【跨国数仓迁移最佳实践7】基于MaxCompute多租的大数据平台架构
本系列文章将围绕东南亚头部科技集团的真实迁移历程展开,逐步拆解 BigQuery 迁移至 MaxCompute 过程中的关键挑战与技术创新。本篇为第七篇,基于MaxCompute多租的大数据平台架构。
注:客户背景为东南亚头部科技集团,文中用 GoTerra 表示。
一、为什么要采用多租架构
GoTerra 原来在GCP上,使用Bigquery作为数仓。由于企业规模和合规要求,GoTerra 集团每个业务实体(Business Entity)必须使用单独的云账号,管理和使用云资源,同时进行单独的成本结算。
但对于GoTerra 这样多业务实体的集团公司,GoTerra 多个云账号(下文已租户替代)又带来了跨租户的资源访问、多租户管理、统一资源管控、统一成本管理等挑战。
尤其对于大数据平台来说,为避免各租户重复建设导致资源浪费,一般需要集中建设,但这又不符合企业合规要求;若分开建设的话,又面临跨租户数据访问的挑战。为解决这些问题,GoTerra 在GCP平台上,利用GCP良好的多租户设计和Bigquery跨租户数据访问能力,设计了其"控制平面多租共享、数据平面单租互访"的大数据平台架构,如下: 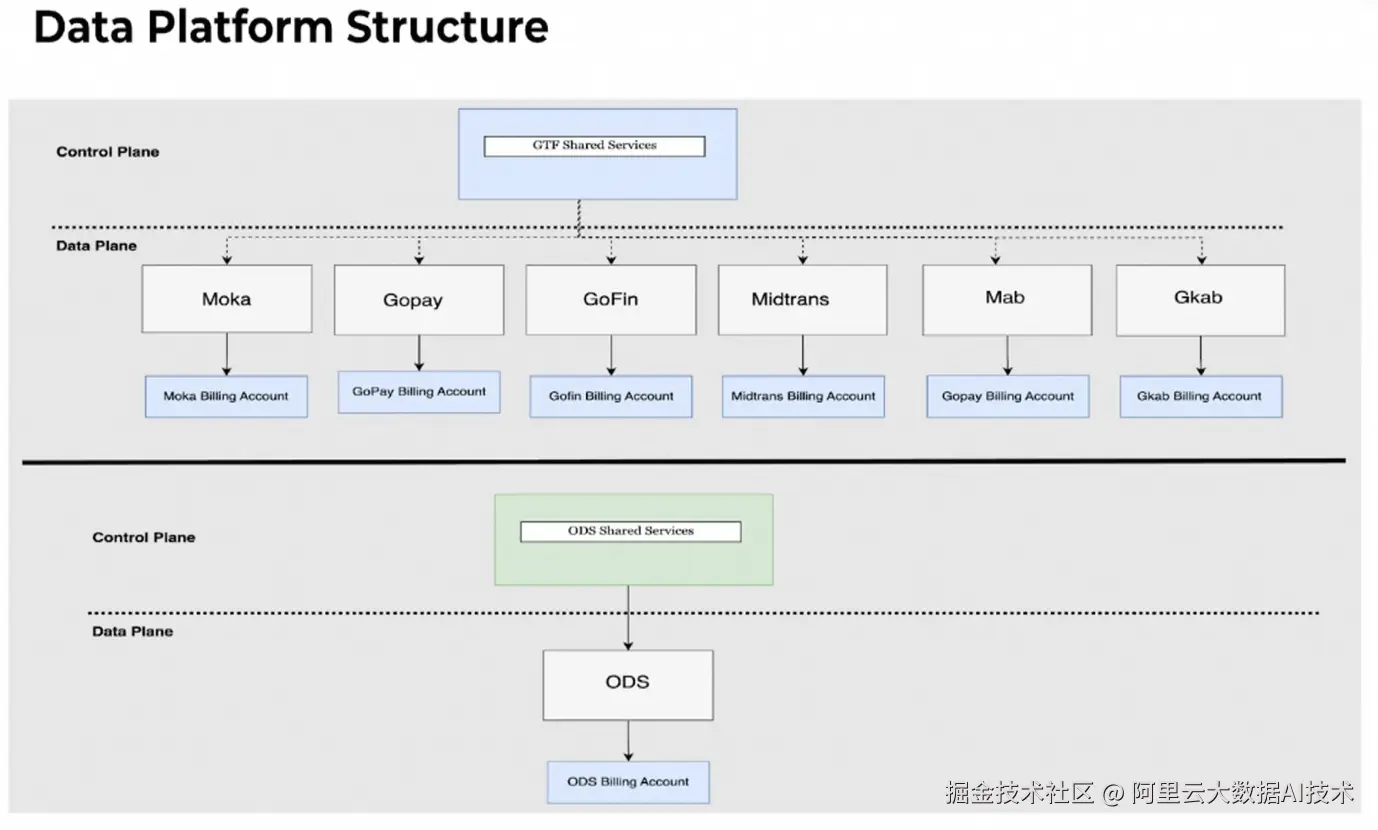
即:
a.控制平面多租户共享资源,主要包括任务调度、元数据管理、数据质量、监控告警、访问控制等大数据基础能力,由企业的DWH/DW团队统一维护,费用分摊到各个业务租户account
b.数据平面每个业务实体account单租,由Bigquery提供数据接入、数据计算、数据存储和服务的数仓能力,由各个业务实体的DA/DS团队来管理和维护,同时在控制平面的管控下,可以授权访问其他租户Bigquery数据
二、MaxCompute现有多租能力
迁移到MaxCompute,我们跟客户经过了详细的讨论和设计,借助阿里云跨租户云资源访问能力和MaxCompute多租能力,实现了类似的平台架构。
首先,我们先回顾下MaxCompute的多租能力。如下图所示:MaxCompute在同一集群/region下支持多个租户,每个租户下包含项目Project、Quota、网络连接等云资源。Project主要管理数据对象、作业实例、用户角色等;Quota主要管理计算资源。每个租户可以通过跨项目数据访问/代理授权,实现受控的数据互访。 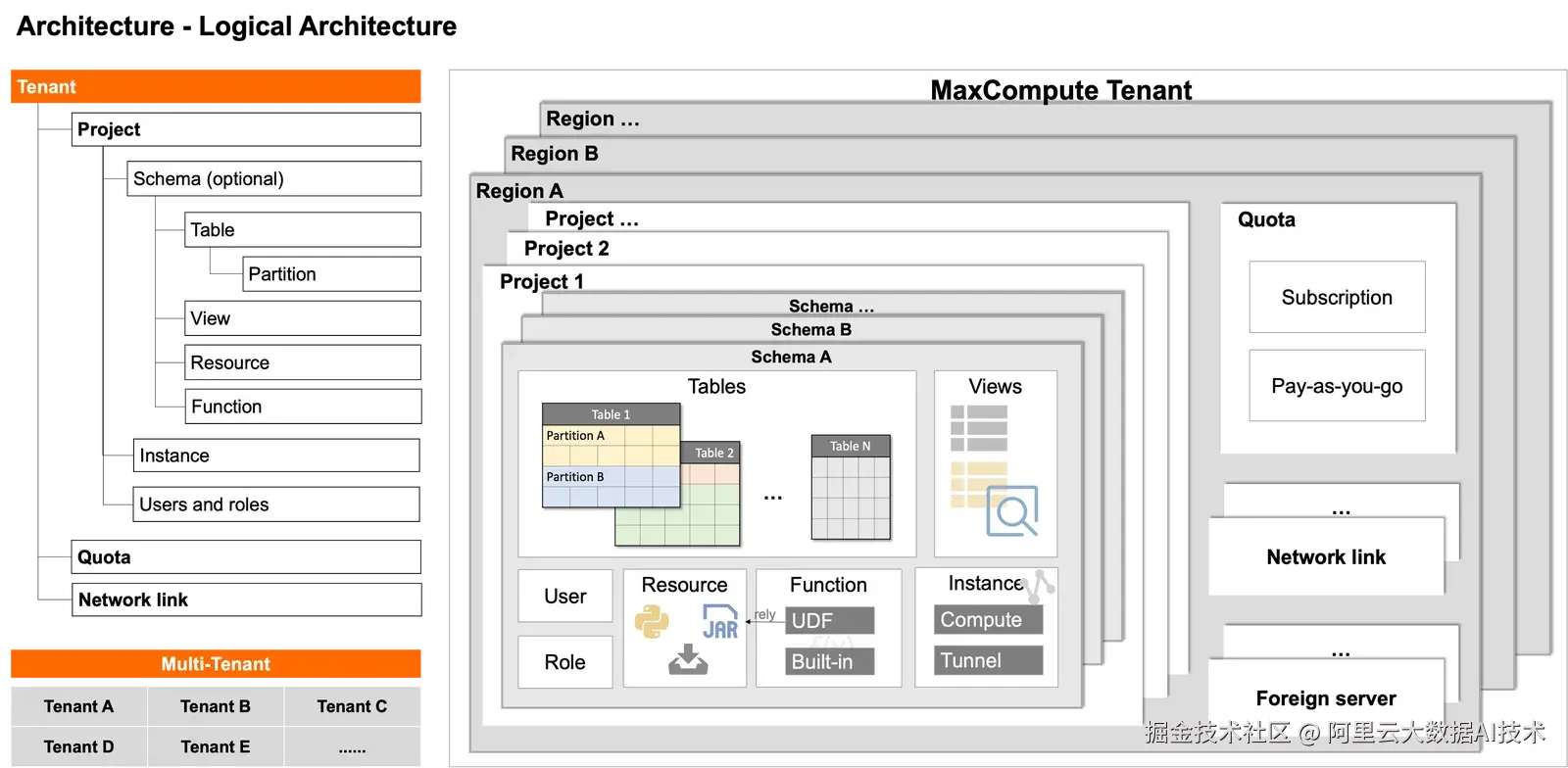
虽然MaxCompute本身是支持多租的,但我们原来谈多租,多是强调其隔离性和安全性,并没有涉及多租在如GoTerra 这样大的集团公司跨账号上的使用场景。所以,MaxCompute多租能力技术上具备了,但实际在商业化/商业模式上没有走出类似于Bigquery Data Mesh这样的创新数据架构。
三、如何在阿里云上实现基于MaxCompute多租的大数据平台架构
如何实现GoTerra 客户在GCP上的多租大数据架构呢?首先我们来分析下需要具备什么样的多租能力? 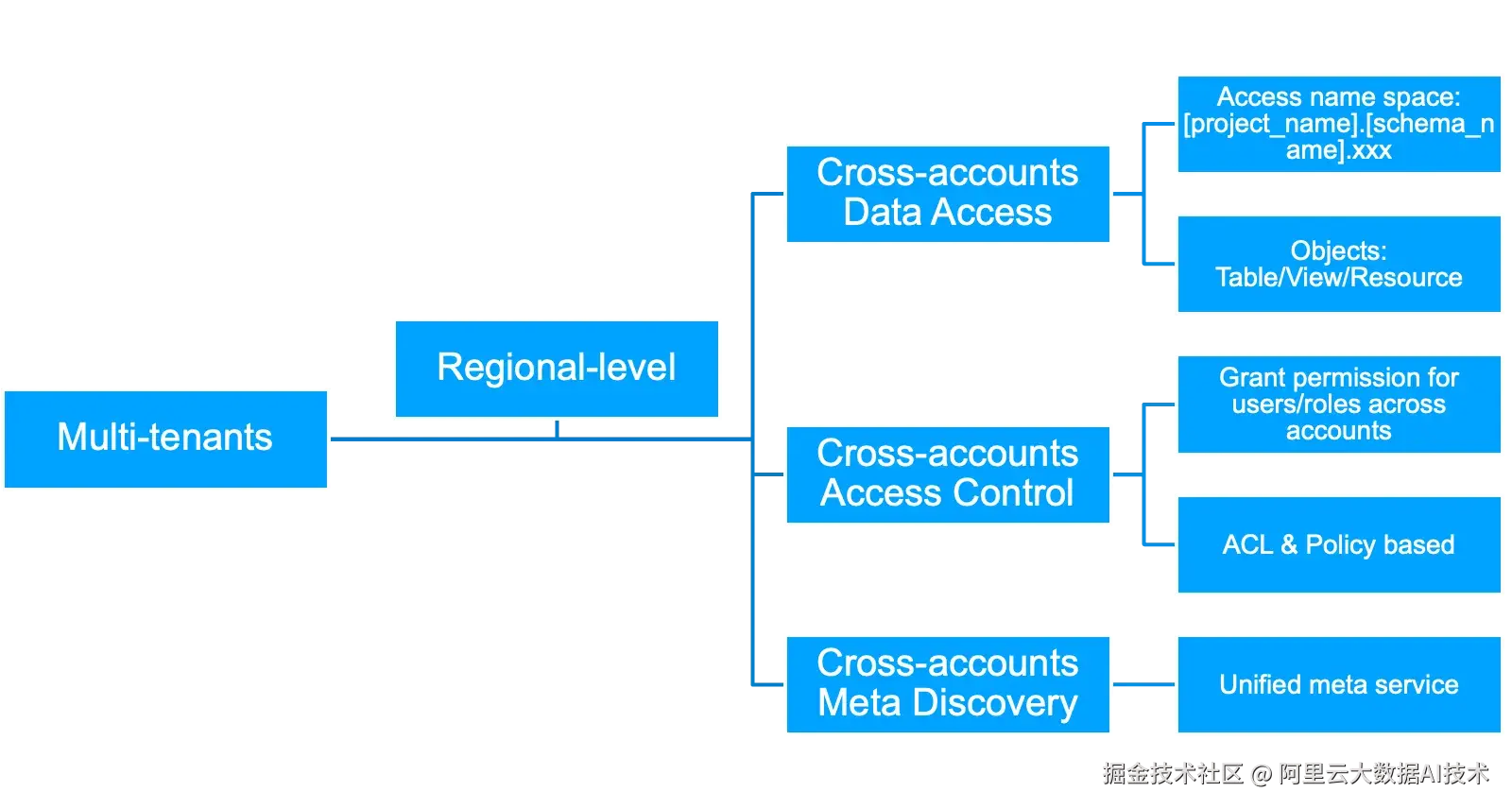
a.跨租户的数据访问:
- 需要有统一的命名空间方便访问:Bigquery是通过project_name.dataset_name.object_name来支持跨租户的数据访问,这个MaxCompute是已经支持的,可以通过project_name.schema_name.object_name来访问
- 需要具备管理数据访问对象的能力:如上文介绍,MaxCompute已经具备
b.跨租户的数据访问控制
- 原来MaxCompute提供了受限的跨租户访问控制能力:基于package的跨项目数据访问和云账号代理授权。但基于package的跨项目数据访问方式无法支持细粒度的访问授权,云账号代理授权的方式无法支持灵活的访问授权,这些都影响了跨租户数据访问的应用。
- ACL和Policy based访问授权:MaxCompute本身支持ACL和Poly based访问授权,但支持上述精细化、灵活授权,需要做增强
c.跨租户的元数据发现
- 在跨租户场景下,需要能够访问跨租户的MaxCompute元数据,方便数据的使用和处理
- 本身MaxCompute元数据是租户共享的,但不管是MaxCompute控制台和DataWorks元数据管理,仅支持同一租户下的元数据发现,即用户可以看到同一租户下的MaxCompute元数据。
从上所知,MaxCompute需要在跨租户的数据访问授权、元数据发现做额外的增强,这些需求已经开发并交付给GoTerra 客户使用,后续也会正式发布,成为MaxCompute公共云的通用能力。
MaxCompute具备了多租能力之后,因为GoTerra 使用阿里云账号访问MaxCompute,也需要阿里云支持跨账号的资源访问,这部分是基于阿里云RAM跨账号授权来实现,示例如下: 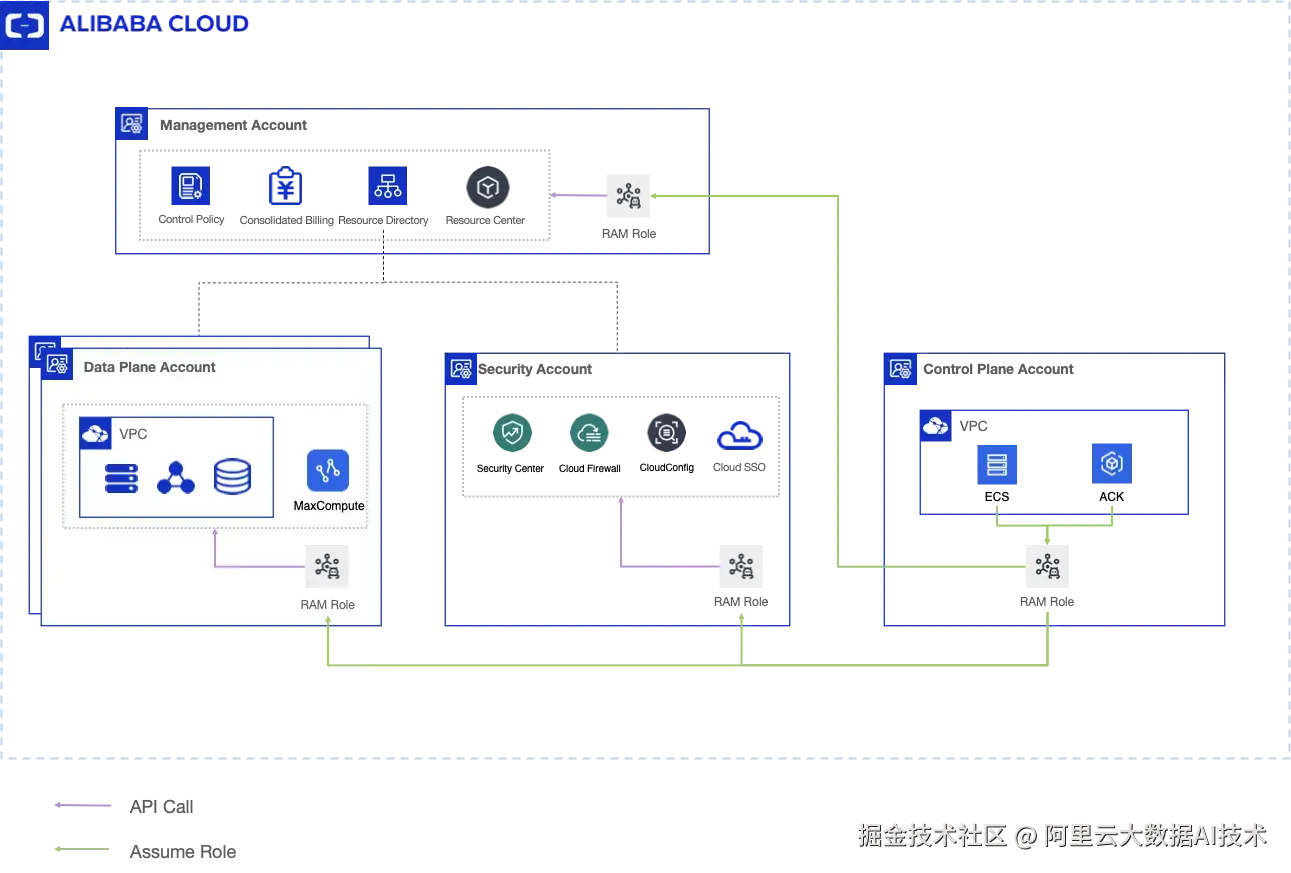
a.创建一个大数据平台控制平面的云账号(Control Plane Account A )和多个数据平面云账号(Data Plane Account B1 ~Data Plane Account Bn)
b.在控制平面的云账号下,创建RAM Role dataplaform_controlplane,该RAM Role可以允许ECS/ACK等云服务访问并扮演该RAM Role
c.在每个数据平面云账号下,创建RAM Role,该RAM Role可以允许控制平面的云账号_A_访问并扮演该RAM Role,同时授予该RAM RoleMaxCompute云资源的访问权限
d.控制平面下的ECS/ACK等云资源,可以通过扮演_dataplaform_controlplane_ RAM Role访问数据平面的RAM Role,并使用数据平面下的MaxCompute云资源
这样,基于上述的云产品能力和架构设计,我们在阿里云上实现了GoTerra 客户原来在GCP上类似的多租大数据平台架构。
下一步展望
我们实现了数据平面的多租,但控制平面GoTerra 客户是自建的一套大数据工具链链,对应的能力是我们DataWorks产品。很多集团类的企业客户并没有像GoTerra 这样的自建能力,他们期望使用DataWorks来一站式构建控制平面的能力。
DataWorks针对这样的场景,也需要多租方面做适配,如支持更灵活的数据源多租、数据分析跨租户元数据发现、数据开发支持数据源多租等,部分功能已经实现,部分功能也在规划中,如此DataWorks将在企业级多租能力上,再上一台阶。