✨作者主页 :IT研究室✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
文章目录
一、前言
系统介绍:
该系统基于大数据技术(如Hadoop和Spark),结合Python/ava开发语言,实现了城市空气污染数据的分析和可视化。系统主要通过处理来自不同城市的空气质量数据(包括PM2.5、PM10、AQI等污染物浓度),对污染的时空分布、关联性、气象因素影响等多方面进行深入分析。用户可以通过前端界面查看城市间污染水平对比、污染物浓度的季节性和年际变化、工作日与周末污染差异等数据,帮助决策者制定更有效的污染控制策略。前端采用Vue、ElementUI、Echarts等技术,后端则通过Django/Spring Boot框架支持数据处理与接口调用,为用户提供高效、直观的数据分析工具。
选题背景:
近年来,城市空气污染问题日益严重,特别是在工业化、城市化进程加速的背景下,空气污染对环境、健康和社会造成了不可忽视的影响。特别是PM2.5、PM10等细颗粒物的浓度超标,已成为全球许多城市面临的主要环境问题。政府和环保组织纷纷加大了污染治理的力度,但仍面临着如何准确监测和评估空气质量、以及如何科学制定污染防控策略的问题。随着数据技术的进步,基于大数据的空气污染监测与分析成为了解决这一问题的有效途径。通过收集并处理大量的空气质量数据,能够更加精准地掌握污染现状、预测污染趋势,为制定环保政策提供数据支持。
选题意义:
本课题的研究意义体现在多个方面。首先,从科学研究角度,通过大数据技术对城市空气污染数据的分析,可以揭示污染物的时空分布特征,为理解污染源、评估污染治理效果提供了理论依据。其次,本系统的开发有助于提升污染物监测的自动化水平,解决了传统监测方法中数据处理能力不足、实时性差的问题,增强了数据分析的可操作性和准确性。此外,本系统还可以为政府部门提供基于数据的决策支持,帮助其更科学地安排污染防治工作。最后,系统可为环保机构和公众提供便捷的数据查询与可视化展示,提升社会公众对空气污染问题的关注度和环保意识。
二、开发环境
- 大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
- 开发语言:Python+Java(两个版本都支持)
- 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
- 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
- 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
- 数据库:MySQL
三、系统界面展示
- 基于大数据的城市空气污染数据分析系统界面展示:
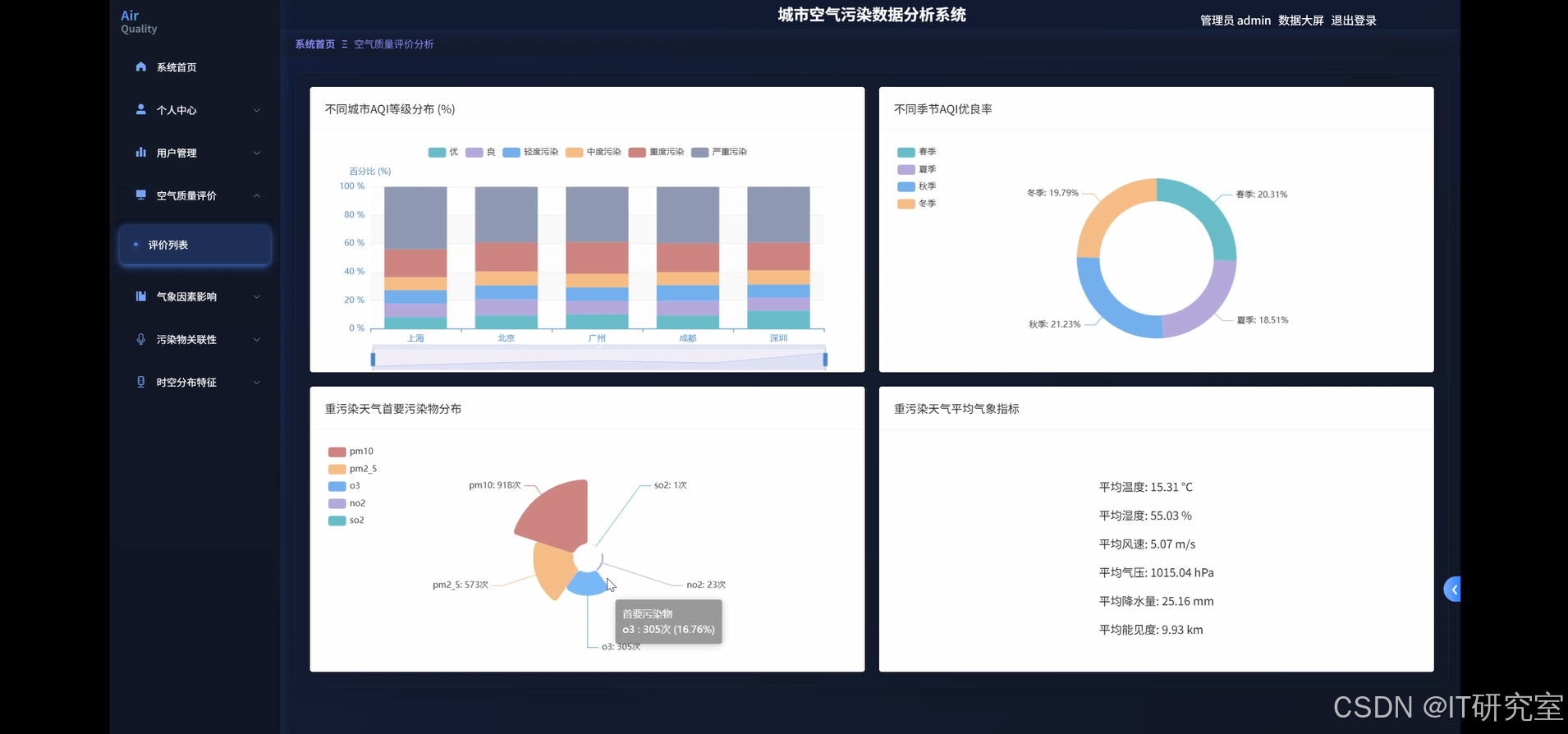
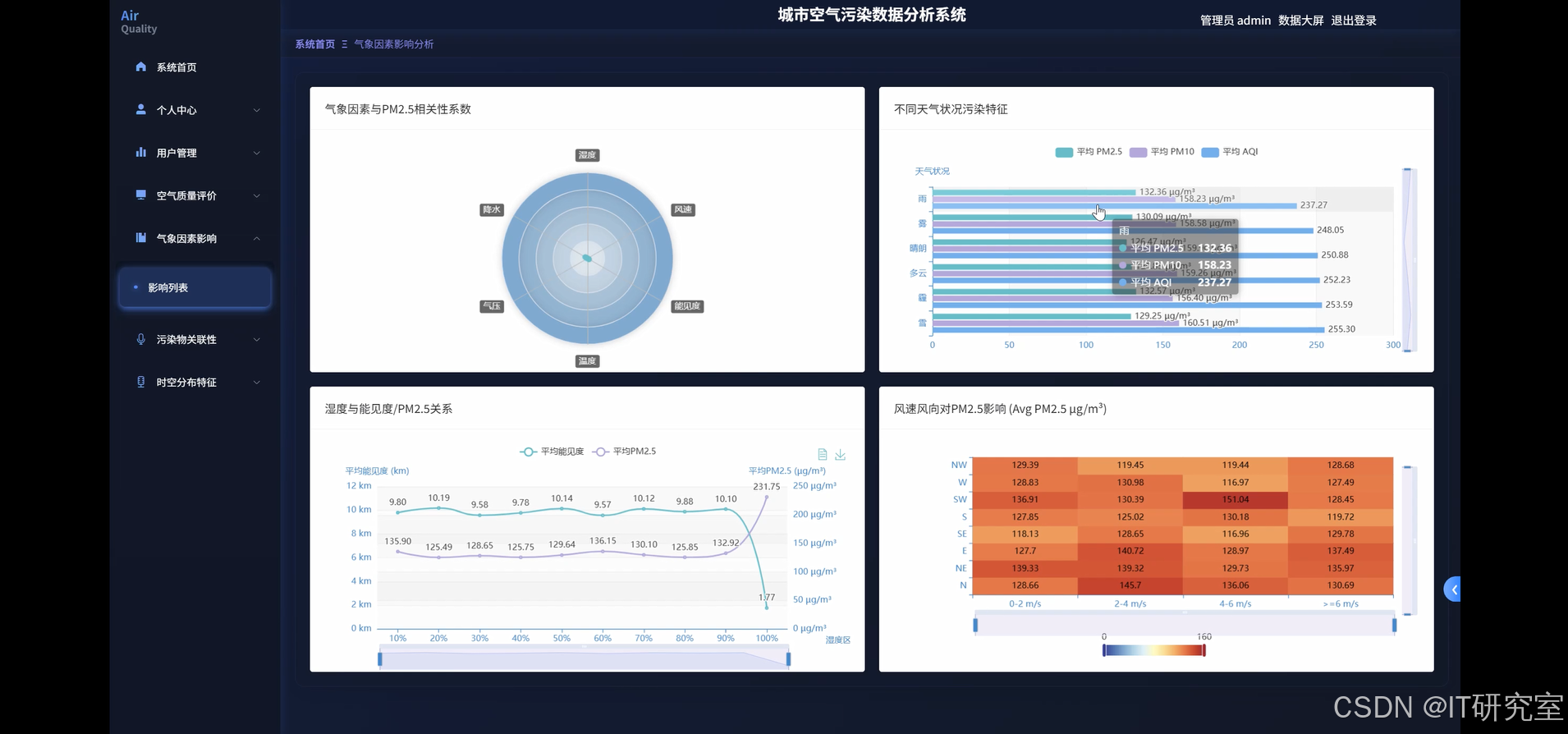
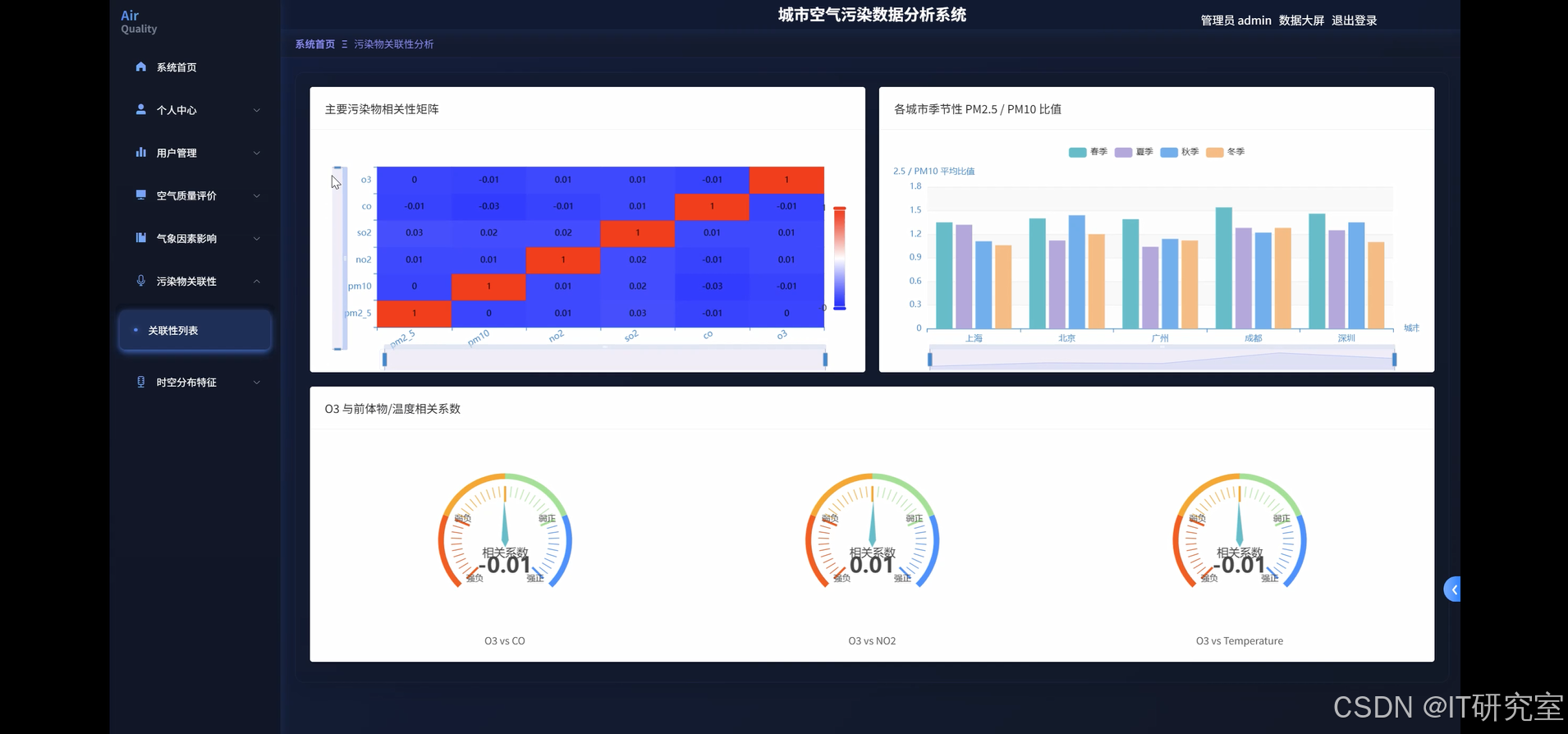
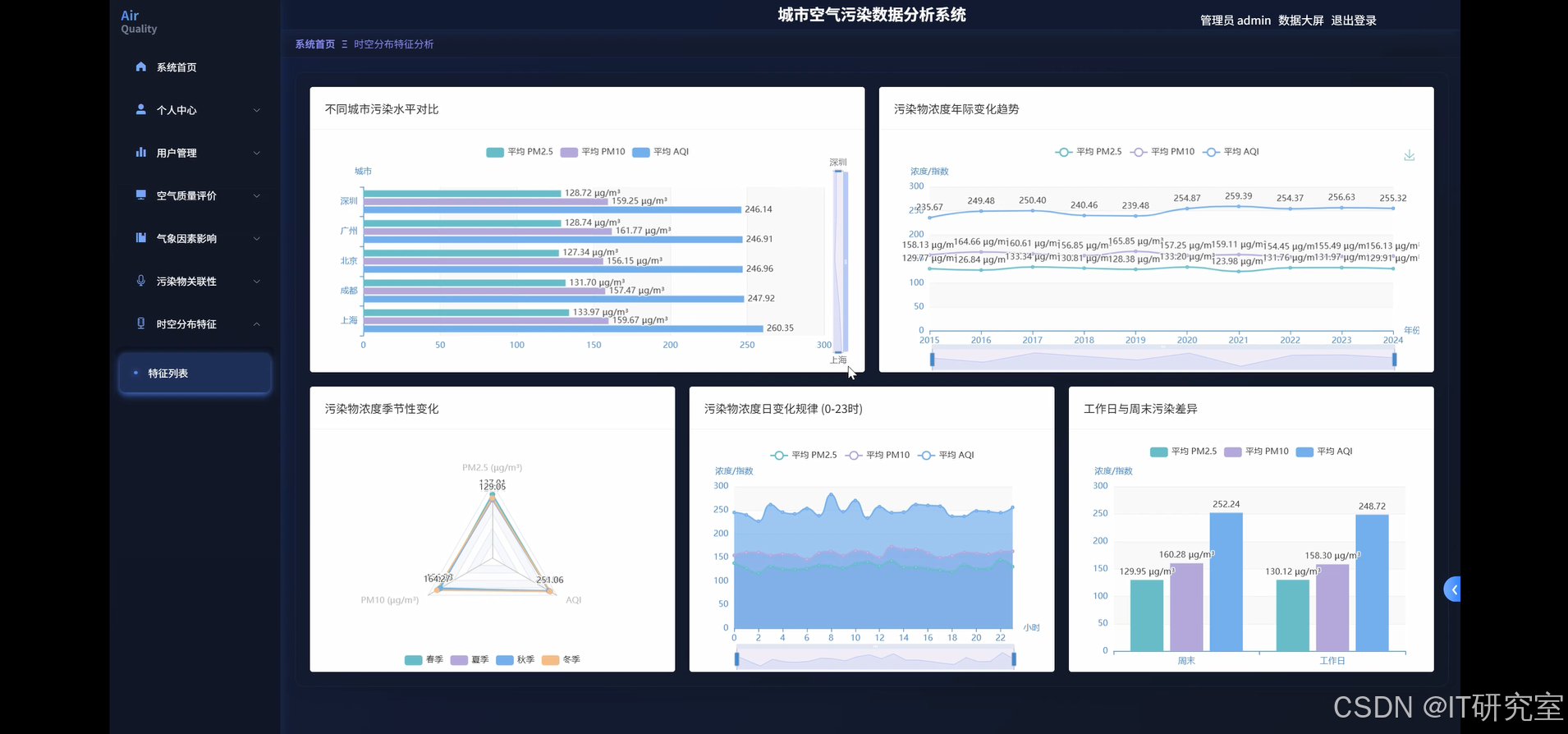
四、代码参考
- 项目实战代码参考:
java(贴上部分代码)
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, year, month, avg, corr
import pandas as pd
# 初始化Spark会话
spark = SparkSession.builder.appName("AirQualityAnalysis").getOrCreate()
# 1. 污染物时空分布特征分析:不同城市污染水平对比
def city_pollution_comparison():
data = spark.read.csv("city_air_quality_data.csv", header=True, inferSchema=True)
city_data = data.groupBy("City").agg(
avg("PM2.5").alias("avg_PM2.5"),
avg("PM10").alias("avg_PM10"),
avg("AQI").alias("avg_AQI"),
avg("NO2").alias("avg_NO2"),
avg("SO2").alias("avg_SO2"),
avg("CO").alias("avg_CO"),
avg("O3").alias("avg_O3")
)
city_data_pd = city_data.toPandas()
city_data_pd.to_csv("city_pollution_comparison.csv", index=False)
# 2. 污染物之间的相关性分析:计算污染物之间的相关性矩阵
def pollution_correlation_analysis():
data = spark.read.csv("city_air_quality_data.csv", header=True, inferSchema=True)
correlation_matrix = data.select("PM2.5", "PM10", "NO2", "SO2", "CO", "O3").toPandas().corr()
correlation_matrix.to_csv("pollution_correlation_matrix.csv", index=True)
# 3. 气象因素对PM2.5浓度的影响分析:温度、湿度、风速与PM2.5的相关性
def meteorological_impact_on_pm25():
data = spark.read.csv("city_air_quality_data.csv", header=True, inferSchema=True)
meteorological_data = data.select("PM2.5", "Temperature", "Humidity", "Wind Speed", "Pressure", "Precipitation", "Visibility")
correlation_results = meteorological_data.select(
corr("PM2.5", "Temperature").alias("corr_PM2.5_Temperature"),
corr("PM2.5", "Humidity").alias("corr_PM2.5_Humidity"),
corr("PM2.5", "Wind Speed").alias("corr_PM2.5_WindSpeed"),
corr("PM2.5", "Pressure").alias("corr_PM2.5_Pressure"),
corr("PM2.5", "Precipitation").alias("corr_PM2.5_Precipitation"),
corr("PM2.5", "Visibility").alias("corr_PM2.5_Visibility")
)
correlation_results.show()
# 4. 污染物浓度季节性变化分析:计算不同季节PM2.5浓度的变化趋势
def seasonal_pollution_analysis():
data = spark.read.csv("city_air_quality_data.csv", header=True, inferSchema=True)
data_with_season = data.withColumn("Season",
when(month("Date").isin([12, 1, 2]), "Winter")
.when(month("Date").isin([3, 4, 5]), "Spring")
.when(month("Date").isin([6, 7, 8]), "Summer")
.when(month("Date").isin([9, 10, 11]), "Fall")
.otherwise("Unknown"))
seasonal_data = data_with_season.groupBy("Season").agg(
avg("PM2.5").alias("avg_PM2.5"),
avg("PM10").alias("avg_PM10"),
avg("AQI").alias("avg_AQI")
)
seasonal_data_pd = seasonal_data.toPandas()
seasonal_data_pd.to_csv("seasonal_pollution_analysis.csv", index=False)五、系统视频
基于大数据的城市空气污染数据分析系统项目视频:
大数据毕业设计选题推荐-基于大数据的城市空气污染数据分析系统-Spark-Hadoop-Bigdata
结语
大数据毕业设计选题推荐-基于大数据的城市空气污染数据分析系统-Spark-Hadoop-Bigdata
想看其他类型的计算机毕业设计作品也可以和我说~ 谢谢大家!
有技术这一块问题大家可以评论区交流或者私我~
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:⬇⬇⬇