上一章节我们讲述了窗口函数的概述、语法和窗口聚合函数,如链接:
HIVE的Window functions窗口函数【一】本文我们将讲解窗口表达式、窗口排序函数、窗口分析函数
文章目录
- [1. 窗口表达式](#1. 窗口表达式)
- [2. 窗口排序函数](#2. 窗口排序函数)
- [3. 窗口分析函数](#3. 窗口分析函数)
1. 窗口表达式
我们知道,在sum(...) over( partition by... order by ... )语法完整的情况下,进行的累积聚合操作,默认累积聚合行为是:从第一行聚合到当前行。
Window expression窗口表达式给我们提供了一种控制行范围的能力,比如向前2行,向后3行。
语法如下:
关键字是rows between,包括下面这几个选项
- preceding:往前
- following:往后
- current row:当前行
- unbounded:边界
- unbounded preceding 表示从前面的起点
- unbounded following:表示到后面的终点
sql
---窗口表达式
--第一行到当前行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between unbounded preceding and current row) as pv2
from website_pv_info;
--向前3行至当前行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between 3 preceding and current row) as pv4
from website_pv_info;
--向前3行 向后1行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5
from website_pv_info;
--当前行至最后一行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between current row and unbounded following) as pv6
from website_pv_info;
--第一行到最后一行 也就是分组内的所有行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between unbounded preceding and unbounded following) as pv6
from website_pv_info;2. 窗口排序函数
窗口排序函数用于给每个分组内的数据打上排序的标号。注意窗口排序函数不支持窗口表达式。总共有4个函数需要掌握:
row_number:在每个分组中,为每行分配一个从1开始的唯一序列号,递增,不考虑重复;
rank:在每个分组中,为每行分配一个从1开始的序列号,考虑重复,挤占后续位置;
dense_rank:在每个分组中,为每行分配一个从1开始的序列号,考虑重复,不挤占后续位置;
示例:
sql
-----窗口排序函数
SELECT
cookieid,
createtime,
pv,
RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn1,
DENSE_RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn2,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn3
FROM website_pv_info
WHERE cookieid = 'cookie1';结果如下:
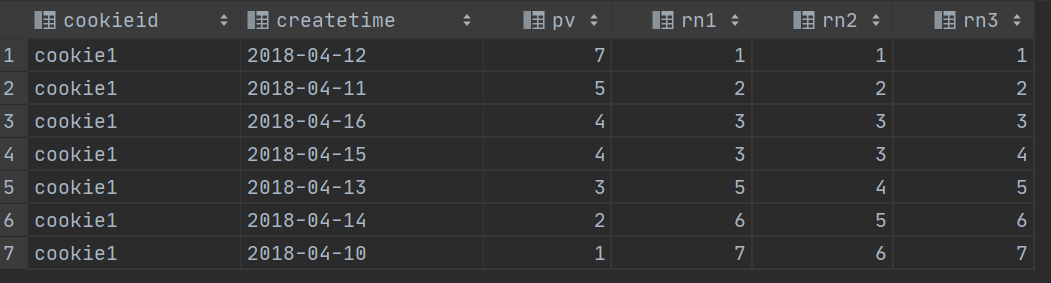
上述这三个函数用于分组TopN的场景非常适合。
sql
--需求:找出每个用户访问pv最多的Top3 重复并列的不考虑
SELECT * from
(SELECT
cookieid,
createtime,
pv,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS seq
FROM website_pv_info) tmp where tmp.seq <4;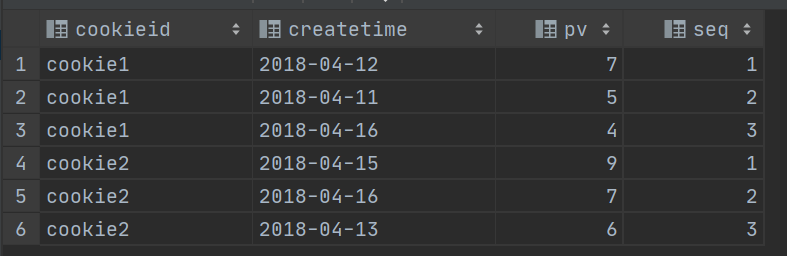
ntile函数,其功能为:将每个分组内的数据分为指定的若干个桶里(分为若干个部分),并且为每一个桶分配一个桶编号。
如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1。
有时会有这样的需求:如果数据排序后分为三部分,业务人员只关心其中的一部分,如何将这中间的三分之一数据拿出来呢?NTILE函数即可以满足。
sql
--把每个分组内的数据分为3桶
SELECT
cookieid,
createtime,
pv,
NTILE(3) OVER(PARTITION BY cookieid ORDER BY createtime) AS rn2
FROM website_pv_info
ORDER BY cookieid,createtime;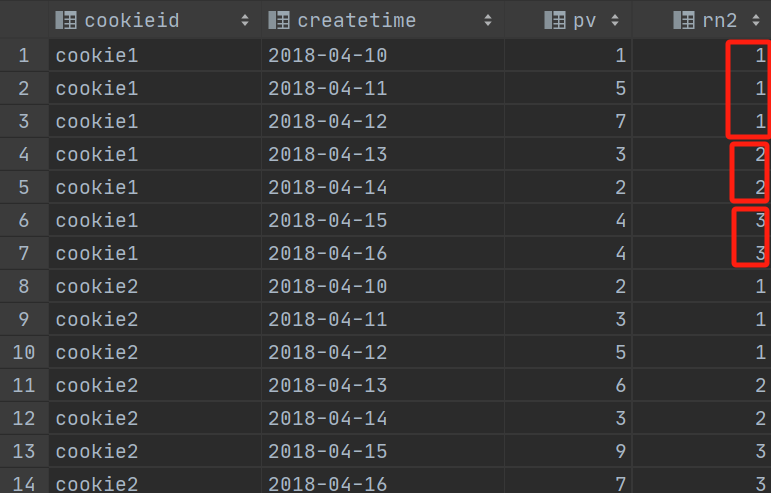
sql
--需求:统计每个用户pv数最多的前3分之1天。
--理解:将数据根据cookieid分 根据pv倒序排序 排序之后分为3个部分 取第一部分
SELECT * from
(SELECT
cookieid,
createtime,
pv,
NTILE(3) OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn
FROM website_pv_info) tmp where rn =1;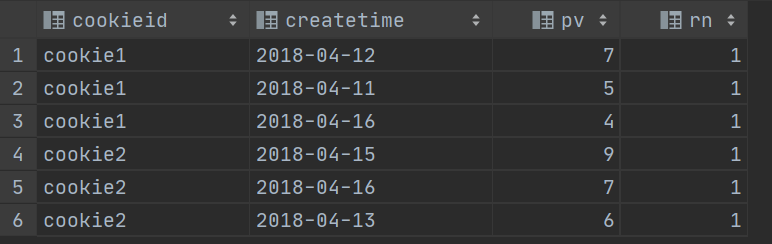
3. 窗口分析函数
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL);
LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值
第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL);
FIRST_VALUE 取分组内排序后,截止到当前行,第一个值;
LAST_VALUE 取分组内排序后,截止到当前行,最后一个值;
下面我们分别举例
sql
select cookieid,
url,
createtime,
lag(createtime,1,'1970-01-01 00:00:00') over() as lag_win
from website_url_info
where cookieid = 'cookie1';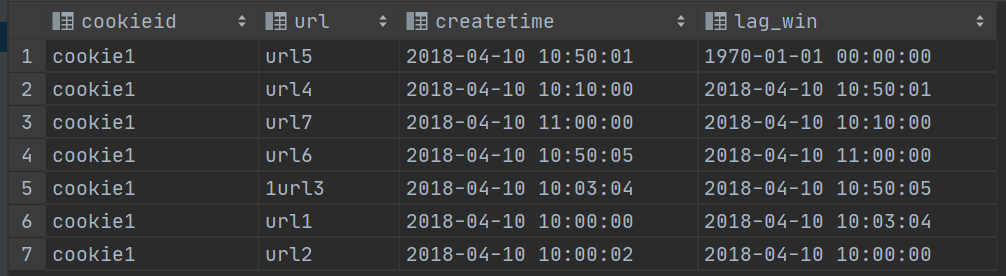
sql
select cookieid,
url,
createtime,
lead(createtime,1,'1970-01-01 00:00:00') over() as lead_win
from website_url_info
where cookieid = 'cookie1';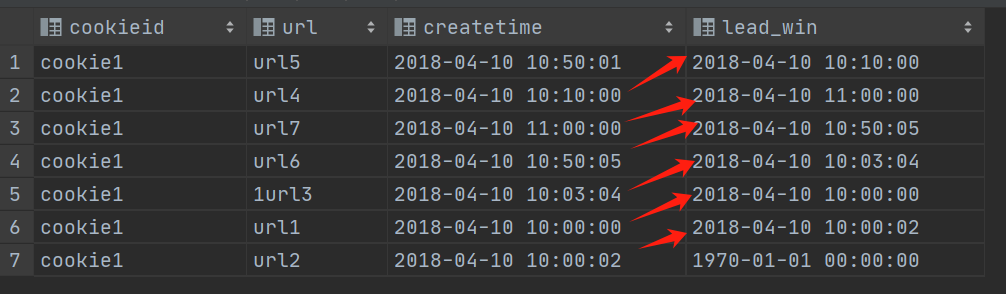
sql
select cookieid,
url,
createtime,
first_value(createtime) over() as fv
from website_url_info
where cookieid = 'cookie1';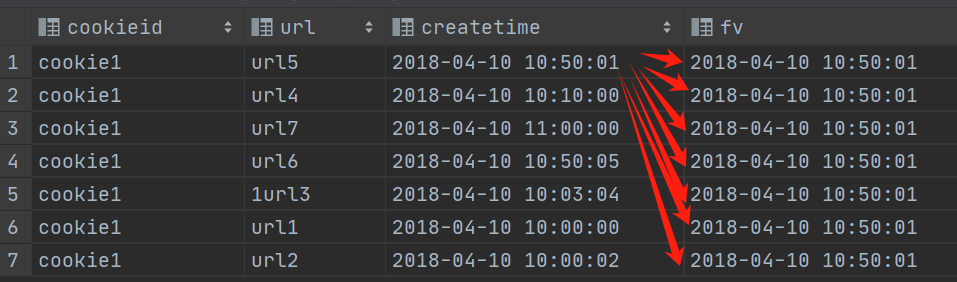
sql
select cookieid,
url,
createtime,
last_value(createtime) over() as lv
from website_url_info
where cookieid = 'cookie1';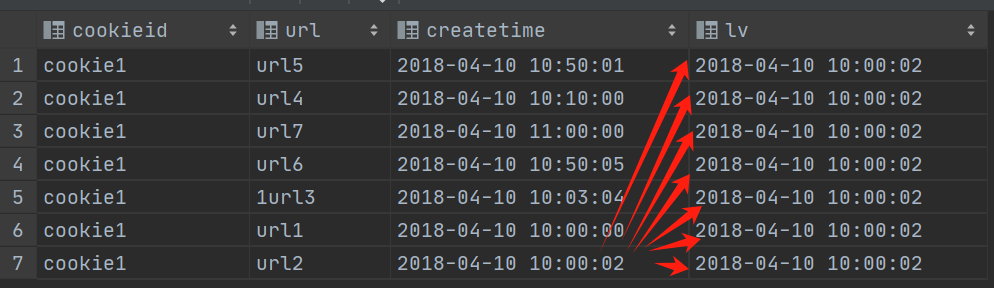

如果有帮助到你,请点赞收藏