
1. 引言
智能体(Agent)是一个使用大语言模型(LLM)来决定应用程序控制流程的系统。随着这些系统的开发,它们可能会变得越来越复杂,难以管理和扩展。例如,你可能会遇到以下问题:
- 智能体可用的工具过多,难以决定下一步调用哪个工具。
- 对于单个智能体来说,上下文变得过于复杂,难以跟踪。
- 系统中需要多个专业领域(例如,规划师、研究员、数学专家等)。
为了解决这些问题,你可能会考虑将应用程序分解为多个更小、独立的智能体,并将它们组合成一个多智能体系统。这些独立的智能体可以简单到一个提示词(prompt)加一次 LLM 调用,也可以复杂到一个 ReAct 智能体(甚至更复杂!)。
随着智能体框架的发展,许多公司开始构建自己的多智能体系统,并寻找能够解决所有智能体任务的"银弹"方案。两年前,研究人员设计了一个名为 ChatDev 的多智能体协作系统。ChatDev 是一个虚拟软件公司,通过拥有不同角色(如首席执行官、首席产品官、艺术设计师、程序员、评审员、测试员等,就像一个常规的软件工程公司一样)的各种智能体来运作。

所有这些智能体协同工作,相互交流,最终成功创建了一款视频游戏。在这一成就之后,许多人认为任何软件工程任务都可以使用这种多智能体架构来解决,即每个 AI 都有明确的角色分工。然而,现实世界的实验表明,并非所有问题都能用相同的架构解决。在某些情况下,更简单的架构可能提供更有效、更具成本效益的解决方案。
1.1 单智能体 vs. 多智能体架构
起初,单智能体方法(即一个 AI 智能体可以处理所有事情,从浏览器导航到文件操作)可能是合理的。然而,随着时间的推移,随着任务变得更加复杂和工具数量的增长,我们的单智能体方法将开始面临挑战。
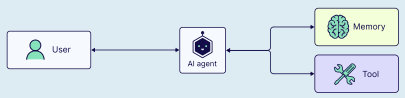
当智能体开始出现异常行为时,我们会注意到以下影响,其原因可能包括:
- 工具过多:智能体对使用哪些工具和/或何时使用感到困惑。
- 上下文过多:智能体越来越大的上下文窗口包含了过多的工具信息。
- 错误过多:由于职责过于宽泛,智能体开始产生次优或不正确的结果。
当我们开始自动化多个不同的子任务(如数据提取或报告生成)时,可能就到了分离职责的时候了。通过使用多个 AI 智能体,每个智能体专注于自己的领域和工具集,我们可以提高解决方案的清晰度和质量。这不仅使智能体变得更有效,而且也简化了智能体本身的开发。
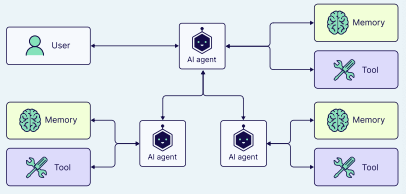
2. 多智能体架构
正如你所见,单智能体和多智能体架构都各有优缺点。当任务直接且定义明确,并且没有特定的资源限制时,单智能体架构是理想的选择。另一方面,当用例复杂且动态、需要更专业的知识和协作、或有可扩展性和适应性要求时,多智能体架构会很有帮助。
2.1 多智能体系统中的模式
在多智能体系统中,有多种连接智能体的方式:
2.1.1 并行 (Parallel)
多个智能体同时处理任务的不同部分。
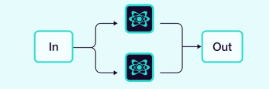
示例:我们希望使用 3 个智能体同时对给定文本进行摘要、翻译和情绪分析。
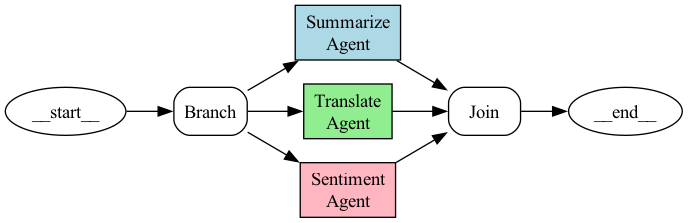
python
from typing import Dict, Any, TypedDict
from langgraph.graph import StateGraph, END
from langchain_core.runnables import RunnableConfig
from textblob import TextBlob
import re
import time
# Define the state
class AgentState(TypedDict):
text: str
summary: str
translation: str
sentiment: str
summary_time: float
translation_time: float
sentiment_time: float
# Summarization Agent
def summarize_agent(state: AgentState) -> Dict[str, Any]:
print("Summarization Agent: Running")
start_time = time.time()
try:
text = state["text"]
if not text.strip():
return {
"summary": "No text provided for summarization.",
"summary_time": 0.0
}
time.sleep(2)
sentences = re.split(r'(?<=[.!?]) +', text.strip())
scored_sentences = [(s, len(s.split())) for s in sentences if s]
top_sentences = [s for s, _ in sorted(scored_sentences, key=lambda x: x[1], reverse=True)[:2]]
summary = " ".join(top_sentences) if top_sentences else "Text too short to summarize."
processing_time = time.time() - start_time
print(f"Summarization Agent: Completed in {processing_time:.2f} seconds")
return {
"summary": summary,
"summary_time": processing_time
}
except Exception as e:
return {
"summary": f"Error in summarization: {str(e)}",
"summary_time": 0.0
}
# Translation Agent
def translate_agent(state: AgentState) -> Dict[str, Any]:
print("Translation Agent: Running")
start_time = time.time()
try:
text = state["text"]
if not text.strip():
return {
"translation": "No text provided for translation.",
"translation_time": 0.0
}
time.sleep(3)
translation = (
"El nuevo parque en la ciudad es una maravillosa adición. "
"Las familias disfrutan de los espacios abiertos, y a los niños les encanta el parque infantil. "
"Sin embargo, algunas personas piensan que el área de estacionamiento es demasiado pequeña."
)
processing_time = time.time() - start_time
print(f"Translation Agent: Completed in {processing_time:.2f} seconds")
return {
"translation": translation,
"translation_time": processing_time
}
except Exception as e:
return {
"translation": f"Error in translation: {str(e)}",
"translation_time": 0.0
}
# Sentiment Agent
def sentiment_agent(state: AgentState) -> Dict[str, Any]:
print("Sentiment Agent: Running")
start_time = time.time()
try:
text = state["text"]
if not text.strip():
return {
"sentiment": "No text provided for sentiment analysis.",
"sentiment_time": 0.0
}
time.sleep(1.5)
blob = TextBlob(text)
polarity = blob.sentiment.polarity
subjectivity = blob.sentiment.subjectivity
sentiment = "Positive" if polarity > 0 else "Negative" if polarity < 0 else "Neutral"
result = f"{sentiment} (Polarity: {polarity:.2f}, Subjectivity: {subjectivity:.2f})"
processing_time = time.time() - start_time
print(f"Sentiment Agent: Completed in {processing_time:.2f} seconds")
return {
"sentiment": result,
"sentiment_time": processing_time
}
except Exception as e:
return {
"sentiment": f"Error in sentiment analysis: {str(e)}",
"sentiment_time": 0.0
}
# Join Node
def join_parallel_results(state: AgentState) -> AgentState:
return state
# Build the Graph
def build_parallel_graph() -> StateGraph:
workflow = StateGraph(AgentState)
# Define parallel branches
parallel_branches = {
"summarize_node": summarize_agent,
"translate_node": translate_agent,
"sentiment_node": sentiment_agent
}
# Add parallel processing nodes
for name, agent in parallel_branches.items():
workflow.add_node(name, agent)
# Add branching and joining nodes
workflow.add_node("branch", lambda state: state) # Simplified branch function
workflow.add_node("join", join_parallel_results)
# Set entry point
workflow.set_entry_point("branch")
# Add edges for parallel execution
for name in parallel_branches:
workflow.add_edge("branch", name)
workflow.add_edge(name, "join")
workflow.add_edge("join", END)
return workflow.compile()
# Main function
def main():
text = (
"The new park in the city is a wonderful addition. Families are enjoying the open spaces, "
"and children love the playground. However, some people think the parking area is too small."
)
initial_state: AgentState = {
"text": text,
"summary": "",
"translation": "",
"sentiment": "",
"summary_time": 0.0,
"translation_time": 0.0,
"sentiment_time": 0.0
}
print("\\nBuilding new graph...")
app = build_parallel_graph()
print("\\nStarting parallel processing...")
start_time = time.time()
config = RunnableConfig(parallel=True)
result = app.invoke(initial_state, config=config)
total_time = time.time() - start_time
print("\\n=== Parallel Task Results ===")
print(f"Input Text:\\n{text}\\n")
print(f"Summary:\\n{result['summary']}\\n")
print(f"Translation (Spanish):\\n{result['translation']}\\n")
print(f"Sentiment Analysis:\\n{result['sentiment']}\\n")
print("\\n=== Processing Times ===")
processing_times = {
"summary": result["summary_time"],
"translation": result["translation_time"],
"sentiment": result["sentiment_time"]
}
for agent, time_taken in processing_times.items():
print(f"{agent.capitalize()}: {time_taken:.2f} seconds")
print(f"\\nTotal Wall Clock Time: {total_time:.2f} seconds")
print(f"Sum of Individual Processing Times: {sum(processing_times.values()):.2f} seconds")
print(f"Time Saved by Parallel Processing: {sum(processing_times.values()) - total_time:.2f} seconds")
if __name__ == "__main__":
main()输出:
Building new graph...
Starting parallel processing...
Sentiment Agent: Running
Summarization Agent: Running
Translation Agent: Running
Sentiment Agent: Completed in 1.50 seconds
Summarization Agent: Completed in 2.00 seconds
Translation Agent: Completed in 3.00 seconds
=== Parallel Task Results ===
Input Text:
The new park in the city is a wonderful addition. Families are enjoying the open spaces, and children love the playground. However, some people think the parking area is too small.
Summary:
Families are enjoying the open spaces, and children love the playground. The new park in the city is a wonderful addition.
Translation (Spanish):
El nuevo parque en la ciudad es una maravillosa adición. Las familias disfrutan de los espacios abiertos, y a los niños les encanta el parque infantil. Sin embargo, algunas personas piensan que el área de estacionamiento es demasiado pequeña.
Sentiment Analysis:
Positive (Polarity: 0.31, Subjectivity: 0.59)
=== Processing Times ===
Summary: 2.00 seconds
Translation: 3.00 seconds
Sentiment: 1.50 seconds
Total Wall Clock Time: 3.01 seconds
Sum of Individual Processing Times: 6.50 seconds
Time Saved by Parallel Processing: 3.50 seconds- 并行性:三个任务(摘要、翻译、情绪分析)同时运行,减少了总处理时间。
- 独立性:每个智能体独立地对输入文本进行操作,执行期间不需要智能体间通信。
- 协调:(代码中的)队列确保结果安全收集并按顺序显示。
- 现实用例:摘要、翻译和情绪分析是常见的 NLP 任务,尤其对于较长的文本,能从并行处理中受益。
2.1.2 顺序 (Sequential)
任务按顺序处理,一个智能体的输出成为下一个智能体的输入。
示例:多步审批流程。
python
from typing import Dict
from langgraph.graph import StateGraph, MessagesState, END
from langchain_core.runnables import RunnableConfig
from langchain_core.messages import HumanMessage, AIMessage
import json
# Agent 1: Team Lead
def team_lead_agent(state: MessagesState, config: RunnableConfig) -> Dict:
print("Agent (Team Lead): Starting review")
messages = state["messages"]
proposal = json.loads(messages[0].content)
title = proposal.get("title", "")
amount = proposal.get("amount", 0.0)
if not title or amount <= 0:
status = "Rejected"
comment = "Team Lead: Proposal rejected due to missing title or invalid amount."
goto = END
else:
status = "Approved by Team Lead"
comment = "Team Lead: Proposal is complete and approved."
goto = "dept_manager"
print(f"Agent (Team Lead): Review complete - {status}")
messages.append(AIMessage(
content=json.dumps({"status": status, "comment": comment}),
additional_kwargs={"agent": "team_lead", "goto": goto}
))
return {"messages": messages}
# Agent 2: Department Manager
def dept_manager_agent(state: MessagesState, config: RunnableConfig) -> Dict:
print("Agent (Department Manager): Starting review")
messages = state["messages"]
team_lead_msg = next((m for m in messages if m.additional_kwargs.get("agent") == "team_lead"), None)
proposal = json.loads(messages[0].content)
amount = proposal.get("amount", 0.0)
if json.loads(team_lead_msg.content)["status"] != "Approved by Team Lead":
status = "Rejected"
comment = "Department Manager: Skipped due to Team Lead rejection."
goto = END
elif amount > 100000:
status = "Rejected"
comment = "Department Manager: Budget exceeds limit."
goto = END
else:
status = "Approved by Department Manager"
comment = "Department Manager: Budget is within limits."
goto = "finance_director"
print(f"Agent (Department Manager): Review complete - {status}")
messages.append(AIMessage(
content=json.dumps({"status": status, "comment": comment}),
additional_kwargs={"agent": "dept_manager", "goto": goto}
))
return {"messages": messages}
# Agent 3: Finance Director
def finance_director_agent(state: MessagesState, config: RunnableConfig) -> Dict:
print("Agent (Finance Director): Starting review")
messages = state["messages"]
dept_msg = next((m for m in messages if m.additional_kwargs.get("agent") == "dept_manager"), None)
proposal = json.loads(messages[0].content)
amount = proposal.get("amount", 0.0)
if json.loads(dept_msg.content)["status"] != "Approved by Department Manager":
status = "Rejected"
comment = "Finance Director: Skipped due to Dept Manager rejection."
elif amount > 50000:
status = "Rejected"
comment = "Finance Director: Insufficient budget."
else:
status = "Approved"
comment = "Finance Director: Approved and feasible."
print(f"Agent (Finance Director): Review complete - {status}")
messages.append(AIMessage(
content=json.dumps({"status": status, "comment": comment}),
additional_kwargs={"agent": "finance_director", "goto": END}
))
return {"messages": messages}
# Routing function
def route_step(state: MessagesState) -> str:
for msg in reversed(state["messages"]):
goto = msg.additional_kwargs.get("goto")
if goto:
print(f"Routing: Agent {msg.additional_kwargs.get('agent')} set goto to {goto}")
return goto
return END
# Build LangGraph
builder = StateGraph(MessagesState)
builder.add_node("team_lead", team_lead_agent)
builder.add_node("dept_manager", dept_manager_agent)
builder.add_node("finance_director", finance_director_agent)
builder.set_entry_point("team_lead")
builder.add_conditional_edges("team_lead", route_step, {
"dept_manager": "dept_manager",
END: END
})
builder.add_conditional_edges("dept_manager", route_step, {
"finance_director": "finance_director",
END: END
})
builder.add_conditional_edges("finance_director", route_step, {
END: END
})
workflow = builder.compile()
# Main runner
def main():
initial_state = {
"messages": [
HumanMessage(
content=json.dumps({
"title": "New Equipment Purchase",
"amount": 40000.0,
"department": "Engineering"
})
)
]
}
result = workflow.invoke(initial_state)
messages = result["messages"]
proposal = json.loads(messages[0].content)
print("\\n=== Approval Results ===")
print(f"Proposal Title: {proposal['title']}")
final_status = "Unknown"
comments = []
for msg in messages[1:]:
if isinstance(msg, AIMessage):
try:
data = json.loads(msg.content)
if "status" in data:
final_status = data["status"]
if "comment" in data:
comments.append(data["comment"])
except Exception:
continue
print(f"Final Status: {final_status}")
print("Comments:")
for comment in comments:
print(f" - {comment}")
if __name__ == "__main__":
main()输出 (金额 = $40,000):
Agent (Team Lead): Starting review
Agent (Team Lead): Review complete - Approved by Team Lead
Routing: Agent team_lead set goto to dept_manager
Agent (Department Manager): Starting review
Agent (Department Manager): Review complete - Approved by Department Manager
Routing: Agent dept_manager set goto to finance_director
Agent (Finance Director): Starting review
Agent (Finance Director): Review complete - Approved
Routing: Agent finance_director set goto to __end__
=== Approval Results ===
Proposal Title: New Equipment Purchase
Final Status: Approved
Comments:
- Team Lead: Proposal is complete and approved.
- Department Manager: Budget is within limits.
- Finance Director: Approved and feasible.- 顺序执行 :
- 智能体按顺序运行:团队负责人 → 部门经理 → 财务总监。
- 如果任何智能体拒绝,循环中断,跳过剩余的智能体。
- 每个智能体修改共享的提案对象,更新状态和评论。
- 协调 :
- 结果存储在一个列表中,但提案对象在智能体之间传递状态。
- 未使用多处理,确保了单线程、有序的工作流。
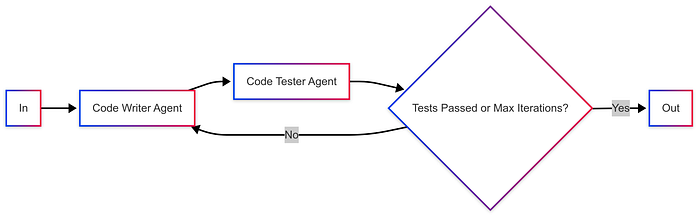
2.1.3 循环 (Loop)
智能体在迭代循环中运行,根据其他智能体的反馈不断改进其输出。
示例:评估用例,例如代码编写和代码测试。
python
from typing import Dict, Any, List
from langgraph.graph import StateGraph, END
from langchain_core.runnables import RunnableConfig
import textwrap
# State to track the workflow
class EvaluationState(Dict[str, Any]):
code: str = ""
feedback: str = ""
passed: bool = False
iteration: int = 0
max_iterations: int = 3
history: List[Dict] = []
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.setdefault("code", "")
self.setdefault("feedback", "")
self.setdefault("passed", False)
self.setdefault("iteration", 0)
self.setdefault("max_iterations", 3)
self.setdefault("history", [])
# Agent 1: Code Writer
def code_writer_agent(state: EvaluationState, config: RunnableConfig) -> Dict[str, Any]:
print(f"Iteration {state['iteration'] + 1} - Code Writer: Generating code")
print(f"Iteration {state['iteration'] + 1} - Code Writer: Received feedback: {state['feedback']}")
iteration = state["iteration"] + 1
feedback = state["feedback"]
if iteration == 1:
# Initial attempt: Basic factorial with bugs (no handling for zero or negatives)
code = textwrap.dedent("""
def factorial(n):
result = 1
for i in range(1, n + 1):
result *= i
return result
""")
writer_feedback = "Initial code generated."
elif "factorial(0)" in feedback.lower():
# Fix for zero case
code = textwrap.dedent("""
def factorial(n):
if n == 0:
return 1
result = 1
for i in range(1, n + 1):
result *= i
return result
""")
writer_feedback = "Fixed handling for n=0."
elif "factorial(-1)" in feedback.lower() or "negative" in feedback.lower():
# Fix for negative input
code = textwrap.dedent("""
def factorial(n):
if n < 0:
raise ValueError("Factorial not defined for negative numbers")
if n == 0:
return 1
result = 1
for i in range(1, n + 1):
result *= i
return result
""")
writer_feedback = "Added error handling for negative inputs."
else:
code = state["code"]
writer_feedback = "No further improvements identified."
print(f"Iteration {iteration} - Code Writer: Code generated")
return {
"code": code,
"feedback": writer_feedback,
"iteration": iteration
}
# Agent 2: Code Tester
def code_tester_agent(state: EvaluationState, config: RunnableConfig) -> Dict[str, Any]:
print(f"Iteration {state['iteration']} - Code Tester: Testing code")
code = state["code"]
try:
# Define test cases
test_cases = [
(0, 1), # factorial(0) = 1
(1, 1), # factorial(1) = 1
(5, 120), # factorial(5) = 120
(-1, None), # Should raise ValueError
]
# Execute code in a safe namespace
namespace = {}
exec(code, namespace)
factorial = namespace.get('factorial')
if not callable(factorial):
return {"passed": False, "feedback": "No factorial function found."}
feedback_parts = []
passed = True
# Run all test cases and collect all failures
for input_val, expected in test_cases:
try:
result = factorial(input_val)
if expected is None: # Expecting an error
passed = False
feedback_parts.append(f"Test failed: factorial({input_val}) should raise an error.")
elif result != expected:
passed = False
feedback_parts.append(f"Test failed: factorial({input_val}) returned {result}, expected {expected}.")
except ValueError as ve:
if expected is not None:
passed = False
feedback_parts.append(f"Test failed: factorial({input_val}) raised ValueError unexpectedly: {str(ve)}")
except Exception as e:
passed = False
feedback_parts.append(f"Test failed: factorial({input_val}) caused error: {str(e)}")
feedback = "All tests passed!" if passed else "\\n".join(feedback_parts)
print(f"Iteration {state['iteration']} - Code Tester: Testing complete - {'Passed' if passed else 'Failed'}")
# Log the attempt in history
history = state["history"]
history.append({
"iteration": state["iteration"],
"code": code,
"feedback": feedback,
"passed": passed
})
return {
"passed": passed,
"feedback": feedback,
"history": history
}
except Exception as e:
print(f"Iteration {state['iteration']} - Code Tester: Failed")
return {"passed": False, "feedback": f"Error in testing: {str(e)}"}
# Conditional edge to decide whether to loop or end
def should_continue(state: EvaluationState) -> str:
if state["passed"] or state["iteration"] >= state["max_iterations"]:
print(f"Iteration {state['iteration']} - {'Loop stops: Tests passed' if state['passed'] else 'Loop stops: Max iterations reached'}")
return "end"
print(f"Iteration {state['iteration']} - Loop continues: Tests failed")
return "code_writer"
# Build the LangGraph workflow
workflow = StateGraph(EvaluationState)
# Add nodes
workflow.add_node("code_writer", code_writer_agent)
workflow.add_node("code_tester", code_tester_agent)
# Add edges
workflow.set_entry_point("code_writer")
workflow.add_edge("code_writer", "code_tester")
workflow.add_conditional_edges(
"code_tester",
should_continue,
{
"code_writer": "code_writer",
"end": END
}
)
# Compile the graph
app = workflow.compile()
# Run the workflow
def main():
initial_state = EvaluationState()
result = app.invoke(initial_state)
# Display results
print("\\n=== Evaluation Results ===")
print(f"Final Status: {'Passed' if result['passed'] else 'Failed'} after {result['iteration']} iteration(s)")
print(f"Final Code:\\n{result['code']}")
print(f"Final Feedback:\\n{result['feedback']}")
print("\\nIteration History:")
for attempt in result["history"]:
print(f"Iteration {attempt['iteration']}:")
print(f" Code:\\n{attempt['code']}")
print(f" Feedback: {attempt['feedback']}")
print(f" Passed: {attempt['passed']}\\n")
if __name__ == "__main__":
main()输出:
Iteration 1 - Code Writer: Generating code
Iteration 1 - Code Writer: Received feedback:
Iteration 1 - Code Writer: Code generated
Iteration 1 - Code Tester: Testing code
Iteration 1 - Code Tester: Testing complete - Failed
Iteration 1 - Loop continues: Tests failed
Iteration 2 - Code Writer: Generating code
Iteration 2 - Code Writer: Received feedback: Test failed: factorial(-1) should raise an error.
Iteration 2 - Code Writer: Code generated
Iteration 2 - Code Tester: Testing code
Iteration 2 - Code Tester: Testing complete - Passed
Iteration 2 - Loop stops: Tests passed
=== Evaluation Results ===
Final Status: Passed after 2 iteration(s)
Final Code:
def factorial(n):
if n < 0:
raise ValueError("Factorial not defined for negative numbers")
if n == 0:
return 1
result = 1
for i in range(1, n + 1):
result *= i
return result
Final Feedback:
All tests passed!
Iteration History:
Iteration 1:
Code:
def factorial(n):
result = 1
for i in range(1, n + 1):
result *= i
return result
Feedback: Test failed: factorial(-1) should raise an error.
Passed: False
Iteration 2:
Code:
def factorial(n):
if n < 0:
raise ValueError("Factorial not defined for negative numbers")
if n == 0:
return 1
result = 1
for i in range(1, n + 1):
result *= i
return result
Feedback: All tests passed!
Passed: True- 全面反馈:代码测试器现在报告所有测试失败,确保代码编写器拥有逐步修复问题所需的信息。
- 正确的反馈处理:代码编写器优先处理修复(先处理零的情况,然后是负输入),确保持续改进。
- 循环终止:当测试通过时,循环正确退出,而不是不必要地运行所有 3 次迭代。
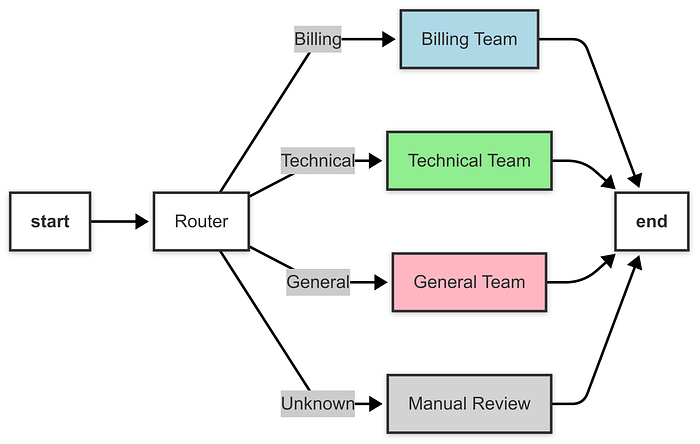
2.1.4 路由 (Router)
一个中央路由器根据任务或输入决定调用哪个(些)智能体。
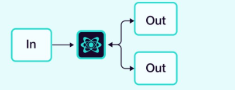
示例:客户支持工单路由。
python
from typing import Dict, Any, TypedDict, Literal
from langgraph.graph import StateGraph, END
from langchain_core.runnables import RunnableConfig
import re
import time
# Step 1: Define the State
# The state holds the ticket information and the processing results
class TicketState(TypedDict):
ticket_text: str # The content of the ticket
category: str # The determined category (Billing, Technical, General, or Unknown)
resolution: str # The resolution provided by the support team
processing_time: float # Time taken to process the ticket
# Step 2: Define the Router Agent
# This agent analyzes the ticket and determines its category
def router_agent(state: TicketState) -> Dict[str, Any]:
print("Router Agent: Analyzing ticket...")
start_time = time.time()
ticket_text = state["ticket_text"].lower()
# Simple keyword-based categorization (could be replaced with an LLM or ML model)
if any(keyword in ticket_text for keyword in ["billing", "payment", "invoice", "charge"]):
category = "Billing"
elif any(keyword in ticket_text for keyword in ["technical", "bug", "error", "crash"]):
category = "Technical"
elif any(keyword in ticket_text for keyword in ["general", "question", "inquiry", "info"]):
category = "General"
else:
category = "Unknown"
processing_time = time.time() - start_time
print(f"Router Agent: Categorized as '{category}' in {processing_time:.2f} seconds")
return {
"category": category,
"processing_time": processing_time
}
# Step 3: Define the Support Team Agents
# Each agent handles tickets for a specific category
# Billing Team Agent
def billing_team_agent(state: TicketState) -> Dict[str, Any]:
print("Billing Team Agent: Processing ticket...")
start_time = time.time()
ticket_text = state["ticket_text"]
resolution = f"Billing Team: Reviewed ticket '{ticket_text}'. Please check your invoice details or contact our billing department for further assistance."
processing_time = time.time() - start_time
time.sleep(1) # Simulate processing time
print(f"Billing Team Agent: Completed in {processing_time:.2f} seconds")
return {
"resolution": resolution,
"processing_time": state["processing_time"] + processing_time
}
# Technical Support Team Agent
def technical_team_agent(state: TicketState) -> Dict[str, Any]:
print("Technical Team Agent: Processing ticket...")
start_time = time.time()
ticket_text = state["ticket_text"]
resolution = f"Technical Team: Reviewed ticket '{ticket_text}'. Please try restarting your device or submit a detailed error log for further investigation."
processing_time = time.time() - start_time
time.sleep(1.5) # Simulate processing time
print(f"Technical Team Agent: Completed in {processing_time:.2f} seconds")
return {
"resolution": resolution,
"processing_time": state["processing_time"] + processing_time
}
# General Support Team Agent
def general_team_agent(state: TicketState) -> Dict[str, Any]:
print("General Team Agent: Processing ticket...")
start_time = time.time()
ticket_text = state["ticket_text"]
resolution = f"General Team: Reviewed ticket '{ticket_text}'. For more information, please refer to our FAQ or contact us via email."
processing_time = time.time() - start_time
time.sleep(0.8) # Simulate processing time
print(f"General Team Agent: Completed in {processing_time:.2f} seconds")
return {
"resolution": resolution,
"processing_time": state["processing_time"] + processing_time
}
# Manual Review Agent (for unknown categories)
def manual_review_agent(state: TicketState) -> Dict[str, Any]:
print("Manual Review Agent: Processing ticket...")
start_time = time.time()
ticket_text = state["ticket_text"]
resolution = f"Manual Review: Ticket '{ticket_text}' could not be categorized. Flagged for human review. Please assign to the appropriate team manually."
processing_time = time.time() - start_time
time.sleep(0.5) # Simulate processing time
print(f"Manual Review Agent: Completed in {processing_time:.2f} seconds")
return {
"resolution": resolution,
"processing_time": state["processing_time"] + processing_time
}
# Step 4: Define the Router Function
# This function determines the next node based on the ticket category
def route_ticket(state: TicketState) -> Literal["billing_team", "technical_team", "general_team", "manual_review"]:
category = state["category"]
print(f"Routing: Ticket category is '{category}'")
if category == "Billing":
return "billing_team"
elif category == "Technical":
return "technical_team"
elif category == "General":
return "general_team"
else:
return "manual_review"
# Step 5: Build the Graph with a Router Pattern
def build_router_graph() -> StateGraph:
workflow = StateGraph(TicketState)
# Add nodes
workflow.add_node("router", router_agent) # Entry point: Categorizes the ticket
workflow.add_node("billing_team", billing_team_agent) # Handles billing tickets
workflow.add_node("technical_team", technical_team_agent) # Handles technical tickets
workflow.add_node("general_team", general_team_agent) # Handles general inquiries
workflow.add_node("manual_review", manual_review_agent) # Handles uncategorized tickets
# Set the entry point
workflow.set_entry_point("router")
# Add conditional edges for routing
workflow.add_conditional_edges(
"router",
route_ticket, # Router function to determine the next node
{
"billing_team": "billing_team",
"technical_team": "technical_team",
"general_team": "general_team",
"manual_review": "manual_review"
}
)
# Add edges from each team to END
workflow.add_edge("billing_team", END)
workflow.add_edge("technical_team", END)
workflow.add_edge("general_team", END)
workflow.add_edge("manual_review", END)
return workflow.compile()
# Step 6: Run the Workflow
def main():
# Test cases for different ticket categories
test_tickets = [
"I have a billing issue with my last invoice. It seems I was overcharged.",
"My app keeps crashing with a technical error. Please help!",
"I have a general question about your services. Can you provide more info?",
"I need assistance with something unrelated to billing or technical issues."
]
for ticket_text in test_tickets:
# Initialize the state for each ticket
initial_state: TicketState = {
"ticket_text": ticket_text,
"category": "",
"resolution": "",
"processing_time": 0.0
}
print(f"\\n=== Processing Ticket: '{ticket_text}' ===")
app = build_router_graph()
start_time = time.time()
result = app.invoke(initial_state, config=RunnableConfig())
total_time = time.time() - start_time
print("\\n=== Ticket Results ===")
print(f"Category: {result['category']}")
print(f"Resolution: {result['resolution']}")
print(f"Total Processing Time: {result['processing_time']:.2f} seconds")
print(f"Total Wall Clock Time: {total_time:.2f} seconds")
print("-" * 50)
if __name__ == "__main__":
main()输出:
=== Processing Ticket: 'I have a billing issue with my last invoice. It seems I was overcharged.' ===
Router Agent: Analyzing ticket...
Router Agent: Categorized as 'Billing' in 0.00 seconds
Routing: Ticket category is 'Billing'
Billing Team Agent: Processing ticket...
Billing Team Agent: Completed in 0.00 seconds
=== Ticket Results ===
Category: Billing
Resolution: Billing Team: Reviewed ticket 'I have a billing issue with my last invoice. It seems I was overcharged.'. Please check your invoice details or contact our billing department for further assistance.
Total Processing Time: 0.00 seconds
Total Wall Clock Time: 1.03 seconds
--------------------------------------------------
=== Processing Ticket: 'My app keeps crashing with a technical error. Please help!' ===
Router Agent: Analyzing ticket...
Router Agent: Categorized as 'Technical' in 0.00 seconds
Routing: Ticket category is 'Technical'
Technical Team Agent: Processing ticket...
Technical Team Agent: Completed in 0.00 seconds
=== Ticket Results ===
Category: Technical
Resolution: Technical Team: Reviewed ticket 'My app keeps crashing with a technical error. Please help!'. Please try restarting your device or submit a detailed error log for further investigation.
Total Processing Time: 0.00 seconds
Total Wall Clock Time: 1.50 seconds
--------------------------------------------------
=== Processing Ticket: 'I have a general question about your services. Can you provide more info?' ===
Router Agent: Analyzing ticket...
Router Agent: Categorized as 'General' in 0.00 seconds
Routing: Ticket category is 'General'
General Team Agent: Processing ticket...
General Team Agent: Completed in 0.00 seconds
=== Ticket Results ===
Category: General
Resolution: General Team: Reviewed ticket 'I have a general question about your services. Can you provide more info?'. For more information, please refer to our FAQ or contact us via email.
Total Processing Time: 0.00 seconds
Total Wall Clock Time: 0.80 seconds
--------------------------------------------------
=== Processing Ticket: 'I need assistance with something unrelated to billing or technical issues.' ===
Router Agent: Analyzing ticket...
Router Agent: Categorized as 'Billing' in 0.00 seconds
Routing: Ticket category is 'Billing'
Billing Team Agent: Processing ticket...
Billing Team Agent: Completed in 0.00 seconds
=== Ticket Results ===
Category: Billing
Resolution: Billing Team: Reviewed ticket 'I need assistance with something unrelated to billing or technical issues.'. Please check your invoice details or contact our billing department for further assistance.
Total Processing Time: 0.00 seconds
Total Wall Clock Time: 1.00 seconds- 动态路由 :
router_agent确定工单类别,route_ticket函数使用add_conditional_edges将工作流引导到适当的节点。 - 基于条件的流程:与并行模式(多个节点并发运行)不同,路由模式根据条件(类别)仅执行一条路径。
- 可扩展性 :可以通过扩展节点并更新
route_ticket函数来处理新类别,从而添加更多的支持团队。
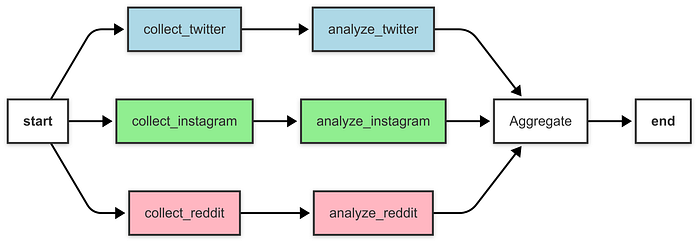
2.1.5 聚合器 (或合成器) (Aggregator/Synthesizer)
多个智能体贡献输出,由一个聚合器智能体收集并合成为最终结果。
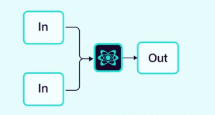
示例:社交媒体情感分析聚合器。
python
from typing import Dict, Any, TypedDict, List
from langgraph.graph import StateGraph, END
from langchain_core.runnables import RunnableConfig
from textblob import TextBlob
import time
from typing_extensions import Annotated
from operator import add
# Step 1: Define the State
class SocialMediaState(TypedDict):
twitter_posts: List[str]
instagram_posts: List[str]
reddit_posts: List[str]
twitter_sentiment: Dict[str, float]
instagram_sentiment: Dict[str, float]
reddit_sentiment: Dict[str, float]
final_report: str
processing_time: Annotated[float, add]
# Step 2: Define the Post Collection Agents
def collect_twitter_posts(state: SocialMediaState) -> Dict[str, Any]:
print("Twitter Agent: Collecting posts...")
start_time = time.time()
posts = [
"Loving the new product from this brand! Amazing quality.",
"Terrible customer service from this brand. Very disappointed."
]
time.sleep(1) # Simulate processing time
processing_time = time.time() - start_time # Include time.sleep in processing_time
print(f"Twitter Agent: Completed in {processing_time:.2f} seconds")
return {
"twitter_posts": posts,
"processing_time": processing_time
}
def collect_instagram_posts(state: SocialMediaState) -> Dict[str, Any]:
print("Instagram Agent: Collecting posts...")
start_time = time.time()
posts = [
"Beautiful design by this brand! #loveit",
"Not impressed with the latest release. Expected better."
]
time.sleep(1.2) # Simulate processing time
processing_time = time.time() - start_time
print(f"Instagram Agent: Completed in {processing_time:.2f} seconds")
return {
"instagram_posts": posts,
"processing_time": processing_time
}
def collect_reddit_posts(state: SocialMediaState) -> Dict[str, Any]:
print("Reddit Agent: Collecting posts...")
start_time = time.time()
posts = [
"This brand is awesome! Great value for money.",
"Had a bad experience with their support team. Not happy."
]
time.sleep(0.8) # Simulate processing time
processing_time = time.time() - start_time
print(f"Reddit Agent: Completed in {processing_time:.2f} seconds")
return {
"reddit_posts": posts,
"processing_time": processing_time
}
# Step 3: Define the Sentiment Analysis Agents
def analyze_twitter_sentiment(state: SocialMediaState) -> Dict[str, Any]:
print("Twitter Sentiment Agent: Analyzing sentiment...")
start_time = time.time()
posts = state["twitter_posts"]
polarities = [TextBlob(post).sentiment.polarity for post in posts]
avg_polarity = sum(polarities) / len(polarities) if polarities else 0.0
time.sleep(0.5) # Simulate processing time
processing_time = time.time() - start_time
print(f"Twitter Sentiment Agent: Completed in {processing_time:.2f} seconds")
return {
"twitter_sentiment": {"average_polarity": avg_polarity, "num_posts": len(posts)},
"processing_time": processing_time
}
def analyze_instagram_sentiment(state: SocialMediaState) -> Dict[str, Any]:
print("Instagram Sentiment Agent: Analyzing sentiment...")
start_time = time.time()
posts = state["instagram_posts"]
polarities = [TextBlob(post).sentiment.polarity for post in posts]
avg_polarity = sum(polarities) / len(polarities) if polarities else 0.0
time.sleep(0.6) # Simulate processing time
processing_time = time.time() - start_time
print(f"Instagram Sentiment Agent: Completed in {processing_time:.2f} seconds")
return {
"instagram_sentiment": {"average_polarity": avg_polarity, "num_posts": len(posts)},
"processing_time": processing_time
}
def analyze_reddit_sentiment(state: SocialMediaState) -> Dict[str, Any]:
print("Reddit Sentiment Agent: Analyzing sentiment...")
start_time = time.time()
posts = state["reddit_posts"]
polarities = [TextBlob(post).sentiment.polarity for post in posts]
avg_polarity = sum(polarities) / len(polarities) if polarities else 0.0
time.sleep(0.4) # Simulate processing time
processing_time = time.time() - start_time
print(f"Reddit Sentiment Agent: Completed in {processing_time:.2f} seconds")
return {
"reddit_sentiment": {"average_polarity": avg_polarity, "num_posts": len(posts)},
"processing_time": processing_time
}
# Step 4: Define the Aggregator Agent
def aggregate_results(state: SocialMediaState) -> Dict[str, Any]:
print("Aggregator Agent: Generating final report...")
start_time = time.time()
twitter_sentiment = state["twitter_sentiment"]
instagram_sentiment = state["instagram_sentiment"]
reddit_sentiment = state["reddit_sentiment"]
total_posts = (twitter_sentiment["num_posts"] +
instagram_sentiment["num_posts"] +
reddit_sentiment["num_posts"])
weighted_polarity = (
twitter_sentiment["average_polarity"] * twitter_sentiment["num_posts"] +
instagram_sentiment["average_polarity"] * instagram_sentiment["num_posts"] +
reddit_sentiment["average_polarity"] * reddit_sentiment["num_posts"]
) / total_posts if total_posts > 0 else 0.0
overall_sentiment = ("Positive" if weighted_polarity > 0 else
"Negative" if weighted_polarity < 0 else "Neutral")
report = (
f"Overall Sentiment: {overall_sentiment} (Average Polarity: {weighted_polarity:.2f})\\n"
f"Twitter Sentiment: {twitter_sentiment['average_polarity']:.2f} (Posts: {twitter_sentiment['num_posts']})\\n"
f"Instagram Sentiment: {instagram_sentiment['average_polarity']:.2f} (Posts: {instagram_sentiment['num_posts']})\\n"
f"Reddit Sentiment: {reddit_sentiment['average_polarity']:.2f} (Posts: {reddit_sentiment['num_posts']})"
)
time.sleep(0.3) # Simulate processing time
processing_time = time.time() - start_time
print(f"Aggregator Agent: Completed in {processing_time:.2f} seconds")
return {
"final_report": report,
"processing_time": processing_time
}
# Step 5: Build the Graph with an Aggregator Pattern
def build_aggregator_graph() -> StateGraph:
workflow = StateGraph(SocialMediaState)
# Add nodes for collecting posts
workflow.add_node("collect_twitter", collect_twitter_posts)
workflow.add_node("collect_instagram", collect_instagram_posts)
workflow.add_node("collect_reddit", collect_reddit_posts)
# Add nodes for sentiment analysis
workflow.add_node("analyze_twitter", analyze_twitter_sentiment)
workflow.add_node("analyze_instagram", analyze_instagram_sentiment)
workflow.add_node("analyze_reddit", analyze_reddit_sentiment)
# Add node for aggregation
workflow.add_node("aggregate", aggregate_results)
# Add a branching node to trigger all collection nodes in parallel
workflow.add_node("branch", lambda state: state)
# Set the entry point to the branch node
workflow.set_entry_point("branch")
# Add edges from branch to collection nodes (parallel execution)
workflow.add_edge("branch", "collect_twitter")
workflow.add_edge("branch", "collect_instagram")
workflow.add_edge("branch", "collect_reddit")
# Add edges from collection to sentiment analysis
workflow.add_edge("collect_twitter", "analyze_twitter")
workflow.add_edge("collect_instagram", "analyze_instagram")
workflow.add_edge("collect_reddit", "analyze_reddit")
# Add edges from sentiment analysis to aggregator
workflow.add_edge("analyze_twitter", "aggregate")
workflow.add_edge("analyze_instagram", "aggregate")
workflow.add_edge("analyze_reddit", "aggregate")
# Add edge from aggregator to END
workflow.add_edge("aggregate", END)
return workflow.compile()
# Step 6: Run the Workflow
def main():
initial_state: SocialMediaState = {
"twitter_posts": [],
"instagram_posts": [],
"reddit_posts": [],
"twitter_sentiment": {"average_polarity": 0.0, "num_posts": 0},
"instagram_sentiment": {"average_polarity": 0.0, "num_posts": 0},
"reddit_sentiment": {"average_polarity": 0.0, "num_posts": 0},
"final_report": "",
"processing_time": 0.0
}
print("\\nStarting social media sentiment analysis...")
app = build_aggregator_graph()
start_time = time.time()
config = RunnableConfig(parallel=True)
result = app.invoke(initial_state, config=config)
total_time = time.time() - start_time
print("\\n=== Sentiment Analysis Results ===")
print(result["final_report"])
print(f"\\nTotal Processing Time: {result['processing_time']:.2f} seconds")
print(f"Total Wall Clock Time: {total_time:.2f} seconds")
if __name__ == "__main__":
main()输出:
Starting social media sentiment analysis...
Instagram Agent: Collecting posts...
Reddit Agent: Collecting posts...
Twitter Agent: Collecting posts...
Reddit Agent: Completed in 0.80 seconds
Twitter Agent: Completed in 1.00 seconds
Instagram Agent: Completed in 1.20 seconds
Instagram Sentiment Agent: Analyzing sentiment...
Reddit Sentiment Agent: Analyzing sentiment...
Twitter Sentiment Agent: Analyzing sentiment...
Reddit Sentiment Agent: Completed in 0.40 seconds
Twitter Sentiment Agent: Completed in 0.50 seconds
Instagram Sentiment Agent: Completed in 0.60 seconds
Aggregator Agent: Generating final report...
Aggregator Agent: Completed in 0.30 seconds
=== Sentiment Analysis Results ===
Overall Sentiment: Positive (Average Polarity: 0.15)
Twitter Sentiment: -0.27 (Posts: 2)
Instagram Sentiment: 0.55 (Posts: 2)
Reddit Sentiment: 0.18 (Posts: 2)
Total Processing Time: 4.80 seconds
Total Wall Clock Time: 2.13 seconds- 并行执行:收集和分析节点并行运行,减少了总挂钟时间(2.13 秒),相比个体处理时间总和(3.8秒)。
- 聚合:聚合节点将情感结果合并成最终报告,计算总体情感并按平台提供细分。
2.1.6 网络 (或水平) (Network/Horizontal)
智能体以多对多的方式直接相互通信,形成一个去中心化的网络。
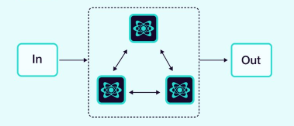
这种架构适用于没有明确的智能体层次结构或特定调用顺序的问题。
from typing import Literal
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, MessagesState, START, END
model = ChatOpenAI()
def agent_1(state: MessagesState) -> Command[Literal["agent_2", "agent_3", END]]:
# you can pass relevant parts of the state to the LLM (e.g., state["messages"])
# to determine which agent to call next. a common pattern is to call the model
# with a structured output (e.g. force it to return an output with a "next_agent" field)
response = model.invoke(...)
# route to one of the agents or exit based on the LLM's decision
# if the LLM returns "__end__", the graph will finish execution
return Command(
goto=response["next_agent"],
update={"messages": [response["content"]]},
)
def agent_2(state: MessagesState) -> Command[Literal["agent_1", "agent_3", END]]:
response = model.invoke(...)
return Command(
goto=response["next_agent"],
update={"messages": [response["content"]]},
)
def agent_3(state: MessagesState) -> Command[Literal["agent_1", "agent_2", END]]:
...
return Command(
goto=response["next_agent"],
update={"messages": [response["content"]]},
)
builder = StateGraph(MessagesState)
builder.add_node(agent_1)
builder.add_node(agent_2)
builder.add_node(agent_3)
builder.add_edge(START, "agent_1")
network = builder.compile()API 参考: ChatOpenAI | StateGraph | START | END
优点:分布式协作和群体驱动的决策。即使某些智能体出现故障,系统仍能保持功能。
缺点:管理智能体间的通信可能变得具有挑战性。更多的通信可能导致效率低下和智能体重复工作的可能性。
2.1.7 移交 (Handoffs)
在多智能体架构中,智能体可以表示为图节点。每个智能体节点执行其步骤,并决定是完成执行还是路由到另一个智能体,包括可能路由到自身(例如,在循环中运行)。多智能体交互中的一个常见模式是移交,即一个智能体将控制权移交给另一个智能体。移交允许你指定:
destination:要导航到的目标智能体(例如,要前往的节点名称)payload:传递给该智能体的信息(例如,状态更新)
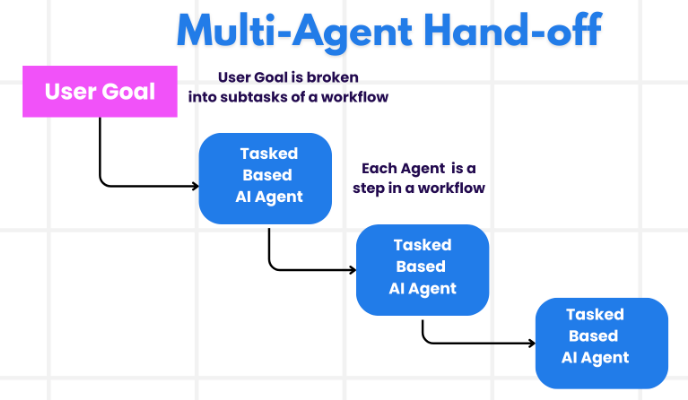
为了在 LangGraph 中实现移交,智能体节点可以返回 Command 对象,该对象允许你结合控制流和状态更新:
python
def agent(state) -> Command[Literal["agent", "another_agent"]]:
# the condition for routing/halting can be anything, e.g. LLM tool call / structured output, etc.
goto = get_next_agent(...) # 'agent' / 'another_agent'
return Command(
# Specify which agent to call next
goto=goto,
# Update the graph state
update={"my_state_key": "my_state_value"}
)在更复杂的场景中,每个智能体节点本身就是一个图(即子图),某个智能体子图中的节点可能希望导航到不同的智能体。例如,如果你有两个智能体 alice 和 bob (父图中的子图节点),并且 alice 需要导航到 bob ,你可以在 Command 对象中设置 graph=Command.PARENT:
python
def some_node_inside_alice(state)
return Command(
goto="bob",
update={"my_state_key": "my_state_value"},
# specify which graph to navigate to (defaults to the current graph)
graph=Command.PARENT,
)注意
如果需要支持使用 Command(graph=Command.PARENT) 进行通信的子图可视化,你需要将它们包装在一个带有 Command 注解的节点函数中。
python
def call_alice(state) -> Command[Literal["bob"]]:
return alice.invoke(state)
builder.add_node("alice", call_alice)作为工具的移交
最常见的智能体类型之一是 ReAct 风格的工具调用智能体。对于这类智能体,一个常见模式是将移交包装在一个工具调用中,例如:
python
def transfer_to_bob(state):
"""Transfer to bob."""
return Command(
goto="bob",
update={"my_state_key": "my_state_value"},
graph=Command.PARENT,
)这是从工具更新图状态的一种特殊情况,除了状态更新之外,还包括了控制流。
重要提示
如果你想使用返回 Command 的工具,你可以使用预构建的 create_react_agent / ToolNode 组件,或者实现你自己的工具执行节点,该节点收集工具返回的 Command 对象并返回它们的列表。
python
call_tools(state):
...
commands = [tools_by_name[tool_call["name"]].invoke(tool_call) for tool_call in tool_calls]
return commands2.1.8 监督者 (Supervisor)
在这种架构中,我们将智能体定义为节点,并添加一个监督者节点(LLM),由它决定接下来应该调用哪些智能体节点。我们使用 Command 根据监督者的决定将执行路由到相应的智能体节点。这种架构也适合于并行运行多个智能体或使用 Map-Reduce 模式。
python
from typing import Literal
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, MessagesState, START, END
model = ChatOpenAI()
def supervisor(state: MessagesState) -> Command[Literal["agent_1", "agent_2", END]]:
# you can pass relevant parts of the state to the LLM (e.g., state["messages"])
# to determine which agent to call next. a common pattern is to call the model
# with a structured output (e.g. force it to return an output with a "next_agent" field)
response = model.invoke(...)
# route to one of the agents or exit based on the supervisor's decision
# if the supervisor returns "__end__", the graph will finish execution
return Command(goto=response["next_agent"])
def agent_1(state: MessagesState) -> Command[Literal["supervisor"]]:
# you can pass relevant parts of the state to the LLM (e.g., state["messages"])
# and add any additional logic (different models, custom prompts, structured output, etc.)
response = model.invoke(...)
return Command(
goto="supervisor",
update={"messages": [response]},
)
def agent_2(state: MessagesState) -> Command[Literal["supervisor"]]:
response = model.invoke(...)
return Command(
goto="supervisor",
update={"messages": [response]},
)
builder = StateGraph(MessagesState)
builder.add_node(supervisor)
builder.add_node(agent_1)
builder.add_node(agent_2)
builder.add_edge(START, "supervisor")
supervisor = builder.compile()API 参考: ChatOpenAI | StateGraph | START | END
查看本教程以获取监督者多智能体架构的示例。
2.1.9 监督者(工具调用)(Supervisor - tool-calling)
在这种监督者架构的变体中,我们将单个智能体定义为工具,并在监督者节点中使用一个工具调用的 LLM。这可以实现为一个 ReAct 风格的智能体,包含两个节点------一个 LLM 节点(监督者)和一个执行工具(在此情况下是智能体)的工具调用节点。
python
from typing import Annotated
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import InjectedState, create_react_agent
model = ChatOpenAI()
# this is the agent function that will be called as tool
# notice that you can pass the state to the tool via InjectedState annotation
def agent_1(state: Annotated[dict, InjectedState]):
# you can pass relevant parts of the state to the LLM (e.g., state["messages"])
# and add any additional logic (different models, custom prompts, structured output, etc.)
response = model.invoke(...)
# return the LLM response as a string (expected tool response format)
# this will be automatically turned to ToolMessage
# by the prebuilt create_react_agent (supervisor)
return response.content
def agent_2(state: Annotated[dict, InjectedState]):
response = model.invoke(...)
return response.content
tools = [agent_1, agent_2]
# the simplest way to build a supervisor w/ tool-calling is to use prebuilt ReAct agent graph
# that consists of a tool-calling LLM node (i.e. supervisor) and a tool-executing node
supervisor = create_react_agent(model, tools)API 参考: ChatOpenAI | InjectedState | create_react_agent
2.1.10 分层(或垂直)(Hierarchical/Vertical)
智能体以树状结构组织,较高级别的智能体(监督者智能体)管理较低级别的智能体。
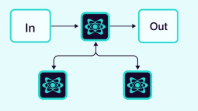
随着向系统中添加更多智能体,对监督者来说管理所有智能体可能变得过于困难。监督者可能开始做出关于下一步调用哪个智能体的糟糕决策,上下文可能变得过于复杂,以至于单个监督者无法跟踪。换句话说,你最终会遇到最初促使采用多智能体架构的相同问题。
为了解决这个问题,你可以分层设计你的系统。例如,你可以创建独立的、专业化的智能体团队,由各自的监督者管理,并有一个顶层的监督者来管理这些团队。
python
from typing import Literal
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, MessagesState, START, END
from langgraph.types import Command
model = ChatOpenAI()
# define team 1 (same as the single supervisor example above)
def team_1_supervisor(state: MessagesState) -> Command[Literal["team_1_agent_1", "team_1_agent_2", END]]:
response = model.invoke(...)
return Command(goto=response["next_agent"])
def team_1_agent_1(state: MessagesState) -> Command[Literal["team_1_supervisor"]]:
response = model.invoke(...)
return Command(goto="team_1_supervisor", update={"messages": [response]})
def team_1_agent_2(state: MessagesState) -> Command[Literal["team_1_supervisor"]]:
response = model.invoke(...)
return Command(goto="team_1_supervisor", update={"messages": [response]})
team_1_builder = StateGraph(Team1State)
team_1_builder.add_node(team_1_supervisor)
team_1_builder.add_node(team_1_agent_1)
team_1_builder.add_node(team_1_agent_2)
team_1_builder.add_edge(START, "team_1_supervisor")
team_1_graph = team_1_builder.compile()
# define team 2 (same as the single supervisor example above)
class Team2State(MessagesState):
next: Literal["team_2_agent_1", "team_2_agent_2", "__end__"]
def team_2_supervisor(state: Team2State):
...
def team_2_agent_1(state: Team2State):
...
def team_2_agent_2(state: Team2State):
...
team_2_builder = StateGraph(Team2State)
...
team_2_graph = team_2_builder.compile()
# define top-level supervisor
builder = StateGraph(MessagesState)
def top_level_supervisor(state: MessagesState) -> Command[Literal["team_1_graph", "team_2_graph", END]]:
# you can pass relevant parts of the state to the LLM (e.g., state["messages"])
# to determine which team to call next. a common pattern is to call the model
# with a structured output (e.g. force it to return an output with a "next_team" field)
response = model.invoke(...)
# route to one of the teams or exit based on the supervisor's decision
# if the supervisor returns "__end__", the graph will finish execution
return Command(goto=response["next_team"])
builder = StateGraph(MessagesState)
builder.add_node(top_level_supervisor)
builder.add_node("team_1_graph", team_1_graph)
builder.add_node("team_2_graph", team_2_graph)
builder.add_edge(START, "top_level_supervisor")
builder.add_edge("team_1_graph", "top_level_supervisor")
builder.add_edge("team_2_graph", "top_level_supervisor")
graph = builder.compile()优点:不同级别的智能体之间角色和职责分工明确。通信流程化。适用于具有结构化决策流程的大型系统。
缺点:上层故障会破坏整个系统。下层智能体的独立性有限。
API 参考: ChatOpenAI | StateGraph | START | END | Command
2.1.11 自定义多智能体工作流 (Custom multi-agent workflow)
每个智能体仅与一部分智能体通信。流程的某些部分是确定性的,只有部分智能体可以决定下一步调用哪些其他智能体。
在这种架构中,我们将单个智能体添加为图节点,并提前定义智能体的调用顺序,形成一个自定义工作流。在 LangGraph 中,工作流可以通过两种方式定义:
-
显式控制流(普通边):LangGraph 允许你通过普通的图边显式定义应用程序的控制流(即智能体通信的顺序)。
-
动态控制流(Command) :在 LangGraph 中,你可以允许 LLM 决定部分应用程序控制流。这可以通过使用
Command来实现。一个特殊情况是监督者工具调用架构。在这种情况下,驱动监督者智能体的工具调用 LLM 将决定工具(智能体)的调用顺序。pythonfrom langchain_openai import ChatOpenAI from langgraph.graph import StateGraph, MessagesState, START model = ChatOpenAI() def agent_1(state: MessagesState): response = model.invoke(...) return {"messages": [response]} def agent_2(state: MessagesState): response = model.invoke(...) return {"messages": [response]} builder = StateGraph(MessagesState) builder.add_node(agent_1) builder.add_node(agent_2) # define the flow explicitly builder.add_edge(START, "agent_1") builder.add_edge("agent_1", "agent_2")
API 参考: ChatOpenAI | StateGraph | START
3. 智能体间的通信
构建多智能体系统时,最重要的事情是弄清楚智能体之间如何通信。有几点不同的考虑:
- 智能体是通过图状态还是通过工具调用进行通信?
- 如果两个智能体有不同的状态模式(state schema)怎么办?
- 如何通过共享消息列表进行通信?
3.1 图状态 vs 工具调用
在智能体之间传递的"有效载荷"(payload)是什么?在上面讨论的大多数架构中,智能体通过图状态进行通信。在监督者工具调用的例子中,有效载荷是工具调用参数。
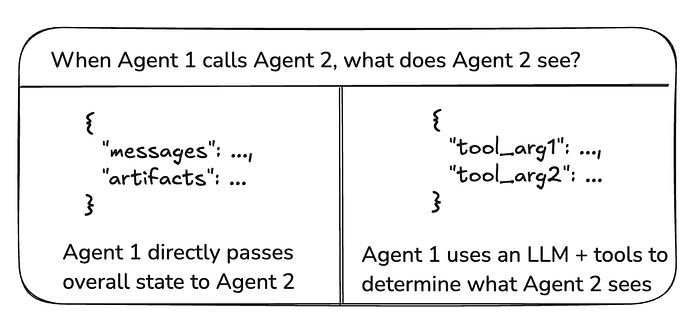
图状态
要通过图状态进行通信,单个智能体需要被定义为图节点。这些节点可以作为函数或整个子图添加。在图执行的每一步,智能体节点接收图的当前状态,执行智能体代码,然后将更新后的状态传递给下一个节点。
通常,智能体节点共享单一的状态模式。但是,你可能希望设计具有不同状态模式的智能体节点。
3.2 不同的状态模式
一个智能体可能需要具有与其他智能体不同的状态模式。例如,一个搜索智能体可能只需要跟踪查询和检索到的文档。在 LangGraph 中有两种方法可以实现这一点:
- 定义具有独立状态模式的子图智能体。如果子图和父图之间没有共享的状态键(通道),重要的是添加输入/输出转换,以便父图知道如何与子图通信。
- 定义具有私有输入状态模式的智能体节点函数,该模式与整体图状态模式不同。这允许传递仅执行该特定智能体所需的信息。
3.3 共享消息列表
智能体之间最常见的通信方式是通过共享的状态通道,通常是一个消息列表。这假设状态中至少有一个通道(键)是由智能体共享的。当通过共享消息列表进行通信时,还有一个额外的考虑:智能体是应该共享其思维过程的完整历史记录,还是只共享最终结果?
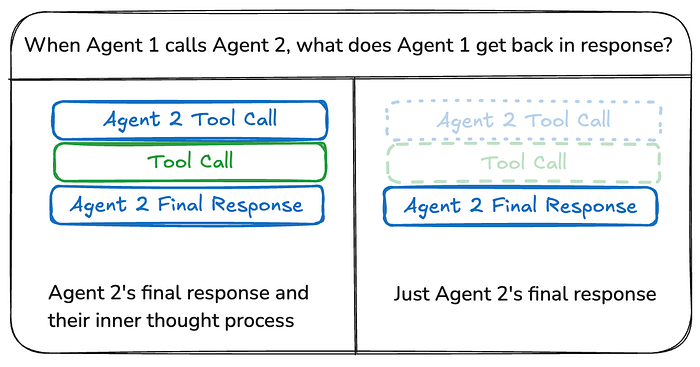
共享完整历史
智能体可以将其思维过程(即"草稿纸")的完整历史记录与所有其他智能体共享。这个"草稿纸"通常看起来像一个消息列表。共享完整思维过程的好处是,它可能帮助其他智能体做出更好的决策,并提高整个系统的推理能力。缺点是随着智能体数量及其复杂性的增长,"草稿纸"会迅速增长,可能需要额外的内存管理策略。
共享最终结果
智能体可以拥有自己的私有"草稿纸",只与其他智能体共享最终结果。这种方法可能对于拥有许多智能体或更复杂的智能体的系统更有效。在这种情况下,你需要定义具有不同状态模式的智能体。
对于作为工具调用的智能体,监督者根据工具模式(tool schema)确定输入。此外,LangGraph 允许在运行时将状态传递给单个工具,因此下属智能体可以在需要时访问父状态。
4. 结语
多智能体 LLM 系统通过利用并行、顺序、路由器和聚合器工作流等多种架构模式(如本篇博客所探讨的)为处理复杂任务提供了一个强大的范式。
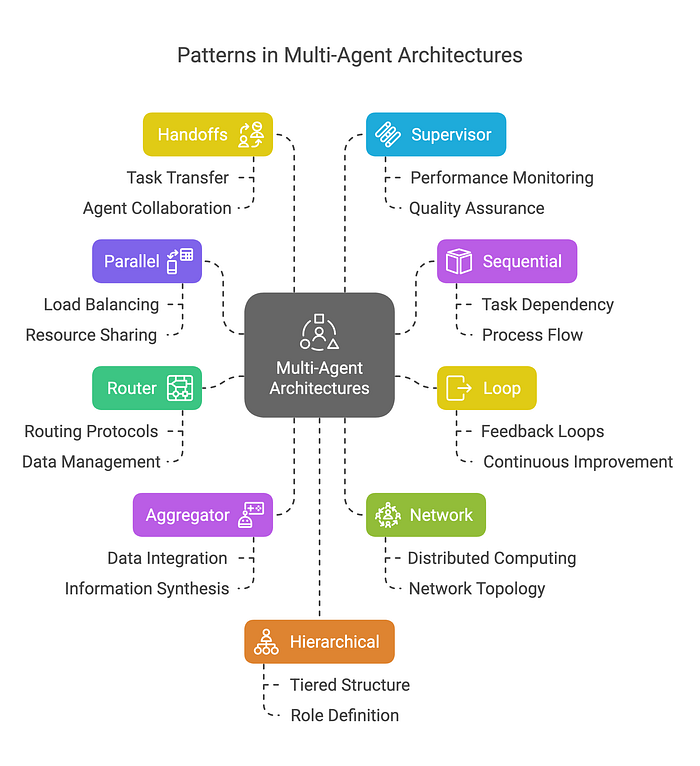
通过对共享状态、消息列表和工具调用等通信机制的详细检查,我们看到了智能体如何协作以实现无缝协调。