今天简单介绍两篇讨论SFT和DPO算法微改进的文章。这两篇文章的优势都不是理论叙事,也不是发明了个(XXPO),就比较像在工业场景训练当中的微改进,改进简单,效果也不错。
一篇是针对SFT的改进 PROXIMAL SUPERVISED FINE-TUNING,一篇是针对DPO的改进 Bridging Offline and Online Reinforcement Learning for LLMs
先说针对SFT的↓
PROXIMAL SUPERVISED FINE-TUNING
一句话总结
这篇文章使用了类似PPO的loss来训练SFT,即一种近似的SFT( Proximal supervised fine-tuning-PSFT)
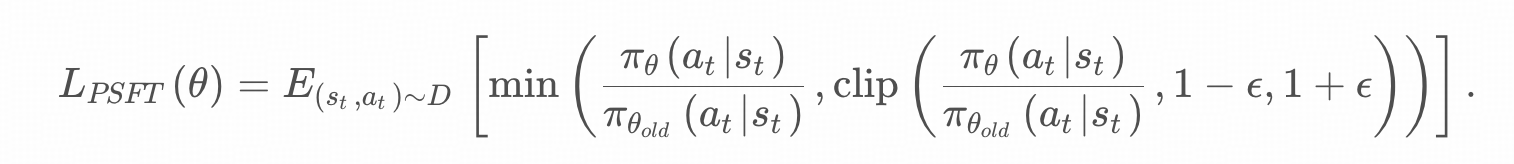
这种做法大大减少了SFT训练中的熵坍缩现象,不仅保留了更强的泛化能力,也为后续RL提供了更好的起点。
关键结果
1. SFT的熵坍缩问题
比起RL训练中的熵坍缩问题,SFT中的熵坍缩问题往往更加显著,比较常见的表现就是经过1-2个epoch的训练,SFT模型针对某个特定问题,乃至某类特定问题的答案,不管怎么采样都不会发生变化。
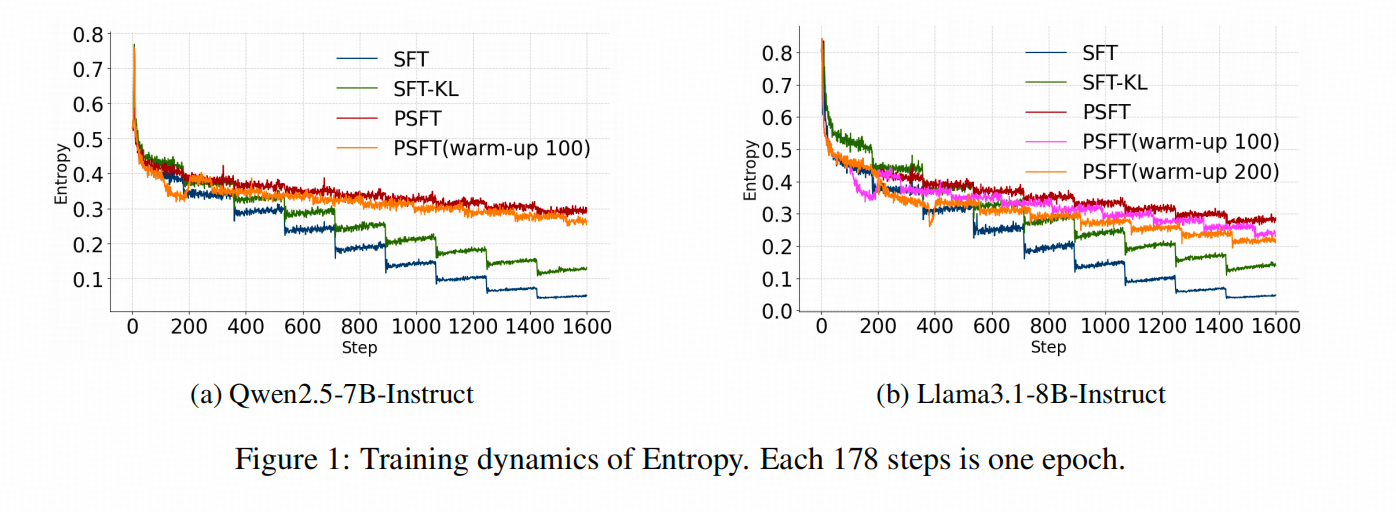
譬如上图中,除了作者提出的做法PSFT以外,SFT和SFT_KL在训练过程中,答案的熵都在大幅下降。
SFT_KL 是作者自己设的对比组,猜想训练目标应该是
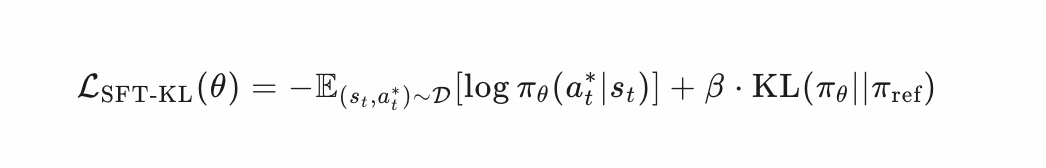
这里β\betaβ 是0.5。
值得注意的是,上图中有非常明显的"下台阶"现象,这是SFT训练中一种比较常见的现象,即每一个epoch,SFT模型都在很大程度上实现了"背答案",即每个token的loss都大幅度下降了一个尺度,这其实也是熵坍缩的一部分。
2. PSFT能否实现更好的【泛化】?
作者验证这点的思路也很简单,在数学推理任务上训练后,如果能在知识任务和IF任务上保持准确率不掉,即为能【泛化】。(其实我们通常讲泛化值得是在A-Domain学习的能力能在B-Domain上接近无损的使用,即能力迁移,作者这里指得更接近是 【不遗忘】)
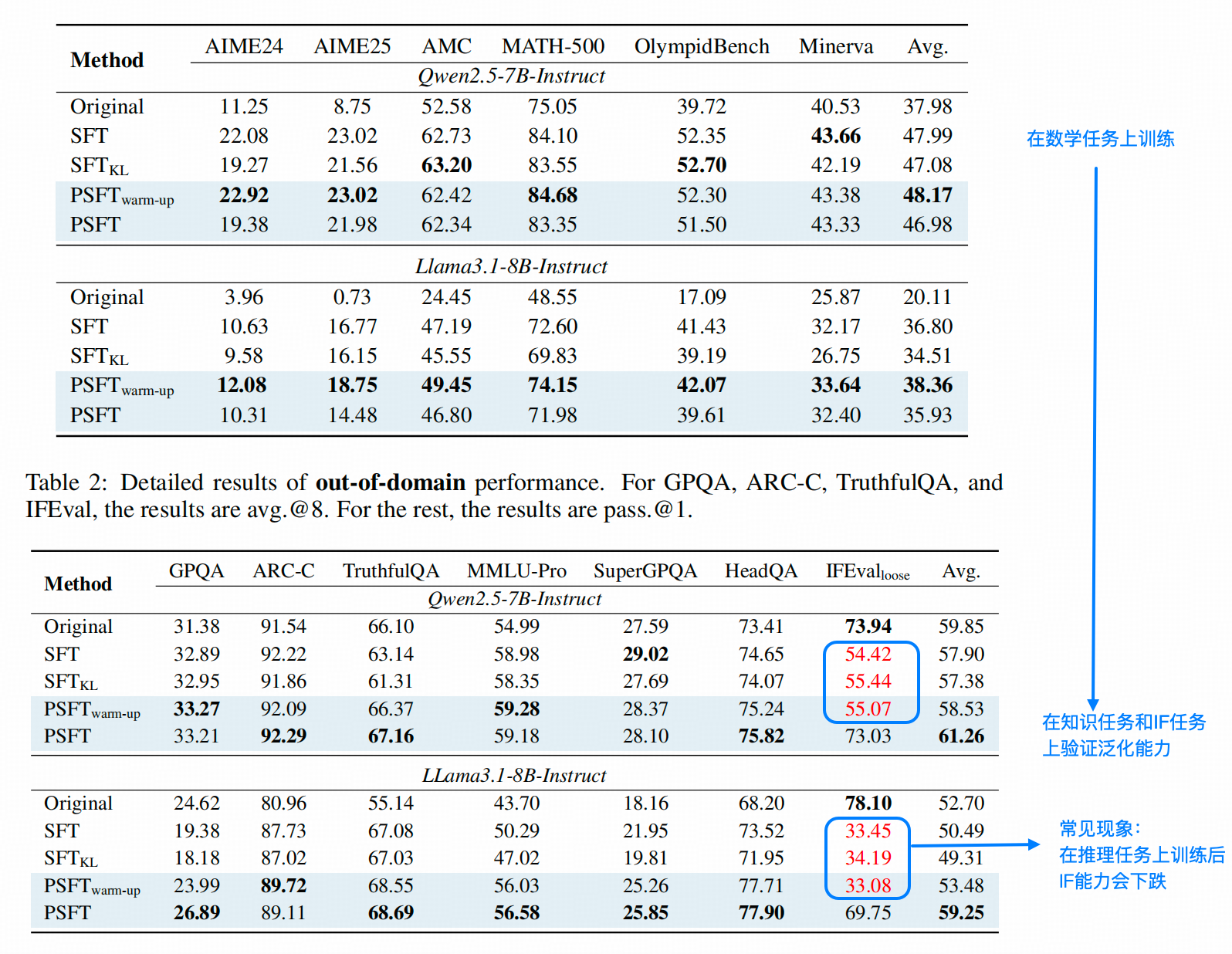
仔细观察上表,我们可以看出,1. 在数学任务集上,SFT和PSFT的结果差距不大。
- 在知识任务和IF(Instruction Following)任务上,PSFT基本保持不掉点,但是SFT却出现能力倒退。
一个比较奇怪的事情是,同是PSFT方法,有warm-up的PSFT和SFT在IF任务上掉点一样严重,但没有warm-up的版本却没有这种情况,因为什么,因为作者这里写的warm-up不是我们平常说的学习率由低到高往上涨的过程,而是直接前两个epoch不用PSFT而是直接用SFT(这种写法真的可以叫逆天了,起个啥新名都比强行用大波波指代大屁股强吧,😒)
3. PSFT 能否给RL提供更好的基础?
作者用Qwen3-4B的BASE模型在几个Align数据集上跑完了SFT+DPO的Align实验。下图a 展示的仍然是SFT和PSFT相比 ,熵的变化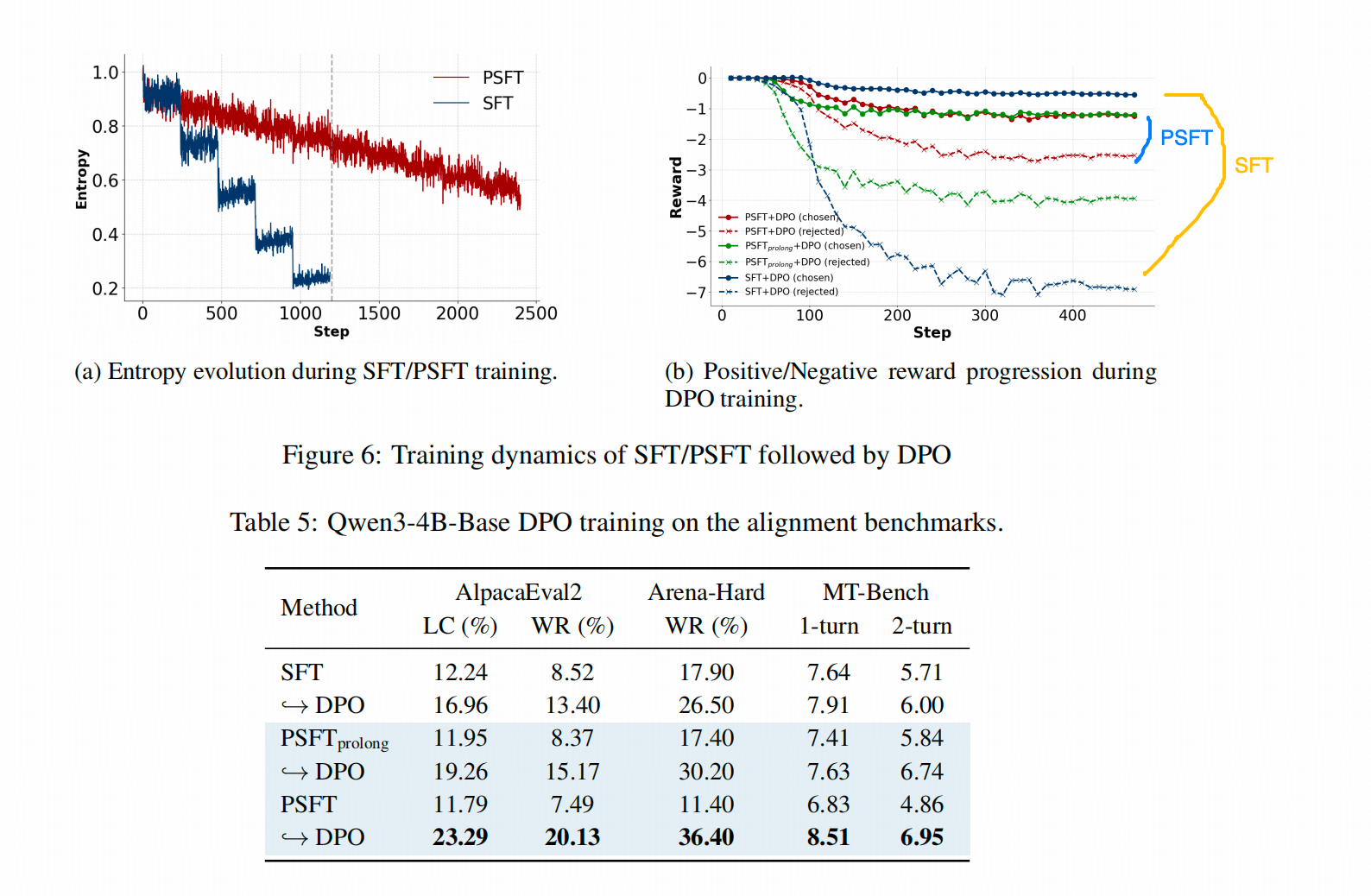
上表的指标也展示了PSFT+DPO的效果要好于 SFT+DPO
4. 高熵token受益最大
在2/8定律那篇文章中提到过,reasoning 训练的整个过程中,一些引导思考的词(这是认知分析那篇文章说的)总是有更高的熵。而PSFT的作者也分析了在训练第一个epoch和第三个epoch中,哪些token会被类PPO loss里的(1−ϵ,1+ϵ)(1 - \epsilon, 1 + \epsilon)(1−ϵ,1+ϵ)的界线减掉。下图的词云中词的字体越大说明出现频次越高。

从上图能看出来,这些被clip频次更高的Token恰恰是熵较高的【认知token】,这一来印证了其他文章的观点,二来也说明,这些具备高熵的token让更多样本联合训练,比让几个样本带来的高loss带走是更好的选择。
Bridging Offline and Online Reinforcement Learning for LLMs
一句话总结
我们常说的DPO,经常被定义为Offline方法, 原因有两个,一个是训练数据静态,一个是Reference 模型是静态的,即这两个都不会随着训练的进程而有所调整。
而本文设想了这样一种情况,如果我每训练几十步就更新一次Ref模型和训练数据中的Response ,形成一种所谓的semi-online DPO ,那在我更新频率多频繁的时候,能赶上Online RL的其他算法的性能呢?
这篇文章给出的结论是:
- 对于数学任务,每100步更新一次就能打平GRPO
- 对于IF任务,一步一更新甚至能比GRPO结果好,5步/10步 1更新都能达到不错的效果
- 只要中途更新,效果就比纯Offline DPO强。
为什么要跟GRPO比?
因为DPO的训练没有Value Model的参与,GRPO也没有。
关键结果
1. 数学任务和IF任务上,Semi-Online DPO都能达到不错的效果
下表中,Seed 就是原模型,在Semi-Online DPO旁边括号里就是模型和数据的更新频率,Online DPO机会就是每一步都更新。结果显示,Semi-online DPO中每100步更新的平均效果最好。
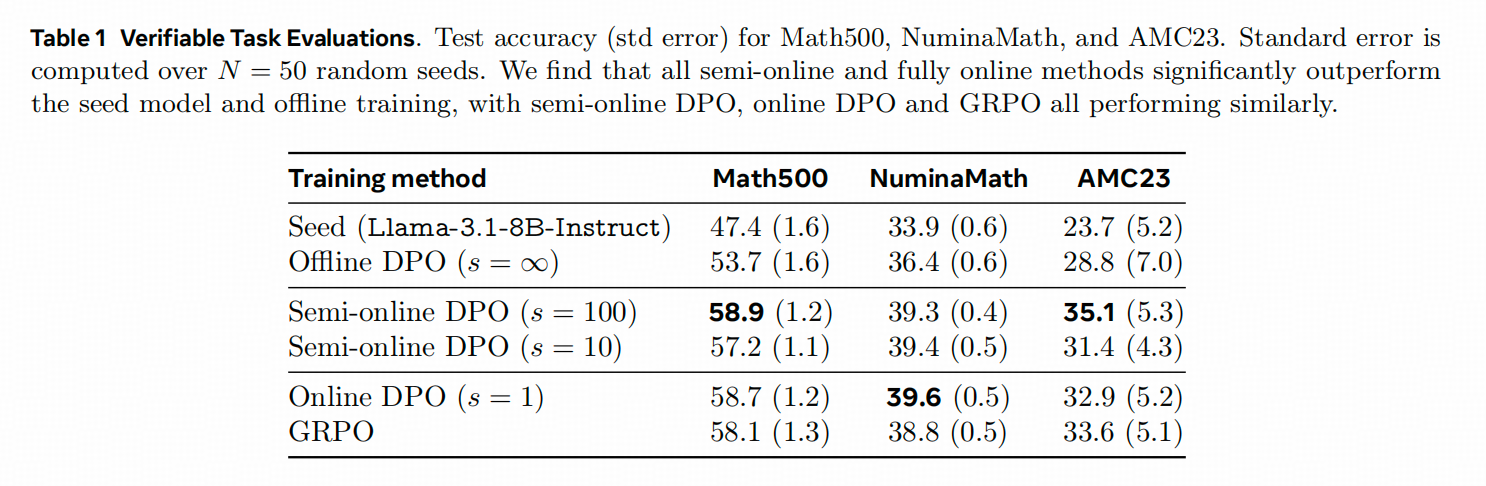
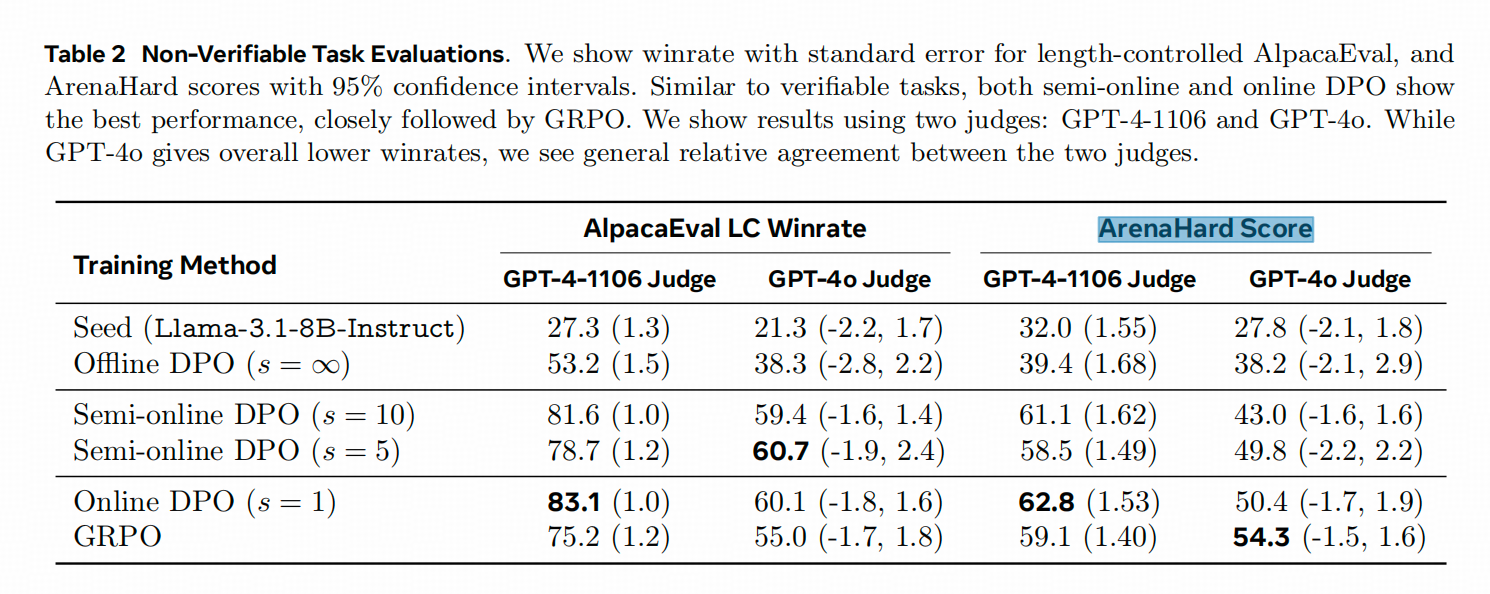
再看在IF任务上(这是用LLM-as-Judge的方法测评的),可以看出来上下两个表中,纯Offline DPO和Semi-online DPO之间的Performance Gap3=都是比较大的。
2. 只更新数据,不更新Ref Model行不行?
答案肯定是不行,但是作者这里其实也有点硬凹------因为相比训练数据的准备难度,Ref Model更新根本不算个事啊。不过,作者画得这个图还挺好的。
下图展示的是,纯Online DPO在训练数学任务的时候,生成长度和Reward的变化曲线。
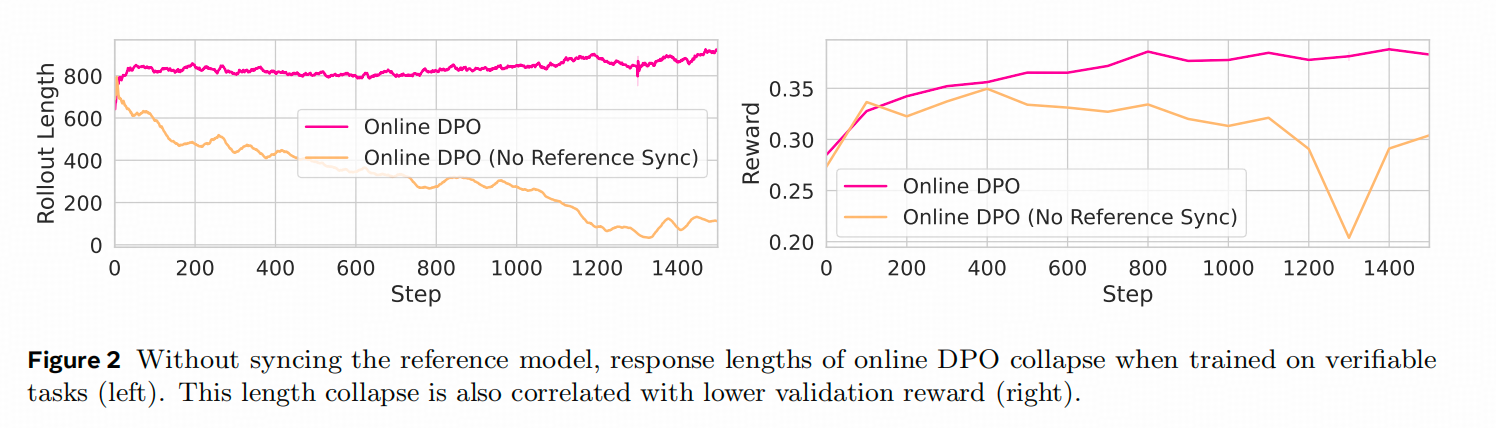
从上图可以看出来,如果没有Ref Model的更新,模型的训练其实并不稳定,原因其实也比较直白,初始的Ref Model 之所以要被训练,就是因为在目标任务上表现不好,即策略分布存在问题,好的策略不一定真的在这个原始策略分布的非常附近的地方。
3. 熵的变化
下面这个图比较有意思,左边图画得是各种Semi-online DPO(更新步数不同)与GRPO 在训练过程中 熵的变化。
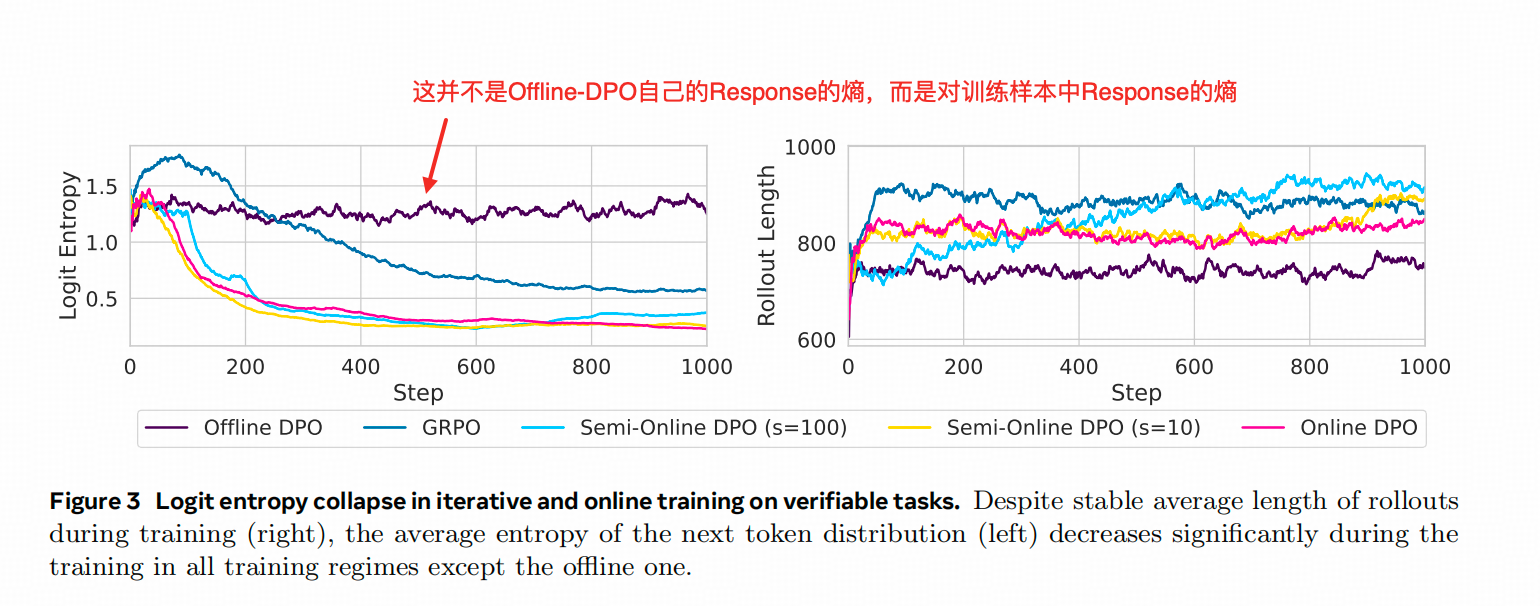
如果我们排除一些细节,GRPO(蓝线)和Online DPO(红线)最大的差别在于Ref Model是否实时更新,而这个蓝线和红线的Gap就有可能是这个差异带来的,回想前面PSFT的现象和结论,Ref Model本身就是对Logits更新的一种限制,会抑制SFT的熵坍缩,这里频繁的更新Ref Model 反而消除了这一优势。
总结和评价
- 其实可以在PSFT上再加一层 Ref Model固定步数更新(不一定非常更新到最新的checkpoint),也可以更新到前面一些checkpoint的集成模型上。
- 对设计Semi-online DPO最大的疑问其实是:你的数据怎么来,有Reward我用你?没Reward我用你? 因为Semi-Online这个步骤其实切断了一个正常数据准备和模型训练可并行的处理流,要求能够给新的Response打分或排序。如果真的有实时排序的能力,用GRPO不香吗?而且还别说Online RL有很多种其他方案呢。
- 这两篇文章其实都显示了工业中常用的【魔改】的有效性( ̄▽ ̄)~* ,其实工业中最常出现的魔改就是把一些有效的方法当中可能有效的组件互相再排列组合一下,脑子动的不够快没关系,手动的够快就行了。😅