一、 前情回顾
1. 视觉处理三大任务
计算机视觉任务可主要分为以下三类:
-
图像分类(Image Classification) :
识别图像中主要物体或场景的类别,输出单一类别标签。通常假设图像中仅包含一个主导对象。
-
目标检测(Object Detection) :
识别图像中多个物体的类别,并为每个物体提供一个定位的边界框(Bounding Box)。适用于包含多个目标的复杂场景。
-
图像分割(Image Segmentation) :
将图像划分为多个区域,为像素级内容赋予语义信息。
- 语义分割(Semantic Segmentation):为图像中每个像素分配一个类别标签,不区分同一类别的不同实例。
- 实例分割(Instance Segmentation):在语义分割基础上,进一步区分属于同一类别的不同个体,为每个对象生成独立的分割掩码。
2. 模型生命周期:训练、验证、测试与推理
-
训练(Training) :
使用带有标注的训练数据集优化模型参数,使模型学习输入与输出之间的映射关系。
-
验证(Validation) :
在训练过程中或结束后,使用独立的验证集评估模型性能,用于超参数调优、早停(Early Stopping)等,防止过拟合。验证集需带标注。
-
测试(Testing) :
模型训练完成后,使用完全独立的测试集评估其最终性能,反映模型的泛化能力。测试集需带标注。
-
推理(Inference) :
将训练好的模型部署到实际应用中,对未标注的新数据进行预测。此阶段不涉及参数更新。
3. 模型性能问题:过拟合、欠拟合与鲁棒性
-
欠拟合(Underfitting) :
模型在训练集和测试集上均表现不佳,表明模型未能充分学习数据特征,通常由模型复杂度不足或训练不充分导致。
-
过拟合(Overfitting) :
模型在训练集上表现优异,但在测试集上性能显著下降,表明模型过度记忆训练数据中的噪声或特定模式,泛化能力差。
-
鲁棒性(Robustness) :
指系统在存在模型不确定性、参数扰动、外部干扰或环境变化(如输入噪声、光照变化、对抗攻击)的情况下,仍能保持其预定性能指标(如准确性、稳定性)的能力。高鲁棒性是模型可靠部署的关键。
4. 上游任务与下游任务
-
上游任务(Upstream Task) :
利用大规模无标注或弱标注数据进行预训练,学习通用的特征表示(如通过自监督学习训练基础模型),产出预训练模型(Pre-trained Model)。
-
下游任务(Downstream Task) :
基于预训练模型,通过微调(Fine-tuning)或迁移学习,针对特定应用场景(如医疗影像分类、工业缺陷检测)开发专用模型,实现技术落地。
5. 感受野(Receptive Field)
-
浅层卷积(Shallow Convolution) :
网络前几层的感受野较小,关注局部细节和空间结构信息,适合检测小尺寸物体。
-
深层卷积(Deep Convolution) :
网络后几层的感受野较大,捕获更广泛的上下文和高级语义信息,适合识别大尺寸物体或复杂场景。
现代目标检测模型(如YOLO系列)通过融合浅层与深层特征图,实现多尺度检测,提升对不同尺寸目标的检测能力。
二、目标检测基础
1、概念
目标检测(Object Detection)是计算机视觉中的一个重要领域,它涉及到识别图片或视频某一帧中的物体是什么类别,并确定它们的位置。通常用于多个物体的识别,可以同时处理图像中的多个实例,并为每个实例提供一个边界框和类别标签
主要挑战:
- 目标种类与数量:场景中可能包含多种类别的多个物体。
- 目标尺度问题:物体在图像中可能呈现极大或极小的尺寸。
- 环境干扰:光照变化、遮挡、背景杂乱等因素影响检测准确性。
2、标注
- 在目标检测任务中,标注主要涉及的是边界框(Bounding Box 标注,即为图像中的每一个需要检测的目标物体画出一个边界框,并给定 类别标签
- 在训练目标检测模型的时候,我们就需要先为数据集做标注
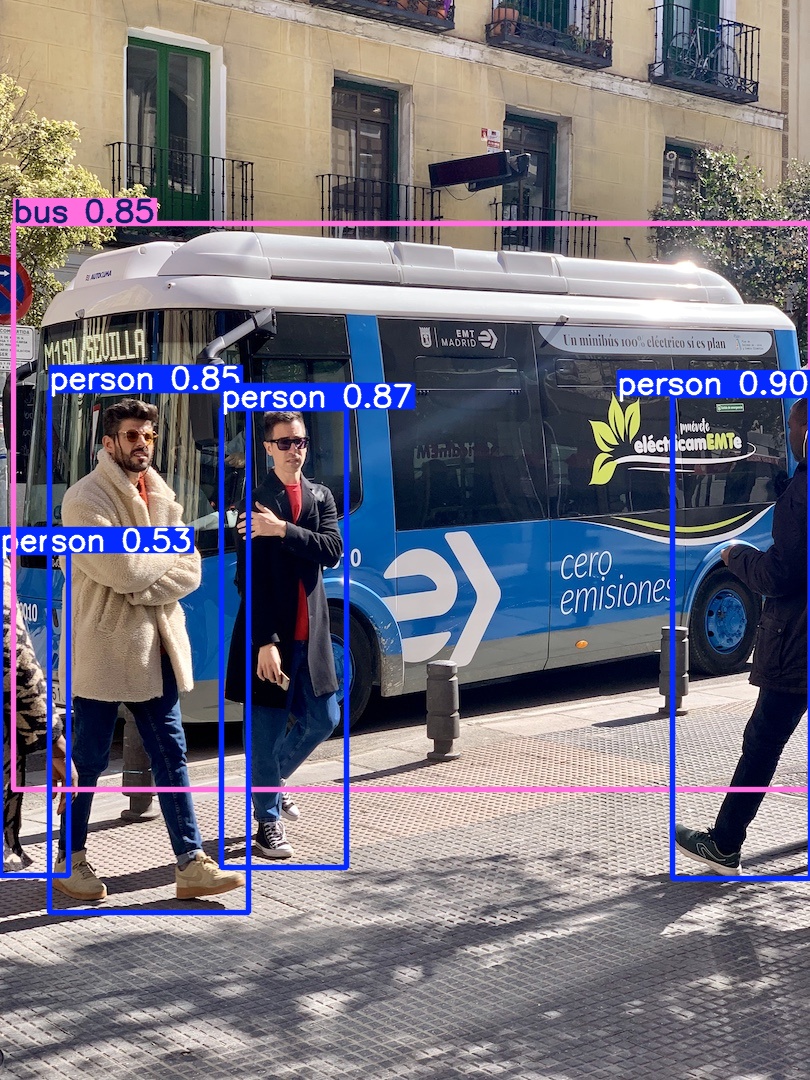
3.应用场景
目标检测技术广泛应用于多个领域:
- 自动驾驶:实时检测车辆、行人、交通信号灯、道路标志等。
- 安防监控:识别异常行为、入侵检测、人群密度分析。
- 人脸检测:定位图像或视频中的人脸区域。
- 医学影像分析:辅助识别肿瘤、病灶、器官等。
- 无人机应用:目标搜寻、线路巡检、农业监测。
- 工业缺陷检测:自动识别产品表面的划痕、裂纹等缺陷。
更多应用场景可参考:
4. 技术架构
根据检测流程的复杂度,主流目标检测方法可分为两大类:
| 特性 | 单阶段检测(One-stage Detection) | 两阶段检测(Two-stage Detection) |
|---|---|---|
| 主要算法 | YOLO系列、SSD、RetinaNet | R-CNN、Fast R-CNN、Faster R-CNN |
| 检测精度 | 较低(但随版本迭代持续提升) | 较高 |
| 检测速度 | 较快(可达实时或视频流级别) | 较慢 |
- 两阶段检测:首先生成候选区域(Region Proposals),然后对每个候选区域进行分类和回归。精度高但速度慢。
- 单阶段检测:直接在图像网格上进行密集预测,一步完成分类与定位。速度快,适合实时应用。
5. 评估指标
5.1 边界框(Bounding Box)
在目标检测 任务中,Bounding Box(边界框) 是用来定位图像中检测到的物体位置 的一个矩形框。每个检测出的物体都会被分配一个边界框,用来表示该物体在图像中的位置 和大小
边界框用于定位图像中检测到的物体,通常由以下信息构成:
- 类别标签(Class Label):物体的类别(如"猫"、"车")。
- 置信度分数(Confidence Score):模型对检测结果的置信程度(0~1)。
- 边界框坐标 :表示矩形框位置与大小,常见表示方式有:
(x_min, y_min, x_max, y_max):左上角与右下角坐标。(center_x, center_y, width, height):中心点坐标与宽高。
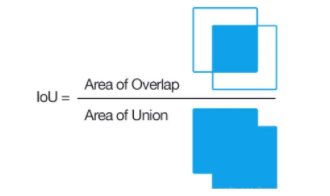
5.2 交并比
在目标检测 任务中,IoU(Intersection over Union,交并比)是一个非常关键的评估指标 ,用于衡量模型预测的边界框(Predicted Bounding Box)与真实边界框(Ground Truth Bounding Box)之间的重合程度
- IoU 的计算方式是两个边界框的交集面积 除以它们的并集面积,公式如下:
IoU=Area of OverlapArea of Union=A∩BA∪B IoU=\frac{Area\,of\,Overlap}{Area\,of\,Union}=\frac{A∩B}{A∪B} IoU=AreaofUnionAreaofOverlap=A∪BA∩B
其中 AAA 为预测框,BBB 为真实框。
- IoU 计算公式图形表示如下:
- IoU 值是介于 0,1 之间的,以下是对不同取值的一个说明:
| IoU 值 | 含义说明 |
|---|---|
| IoU = 0 | 两个框完全不重合,预测框与真实框没有任何交集 |
| 0 < IoU < 0.5 | 有一定重合,但重合度较低,预测效果一般 |
| 0.5 ≤ IoU < 1 | 重合度较高,预测框接近真实框,效果较好 |
| IoU = 1 | 完全重合,预测框与真实框完全一致,可能是理想情况或存在过拟合风险 |
5.3 置信度
置信度反映模型对检测结果的信心,通常由两部分组成(以YOLO为例):
Confidence=Pr(Object)×IoUpredtruth \text{Confidence} = \Pr(\text{Object}) \times \mathrm{IoU}_{\text{pred}}^{\text{truth}} Confidence=Pr(Object)×IoUpredtruth
-
Pr(Object)\Pr(\text{Object})Pr(Object):框内存在目标的概率。
-
IoUpredtruth\mathrm{IoU}_{\text{pred}}^{\text{truth}}IoUpredtruth:预测框与真实框的交并比(训练时已知,预测时由模型估计)。
预测的 IoU:不是真实计算出来的,而是模型自己"估计"的,表示它认为这个框和真实框有多接近
在深度学习的目标检测任务中,置信度是由网络的输出层(通常包括卷积层、池化层和全连接层等)共同作用的结果
在目标检测任务中,通常涉及到三种类型的置信度:目标存在置信度、类别置信度、综合置信度
| 类型 | 含义 |
|---|---|
| 目标存在置信度 | 表示当前预测框中存在目标物体的概率(不管是什么类别) |
| 类别置信度 | 表示当前框中的物体属于某个类别的概率(如"猫"、"狗"、"人"等) |
| 综合置信度 | 最终输出的置信度,等于目标存在置信度 × 类别置信度 |
总结:
| 阶段 | 置信度的计算方式 | 说明 |
|---|---|---|
| **训练阶段 ** | 使用真实框(Ground Truth)计算 IoU | 模型通过对比预测框与真实框,学习如何提升置信度 |
| 预测阶段 | 模型无法访问真实框,置信度完全由网络直接输出 | 通过设置置信度阈值(如 0.5)过滤低质量预测框,再通过 NMS 去除重复框 |
5.4 混淆矩阵
- 混淆矩阵是一种用于评估分类模型性能的表格形式,特别适用于监督学习中的分类任务。它通过将模型的预测结果与真实标签进行对比,帮助我们直观地理解模型在各个类别上的表现
- 在混淆矩阵中:
- 列(Columns) :表示真实类别(True Labels)
- 行(Rows) :表示预测类别(Predicted Labels)
- 单元格中的数值:表示在该真实类别与预测类别组合下的样本数量
- 在目标检测任务中,混淆矩阵的构建依赖于 IoU 阈值,因为 IoU 决定了哪些预测被认为是"正确检测",从而影响 TP、FP、FN 的统计,最终影响混淆矩阵的结构和数值
| 实际为正类 | 实际为负类 | |
|---|---|---|
| 预测为正类 | TP(真正例) | FP(假正例) |
| 预测为负类 | FN(假反例) | TN(真反例) |
在目标检测中的定义:
| 类型 | 定义 | 示例 |
|---|---|---|
| TP | 预测类别正确,且IoU ≥ 阈值 | 预测为"猫",IoU=0.85,真实为"猫" |
| FP | 1. 类别错误(IoU ≥ 阈值) 2. 类别正确但IoU < 阈值 | 预测为"猫"(实为"狗"),IoU=0.6;或预测为"猫",IoU=0.4 |
| FN | 真实存在目标,但未检测到 | 图中有猫,但模型未输出任何框 |
| TN | 背景区域被正确识别为"无目标" | 背景区域无预测框 |
5.5 精确度和召回率
- 精确度(Precision):在所有预测为正类的样本中,预测正确的比例,也称为查准率
- 召回率(Recall):在所有实际为正类的样本中,预测正确的比例,也称为查全率
- 准确度、精确度、召回率、F1 分数在机器学习中已经讲过,定义和公式如下图:

5.6 mAP
5.6.1 PR曲线
- PR 曲线,即精确率(Precision)- 召回率(Recall)曲线,是评估分类模型性能的重要工具之一,尤其是在类别不平衡问题中。它通过展示不同阈值下的精确率和召回率之间的关系,帮助我们理解模型在不同决策边界上的表现
- PR 曲线的生成过程:
- 对于每个样本,模型会输出一个预测分数或置信度,表示该样本属于某一类别的概率
- 设定多个置信度阈值:通常会设定一系列的置信度阈值,比如从 0 到 1,每隔 0.1 设置一个阈值,这些阈值将用于决定哪些预测被视为"正例"(Positive),哪些被视为"负例"(Negative)
- 对于每一个阈值,根据预测分数与该阈值的比较结果,我们可以计算出当前阈值下的精确率(Precision)和召回率(Recall)
- 将每个阈值下的精确率和召回率作为坐标点,绘制在二维平面上,横轴为召回率 ,纵轴为精确率,从而形成一条曲线
5.6.2 AP
- 在 PR 曲线中,曲线上每个点表示了在对应召回率下的最大精确率值。当 P=R 时成为平衡点(BEP),如果这个值较大,则说明学习器的性能较好。所以 PR 曲线越靠近右上角性能越好。即 PR 曲线的面积越大,表示分类模型在精确率和召回率之间有更好的权衡,性能越好
- 常用的评估指标是 PR 曲线下的面积,即 AP(Average Precision),通过 PR 曲线下的面积来计算 AP,从而综合评估模型在不同置信度阈值下的性能,值越接近 1 越好
- 平均精度(Average Precision, AP)通过计算每个类别在不同置信度阈值下的 Precision(查准率)和 Recall(查全率)的平均值来综合评估模型的性能。AP 被广泛应用于评估模型在不同置信度阈值下的表现,并且是计算 mAP(平均平均精度)的基础
- AP 就是用来衡量一个训练好的模型在识别某个类别时的表现好坏。AP 越高,说明模型在这个类别上的识别能力越强
5.6.3 mAP
平均平均精度(mean Average Precision,mAP) 是在不同置信度阈值下计算的平均精确度(Average Precision, AP)的平均值AP 是在不同召回率水平下的精确度平均值,而 mAP 是所有类别AP的平均值,反映模型在所有类别上的综合性能。
mAP=1N∑i=1NAPi \mathrm{mAP} = \frac{1}{N} \sum_{i=1}^{N} \mathrm{AP}_i mAP=N1i=1∑NAPi
其中 NNN 为类别总数。
| 名称 | 含义 | 说明 |
|---|---|---|
| AP(Average Precision) | 衡量模型在某一类别上的检测或分类性能 | 通过 Precision-Recall 曲线下的面积来计算,值越高表示模型在该类别上的性能越好 |
| mAP(mean Average Precision) | 模型在所有类别上的 AP 的平均值 | 衡量模型整体性能的综合指标,值越高表示模型在所有类别上的平均表现越好 |
- mAP 计算步骤:
- 计算每个类别的 AP:对于数据集中包含的每个类别,分别计算 AP
- 计算 mAP:将所有类别的 AP 取平均值,得到 mAP
6. NMS 后处理技术
非极大值抑制(Non-Maximum Suppression,NMS) 是目标检测任务中常用的后处理技术 ,用于去除冗余的边界框(Bounding Boxes) ,保留最有可能的检测结果
目的:解决同一目标被多次检测的问题,保留最可靠的预测框。
核心思想:对每个类别,按置信度排序,保留高置信度框,并抑制与其高度重叠的低置信度框。
算法步骤:
- 设定置信度阈值(如0.5),过滤低置信度预测框。
- 对剩余框按置信度从高到低排序。
- 选取置信度最高的框加入输出列表,并从候选框中移除。
- 计算当前框与输出列表中每个框的IoU。
- 若IoU > 预设阈值(如0.5),则抑制(丢弃)当前框。
- 重复步骤3-5,直至所有框处理完毕。
NMS确保了每个目标最终只有一个高质量的检测结果,显著提升了检测的清晰度与准确性。
结语
本文系统梳理了目标检测领域的核心概念与关键技术,从前情回顾到具体指标,构建了完整的知识框架。理解这些基础内容是深入学习YOLO、Faster R-CNN等先进检测模型的前提。随着技术发展,目标检测在精度、速度与鲁棒性方面持续进步,正不断推动人工智能在现实世界中的广泛应用。