请参考OCR、文档解析工具合集(上),资料搜集于网络。
dots.ocr
小红书团队开源的一个多语言文档解析神器,1.7B参数规模,用统一的视觉语言模型(多模态模型)搞定传统方案需要多个模型配合才能完成的复杂任务。基于Qwen2.5-VL架构,使用aim-v2的设计思路。
OmniDocBench:
- 文本识别:Edit距离只有0.032(英文)和0.066(中文),识别准确率接近完美
- 表格解析:TEDS(Tree Edit Distance,树编辑距离/相似性)得分达到88.6%和89.0%,超越Gemini 2.5 Pro的85.8%
- 阅读顺序:Edit距离仅为0.040和0.067,远优于其他竞争对手
特点:
- 多语言支持:
- 所有任务都交给一个视觉语言模型来处理,只需要改变输入的提示词,就能在不同任务间切换。简化架构,提高各个任务间的协同效果。
- 解析结果会生成三个文件:
- JSON格式的结构化数据,包含每个元素的位置、类型和内容
- Markdown文件,适合进一步编辑和处理
- 带有标注框的可视化图片,方便检查解析效果
局限:
- 复杂表格和公式的解析还不够完美
- 文档中的图片暂时还不能解析
- 对于字符密度特别高的图片可能会解析失败
- 在大批量PDF处理时性能还有优化空间
架构
解读
- 先用海量的通用图文数据,喂出一个12亿参数的视觉编码器;让模型先看懂世界,具备识别物体、理解场景等基础视觉能力;
- 引入NaViT架构,能原生处理高分辨率图像,通过局部注意力(Local Attention)机制,避开全局计算带来的算力爆炸。在此基础上,将OCR、视频等更多样的数据源融入,与Qwen2.5-1.5B进行对齐。生成专为文档而生的视觉编码器dots.vit;
- 面向任务的精细打磨。先冻结视觉部分,用OCR数据专攻语言模型的文本能力;再解冻所有参数,进行联合微调。
安装
bash
conda create -n dots_ocr python=3.12
conda activate dots_ocr
git clone https://github.com/rednote-hilab/dots.ocr.git
cd dots.ocr
pip install torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --index-url
https://download.pytorch.org/whl/cu128
conda install cuda-toolkit -c nvidia
pip install -e .
python3 tools/download_model.py
model downloaded to /home/Ubuntu/dots.ocr/weights/DotsOCR
export hf_model_path=./weights/DotsOCR
export PYTHONPATH=$(dirname "$hf_model_path"):$PYTHONPATH
sed -i '/^from vllm\.entrypoints\.cli\.main import main$/a\from DotsOCR import modeling_dots_ocr_vllm' `which vllm`
# 启动vLLM服务
CUDA_VISIBLE_DEVICES=0 vllm serve ${hf_model_path} \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.95 \
--chat-template-content-format string \
--served-model-name model \
--trust-remote-code
python3 demo/demo_hf.py
# Gradio Web界面
python demo/demo_gradio.py
# Gradio标注界面
python demo/demo_gradio_annotion.pyPaddleOCR
百度基于PaddlePaddle深度学习框架开发的开源OCR工具箱,致力于为用户提供实用、超轻量、多语言的OCR能力,支持训练与部署不同模型。
特性
- 多语言支持:80+语言
- 超轻量:方便在各种场景部署
- 高准确率:在图片与文档文字识别上表现突出
- 模块化、灵活:可按需求选择算法平衡准确率与速度
- PP-OCRv5:通用场景文字识别模型,覆盖简中、繁中、英文、日文、拼音
- 全流程低代码开发工具:PaddleX基于PaddleOCR提供一站式能力
通过自定义手写数据集微调后,准确率可达78%。PP-FormulaNet_plus为增强版模型
Dolphin
字节跳动开源的通过异构锚点提示进行文档/图像解析的轻量级多模态模型,体积小、速度快,解析效率提升明显。
文档图像解析领域,传统方法通过多组件协作实现解析,结构清晰但处理复杂布局时效率受限。视觉-语言模型通过端到端训练显著提升解析性能,但在长文档和复杂结构面前仍面临瓶颈。
论文,一种采用先分析再解析策略的多模态文档解析模型,首先生成阅读顺序的布局元素序列,这些异构元素作为锚点并与任务特定prompt结合,反馈给Dolphin以进行并行内容解析。有效融合传统方法的结构化优势与视觉语言模型的表达能力,在准确性和鲁棒性上实现显著提升。
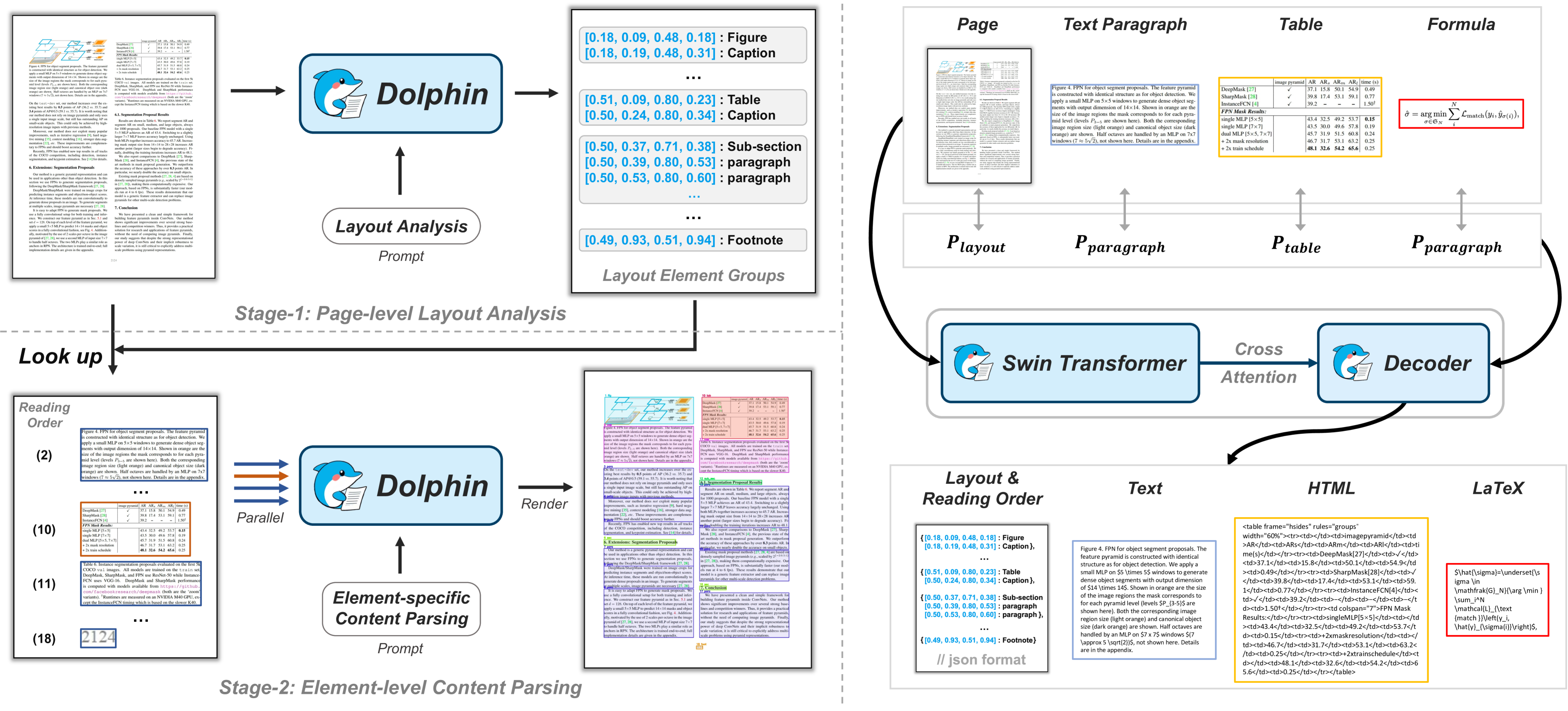
为训练Dolphin,官方构建一个超3000万样本的大规模数据集,涵盖多粒度解析任务。通过在主流基准和自建基准上的全面评估,Dolphin在多样化的页面级和元素级任务上均达到SOTA,同时由于其轻量级的架构配置和并行解析机制确保卓越的效率。
可改进方向:
- 增强对非标准布局的支持:当前模型主要支持标准水平文本布局,未来应扩展其能力以处理垂直文本,如古籍手稿等。这可能需要更灵活的布局分析模块和对不同书写方向的适应性。
- 扩展多语言覆盖范围:支持更多世界语言。
- 深化并行处理粒度:尽管已通过并行元素解析提高效率,但未来可进一步优化,实现文本行和表格单元格等更细粒度的并行处理,以实现更高的计算效率。
- 提升手写识别能力:当前模型对手写内容的识别能力有待提升。未来的工作可以探索集成专门的手写识别模块或利用更强大的视觉骨干网络来改善这一能力。
- 复杂图表语义理解:虽然能识别图表元素,但对图表中复杂数据可视化(如趋势、关系)的深层语义理解尚有空间。未来可探索结合图神经网络或更复杂的VLM技术,实现对非文本视觉元素的更高级理解。
- 泛化到更多文档类型:针对合同、发票、医疗报告等特定领域文档,可能需要领域特定的知识增强和微调,以实现更高精度的结构化信息提取,超越通用文档解析的范畴。
Stirling-PDF
官网,GitHub,一个功能超强的本地化PDF处理工具,基于浏览器界面操作;支持超过50种PDF处理功能,如文件分割、合并、压缩、格式转换、文字提取、OCR、加密和水印;数据全程在本地处理,安全又贴心,特别适合企业和个人使用。
核心功能:
-
PDF文件操作:
- 轻松合并多个PDF文件;
- 按页分割PDF;
- 调整PDF页面顺序、旋转页面或移除多余页;
- 自动识别空白页并删除。
-
PDF转换:
- PDF与图片互相转换;
- PDF转Word、Excel或HTML;
- 从网页链接、Markdown直接生成PDF。
-
高级编辑:
- 给PDF添加数字签名、页码、水印或注释;
- OCR识别扫描的文档并提取文字;
- 加密或移除密码保护的PDF文件。
-
其他特色功能:
- 检测并对比两个PDF文件的差异;
- 修复损坏的PDF;
- 调整压缩文件大小,优化存储空间。
安装
bash
docker pull stirlingpdf/stirling-pdf
docker run -d -p 8080:8080 stirlingpdf/stirling-pdf浏览器打开http://localhost:8080体验。
也可从官网下载exe安装程序。
OCRFlux
基于VLM的开源工具包,专为将PDF文档和图像转换为结构清晰、可读性强的Markdown文本而设计。一张12GB的RTX-3090显卡即可部署运行。官网。
模型地址:https://huggingface.co/ChatDOC/OCRFlux-3B
关键特性
- 单页解析的卓越品质
在单页解析方面,OCRFlux表现出色。与现有的基准模型olmOCR-7B-0225-preview、Nanonets-OCR-s和MonkeyOCR相比,在发布的基准测试OCRFlux-bench-single上分别实现0.095(从0.872到0.967)、0.109(从0.858到0.967)和0.187(从0.780到0.967)的更高编辑距离相似性(EDS)。这些改进主要来自于对复杂表格的高质量解析,尤其是在需要跨行和跨列合并单元格的情况下。
- 原生支持多页文档解析
与现有工具简单地按页拼接内容不同,OCRFlux是第一个能够自动检测并合并跨页元素以产生连贯文档结构的文档解析工具。在基准测试中,达到98.3%的高准确率。甚至能够在页面分割的情况下重建完整的表格,即使在诸如表头重复、多行单元格分割和表格垂直分割等复杂场景中也是如此。在交互式比较部分提供一些真实世界的跨页表格。参考表格和重建表格之间的TEDS得分平均达到0.950。
- 高效率与紧凑模型尺寸
OCRFlux仅包含30亿参数,这使其在实现更好性能的同时具有极高的效率。与70亿参数的基准模型相比,在GTX 3090 GPU上实现约3倍的更高吞吐量。
单页解析
- 列跨表与合并单元格:当表格单元格跨越多列时,确定单元格边界和关系变得十分困难。跨行或跨列合并的单元格模糊底层结构,导致识别单个单元格及其内容时出现歧义。OCRFlux能够精确地恢复它们,因为它在训练数据中使用HTML格式来表示表格,这自然支持表示复杂表格。
- 多栏布局:具有多栏的文档会破坏典型的从左到右的阅读顺序,需要复杂的算法来重建跨栏的文本元素之间的正确顺序和关系。OCRFlux能够准确识别多栏布局,并将其转换为具有自然阅读顺序的清晰Markdown。
- 多表:单页上的多个表格增加表格检测和解析的复杂性,要求系统能够区分不同的表格并正确地对每个表格进行分割。OCRFlux的整文件解析能力在解析过程中通过识别和分离它们来有效处理多个表格。
- 多语言:处理同一文档中的不同语言需要强大的语言识别和处理能力,因为不同书写系统的特性可能差异很大。
跨页段落/表格合并
- 跨越三页的表格:标准的PDF分页通常会将表格分割到不同的页面上,这使得OCR系统难以准确地重建它们。OCRFlux通过自动检测和合并碎片化的表格元素并匹配其表头,从而实现无缝且准确的输出。
- 表格垂直分割:具有众多列的表格通常会垂直分割到多个页面上,这给理解和准确地重新连接逻辑上相关的片段带来挑战。OCRFlux通过其先进的跨页表格合并能力有效地解决这一问题。
- 表头重复:当表格跨越多个页面时,表头通常会在每一页上重复,这可能会混淆OCR系统并导致误解。OCRFlux通过无缝合并跨页内容,删除多余的表头,同时保留必要的表格数据来解决这一问题。
- 多行单元格分割:内容较多的单元格可能会跨越多个页面,这给正确合并这些碎片化的行以保持数据完整性带来挑战。OCRFlux有效地确保完整的、准确的单元格内容在最终输出中得以保留。
训练
- 单页解析训练
为了确保OCRFlux-3B模型在单页解析方面的高质量,使用私有文档数据集来训练模型。包含大约110万页,主要来自金融和学术文件。都经过多轮人工标注和检查。使用公共olmOCR-mix-0225数据集中的部分数据(约25万页)。发现GPT-4o在包含表格的页面上的真实标签质量较差,因此在训练中过滤掉它们。
与olmOCR等先前的工作不同,模型仅使用页面图像作为输入,而不是任何元数据,如文本块及其位置。这一决定与RolmOCR中的决策一致。这不会损害模型的准确性,反而会显著减少提示长度,从而降低处理时间和内存消耗。此外,它还可以避免因损坏的元数据或OCR结果(如错误读取的字符、错误的阅读顺序和内容缺失)而可能引起的潜在错误。
由于Markdown本身无法自然地表示具有rowspan和colspan单元格的复杂表格,在训练数据中使用HTML格式来表示表格。
- 跨页段落/表格合并训练
PDF文档通常以分页形式呈现,这常常导致表格或段落被分割到连续的页面上。准确地检测并合并这些跨页结构对于避免生成不完整或碎片化的内容至关重要。
检测任务可以表述如下:给定两个连续页面的Markdowns------每个都结构化为Markdown元素(例如,段落和表格)的列表------目标是识别出应该跨页合并的元素的索引。
然后对于合并任务,如果要合并的元素是段落,可以简单地将它们连接起来。然而,对于两个表格片段,它们的合并要复杂得多。
为了训练模型执行检测和合并任务,在训练中使用大约45万份样本用于检测任务,10万份样本用于合并任务。都来自私有数据集。
没有分别训练单页解析和跨页合并任务,而是将它们一起在同一个多模态LLM中联合训练,使用不同的提示。有助于将这两种能力整合到一个单一模型中,使其在推理时更加强大和高效。
评估
单页解析评估
将OCRFlux-3B模型与olmOCR-7B-0225-preview和Nanonets-OCR-s作为基线进行比较。使用两个基准测试:
- OCRFlux-bench-single:包含2000个PDF页面(1000个英文页面和1000个中文页面)及其真实Markdowns(经过多轮人工标注和检查)。
- OCRFlux-pubtabnet-single:从公共PubTabNet基准测试中衍生而来,经过一些格式转换。包含9064个HTML表格样本,根据它们是否具有rowspan和colspan单元格,被分为简单表格和复杂表格。
发布的基准测试数据并未包含在训练和评估数据中。以下是主要结果:
- 在OCRFlux-bench-single中,计算生成的Markdowns与真实Markdowns之间的编辑距离相似性(SED)作为评估指标;
- 在OCRFlux-pubtabnet-single中,计算生成的HTML表格与真实HTML表格之间的TEDS作为评估指标。
(二)跨页段落/表格合并评估
在跨页段落/表格合并评估中,由于olmOCR-7B-0225-preview和Nanonets-OCR-s没有相应的功能,仅报告OCRFlux-3B的结果。同样使用两个基准测试:
- OCRFlux-bench-cross:包含1000个样本(英文和中文样本各500个),每个样本包含两个连续页面的Markdown元素列表,以及需要合并的元素的索引(经过多轮人工检查后标注)。如果没有表格或段落需要合并,则注释数据中的索引为空。
- OCRFlux-pubtabnet-cross:包含9064对分割的表格片段,以及它们对应的合并后的版本。
发布的基准测试数据同样未包含在训练和评估数据中。以下是主要结果:
- 在OCRFlux-bench-cross中,计算准确率、精确率、召回率和F1分数作为评估指标。只有当它准确判断出两个页面之间是否有需要合并的元素并输出正确的索引时,检测结果才算正确;
- 在OCRFlux-pubtabnet-cross中,计算生成的合并表格与真实合并表格之间的TEDS作为评估指标。
运行:python -m ocrflux.pipeline ./localworkspace --data test.pdf --model /model_dir/OCRFlux-3B
LangExtract
谷歌开源,使用Google Gemini从非结构化文本中提取结构化信息,具备精确的源定位和交互式可视化功能。特别强调结果的可追溯性和透明性。每一个被抽出来的信息,都会直接关联到原文中的出处,即:可回溯+验证+审计,尤其适用于医疗、金融这类对准确性要求极高的领域。
功能:
- 精确源定位:将每个提取结果映射到源文本的确切位置,通过可视化高亮显示实现轻松追踪和验证;
- 可靠的结构化输出:基于少样本示例强制执行一致的输出模式,利用Gemini等支持模型的受控生成功能;
- 长文档优化:使用优化的文本分块、并行处理和多轮传递克服"大海捞针"的挑战,实现更高的召回率;
- 领域适应性:仅使用少量示例即可为任何领域定义提取任务,无需微调模型即可适应您的需求;
- 交互式可视化:生成交互式HTML可视化,通过直观的高亮显示在上下文中查看提取的实体;
- 集成方便:支持Google Colab、Jupyter,开发调试的闭环很顺畅;
- LLM支持:支持从Gemini系列到通过Ollama接口的本地开源模型等多种LLM。
对比
| 特性 | 传统方法 | LangExtract |
|---|---|---|
| 结构一致性 | 手动处理,容易出错 | 通过指令和示例强制保证 |
| 结果可追溯性 | 很弱,常丢失上下文 | 每个输出都链接回原文 |
| 长文本处理 | 分窗口处理,易丢失信息 | 分块+并行+聚合 |
| 可视化支持 | 通常需要自定义开发 | 内置交互式HTML报告 |
| 部署灵活性 | 模型固定,扩展难 | 以Gemini为主,支持其他LLM,可本地部署 |
优势:
- 并行处理:支持多线程处理,提高长文档处理效率
- 多轮提取:通过多次提取提高召回率
- 上下文优化:可调整上下文大小以获得更好的准确性
安装:pip install langextract
示例:
py
import langextract as lx
import textwrap
# 1. 定义提示词
prompt = textwrap.dedent("""
Extract characters, emotions, and relationships in order of appearance.
Use exact text for extractions. Do not paraphrase or overlap entities.
Provide meaningful attributes for each entity to add context.
""")
# 2. 提供高质量示例
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks? It is the east, and Juliet is the sun.",
extractions=[
lx.data.Extraction(extraction_class="character", extraction_text="ROMEO", attributes={"emotional_state": "wonder"}),
lx.data.Extraction(extraction_class="emotion", extraction_text="But soft!", attributes={"feeling": "gentle awe"}),
lx.data.Extraction(extraction_class="relationship", extraction_text="Juliet is the sun", attributes={"type": "metaphor"}),
],
)
]
# 3. 对新文本进行抽取
input_text = "Lady Juliet gazed longingly at the stars, her heart aching for Romeo"
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-pro" # gemini-2.5-flash,
# config=model_config, # 使用ModelConfig
fence_output=True,
use_schema_constraints=False,
debug=False
)
# 4. 保存并生成可视化报告
lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl")
html_content = lx.visualize("extraction_results.jsonl")
withopen("visualization.html", "w") as f:
f.write(html_content)LangExtract的解析结果为Extraction类型的对象列表,代表抽取信息的完整结构,一个数据结果的容器,包含如下信息:
- 核心层:定义"是什么"
- extraction_class:实体类型
- extraction_text:提取的具体文本内容
- 定位层:记录"在哪里
- char_interval:字符级别的精确位置
- token_interval:Token级别的位置(更适合NLP处理)
- 组织层:管理"如何组织"
- extraction_index:全局序号
- group_index:分组编号
- alignment_status:匹配质量状态
- 语义层:描述"更多信息"
- description:人类可读的描述
- attributes:结构化属性字典,关键特性
LangExtract在超长文档解析上的一些设计策略:
- 多次提取:借助
extraction_passes参数,可以执行独立的多次提取,以发现每次提取中出现的新的非重叠实体,从而减少遗漏; - 智能分块:通过分块使用更小的上下文,提高单次推理的提取质量,减少上下文干扰;通过对文本分隔符等智能识别,确保上下文完整性和格式规范;
- 并行处理:为了提高大文档的处理性能,可以设置并行化处理
max_workers参数,以减少总体延迟,同时也可以更好的配合分块处理。