前言
又是一年"金九银十"秋招季,大模型相关的技术岗位竞争也到了白热化阶段。为满足大家碎片化时间复习补充面试知识点的需求(泪目,思绪回到前两年自己面试的时候),笔者特开设 《大模型工程面试经典》 专栏,持续更新工作学习中遇到大模型技术与工程方面的面试题及其讲解。每个讲解都由一个必考题和相关热点问题组成,小伙伴们感兴趣可关注笔者掘金账号和专栏,更可关注笔者同名微信公众号: 大模型真好玩,免费分享学习工作中的知识点和资料。
一、面试题:如何进行多机多卡的微调
1.1 问题浅析
该问题是一个较为复杂且综合性极强的面试题。它不仅涉及算法层面的并行策略选择,还考察了候选人的工程化实践能力。
1.2 标准回答
第一段首先说明多机多卡微调会涉及哪些关键技术。所谓多机多卡微调,本质上就是通过分布式训练框架将模型、数据和计算任务切分到多个GPU节点上并行执行。常见的并行模式包括数据并行(Data Parallel, DP) 、模型并行(Model Parallel, MP) ,以及近年来在大模型训练中应用广泛的张量并行(Tensor Parallel,TP) 和 流水线并行(Pipeline Parallel, PP)。
-
数据并行主要解决"批量太大"的问题,把训练数据分块分发到不同GPU,单纯使用数据并行会使每个GPU上拥有完整的模型副本,但处理不同的数据批次,通过AllReduce方式同步梯度来更新模型;
-
模型并行则是针对模型参数过大的情况,不同GPU放模型的不同部分;
-
张量并行会把单个大矩阵按照行或列拆开分布到多张卡上并行计算,在大规模Transformer模型里应用最广,有时候也把张量并行看作模型并行的一种;
-
流水线并行把模型的不同层当作流水线的不同工具,分配到不同GPU上,每个GPU负责处理数据流中的一段。同时通过流水线调度机制让不同batch在不同阶段并行流动,像工厂流水线一样工作。
-
实际工程中常使用混合并行来突破单一策略的局限。例如,当单卡显存不足时,可以先使用张量并行把模型的权重切分,再叠加数据并行来保证足够的吞吐,这也是Megatron-LLM的典型做法。如果规模继续扩大,还要结合流水线并行,也就是把不同的网络层分布到不同GPU节点上,不同节点负责模型的不同阶段,这就是所谓的3D并行,也是当代大模型训练的标配。
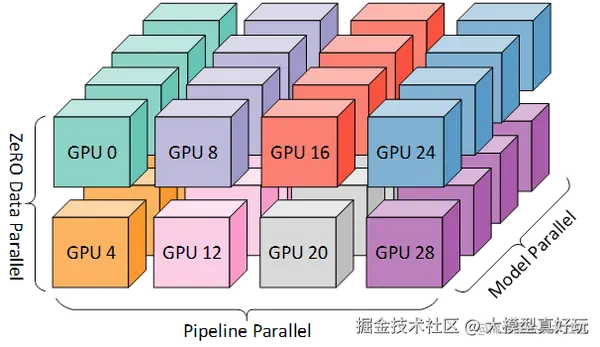
第二段详细描述如何在工程层面实现稳定高效的分布式训练。要实现稳定高效的多机多卡微调,不仅要选择好并行策略,而且还要掌握底层通信与调度机制。目前业界主流做法是基于NCCL通信库与高性能互联搭建分布式集群,通过PyTorch Distributed、DeepSpeed或Megatron-LLM等框架实现自动化调度和梯度同步。此外在工程方面还必须考虑容错性、断点续训、混合精度(FP16/BF16)等因素。
二、相关热点问题
2.1 在工程实践中通信带宽不足会带来哪些影响?
答案: 通信带宽不足是多机多卡微调中最常见的瓶颈之一,表现为 梯度同步速度过慢、训练吞吐下降、GPU 利用率偏低。尤其是在跨节点训练时,如果网络互联仅是万兆以太网而非 InfiniBand 或 NVLink,那么通信时间可能占到整体训练时间的-半以上,导致扩展效率大幅降低。
2.2 在多机多卡微调中,如何应对单节点故障?
答案: 多机多卡训练过程中,单节点故障往往会导致整个训练任务中断,影响极大。工程实践中常见的解决方案是 断点续训 与 分布式容错机制。比如,通过定期保存checkpoint,可以在节点恢复或替换后快速回滚到最近一次保存的状态,避免重复计算。部分框架(如 DeepSpeed、Horovod)也支持自动容错,在检测到节点失联时能自动重试或调整并行策略。
2.3 在多机多卡微调中,DeepSpeed策略为什么要使用ZeRO优化器?

答案: 在传统的数据并行中,每个GPU都保存着一份完整的模型副本,包括:
- 优化器状态 (Optimizer States):例如 Adam 优化器中的动量(momentum)和方差(variance)。
- 梯度 (Gradients)
- 模型参数 (Parameters)
这导致了巨大的显存冗余。ZeRO 通过将这三部分内容在数据并行的多个GPU之间进行分区(Partition) ,而不是每个GPU都存一份完整副本,从而解决了这个问题。
ZeRO 的优化是分阶段的,通常称为 ZeRO-1, ZeRO-2, ZeRO-3。
1. ZeRO-Stage 1 (优化器状态分区)
将优化器状态(如 Adam 的 m 和 v)切分到所有数据并行进程的GPU上。每个GPU只负责存储和更新其中一份分区。结合我们文章大模型工程面试经典(一)---如何评估大模型微调&训练所需硬件成本 该策略减少大约4倍的显存占用。
2. ZeRO-Stage 2 (梯度分区)
在 Stage 1 的基础上,梯度也被切分到所有GPU上。每个GPU在反向传播后只保留它负责的那部分梯度。进一步减少了 2倍 的梯度内存占用。卡间通信需要使用AllReduce方式同步更新梯度,训练时长增加。
3. ZeRO-Stage 3 (参数分区)
在 Stage 2 的基础上,模型参数 也被切分到所有GPU上。每个GPU只保存它负责的那部分参数。将显存占用减少到 1/GPU数目 ,这是显存减少最显著的阶段。通信开销最大。在前向传播时,需要从其他GPU收集(Gather)所需的参数,计算完立即释放;在反向传播时,同样需要收集参数来计算梯度。这用通信换取了显大的内存空间。
三、总结
本期分享系统介绍了如何进行多机多卡大模型微调这一大模型面试几乎必问的关键问题,并扩展了3个热点问题。总的来说,多机多卡微调类的问题是最顶尖的工程方面问题,按文中模板回答一定是加分项!小伙伴们阅读后感兴趣可关注笔者掘金账号和专栏,更可关注笔者同名微信公众号: 大模型真好玩,免费分享学习工作中的知识点和资料。