没有Kafka怎么办?Flink SQL 创建 mysql-cdc 作业

前言
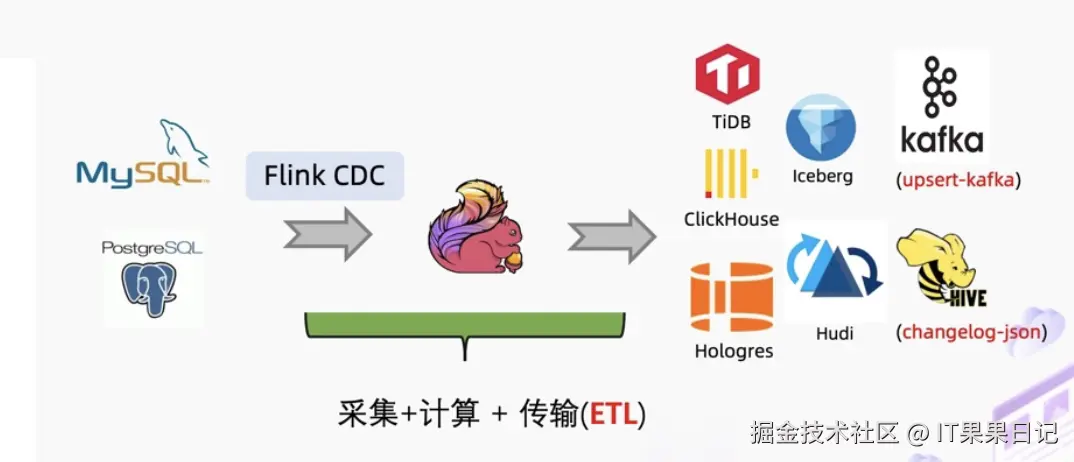
在大数据与实时计算的浪潮中,如何高效、低延迟地捕获和处理业务数据库的变更日志,已成为构建流式数据管道的关键。MySQL-CDC(Change Data Capture)技术正是为此而生,它能够实时监听MySQL数据库的二进制日志(Binlog),精准捕捉数据的插入、更新和删除等变更事件,并将这些事件作为连续不断的流推送到下游处理系统,为实时数仓、数据同步和流式分析提供了源头活水。
与传统依赖定时查询的JDBC连接方式相比,MySQL-CDC带来了一场范式革命。JDBC作业通常以固定的时间间隔轮询拉取数据,无法感知中间的变化,既存在显著的延迟,也可能因频繁查询而对源库造成压力。而CDC则是基于事件的、真正的流式处理,它毫秒级地响应变化,保证了数据的端到端实时性,并且减少了对源库的侵入性。
因此,借助Flink SQL创建MySQL-CDC作业,开发者可以轻松地将数据库变更流与Kafka、Hudi、Iceberg等数据湖仓无缝集成,广泛应用于实时数仓ETL、物化视图更新、微服务间缓存同步、审计以及在线机器学习特征更新等核心场景,是实现"流批一体"架构不可或缺的利器。
添加依赖
下载后将flink-sql-connector-mysql-cdc-2.4.0.jar包拷贝到 $FLINK_HOME/lib 和 $DINKY_HOME/extends/flink1.17/ 目录下
bash
# mysql-cdc连接器,注意版本兼容性
wget https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mysql-cdc/2.4.0/flink-sql-connector-mysql-cdc-2.4.0.jarFlink SQL代码
配置为mysql-cdc连接器的源表
sql
CREATE TABLE users
(
`id` BIGINT NOT NULL COMMENT '主键id',
`user_name` STRING COMMENT '姓名',
`sex` STRING COMMENT '性别',
`age` BIGINT COMMENT '年龄',
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'xxx.xxx.xxx.xxx',
'port' = 'xxxx',
'username' = 'xxxx',
'password' = 'xxxx',
'database-name' = 'xxxx',
'table-name' = 'users',
'server-time-zone' = 'Asia/Shanghai',
'scan.startup.mode' = 'initial', -- 先做全量快照,然后从binlog最新位置开始读取(默认)
-- 'scan.startup.mode' = 'earliest-offset', -- 直接跳过快照,从binlog最早位置开始读取。
-- 'scan.startup.mode' = 'latest-offset',
'debezium.skipped.operations' = 'd,t' -- 跳过删除/truncate操作
);'scan.startup.mode' = 'initial'第一次会做全量读取,后续做增量读取;'debezium.skipped.operations' = 'd,t'表示源表即使做了delete或者truncate操作,目标表也不会同步执行,这是为了防止源表删库跑路牵连到了目标表;
配置为jdbc连接器的目标表
sql
CREATE TABLE users2
(
`id` BIGINT NOT NULL COMMENT '主键id',
`user_name` STRING COMMENT '姓名',
`sex` STRING COMMENT '性别',
`age` BIGINT COMMENT '年龄',
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'table-name' = 'users2',
'url' = 'jdbc:mysql://x.x.x.x:3306/xxxx?useSSL=false&serverTimezone=UTC',
'username' = 'xxxx',
'password' = 'xxxx',
'sink.buffer-flush.max-rows' = '100', -- 根据性能调整,小批量写入
'sink.buffer-flush.interval' = '5s', -- 根据性能调整,控制写入延迟
-- 'sink.parallelism' = '4', -- 增加写入并发
'sink.max-retries' = '3' -- 写入失败重试
);最后sink语句
sql
insert into user2
select * from users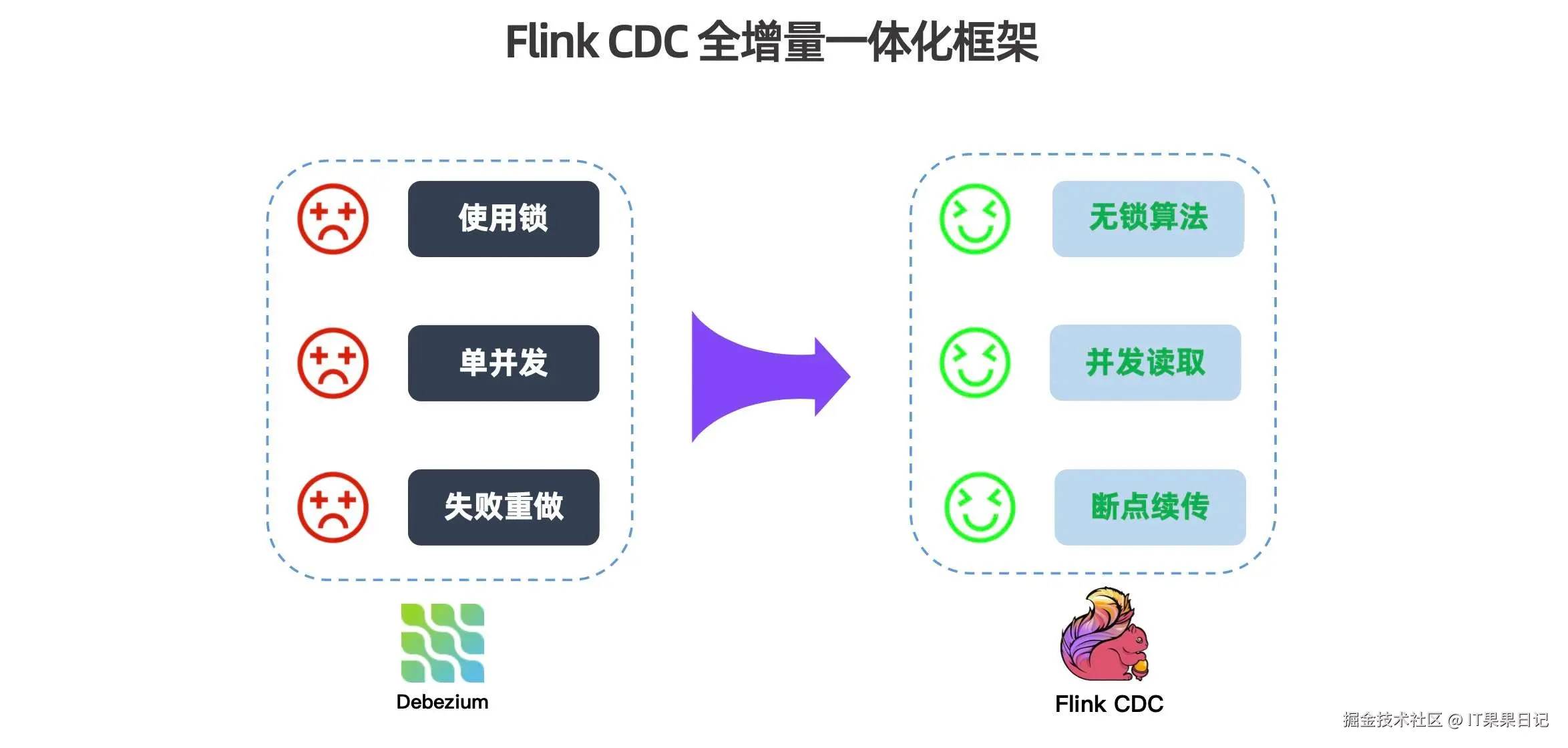

多个sink表
如果想在一个作业里将源表的数据,链式传输给多个表,例如上文中从users表同步数据到users2表和users3表,就要再增加一个users3表的jdbc映射,以及insert语句。
sql
CREATE TABLE users3
(
`id` BIGINT NOT NULL COMMENT '主键id',
`user_name` STRING COMMENT '姓名',
`sex` STRING COMMENT '性别',
`age` BIGINT COMMENT '年龄',
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'table-name' = 'users3',
'url' = 'jdbc:mysql://x.x.x.x:3306/xxxx?useSSL=false&serverTimezone=UTC',
'username' = 'xxxx',
'password' = 'xxxx',
'sink.buffer-flush.max-rows' = '100', -- 根据性能调整,小批量写入
'sink.buffer-flush.interval' = '5s', -- 根据性能调整,控制写入延迟
-- 'sink.parallelism' = '4', -- 增加写入并发
'sink.max-retries' = '3' -- 写入失败重试
);
insert into users3
select * from users;注意这里的源表还是users,而不是users2 ,users2映射的是jdbc连接器,所以如果源表使用users2的话,users3是不会读取到更新记录的。
由于我这里写的场景比较简单,所以insert into users3的代码很少,如果users表到users2和users3表的结构差异比较大,中间做了很多转换,导致insert sql逻辑复杂,那么跳过users2而直接从users表insert into users3时可读性就会很差。解决办法如下:
sql
CREATE TABLE users2_cdc
(
`id` BIGINT NOT NULL COMMENT '主键id',
`user_name` STRING COMMENT '姓名',
`sex` STRING COMMENT '性别',
`age` BIGINT COMMENT '年龄',
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'xxx.xxx.xxx.xxx',
'port' = 'xxxx',
'username' = 'xxxx',
'password' = 'xxxx',
'database-name' = 'xxxx',
'table-name' = 'users2',
'server-time-zone' = 'Asia/Shanghai',
'scan.startup.mode' = 'initial', -- 先做全量快照,然后从binlog最新位置开始读取(默认)
-- 'scan.startup.mode' = 'earliest-offset', -- 直接跳过快照,从binlog最早位置开始读取。
-- 'scan.startup.mode' = 'latest-offset',
'debezium.skipped.operations' = 'd,t' -- 跳过删除/truncate操作
);
insert into users3
select * from users2_cdc;users2_cdc这个表要使用mysql-cdc连接器,虽然它也是users2表,但是和前文中创建的使用jdbc连接器的users2表要分别创建。以上的两条链路也可以分别写在不同的Flink SQL作业里。