FPGA 中 DDR 控制器的地址映射顺序(Address Mapping Order) 是优化设计速度(带宽和效率) 的关键。
简单来说,地址映射顺序决定了线性地址如何映射到 DDR 芯片内部的物理结构(Bank、Row、Column) 。正确的映射可以最大化访问的局部性 ,从而减少耗时严重的 行激活(Row Activate) 命令,显著提升有效带宽。
一、核心概念:DDR 的内部结构
要理解地址映射,必须先了解 DDR SDRAM 的物理结构。你可以把它想象成一个有很多本书的图书馆:
-
Bank : 相当于图书馆的楼层 (例如,Bank 0, Bank 1, ...)。DDR3/4 通常有 8个 Banks。
-
Row : 相当于一层楼里的一个书架。一个 Bank 里有很多个 Rows。
-
Column : 相当于一个书架上的某一本书。一个 Row 里有很多个 Columns。
访问数据的流程:
-
激活(Activate) : 告诉 DDR,"我要去第 X 层楼(Bank)的第 Y 个书架(Row)"。这是一个高延迟的操作。
-
读/写(Read/Write): "请把那个书架上的第 Z 本书(Column)给我"。在同一个"书架"(Row)上连续取多本书(Burst Length)是非常快的。
-
预充电(Precharge): 关闭当前的书架(Row),为打开另一个书架做准备。
关键点 : 最耗时的操作是 Activate。因此,优化的目标就是尽可能让连续的内存访问发生在同一个 Bank 和同一个 Row 内,从而最大限度地减少 Activate 命令。
二、地址映射顺序的作用
地址映射顺序决定了用户发出的线性地址 如何被解码成 Bank、Row、Column 这三个物理地址。
-
用户逻辑看到的地址 :
addr[31:0](一个长长的、连续的地址空间) -
MIG (Memory IP) 做的事情 : 将
addr[31:0]切分成rank_addr、``bank_addr、``row_addr、``col_addr。
映射顺序就是定义 addr[] 的哪几位被分配给 bank_addr,哪几位给 row_addr,哪几位给 col_addr。
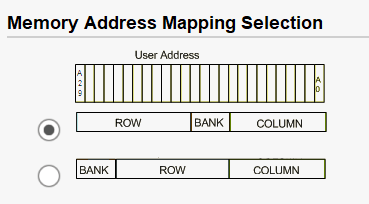
三、DDR地址映射配置
最常见的两种预设模式是:
a. ROW_COLUMN_BANK (或类似名称)
-
含义 : 线性地址的高位 映射到 Row ,中间位 映射到 Column ,低位 映射到 Bank。
-
访问模式 : 连续地址访问会在不同的 Bank、相同的 Row 之间跳转。
-
优点 : 非常适合连续 burst 访问(例如,DMA 传输大块数据)。因为连续访问总是在同一个 Row 内,只需要一次
Activate,后续都是快速的Read/Write命令,效率极高。 -
缺点: 如果访问模式是稀疏的、随机跨越大地址范围的,效果一般。
b. BANK_ROW_COLUMN (或类似名称)
-
含义 : 线性地址的高位 映射到 Bank ,中间位 映射到 Row ,低位 映射到 Column。
-
访问模式 : 连续地址访问会在同一个 Bank、不同的 Row 之间跳转。
-
优点 : 对于某些特定的访问模式可能有用,但通常性能较差 。因为连续访问每次都会切换到新的 Row,导致每次访问都需要先
Precharge再Activate,产生大量延迟,带宽利用率极低。 -
缺点: 几乎不用于需要高带宽的场景。
简单对比:
假设你顺序读取 0x0, 0x4, 0x8, 0xC ...(Cache line 大小访问)
-
使用
ROW_COLUMN_BANK: 这些地址很可能落在 同一个 Row,不同的 Bank 。只需要一次Activate,然后可以连续发出读命令,速度飞快。 ✅ -
使用
BANK_ROW_COLUMN: 这些地址很可能落在 同一个 Bank,不同的 Row 。每读一次,都需要先关闭当前 Row (Precharge),再打开新 Row (Activate),然后才能读,速度极慢。 ❌
四、如何选择以实现"速度快"?
黄金法则:让你的内存访问模式与地址映射顺序相匹配。
-
绝大多数情况下的最佳选择 :
ROW_COLUMN_BANK。- 为什么? 大多数高性能数据传输(如视频帧处理、网络包处理、科学计算)都是通过 DMA 进行连续块传输 。
ROW_COLUMN_BANK映射正是为这种顺序访问模式而优化的,它能最大化利用 Banks 的并行性和 Row 的局部性。
- 为什么? 大多数高性能数据传输(如视频帧处理、网络包处理、科学计算)都是通过 DMA 进行连续块传输 。
-
何时选择其他映射?
-
如果你的访问模式是极其特殊的"跨步(Stride)"访问,并且你通过分析发现默认映射导致 Bank Conflict 率很高,才需要考虑自定义映射。
-
例如,如果你总是以固定的、很大的步长访问内存(访问地址 0, N, 2N, 3N...),并且 N 的值恰好导致所有访问都命中同一个 Bank 的不同 Row,那么性能就会很差。这时可能需要调整映射顺序,将这些访问"打散"到不同的 Bank 上。但这种分析非常复杂,通常需要仿真。
-
-
对于 UltraScale+ MIG:
- MIG 提供了更灵活的选项,例如
R-B-C,B-R-C等。同样的原则适用:R-B-C(Row-Bank-Column) 通常是顺序访问的最佳选择。
- MIG 提供了更灵活的选项,例如
五、结论
为了获得最快的速度,尤其是在进行顺序访问时,在 Xilinx MIP IP 中应优先选择 ROW_COLUMN_BANK 或 ROW_BANK_COLUMN 这样的地址映射顺序。 这是提升 DDR 带宽利用率和系统性能的最简单、最重要的配置之一。如下图