么实现倒排索引的更新:就是用新的补充索引,通过新增索引来反应修改,而不是重写整个倒排索引,查完每个倒排索引后对结果进行合并。加标记代表被删除。
问题:索引越来越多、删除问题。ES 通过分段(Segment)机制+合并(Merge)策略。自动触发:当分段数量达到阈值(可配置)时,后台线程异步执行合并,会剔除标记为删除的数据,且合并后的大分段会替代参与合并的小分段,小分段随后被删除,释放磁盘空间。
文档近实时搜索: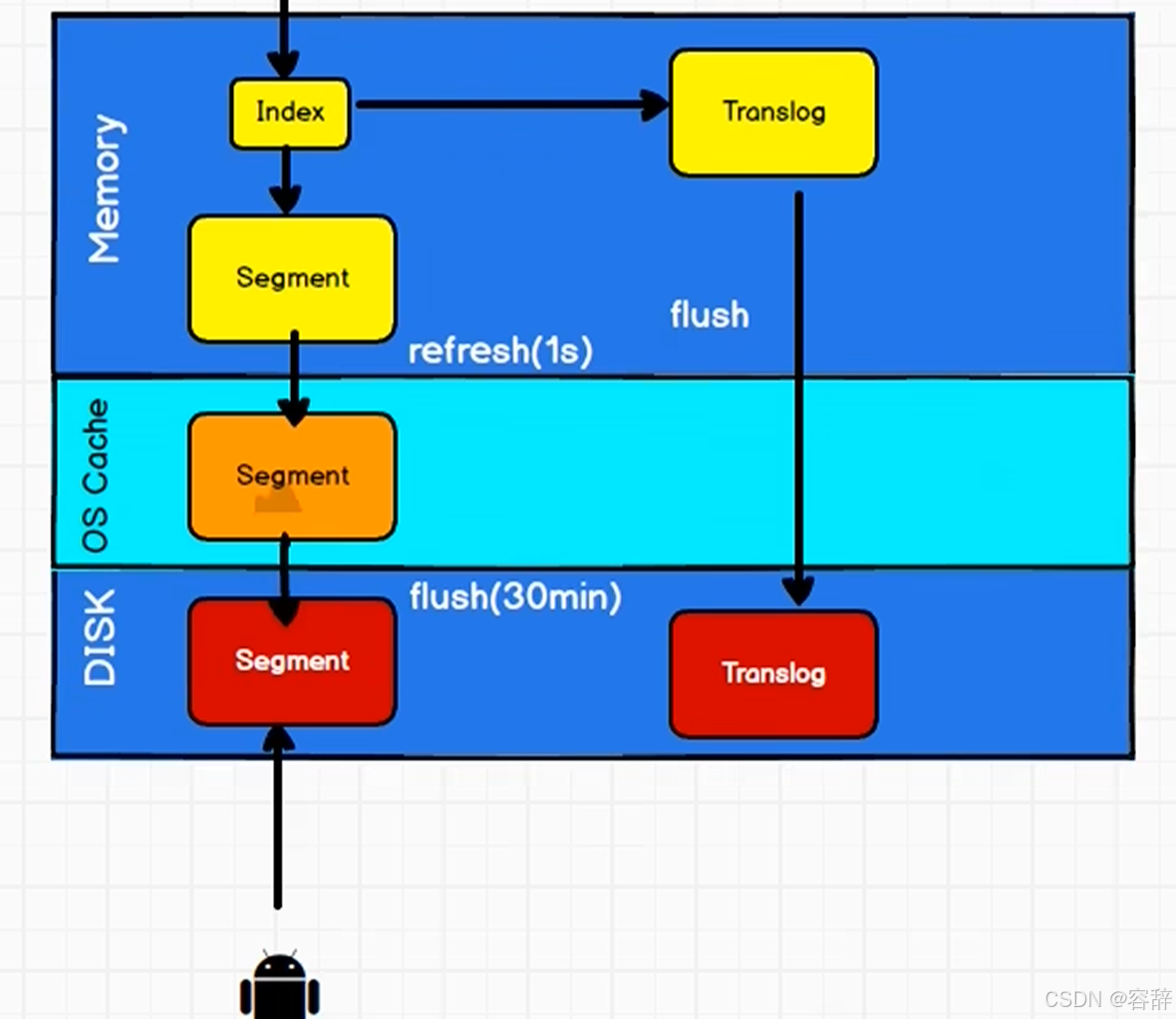
文档分析(分析器)
- 字符过滤器可以去掉HTML、将&转换为and等
- 分词器
- Token过滤器:大小写转换、删除无用词条、增加同义词
es内置分析器:GET http://localhost:9200/_analyze
javascript
{
"analyzer": "standard",
"text": "text to analyze"
}
//可以加入中文分词器插件
{
"analyzer": "ik_max_word",//细粒度拆分,ik_smart粗粒度
"text": "测试单词"
}扩展分词字典:在ik的config,创建custom.dic写入词条;修改IKAnalyzer.cfg.xml将custom.dic写入即可。
可以在创建索引的时候自定义分析器。
文档冲突
ES采用乐观锁version(if_seq_no&if_primary_term或者是version&version_type=external)
Kibana
Kibana下载,Kibana是一个免费且开放的用户界面,能够让你对Elasticsearch 数据进行可视化修改。 config/kibana.yml 文件
yml
# 默认端口
server.port: 5601
# ES 服务器的地址
elasticsearch.hosts: ["http://localhost:9200"]
# 索引名
kibana.index: ".kibana"
# 支持中文
i18n.locale: "zh-CN"