
已在GitHub开源与本博客同步的YOLOv5_RK3588_object_detect项目 ,地址:https://github.com/A7bert777/YOLOv5_RK3588_object_detect/tree/main
详细使用教程,可参考README.md或参考本博客第六章 模型部署
文章目录
- 一、项目回顾
- 二、模型选择介绍
- 三、项目文件梳理
- [四、YOLOv5模型训练 & PT转ONNX](#四、YOLOv5模型训练 & PT转ONNX)
- 五、ONNX转RKNN
- 六、模型部署
一、项目回顾
博主之前有写过YOLO11、YOLOv8目标检测&图像分割、YOLOv10目标检测、MoblieNetv2、ResNet50图像分类的模型训练、转换、部署文章,感兴趣的小伙伴可以了解下:
【YOLO11部署至RK3588】模型训练→转换RKNN→开发板部署
【YOLOv10部署RK3588】模型训练→转换rknn→部署流程
【YOLOv8-obb部署至RK3588】模型训练→转换RKNN→开发板部署
【YOLOv8-pose部署至RK3588】模型训练→转换RKNN→开发板部署
【YOLOv8部署至RK3588】模型训练→转换rknn→部署全流程
【YOLOv8seg部署RK3588】模型训练→转换rknn→部署全流程
【MobileNetv2图像分类部署至RK3588】模型训练→转换rknn→部署流程
【ResNet50图像分类部署至RK3588】模型训练→转换RKNN→开发板部署
YOLOv8n部署RK3588开发板全流程(pt→onnx→rknn模型转换、板端后处理检测)
二、模型选择介绍
近期需要做一个针对图像目标检测的模型,并部署到RK3588公版的开发板上,可选择的有YOLOv5、YOLOv8、YOLOv10、YOLO11等,其他算法都已经部署过了,博主其实最早接触到的算法就是YOLOv5,但后续新YOLO算法层出不穷,大家也都转向了YOLOv8、11等算法,也就冷落了YOLOv5,但仍不能否认其价值,因此准备出一篇YOLOv5的全流程部署教程,以此文记录,相互学习,诸君共勉。
三、项目文件梳理
YOLOv5训练、转换、部署所需三个项目文件:
第一个:YOLOv5模型训练以及转换onnx的项目文件(链接在此);
第二个:用于在虚拟机中进行onnx转rknn的虚拟环境配置项目文件(链接在此);
第三个:在开发板上做模型部署的项目文件(链接在此);
这里说下为什么第一个文件要用瑞芯微的仓库而不是ultralytics官方的仓库 ,瑞芯微的官方回复如下:
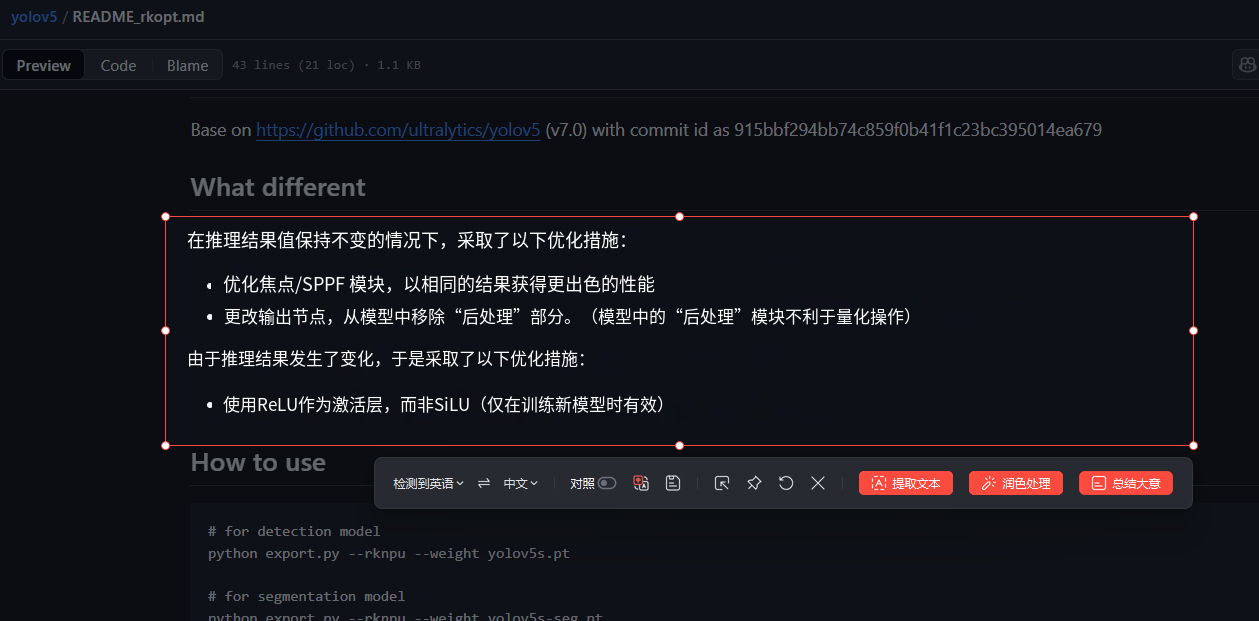
是因为为了优化Focus以及SPPF模块,并将原项目中的激活函数改为ReLU,以更好地适配瑞芯微系列的芯片,如RK3588等。
当然了,如果你就是想用ultralytics官方的yolov5去训练,其实也没有问题,只要注意下版本即可,最好选用7.0版本,但要记得在转换ONNX模型时一定要在瑞芯微的yolov5项目下进行
注:第一个文件使用master版本,第二个和第三个文件均使用2.1.0tag版本
如下所示:
四、YOLOv5模型训练 & PT转ONNX
先将第一个文件 git clone 后(我将其重命名为yolov5-rknn),创建并安装conda环境:
bash
pip install -r requirements.txt等待安装完成
将train.py下的 def parse_opt(known=False): 中的参数进行修改,包括weights、cfg、data、epochs、batch-size等,如下所示:
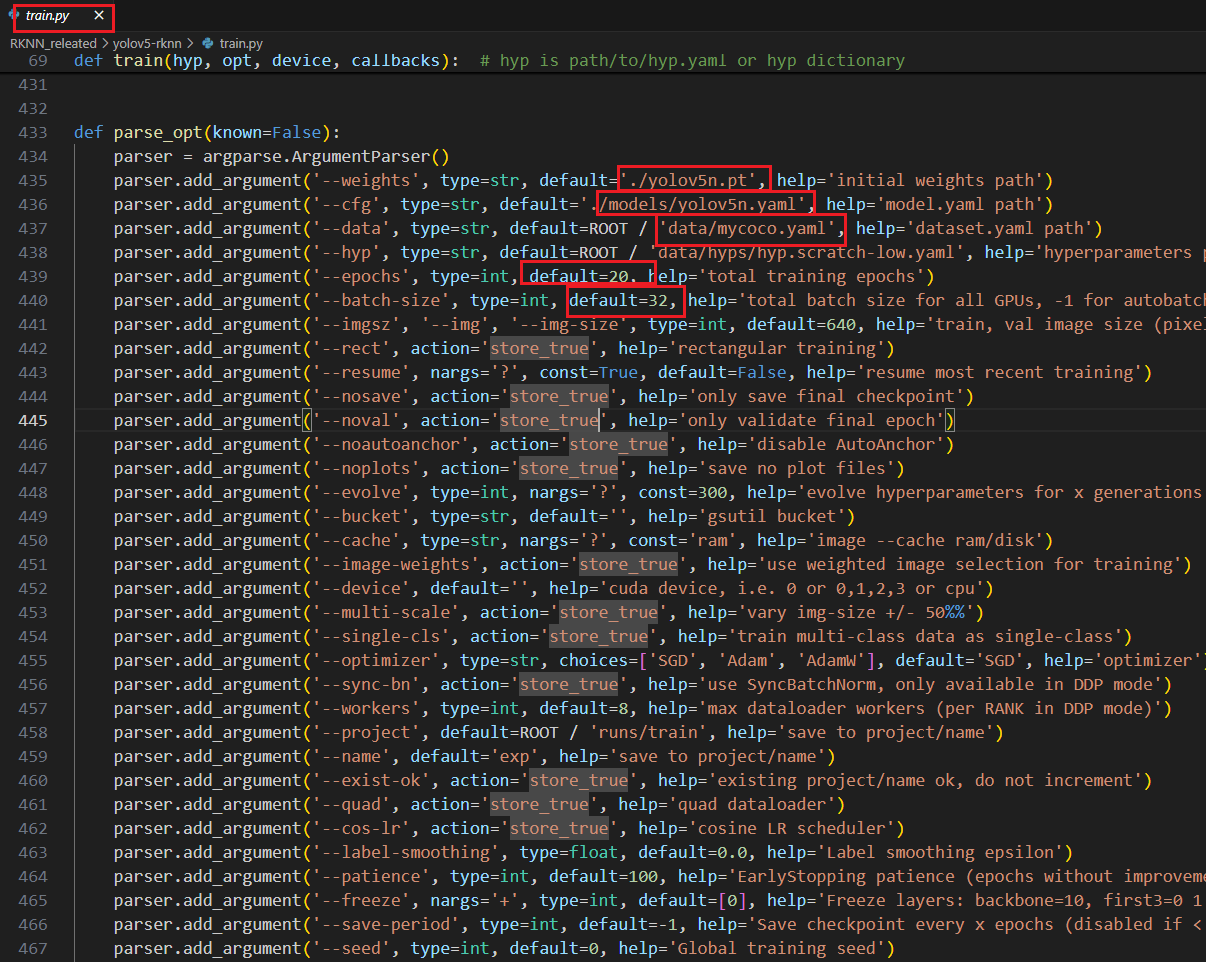
yolov5n.pt建议自己去官网先下好,不然训练前做AMP的时候会自动下载,速度较慢
yolov5n.yaml如下所示(可直接复制我的):
yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 8 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]只需改成自己数据集的类别即可,我的数据集中共有8个类别
mycoco.yaml如下所示(可直接复制我的,但是要把数据集路径和类别数量及类别名称改成自己的):
yaml
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# COCO 2017 dataset http://cocodataset.org by Microsoft
# Example usage: python train.py --data coco.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco ← downloads here (20.1 GB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /Dataset/Constrution/MOCS/MOCS # dataset root dir
train: /Dataset/Constrution/MOCS/MOCS/images/train # train images (relative to 'path') 118287 images
val: /Dataset/Constrution/MOCS/MOCS/images/val # val images (relative to 'path') 5000 images
#test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# number of classes
nc: 8
# Classes
names: ['Worker', 'Bulldozer', 'Excavator', 'Truck', 'Loader', 'Pump truck', 'Concrete transport Mixer', 'Pile driver']至于batchsize和epoch就因人而异了,我主要是做个演示,所以epoch就设为20,常规设置为300,batchsize为64
执行train.py进行训练:
bash
python train.py训练完成后,终端结果如下所示:

然后将训练好的best.pt模型复制到yolov5-rknn路径下,我将其重命名为yolov5_rknn7.0_best.pt,然后执行命令:
bash
python export.py --rknpu --weight yolov5_rknn7.0_best.pt如下所示:
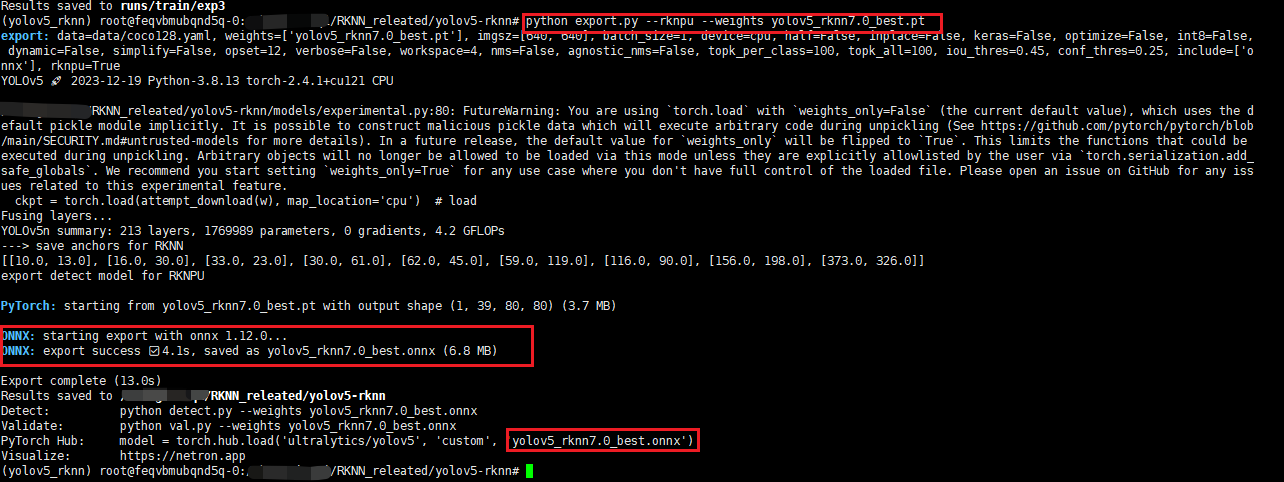
可以看到,在当前路径下生成了同名的onnx模型:
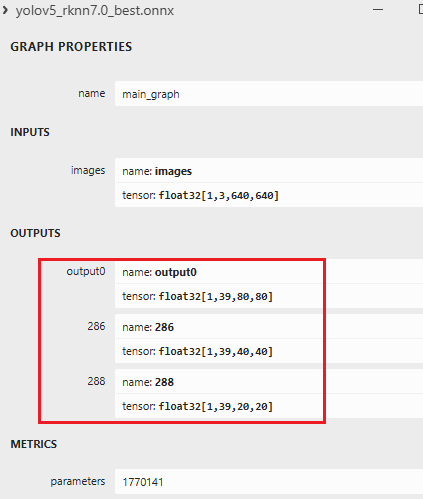
此时需要用netron打开onnx模型,观察模型输出是否正确,应该为如下所示,即有三个输出通道:
五、ONNX转RKNN
在进行这一步的时候,如果你是在云服务器上运行,请先确保你租的卡能支持RKNN的转换运行。博主是在自己的虚拟机中进行转换 。
先安装转换环境
这里我们先创建环境:
bash
conda create -n rknn210 python=3.8创建完成如下所示:
现在需要用到 第二个文件:rknn-toolkit2-2.1.0文件 。
进入rknn-toolkit2-2.1.0\rknn-toolkit2-2.1.0\rknn-toolkit2\packages文件夹下,看到如下内容:
在终端激活环境,在终端输入
bash
pip install -r requirements_cp38-2.1.0.txt -i https://pypi.tuna.tsinghua.edu.cn/simple然后再输入
bash
pip install rknn_toolkit2-2.1.0+708089d1-cp38-cp38-linux_x86_64.whl然后,我们的转rknn环境就配置完成了。
现在要进行模型转换,其实大家可以参考rknn_model_zoo-2.1.0\examples\yolov5下的README指导进行转换:
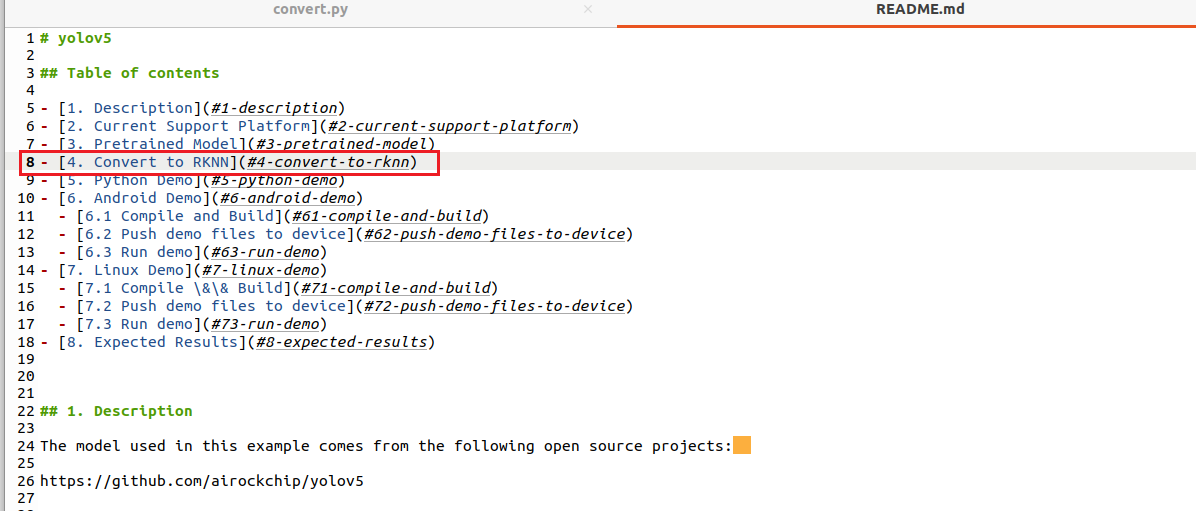
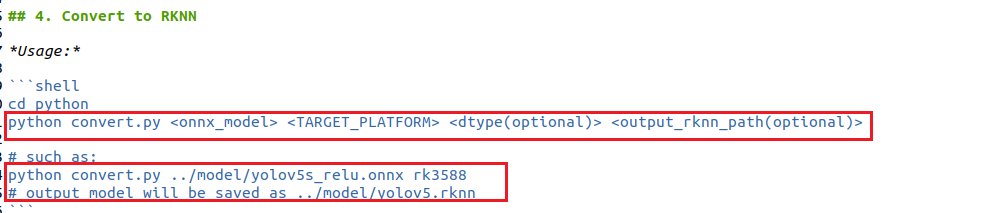
这里我也详细再说一遍转换流程,修改convert.py,如下所示:
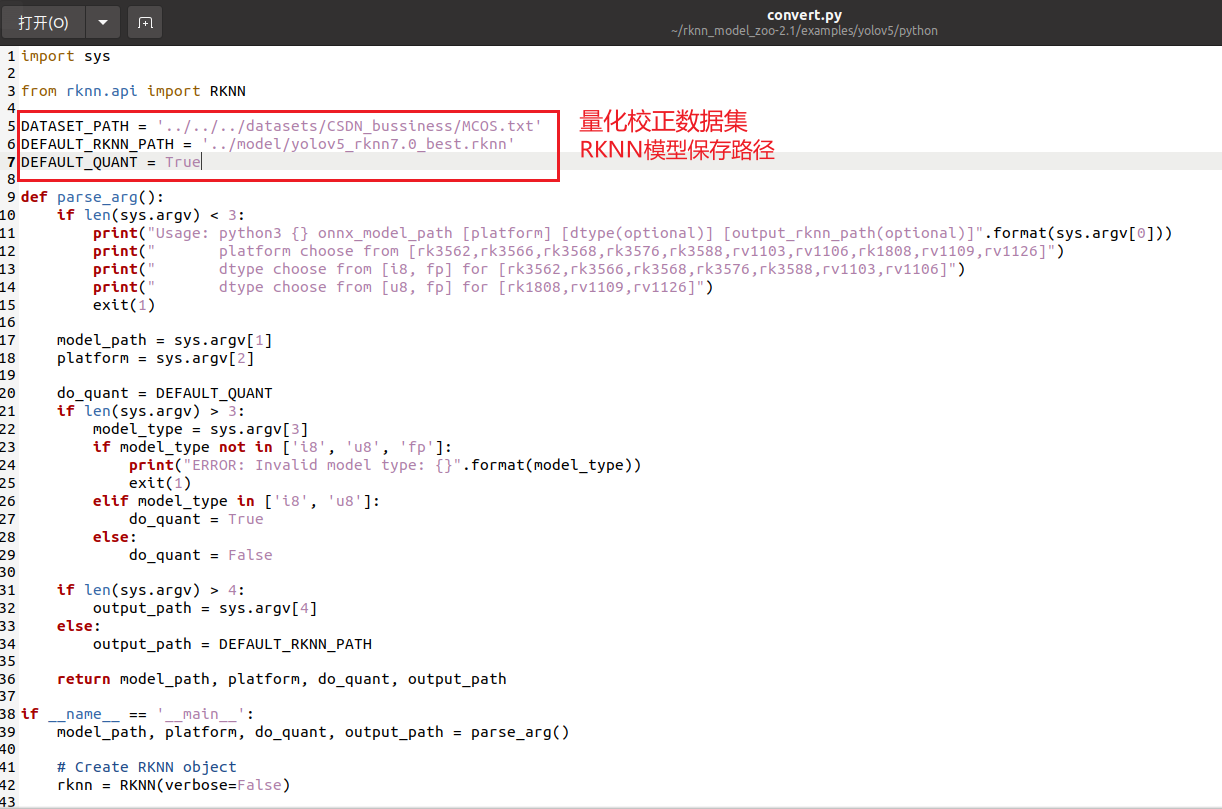
修改完成后,将我们之前得到的onnx模型复制到model文件夹下:
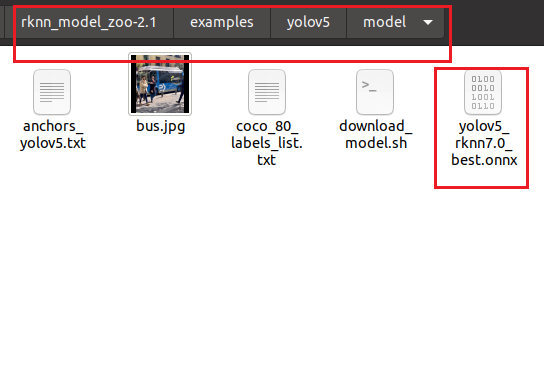
打开终端,激活rknn210环境,输入命令:
bash
python convert.py yolov5_rknn7.0_best.onnx rk3588结果如下:
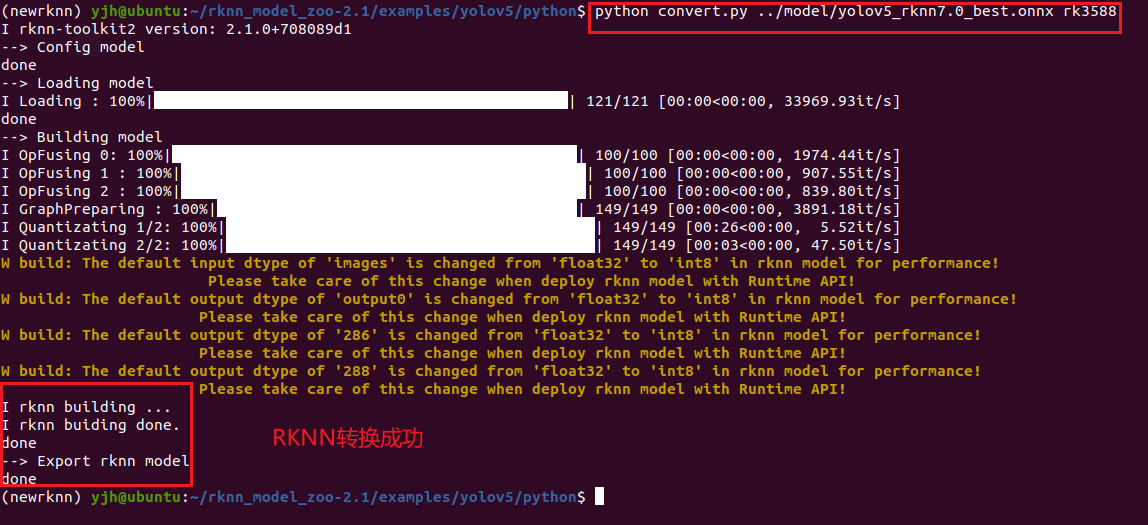
在model文件夹下生成了RKNN模型,如下所示:
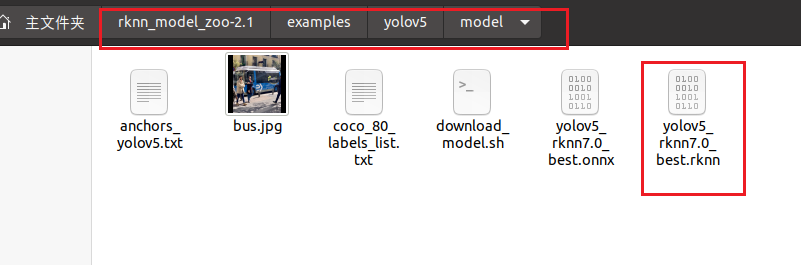
复制到win下,用netron打开,输出结构如下所示:
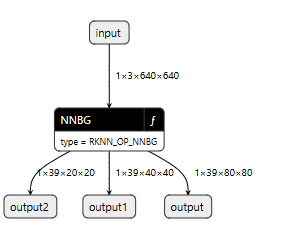
可以看到,和ONNX一致,同为三个输出
六、模型部署
如果前面流程都已实现,模型的结构也没问题的话,则可以进行最后一步:模型端侧部署。
我已经帮大家做好了所有的环境适配工作,科学上网后访问博主GitHub仓库: YOLOv5_RK3588_object_detect ,进行简单的路径修改就即可编译运行。
统一声明:
1、这个仓库的项目只能做图片的批量检测,不支持视频流检测,没时间做这个,有需要的自己修改代码。
2、从GitHub的README.md中加QQ后直接说问题和小星星截图,对于常见的相同问题,很多都已在CSDN博客中提到了(RKNN转换流程是统一的,可去博主所有的RKNN相关博客下去翻评论),已在评论中详细解释过的问题,不予回复。
重点:请大家举手之劳,帮我的仓库点个小星星
点了小星星的同学可以免费帮你解决转模型与部署过程中遇到的问题。
我已经把自己的RKNN模型放到了Github项目的model文件夹下、测试图片放到inputimage文件夹下,大家 git clone 后可直接先把build下内容删掉然后重新编译,在用我的RKNN模型和图片直接运行测试。
git clone后把项目复制到开发板上,按如下流程操作:
①:cd build,删除所有build文件夹下的内容
②:cd src 修改main.cc,修改main函数中的如下三个内容,将这三个参数改成自己的绝对路径:
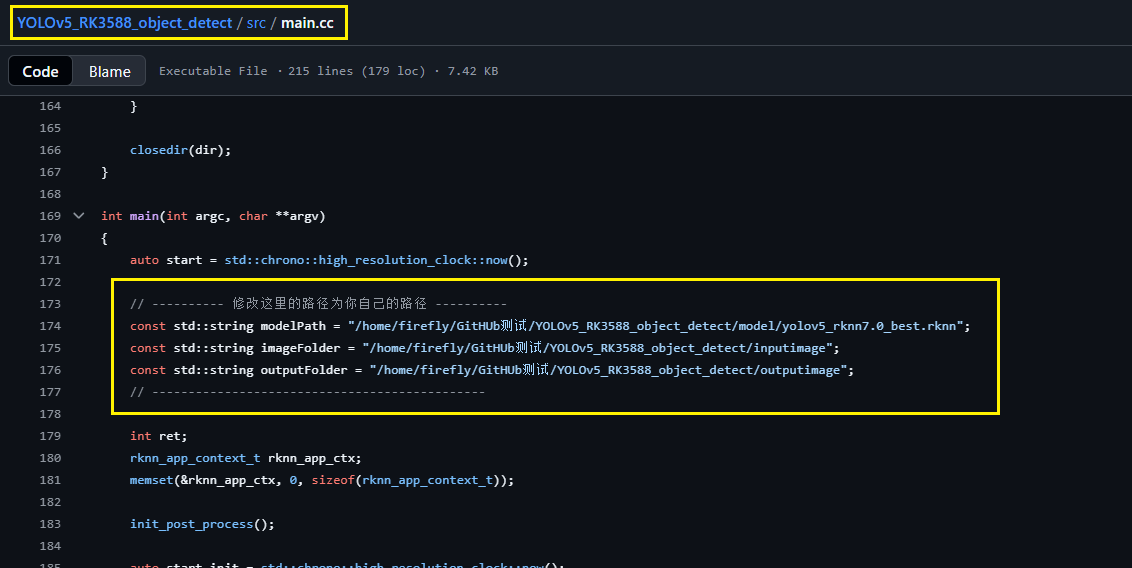
③:cd src 修改postprocess.cc下的txt标签的绝对路径:
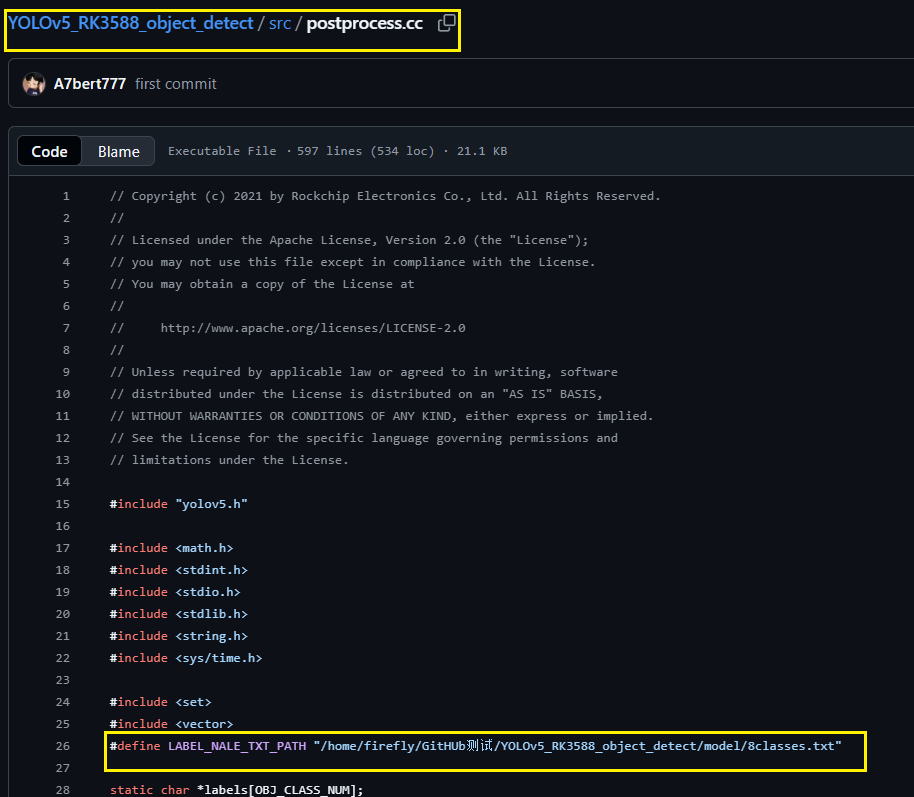
解释一下,这个标签路径中的内容如下所示:
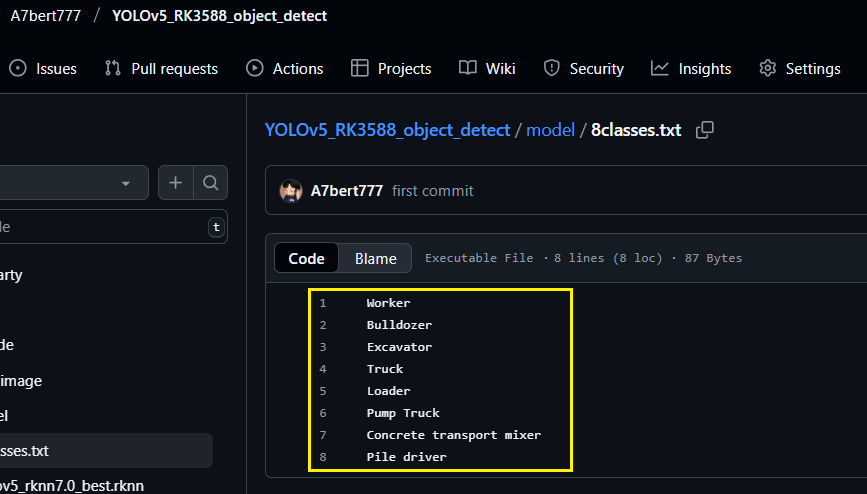
其实就是你在训练模型时在yaml配置文件中的那几个类别名(如果你先用博主的RKNN模型测试,则无需要改txt中的内容)
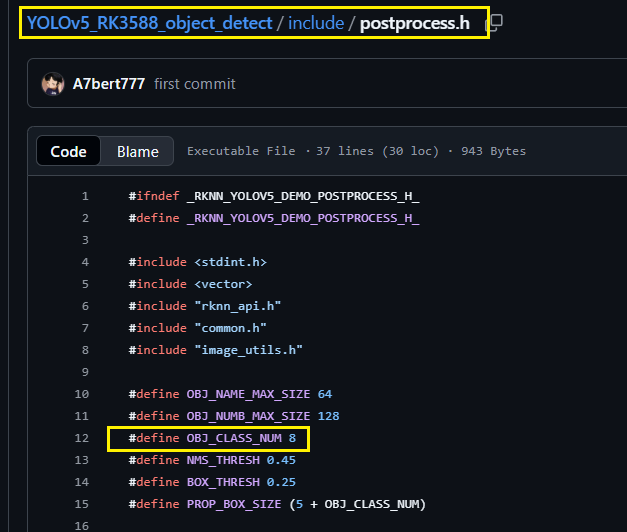
④修改include/postprocess.h 中的宏 OBJ_CLASS_NUM
⑤:把你之前训练好并已转成RKNN格式的模型放到 model 文件夹下,然后把你要检测的所有图片都放到 inputimage 文件夹下,在运行程序后,生成的结果图片在 outputimage 目录下。
⑥:进入build文件夹进行编译
bash
cd build
bash
cmake ..
bash
make在build下生成可执行文件文件:rknn_yolov5_demo
在build路径下输入
bash
./rknn_yolov5_demo运行结果如下所示:
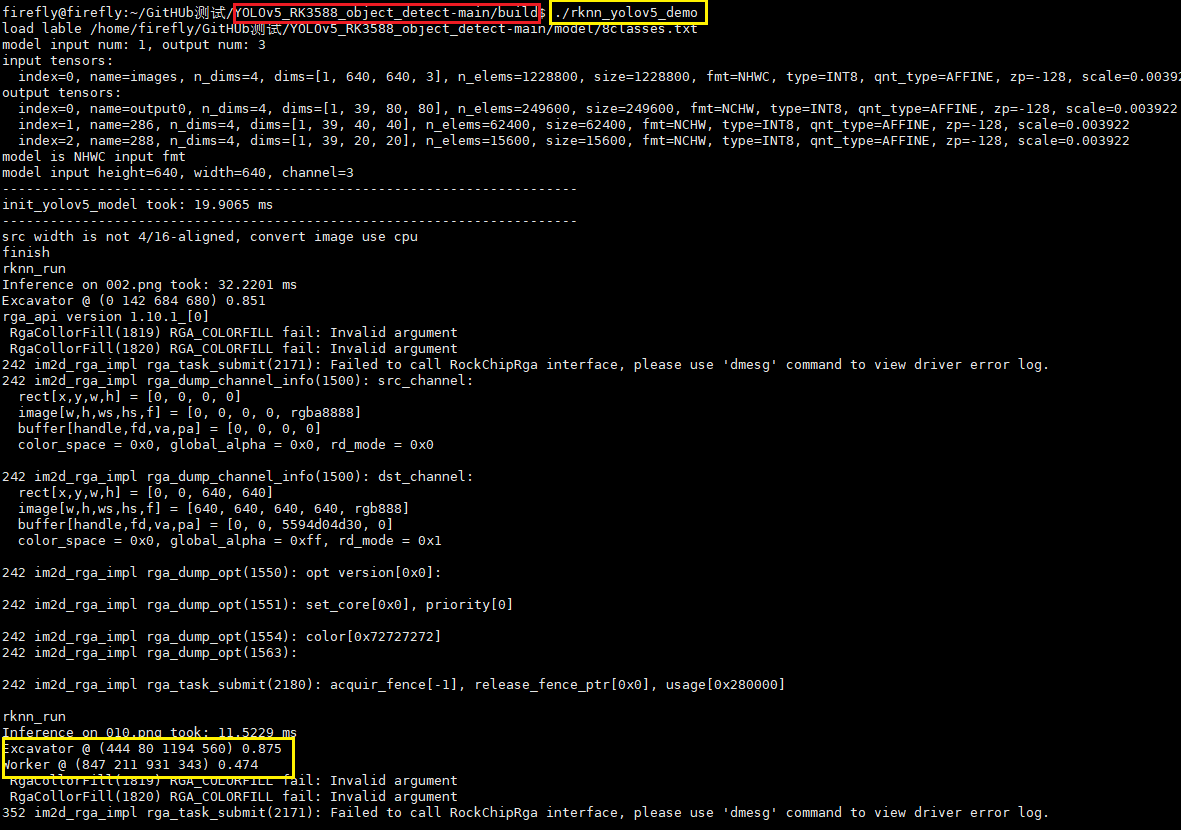
生成的结果图片在 outputimage 目录下,我也将其上传到Github项目中:
在执行完 ./rknn_yolov5_demo 后在 outputimage 下的输出结果图片示例:





上述即博主此次更新的YOLOv5部署RK3588,包含PT转ONNX转RKNN的全流程步骤,欢迎交流!