在虚拟试穿(VTON)领域,现有研究多聚焦于服装,这在一定程度上限制了其应用范围。浙江大学团队提出了一个统一框架 OmniTry,该框架将 VTON 的应用范畴拓展至服装之外的各类可穿戴物品,像珠宝、配饰等,还提供无蒙版设置以贴合实际应用场景。面对扩展物品类型时数据管理获取配对图像的难题,团队设计了独特的两阶段流程,巧妙利用大规模未配对图像和少量配对图像训练微调模型。经基于综合基准的评估,OmniTry 在物体定位和身份保存上表现卓越,且代码、模型权重和评估基准即将公开,有望推动该领域发展。

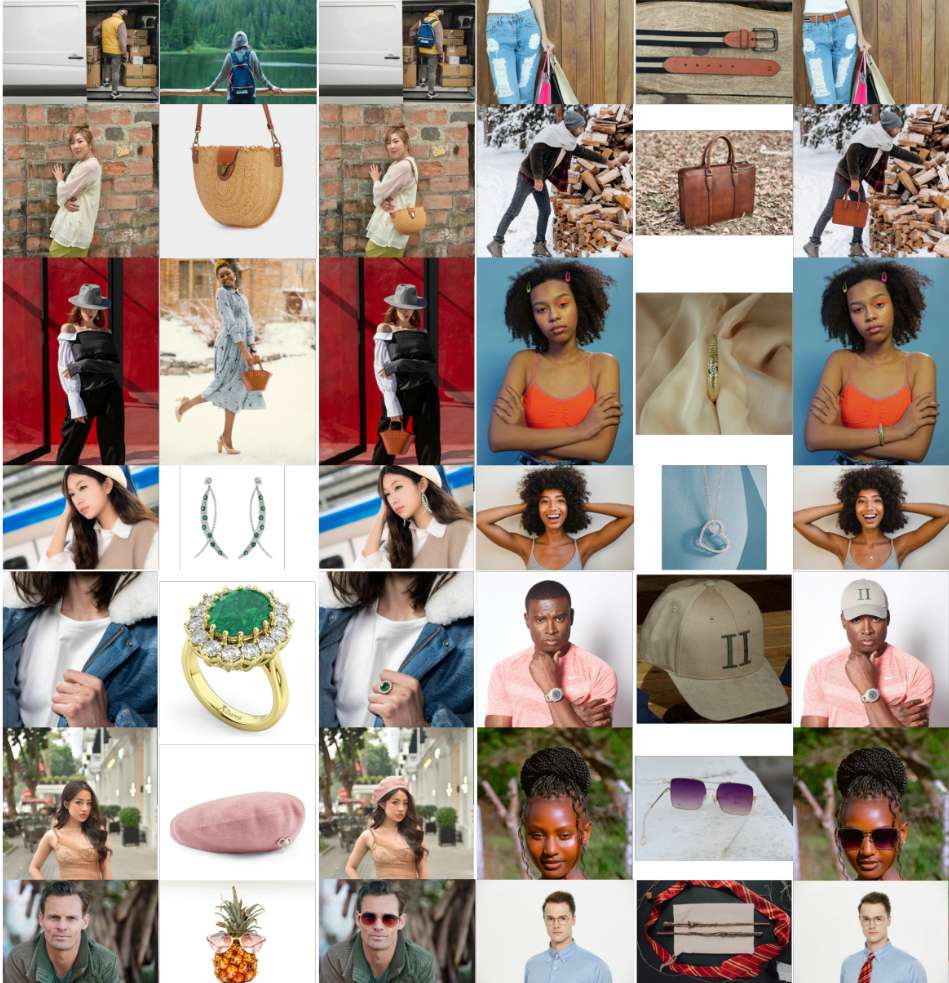
试穿结果
在包含 12 个主要可穿戴物品类别的 OmniTry-Bench 上进行评估的结果。
与现有方法的比较

将 OmniTry 扩展到不常见的类。

相关链接
论文介绍

虚拟试穿 (VTON) 是一项实用且应用广泛的任务,现有研究大多侧重于服装。本文提出了一个统一的框架 OmniTry,它将 VTON 的范围从服装扩展到任何可穿戴物品,例如珠宝和配饰,并提供无遮罩设置,以实现更实际的应用。当扩展到各种类型的物品时,获取配对图像(即物品图像和相应的试穿结果)的数据管理具有挑战性。
为了解决这个问题,论文提出了一个两阶段流程:
-
利用大规模未配对图像(即带有任何可穿戴物品的肖像)来训练模型进行无遮罩定位。论文重新设计了修复模型,使其能够在给定空遮罩的情况下自动将物品绘制到合适的位置。
-
使用配对图像进一步微调模型,以迁移物品外观的一致性。即使只有少量配对样本,第一阶段后的模型也能快速收敛。
OmniTry 的评估基于一个包含 12 类常见可穿戴物品的综合基准,其中包含店内和野外图像。实验结果表明,与现有方法相比,OmniTry 在物体定位和身份保存方面均表现出色。
方法概述
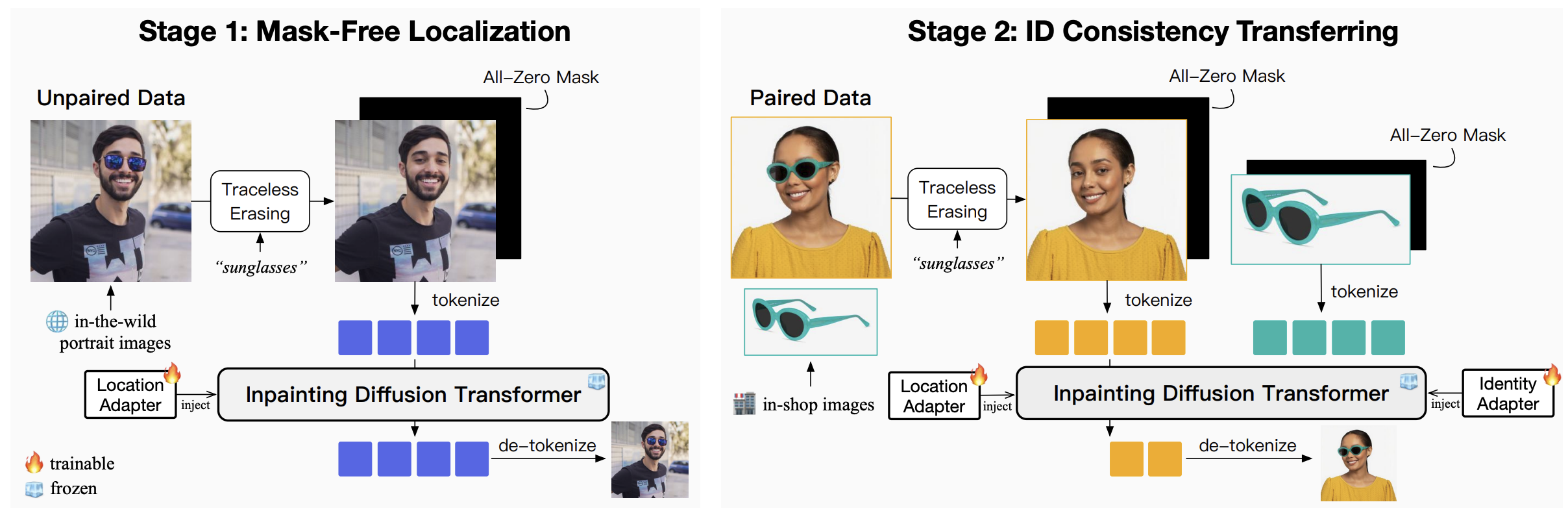
OmniTry 的两阶段训练流程。 第一阶段基于自然场景人像图像,以无口罩的方式将可穿戴物品添加到人物身上。第二阶段引入店内配对图像,旨在控制物体外观的一致性。
实验结果
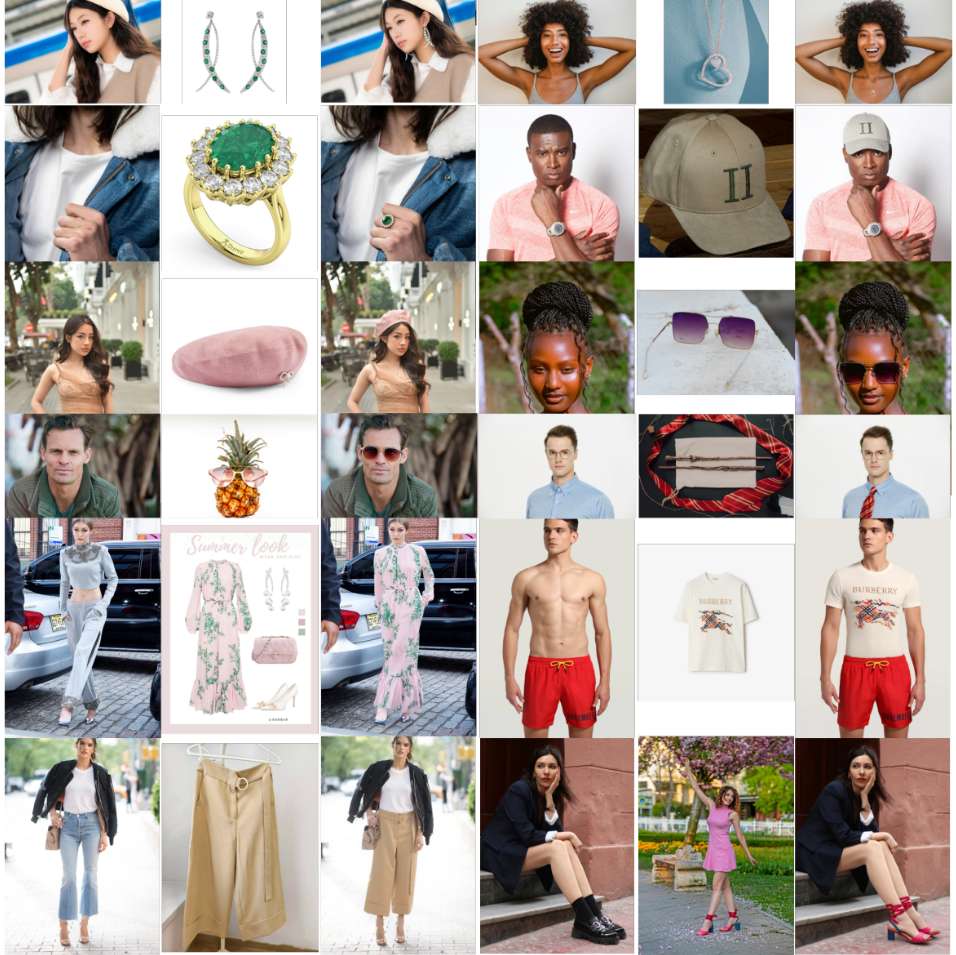

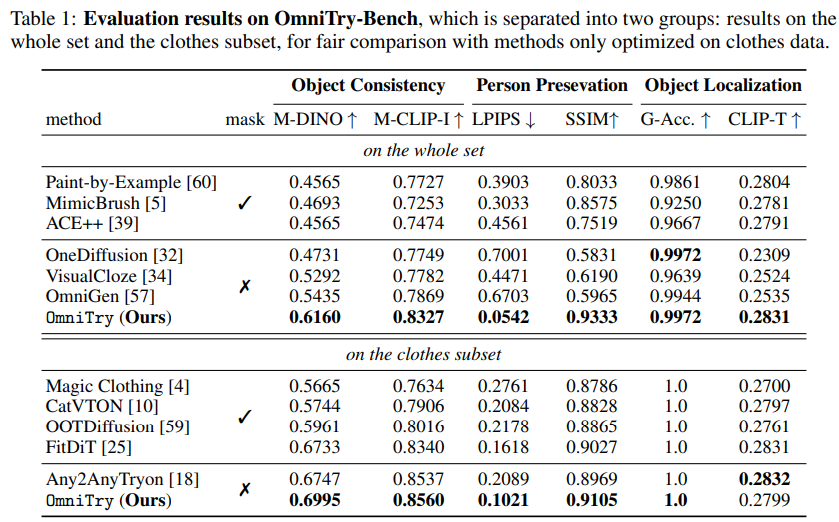
结论
OmniTry 是一个统一的无遮罩试穿框架,它将现有的服装试穿扩展至任何可穿戴物体。为了解决许多类型物体缺乏丰富的配对样本(即物体和试穿图像)的问题,在 OmniTry 中提出了一个两阶段训练流程。
-
第一阶段,利用大规模未配对图像来监督模型进行无遮罩物体定位。
-
第二阶段,则对模型进行训练以保持物体的一致性。
论文详细阐述了 OmniTry 的设计,包括用于避免捷径学习的无痕擦除、用于无遮罩生成的基于图像修复的重新利用策略以及用于身份迁移的带遮罩全注意力机制。提出了一个针对统一试穿的新基准,并证明了 OmniTry 与现有方法相比的有效性。大量的实验也验证了 OmniTry 即使使用少量配对图像进行训练也能实现高效的学习。