想要掌握如何将大模型的力量发挥到极致吗?叶梓老师带您深入了解 Llama Factory ------ 一款革命性的大模型微调工具。
1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其最大潜力。
CSDN教学平台录播地址:https://edu.csdn.net/course/detail/39987
视频号(直播分享):sphuYAMr0pGTk27 抖音号:44185842659
人工智能培训讲师叶梓分享前沿技术:腾讯混元开源视频拟音模型
当前的视频生成模型能够合成高质量的视觉内容,但缺乏同步音频,这极大地限制了用户体验的沉浸感。传统Foley艺术需要专业人士逐帧创建,耗时且成本高昂,无法与现代视频生成系统的效率相匹配。现有的自动化Foley生成方法,如基于文本的音频合成(TTA)和视频到音频(V2A)的生成方法,均存在多模态数据稀缺、模态不平衡和音频质量有限等问题。
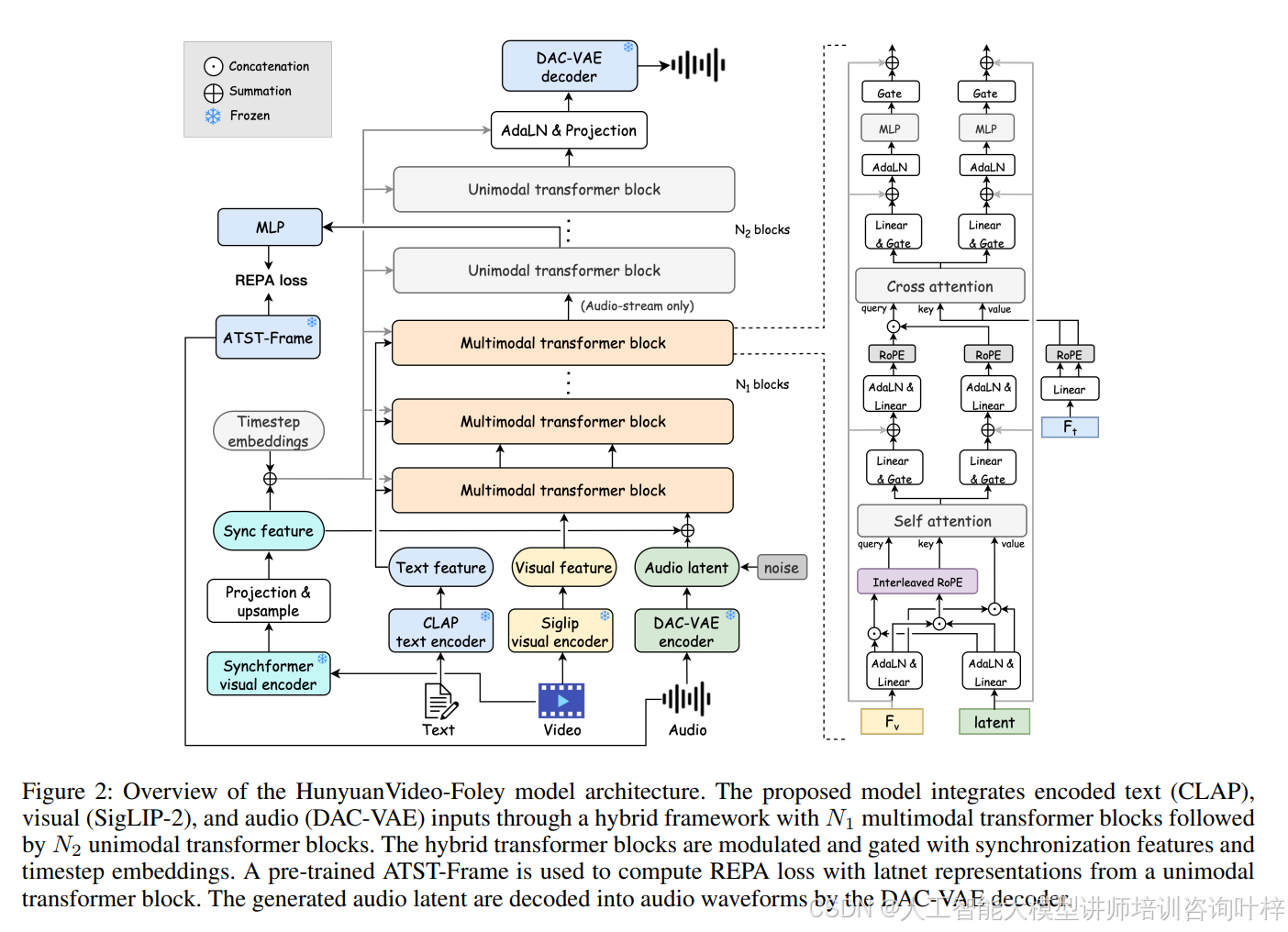
图2概述了HunyuanVideo-Foley模型的架构,展示了如何通过多模态Transformer块和单模态Transformer块的结合,以及如何利用同步特征和时间步嵌入进行调制。
HunyuanVideo-Foley框架包含以下三大核心创新:
-
可扩展的数据管道:通过自动化标注构建了约10万小时的多模态数据集,解决了多模态数据稀缺的问题。
-
表示对齐策略:使用自监督音频特征指导潜在扩散训练,有效提升了音频质量和生成稳定性。
-
新型多模态扩散Transformer:包含用于音频-视频融合的双流结构和通过交叉注意力注入文本语义的结构,解决了模态竞争问题。
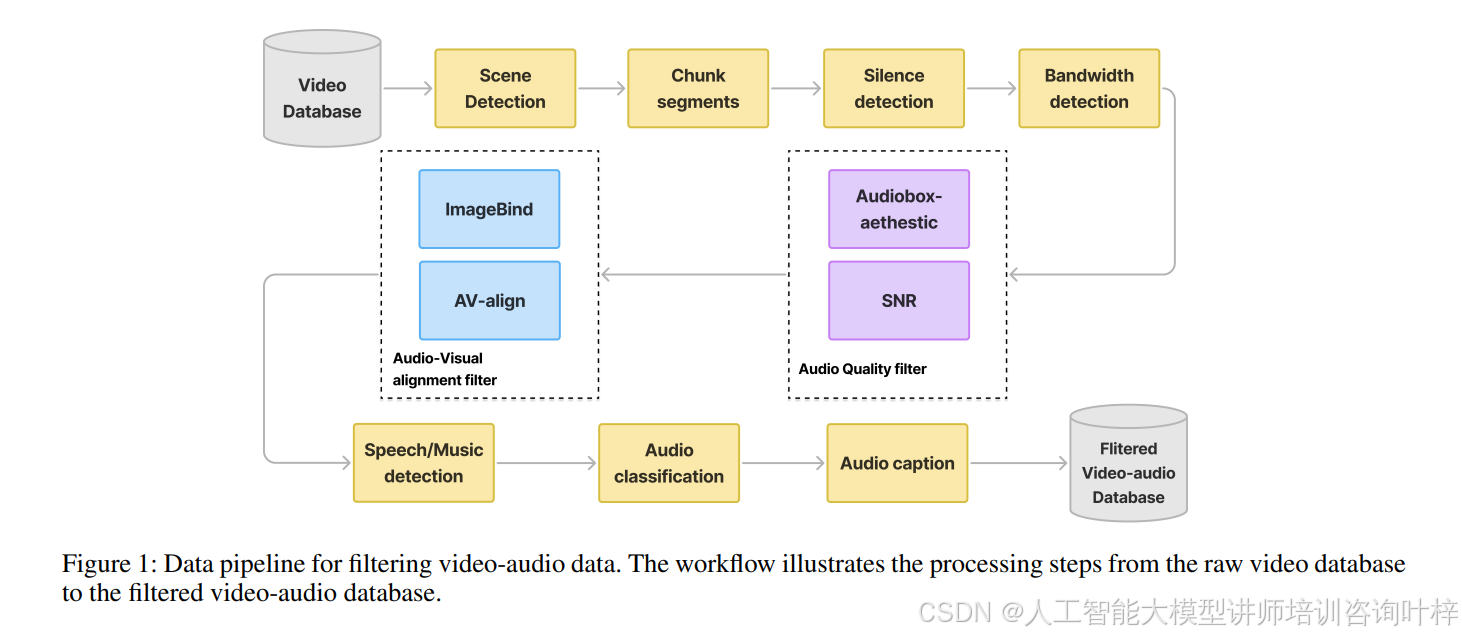
图1展示了数据管道的工作流程,从原始视频数据库到过滤后的视频-音频数据库的处理步骤。
论文还提出了表示对齐(REPA)损失函数,通过将单流音频扩散Transformer块的隐藏嵌入与预训练的自监督模型提取的音频特征对齐,从而增强音频生成质量和稳定性。同时,采用基于DAC的增强型自编码器,将离散令牌替换为连续的128维表示,显著提高了音频重建能力。
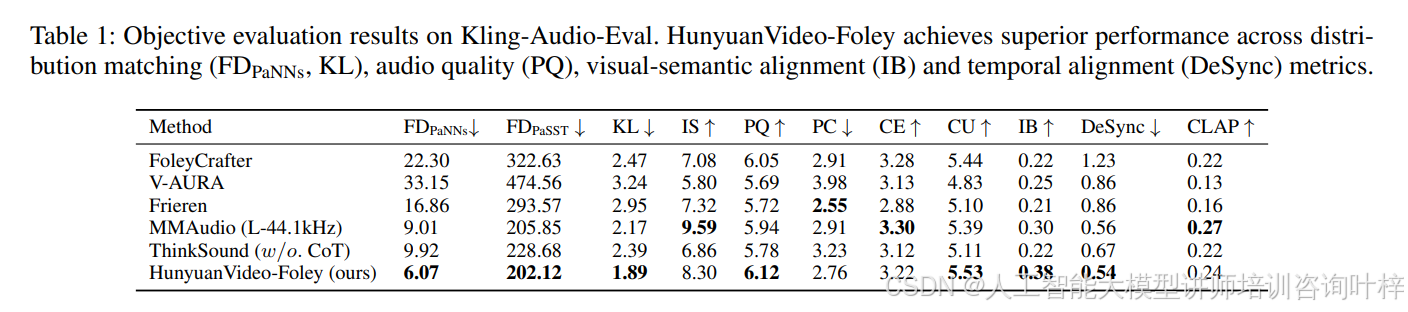
通过综合评估表明,HunyuanVideo-Foley在音频保真度、视觉-语义对齐、时间对齐和分布匹配等方面均达到了新的最优性能。例如,在Kling-Audio-Eval数据集的客观评估中(表1),HunyuanVideo-Foley在分布匹配(FDPaNNs、KL)、音频质量(PQ)、视觉-语义对齐(IB)和时间对齐(DeSync)等多个指标上均优于基线模型。