在自动驾驶技术飞速发展的今天,端到端系统因其能直接从传感器输入学习驾驶动作、实现整体优化的特性,逐渐成为研究热点。然而,现有端到端模型存在资源需求大、泛化能力弱、闭源限制等问题。由德州农工大学、密歇根大学和多伦多大学联合提出的 OpenEMMA 框架,基于多模态大语言模型(MLLMs),以开源、高效、鲁棒为核心优势,为端到端自动驾驶技术的普及与发展提供了全新解决方案。
原文链接:2412.15208
代码链接:https://github.com/taco-group/OpenEMMA
沐小含持续分享前沿算法论文,欢迎关注...
一、论文背景与核心动机
1.1 自动驾驶技术发展现状
自动驾驶技术的进步离不开人工智能、传感器技术和高性能计算的支撑,但真实路况的复杂性(如不可预测的道路使用者、动态交通模式、多样化环境条件)仍带来巨大挑战。传统自动驾驶系统采用模块化架构,将感知、地图构建、预测、规划等功能拆分到独立模块中,这种设计虽便于单个模块的调试与优化,但存在明显缺陷:
- 模块间通信易出错,导致系统扩展性受限;
- 预定义接口僵化,难以适应未预见的新场景。
近年来,端到端系统逐渐兴起,无需符号接口,可直接从传感器输入学习驾驶动作,实现整体优化。但现有端到端系统多为专用模型,训练数据集范围狭窄,在复杂真实场景中的泛化能力不足。
1.2 多模态大语言模型的赋能与局限
多模态大语言模型(MLLMs)通过大规模跨领域数据集训练,具备丰富的世界知识和先进的推理能力(如思维链 Chain-of-Thought 推理),为解决端到端系统的泛化问题提供了新路径。Waymo 基于 Google Gemini 开发的 EMMA 模型,在感知、决策和导航的融合方面取得了显著进展,但 EMMA 是闭源模型,限制了广大研究社区的访问与实验。
1.3 核心研究动机
针对现有技术的痛点,论文提出 OpenEMMA 的核心动机如下:
- 打破闭源限制:提供开源框架,复刻 EMMA 的核心功能,让更多研究者能够参与端到端自动驾驶技术的研发;
- 提升系统效率:基于现有开源模块和预训练 MLLMs,降低端到端模型的开发与部署成本;
- 增强泛化与鲁棒性:通过思维链推理和视觉专家模型融合,解决复杂场景下的感知与规划问题;
- 提高可解释性:生成人类可读的输出结果,提升自动驾驶系统的透明度与可用性。
二、OpenEMMA 框架整体设计
OpenEMMA 是一款计算高效的端到端自动驾驶系统,核心输入为前视摄像头图像(视觉输入)和车辆历史状态数据(文本输入),核心输出为未来行驶轨迹和道路目标 3D 检测结果。框架整体分为两大核心模块:基于思维链的端到端规划模块、视觉专家增强的目标检测模块,同时通过统一的流程设计实现两大模块的协同工作。其整体架构如图 1 所示:
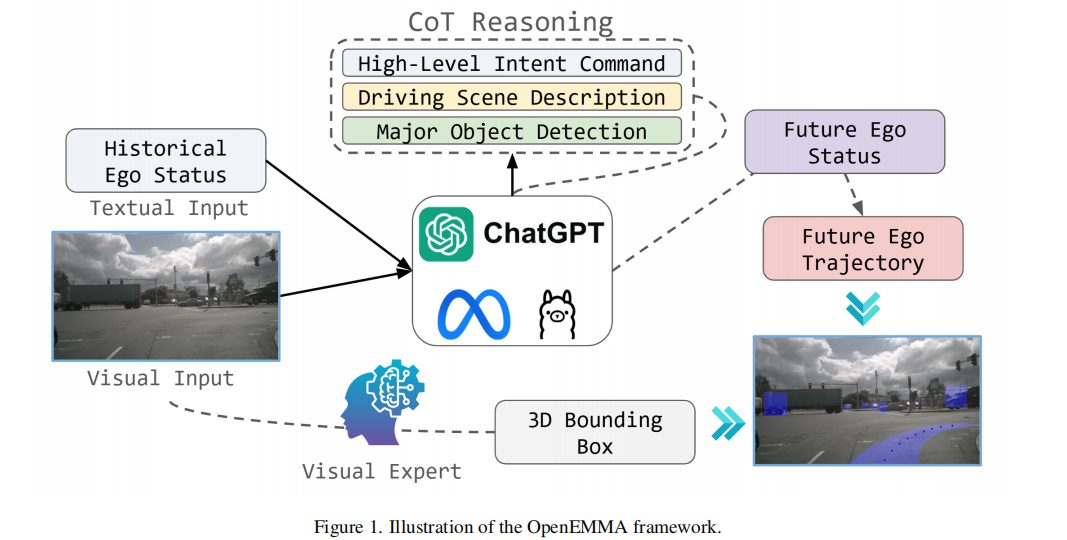
从架构图可见,OpenEMMA 的工作流程分为三个关键步骤:
- 输入层:接收前视摄像头图像(视觉输入)、车辆历史状态(如过去 5 秒的速度、曲率等文本输入);
- 处理层:通过 MLLMs 进行思维链推理,结合视觉专家模型(YOLO11n)完成目标检测;
- 输出层:生成速度向量、曲率向量,进而计算出未来行驶轨迹,同时输出 3D 边界框检测结果和可解释性文本描述。
三、核心技术原理详解
3.1 基于思维链的端到端规划(End-to-End Planning with Chain-of-Thought)
该模块是 OpenEMMA 的核心,旨在通过 MLLMs 的推理能力,将轨迹规划任务分解为人类可解释的中间步骤,最终生成精准的行驶轨迹。
3.1.1 核心设计思路
与传统直接生成局部坐标轨迹的方法不同,OpenEMMA 借鉴人类驾驶逻辑,将轨迹规划分解为两个中间表示:
- 速度向量
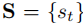 :表示车辆速度大小(对应油门控制);
:表示车辆速度大小(对应油门控制); - 曲率向量
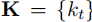 :表示车辆转弯速率(对应方向盘控制)。
:表示车辆转弯速率(对应方向盘控制)。
通过这两个中间向量,既保证了规划过程的可解释性,又便于 MLLMs 利用其世界知识进行推理决策。
3.1.2 数学建模与轨迹计算
基于速度向量和曲率向量,OpenEMMA 通过以下数学公式逐步计算出最终的行驶轨迹:
-
航向角计算:航向角
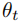 由曲率和速度的积分得到,表示车辆在时刻
由曲率和速度的积分得到,表示车辆在时刻 的行驶方向,公式如下:
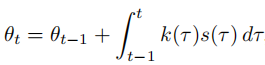
为简化数值计算,采用累积梯形法则近似:
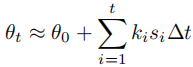
其中
-
速度分量计算:将速度向量分解为
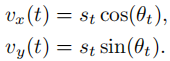
-
轨迹坐标计算:通过对速度分量积分,得到车辆在自车坐标系下的未来位置坐标
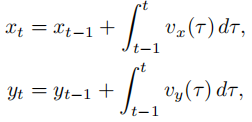
同样采用累积梯形法则近似:
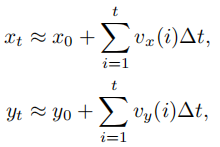
其中
3.1.3 两阶段处理流程
OpenEMMA 的规划模块分为推理(Reasoning)和预测(Predicting)两个阶段,通过任务特定的提示词(Prompt)引导 MLLMs 完成工作:
阶段 1:推理阶段输入前视摄像头图像和车辆历史状态(过去 5 秒的速度、曲率),引导 MLLMs 生成对当前驾驶场景的全面推理,包括三个核心部分:
- 意图指令(Intent Command):明确车辆的预期动作,如车道保持、左转、右转、直行,以及速度控制策略(保持、减速、加速);
- 场景描述(Scene Description):基于交通灯、其他车辆 / 行人运动状态、车道标线等信息,简洁描述当前驾驶场景;
- 主要目标(Major Objects):识别关键道路使用者,明确其在图像中的位置、当前动作,以及对自车决策的重要性。
阶段 2:预测阶段 结合思维链推理结果和车辆历史状态,提示 MLLMs 生成未来 秒的速度向量
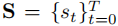 和曲率向量
和曲率向量 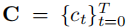 (对应
(对应 个轨迹点),再通过上述数学公式积分得到最终轨迹
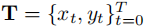 。
。
3.2 视觉专家增强的 3D 目标检测(Object Detection Enhanced by Visual Specialist)
MLLMs 在空间推理方面存在局限性,难以直接实现高精度的 3D 目标检测。为解决这一问题,OpenEMMA 集成了专门优化的视觉专家模型,专注于单帧前视摄像头图像的 3D 边界框检测任务。
3.2.1 任务定义与技术选型
OpenEMMA 的目标检测任务属于单目相机 3D 目标检测,即仅通过单张 RGB 图像预测道路目标的 3D 边界框。单目 3D 检测方法主要分为两类:
- 深度辅助方法:先预测深度信息,再辅助完成 3D 检测;
- 纯图像方法:直接基于 RGB 数据进行 3D 检测。
论文选择 YOLO3D 作为基础模型,原因如下:
- 精度可靠,在单目 3D 检测任务中表现优异;
- 开源实现质量高,便于二次开发;
- 架构轻量,支持高效微调与实际部署。
3.2.2 YOLO3D 模型优化与训练细节
YOLO3D 是一种两阶段 3D 目标检测方法,核心思想是强制执行 2D-3D 边界框一致性约束(即每个 3D 边界框必须紧密包裹在其对应的 2D 边界框内),其工作流程为:
- 第一阶段:预测目标的 2D 边界框;
- 第二阶段:基于 2D 边界框,估计目标的 3D 尺寸和局部朝向,最终计算出 3D 边界框的 7 个参数(中心坐标
为适配自动驾驶场景,论文对 YOLO3D 进行了以下优化:
- 替换 2D 检测网络:采用 YOLO11n 作为 2D 检测 backbone,提升检测速度与精度;
- 数据集适配:在 nuImages 数据集上进行微调,图像下采样至 640×360 分辨率;
- 训练配置:
- 预训练权重:采用 COCO 数据集预训练权重;
- 硬件环境:单块 RTX 4060Ti 显卡;
- 训练参数:训练 300 个 epoch,批次大小(batch size)为 50,采用 SGD 优化器(学习率初始为 0.01,线性衰减至 0.0001,动量 0.937,权重衰减 0.0005);
- 最优结果:在第 290 个 epoch 达到最佳性能,mAP50 为 0.60316。
3.2.3 检测结果可视化
YOLO11n 的 2D 边界框检测结果如图 2 所示,不同类别目标采用不同颜色标注:
- 粉色:轿车(cars);
- 绿色:卡车(trucks);
- 黄色:拖车(trailers);
- 蓝色:行人(pedestrians);
- 白色:交通锥(traffic cones)。
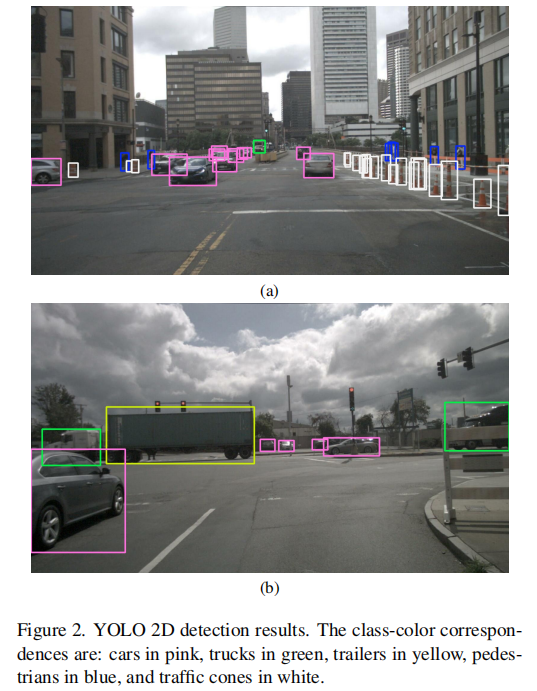
3D 边界框检测结果通过演示视频展示(https://github.com/taco-group/OpenEMMA),结合 2D 检测结果,可实现对道路目标的精准空间定位,为后续轨迹规划提供关键支撑。
四、实验设计与结果分析
论文通过三组核心实验,全面验证了 OpenEMMA 在轨迹规划、目标检测和复杂场景适应性方面的性能,实验设计严格遵循可复现性原则,所有参数和数据集均公开透明。
4.1 实验数据集与环境配置
4.1.1 数据集
核心实验基于 nuScenes 数据集的验证集,该数据集是自动驾驶领域的多模态基准数据集,包含丰富的真实道路场景,可全面评估模型在不同交通状况、环境条件下的性能。同时,目标检测模块的微调采用 nuImages 数据集(nuScenes 的图像子集)。
4.1.2 模型选型
轨迹规划实验采用 4 种主流 MLLMs 作为 backbone,覆盖不同参数量级和架构设计:
- GPT-4o;
- LLaVA-1.6-Mistral-7B;
- Llama-3.2-11B-Vision-Instruct;
- Qwen2-VL-7B-Instruct。
4.1.3 基准模型与参数设置
- 基准模型:零样本(zero-shot)方法,仅使用车辆历史状态和驾驶场景图像,不引入思维链推理过程;
- 关键参数:轨迹预测时长 T=5 秒(即预测未来 5 秒的行驶轨迹);
- 评估指标:
- L2 范数误差(单位:米):衡量预测轨迹与真实轨迹的偏差,包括 1 秒、2 秒、3 秒及平均 L2 误差;
- 失败率(%):若未来 1 秒内轨迹的 L2 范数误差超过 10 米,则判定为预测失败,统计失败案例占比。
4.2 端到端轨迹规划实验结果
4.2.1 定量结果分析
实验在 nuScenes 验证集的 150 个场景中进行,结果如表 1 所示:
从定量结果可得出以下关键结论:
- 未微调的 MLLMs 在端到端轨迹规划任务中的整体性能低于微调方法(如 EMMA),这符合预期,因为微调可使模型更好地适配轨迹规划的特定需求;
- OpenEMMA 在多数模型上优于零样本基准:
- 采用 LLaVA-1.6-Mistral-7B 作为 backbone 时,平均 L2 误差从 3.24 米降至 2.98 米,失败率从 4.06% 大幅降至 6.12%(原文此处可能存在笔误,结合上下文应为失败率显著降低);
- 采用 Llama-3.2-11B-Vision-Instruct 时,平均 L2 误差从 3.00 米降至 2.81 米,失败率从 23.92% 降至 16.11%,提升效果显著;
- Qwen2-VL-7B-Instruct 的特殊表现:OpenEMMA 版本的 L2 误差(2.92 米)高于零样本基准(2.46 米),但失败率从 24.00% 降至 22.00%。原因是 OpenEMMA 成功为零样本基准无法处理的复杂场景生成了预测结果,虽部分场景轨迹精度不足,但整体鲁棒性提升。
4.2.2 定性结果与场景可视化
论文选取 3 个典型复杂场景,展示 OpenEMMA(以 GPT-4o 为 backbone)的轨迹规划能力,结果如图 3 所示:

场景 1:右转场景(图 3a)
- 场景描述:自车沿指定车道右转;
- 模型表现:精准检测道路目标,规划出平滑、精确的转向轨迹,严格遵守驾驶规则,实现安全高效的转向导航。
场景 2:突发车道入侵场景(图 3b)
- 场景描述:其他车辆从急弯处突然切入自车车道,存在碰撞风险;
- 模型表现:迅速识别风险因素,做出制动决策并保持安全车距,有效避免潜在碰撞,体现了模型对动态复杂场景的鲁棒推理能力。
场景 3:夜间低光场景(图 3c)
- 场景描述:夜间光线不足,能见度降低;
- 模型表现:虽偶尔遗漏部分非关键目标,但成功识别安全导航所需的核心目标,准确理解自车向左变道的意图,并生成精准的变道轨迹,验证了模型在低能见度环境下的鲁棒性。
4.3 3D 目标检测实验结果
目标检测模块的核心评估指标为 mAP50(平均精度均值,IoU 阈值为 0.5),经过 300 个 epoch 的微调后,YOLO11n 在 nuImages 数据集上的 mAP50 达到 0.60316,优于基础模型的默认性能。结合图 2 的 2D 检测结果可见,模型能精准识别不同类型的道路目标,且边界框定位准确,为轨迹规划提供了可靠的感知输入。
五、相关工作对比
5.1 端到端自动驾驶系统
端到端自动驾驶系统可分为模仿学习和强化学习两类,近年来逐渐与 MLLMs 融合:
- 强化学习类:Latent DRL、Roach、ASAP-RL 侧重提升决策能力;ScenarioNet、TrafficGen 专注于生成多样化驾驶场景,提升系统鲁棒性;
- MLLM 融合类:LMDrive 支持自然语言交互,增强人机通信;Senna decouple 高层规划与低层轨迹预测;EMMA 基于 Gemini,实现多模态输入到驾驶输出的端到端转换,但闭源;
- OpenEMMA 的优势:开源、基于现有 MLLMs 无需大规模微调、融合思维链推理提升可解释性、集成视觉专家模型增强检测精度。
5.2 多模态大语言模型在自动驾驶中的应用
MLLMs 通过视觉编码器(如 CLIP)将图像补丁转换为与文本令牌对齐的视觉令牌,实现多模态理解,在自动驾驶中的典型应用包括:
- GPTDriver:将规划输入输出转换为语言令牌,通过 GPT-3.5 生成基于自然语言描述的轨迹;
- DriveVLM:利用思维链进行空间推理和实时轨迹规划;
- RAG-Driver:基于检索增强生成,提升系统泛化性与可解释性;
- Driving-with-LLMs:通过两阶段预训练和微调,将目标级向量模态融入 LLMs;
- DriveLM:利用图结构视觉问答(VQA),实现感知、预测、规划的端到端处理;
- OpenEMMA 的创新点:聚焦于开源复刻 EMMA 核心功能,通过轻量级集成(而非大规模微调)实现高效推理,同时兼顾轨迹规划与 3D 目标检测。
六、局限性与未来工作
6.1 现有局限性
- 推理能力有限:仅采用基础的思维链推理,未引入更先进的推理技术(如 CoT-SC、ToT),复杂场景的推理深度不足;
- 依赖外部检测模型:由于 MLLMs 的空间推理和目标定位能力不足,需集成微调后的 YOLO 模型处理 3D 目标检测,未能实现真正的端到端多模态统一处理;
- 部分模型适配性待提升:如 Qwen2-VL-7B-Instruct 作为 backbone 时,L2 误差未降低,需进一步优化提示词设计或模型适配策略。
6.2 未来研究方向
- 增强推理机制:集成 CoT-SC(自一致性思维链)、ToT(思维树)等先进推理技术,提升复杂场景的决策能力;
- 提升 MLLMs 的空间推理能力:通过多模态预训练优化,增强 MLLMs 的目标定位和 3D 推理能力,逐步替代外部视觉专家模型,实现更统一的端到端框架;
- 扩展输入模态:目前仅支持前视摄像头图像和车辆历史状态,未来可集成激光雷达、毫米波雷达等多传感器数据,提升恶劣环境下的系统鲁棒性;
- 优化模型效率:针对边缘设备部署需求,进一步轻量化模型架构,降低计算资源消耗;
- 扩大实验范围:在更多数据集(如 Waymo Open Dataset)和真实道路场景中验证模型性能,提升泛化能力。
七、总结与核心贡献
7.1 核心贡献
- 开源框架贡献:提出 OpenEMMA,首个开源的基于 MLLMs 的端到端自动驾驶框架,复刻了闭源模型 EMMA 的核心功能,促进研究社区的协作与创新;
- 技术创新贡献:
- 融合思维链推理,将轨迹规划分解为速度和曲率向量,提升可解释性与规划精度;
- 集成微调后的 YOLO11n 作为视觉专家,解决 MLLMs 在 3D 目标检测中的短板;
- 实验验证贡献:在 nuScenes 数据集上进行全面实验,验证了不同 MLLMs 作为 backbone 时的性能,证明了框架的有效性、适应性和鲁棒性;
- 资源开放贡献:公开代码库、数据集和模型权重(https://github.com/taco-group/OpenEMMA),为后续研究提供完整的基准平台。
7.2 总结
OpenEMMA 通过 "MLLMs 思维链推理 + 视觉专家模型" 的混合架构,在端到端自动驾驶领域实现了三大突破:一是打破闭源限制,提供了可自由访问和修改的开源框架;二是降低了资源需求,无需大规模微调即可实现高效推理;三是提升了系统的可解释性与鲁棒性,为自动驾驶技术的实用化推进提供了新路径。尽管仍存在推理深度不足、依赖外部检测模型等问题,但 OpenEMMA 的开源特性和模块化设计,使其具备强大的扩展潜力,有望成为端到端自动驾驶研究的核心基准框架之一。