01 概览
随着数字化转型的来临,企业对于数据服务的实时化需求日益增长,在大规模数据和复杂场景的情况下,Flink在实时计算数据链路中扮演着极为重要的角色,本文介绍了网盘如何通过 Flink 构建实时计算引擎,从而提供高性能、低延迟、稳定的实时计算能力。
02 百度网盘实时计算演进
2.1 百度网盘实时计算演进历程
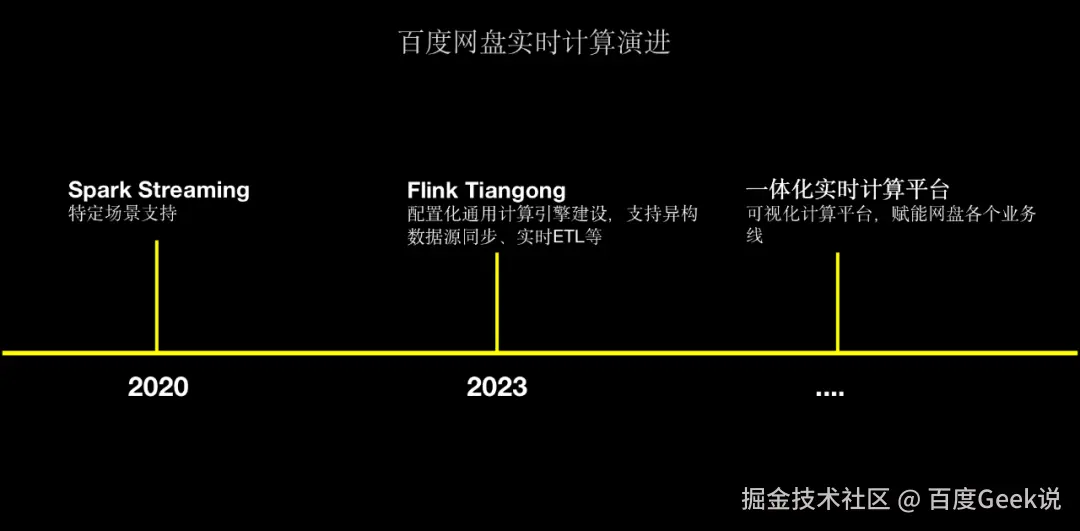
△百度网盘实时计算演进
在 2020 年,网盘主要通过Spark Streaming和Spark Structured Streaming来用于特定场景的支持,主要是在数据同步场景、实时清洗方面的应用。
为了解决Spark Streaming存在的监控告警薄弱、接入成本高、时效性低等问题,网盘于2023年初首次引入Flink实时计算引擎,并基于百度内部StreamCompute平台快速建设集指标监控、告警、任务生命周期管理能力;经过调研测试我们发现Flink任务从0到1接入成本高、开发门槛高,因此,我们开始调研实时计算引擎的解决方案,目标是降低开发门槛、配置化任务接入,最终建设网盘内部的实时计算引擎Tiangong来为业务提供更好的支持。
截止至今,Tiangong计算引擎目前已在数据团队、反作弊团队、用户增长等场景广泛应用,并支持数百万亿的大流量场景。未来我们也计划将基于Tiangong建设网盘一体化实时计算平台,从而赋能网盘内部各个业务线实时计算能力建设。
2.2 为什么选择Flink
网盘实时计算引擎从Spark Streaming和Spark Structured Streaming演进而来,为什么放弃Spark体系选择Flink主要从以下几个方面出发:
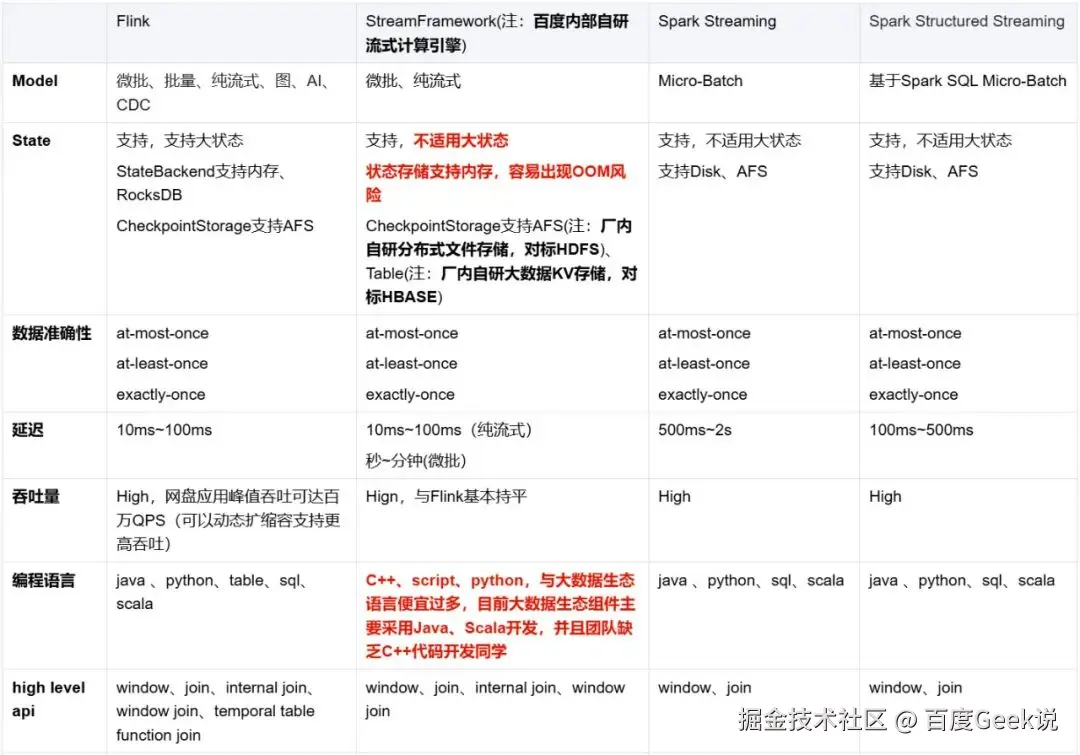
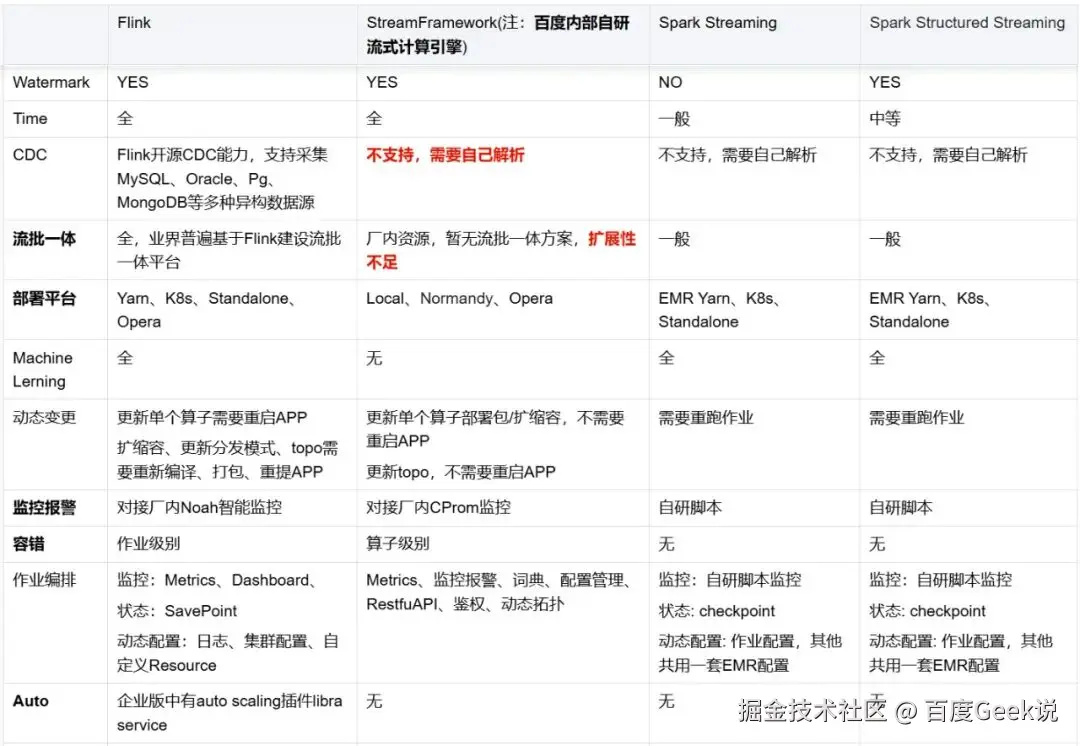

从百度内部实时计算RoadMap和状态管理、流批一体、监控告警、任务管理、生态体系等各方面我们选择基于Flink建设网盘内部的实时计算平台。
2.3 实时计算引擎
2.3.1 实时计算引擎接入现状
目前,百度网盘的Tiangong计算引擎已接入17+应用场景 ,高峰时作业处理的吞吐量达到千万/s ,而机器规模也已经达到了1500台,资源5800CU,并且已经覆盖用商策略、反作弊、主端一刻用增实时投放等多个场景。
2.3.2 Flink Tiangong引擎架构
如下图所示的是网盘Tiangong实时计算引擎的架构。
-
最下层为Runtime层,负责Tiangong计算任务的部署方式,目前支持StreamCompute、Kubernetes、Yarn、Local等方式;
-
核心能力包括Source组件 、Sink组件 以及数据转换引擎
-
Source组件:支持Db、Message Queue、BigData组件、自定义Source等多个异构数据源;
-
Sink组件:支持Db、Message Queue、BigData组件、自定义Sink等多个异构数据目的地;
-
数据转换引擎:支持流批一体、自定义配置化数据清洗、精准一次数据处理、失败容错、IOC容器化管理、自定义SQL拓扑、灵活监控告警等能力;
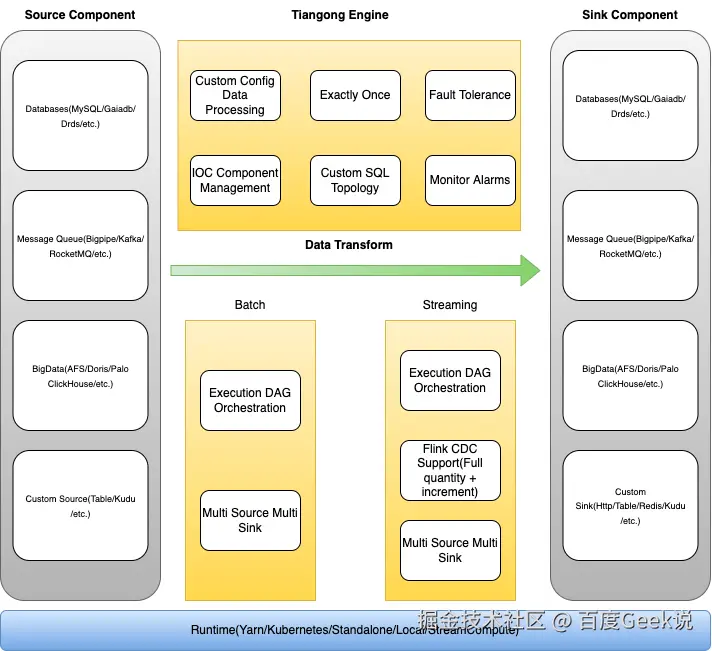
△ Tiangong计算引擎
从功能层面来看,Tiangong实时计算引擎主要包括作业管理和资源管理。其中,作业部分包括作业配置、作业上线以及作业生命周期管理三个方面的功能。
- 在作业配置方面,则包括运行环境配置、source配置、sink配置、清洗逻辑配置以及作业拓扑结构设置;
bash
{
"jobName": "作业名",
"env": {运行环境配置},
"sources": [source端配置],
"udfs": [用户定义函数],
"views": [清洗逻辑],
"coreSql": [核心写入逻辑],
"sinks": [sink端配置],
"customTopology": {自定义作业运行拓扑}
}- 在作业发布方面,则包括作业启动、取消以及删除等;
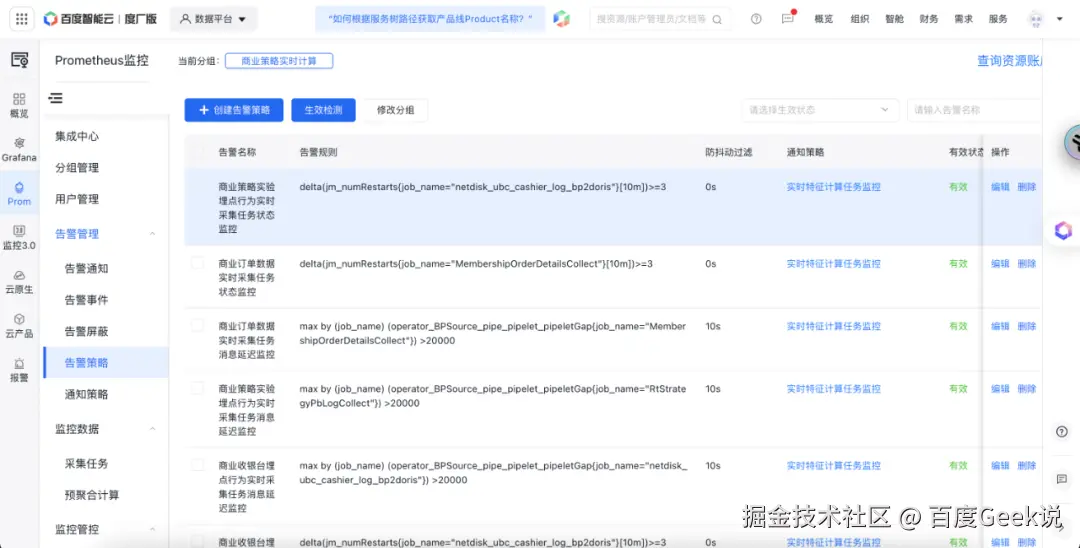
- 作业状态则包括自定义规则告警、监控大盘等;

△ 自定义规则告警
△ 监控大盘
- 在资源管理方面,利用StreamCompute平台能力支持Flink集群动态扩缩容能力与灰度发布能力;
2.4 业务场景实践
前面提到实时计算引擎演进过程和实时计算引擎对比,可以看出网盘实时计算引擎更多地会关注在易用性、稳定性和监控告警体系等方面,具体体现的应用场景主要涉及服务端日志、埋点日志、DB Binlog等场景的实时清洗计算。
2.4.1 网盘实时商业BI中心
网盘现阶段缺乏商业收入数据实时分析与商业策略实验实时评估的能力,导致商业策略AB实验推全链路往往需要经过周粒度才能完成,建设一套适用于网盘的实时商业BI中心有益于加快策略实验迭代与实时商业流水波动分析,助力网盘整体收入增长;
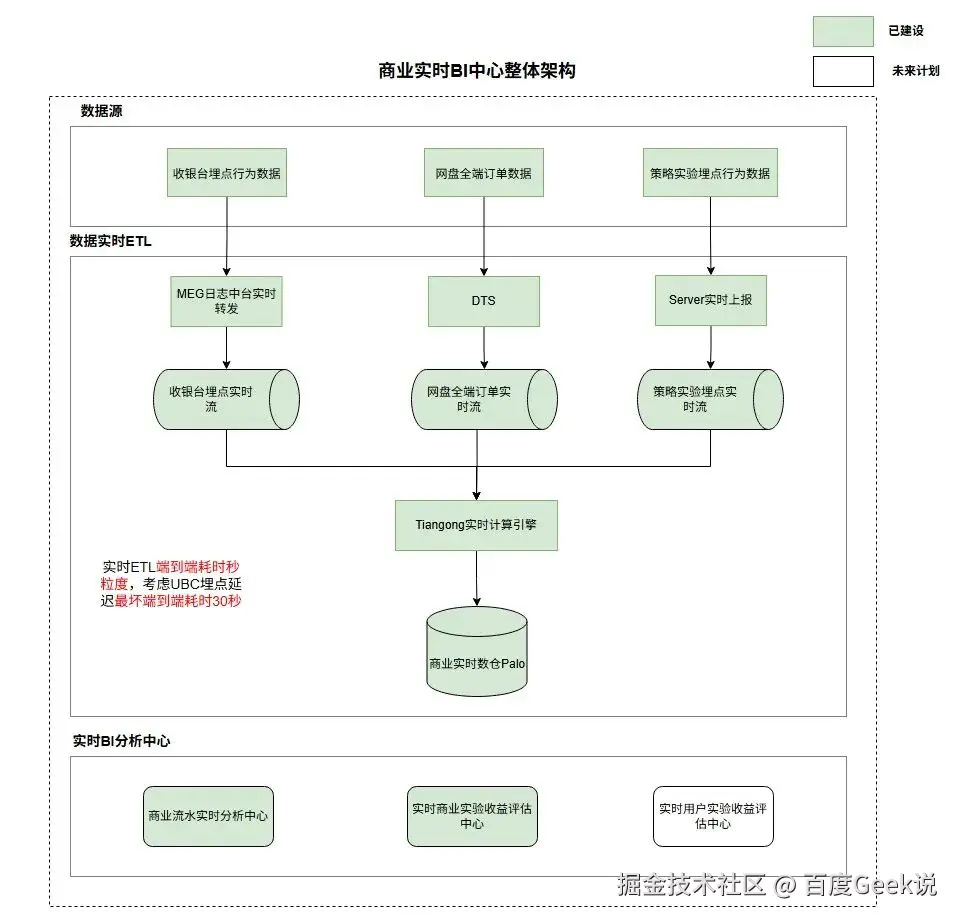
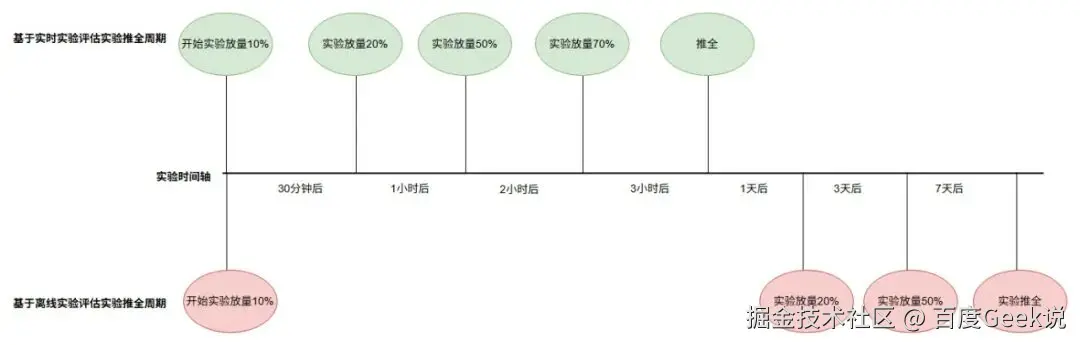
如上图,通过将收银台行为、商业订单、策略实验埋点数据秒粒度接入至实时数仓Palo中后,配合数据可视化平台Sugar建设商业实时BI中心,以此来助力商业策略、商业PM等各个角色快速完成AB实验快速推全,将天粒度实验收益评估机制优化至分钟粒度,整体实验推全链路由周粒度优化至天粒度;
2.4.1.1 Tiangong配置化接入
下述案例为Tiangong引擎配置化接入商业订单实时流:
- 实时流数据源配置
json
{
"sourceType": "bp_source",
"deserializerType": "STRING",
"sourceConfig": {
"parallelism": 20,
"operatorName": "xietong_strategy_businessorder_fr_bp_source",
"metaHost": "host:ip",
"cluster": "demo-cluster",
"username": "username",
"password": "password",
"pipeletName": "demo-pipelet-name",
"pipeletNum": "20",
"startingOffset": {},
"startPoint": "LATEST",
"endOffset": {},
"bpWebServiceAddress": "service_address"
}- 核心处理逻辑配置
bash
{
"jobName": "netdisk_membership_order_deatils_bp2doris",
"env": {
"streamConfigName": "20p_ck_3s_10fail_env", ## 环境配置,主要配置Checkpoint间隔和并行度,根据数据量定义,一般为上游消息队列分区倍数
"tableConfig": {}
},
"sources": [
{
"configType": "CONFIG",
"sourceTableName":"membership_order_binlog", ## 数据源配置,bigpipei订单实时流
"sourceConfig": "prod/netdisk_membership_order_bp_source"
},
{
"configType": "SQL",
"sourceConfig": "CREATE TABLE ods_order_info_rt ## 写入目的地配置,palo写入表
(
id bigint,
order_no string,
user_id bigint,
dev_uid bigint,
app_id bigint,
client_channel tinyint,
pay_channel tinyint,
product_id string,
....
) WITH (
'connector' = 'doris',
'fenodes' = 'host:ip',
'table.identifier' = 'dbName:tableName',
'username' = 'username',
'password' = 'password',
'sink.properties.format' = 'json',
'sink.properties.read_json_by_line' = 'true',
'sink.label-prefix' = 'label-prefix',
'sink.enable-2pc'='true',
'sink.parallelism' = '1'
)"
}
],
"views": [
{
"name": "binlog_filter_view", ## 核心数据处理逻辑,纯SQL接入
"sql": "select CAST(JSON_VALUE(new_values, '$.id') as bigint) as id,
JSON_VALUE(new_values, '$.business_no') as business_no,
JSON_VALUE(new_values, '$.order_no') as order_no,
UNIX_TIMESTAMP() as write_timestamp,
.....
FROM membership_order_binlog,
LATERAL TABLE(BINLOG_NEWVALUES_FILTER(f0))" ## 系统内置Binlog清洗TableFunction
}
],
"coreSql": "insert into ods_order_info_rt select id, ## 写入下游palo表,写入间隔为Checkpoint间隔,上述配置为3秒,每3秒写一批
business_no,
order_no,
user_id,
write_timestamp from binlog_filter_view"
}2.4.1.2 可视化监控体系
Flink作业UI监控
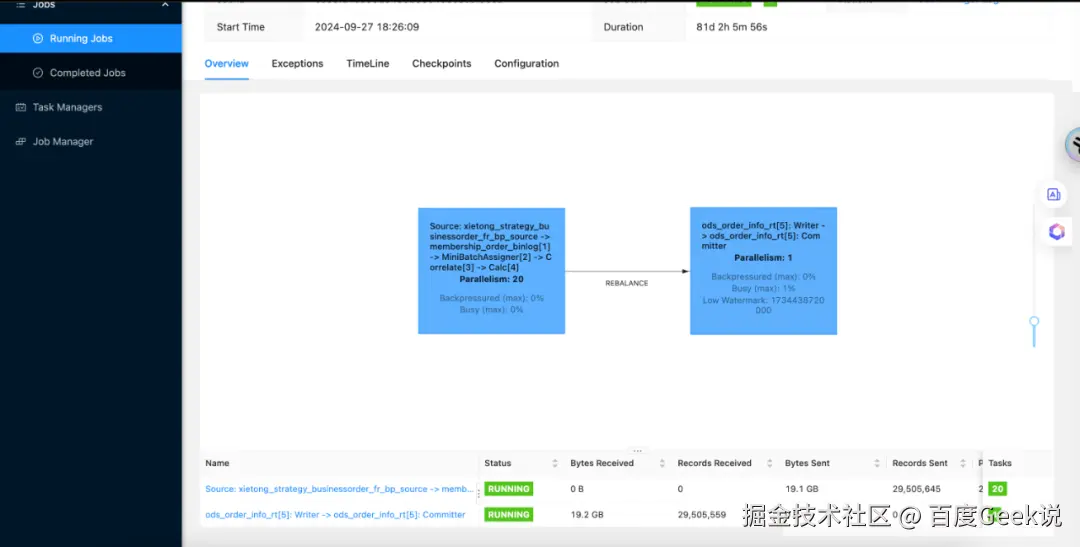
Grafana监控大盘
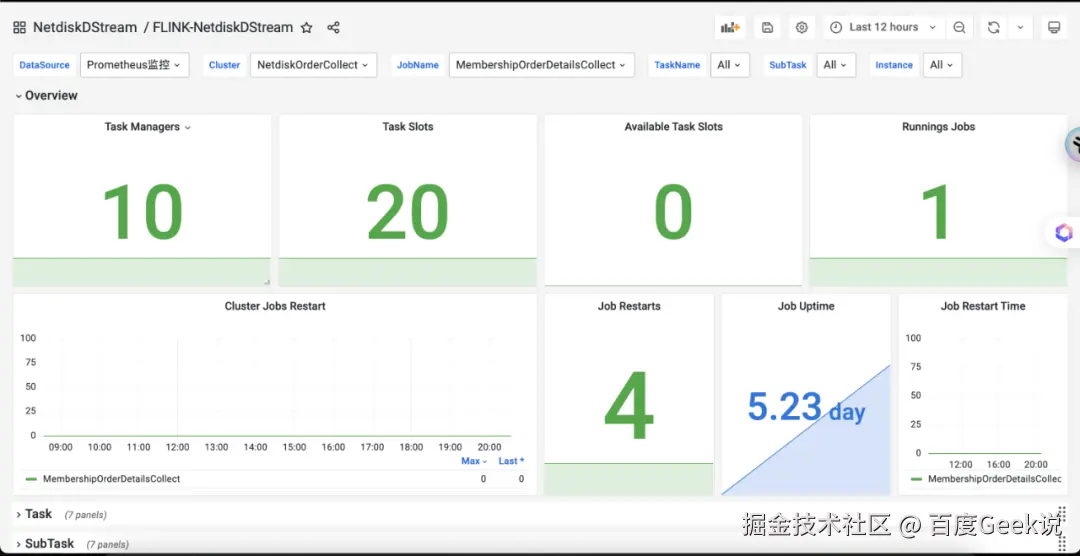
实时任务监控配置
2.4.2 用户商业策略实时特征
基于商业策略实时核心行为相关特征依赖场景,结合核心行为以及用户付费埋点行为数据建设从0点实时累计特征与基于滚动窗口的近X分钟实时特征有助力策略侧对用户刚需需求的感知,并结合用户刚需行为个性化出价以此促进整体商业收入。
2.4.2.1 核心方案
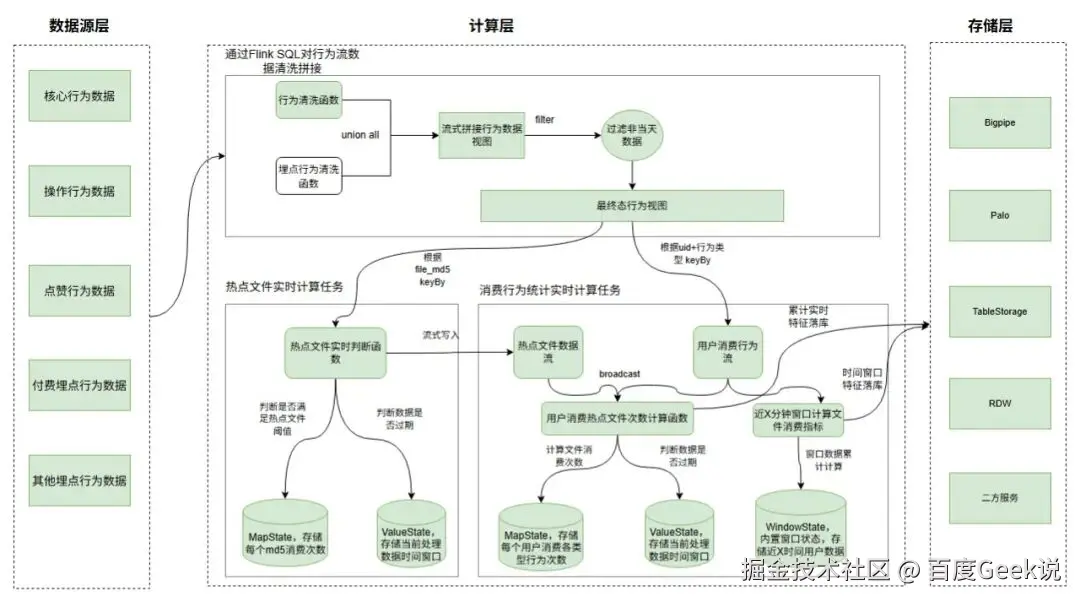
-
如上图,方案二主要将数据流拆为三块,如流数据拼接、热点文件计算、消费行为统计;
-
流数据拼接:利用Tiangong计算引擎,通过Flink SQL+行为清洗UDF函数,将各类行为数据打平为统一格式,并通过union all进行聚合,过滤异常数据后行为行为视图,数据流式产出。
-
热点文件计算:实时将各个file_md5的消费次数存储Flink Map状态中,并根据离线分析得到的热点文件消费阈值判断热点文件,将热点文件流式写入Bigpipe与Palo中,数据流式产出,最优可做到毫秒级;
-
消费行为次数计算:根据热点文件数据流关联用户消费行为,实时对用户消费的文件进行热点/普通归一化处理,后续将每个用户消费不同行为类型的热点/普调次数写入Flink Map状态中,累加计算从0点至今的文件消费次数,实时写入Doris和Palo中,最优可做到秒级;
2.4.2.2 技术难点
(1)大状态问题
问题引入
-
热点文件和用户消费文件次数的计算,都涉及到数据累计的问题,如果将数据存储在共享存储(例如Redis/Table)这类kv存储中,每条数据或每个窗口的数据都需要先查一下上次的计算结果,累加后再写入共享存储中,这从而导致每次计算多一次网络读IO操作,故利用Flink状态机制,将热点文件和用户消费次数存储在Flink状态中,每次判断都在TaskManger本地或者内存中,不涉及到网络IO操作,故性能更好。
-
数据都存入Flink状态中也导致Flink存在大状态问题,从而导致Checkpoint耗时过大从而引起任务背压,最终导致数据处理延迟等问题。
解决方案
状态后端优化
-
选择Rocksdb作为状态后端,开启增量Checkpoint
-
配置changelog状态机制,防止Rocksdb定期Compaction导致的Checkpoint耗时久问题
-
调整rocksdb manged内存大小、rocksdb write buffer大小
快照存储优化
- 开启快照压缩配置
状态TTL机制
- 长期为更新的状态做小时粒度更新,防止状态持续增大。
(2)TableStroage写入性能差
问题引入
- 因厂内Table API创建Table Client过程中需要根据特定表对应的机器数创建对应个数的brpc-client-work-thread、brpc-client-io-thread、fairStrategy-timer-thread等线程,共计3*机器数个,网盘特征Table存储底层表占用200台机器,故创建一个Table Client需要创建600+线程,从而导致Flink计算节点的底层martix容器线程超限,经过和StreamCompute同学沟通需限制Table Client的Rpc线程数为1,并对应Flink集群的计算节点容器最大线程数由1000->1500,从而解决线程超限问题。但因限制Table Client Rpc线程为1导致Table整体写入性能偏差。
解决方案
- 细粒度拆分任务,首先对用户各类行为以及消费的热点/普调资源进行实时计算,后续根据user_id+行为类型keyby,并开3s窗口,取最新的数据落入Table,将3s一个窗口的数据进行压缩。
优化效果
- 原本天粒度写入48亿+次行为特征优化为2亿+次,具体效果如下图:

业务场景大致可以分为实时数仓、实时数据复杂聚合计算、DB业务数据CDC等场景,在这几个场景Flink本身就提供高性能、高稳定性的能力,再配合网盘Tiangong实时计算引擎不熟悉Flink的业务方也可以配置化、低代码的方式快速建设起实时应用。
03 Flink技术挑战和解决方案
3.1 Flink底座建设

△ Flink基建建设
基于StreamCompute平台提供的动态扩缩容、任务生命周期管理、Flink多版本管理、云原生监控告警体系等能力,来快速构建网盘Flink实时计算能力。
3.2 实时计算平台建设

△ Tiangong计算引擎
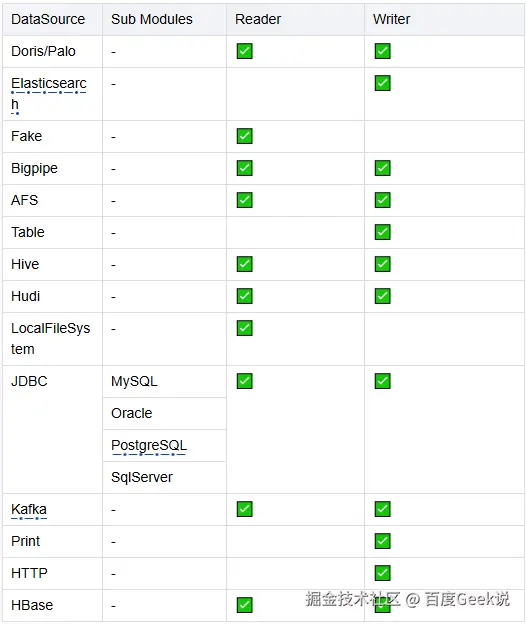
以上为Tiangong计算引擎能力支持,其作为网盘实时计算平台支持目前厂内大部分异构数据源,使用方可以通过简单的配置快速建设实时计算能力,拿上述业务场景实践中的用户商业策略实时特征项目接入Tiangong来看,只需下述配置和少量窗口数据聚合逻辑开发即可:
python
{
"jobName": "business_feature_compute_bp2table", // 作业名
"env": { // 作业运行环境配置
"streamConfigName": "300p_ck_30s_5fail_env",
"tableConfig": {
"stateTtlMs": 600000
}
},
"sources": [ // source配置,download日志
{
"configType": "CONFIG",
"sourceTableName": "idc_log_source",
"sourceConfig": "prod/business_strategy_idc_bp_source"
}
],
"udfs":[ // 数据清洗转换逻辑,SQL无法完成时通过UDF
{
"name": "idc_log_filter_func",
"className": "com.baidu.xxx.IdcLogFilterFunction"
},
{
"name": "idc_feature_transform_func",
"className": "com.baidu.xxx.IdcFeatureTransformFunction"
}
],
"views": [
{
"name": "idc_log_feature_view",
"sql": "select feature_data.event_time as event_time,
.....
from (select idc_feature_transform_func(f0) as feature_data
from idc_log_source
where idc_log_filter_func(f0) = true) as tmp
where feature_data.log_time <> '0' and ....
}
],
"sinks": [ // 双写TableStorage、Doris
{
"sinkConfigNames": ["prod/netdisk_strategy_idc_feature_mi_table_sink","prod/netdisk_strategy_feature_doris_sink"],
"transformSQL": "select event_time,
.....
from idc_log_feature_view",
"watermarkConfig":{ // 涉及开窗逻辑所涉及的watermark配置
"maxOutOfOrdernessMs": 5000,
"idlenessMs": 10000,
"timeAssignerFunctionName": "row_event_time_assigner"
},
// 开窗计算逻辑函数
"rowTransformFunc": "strategyFeatureTransformFunction"
}
]
}
}3.3 自定义作业执行计划
3.3.1 细粒度算子并行度优化
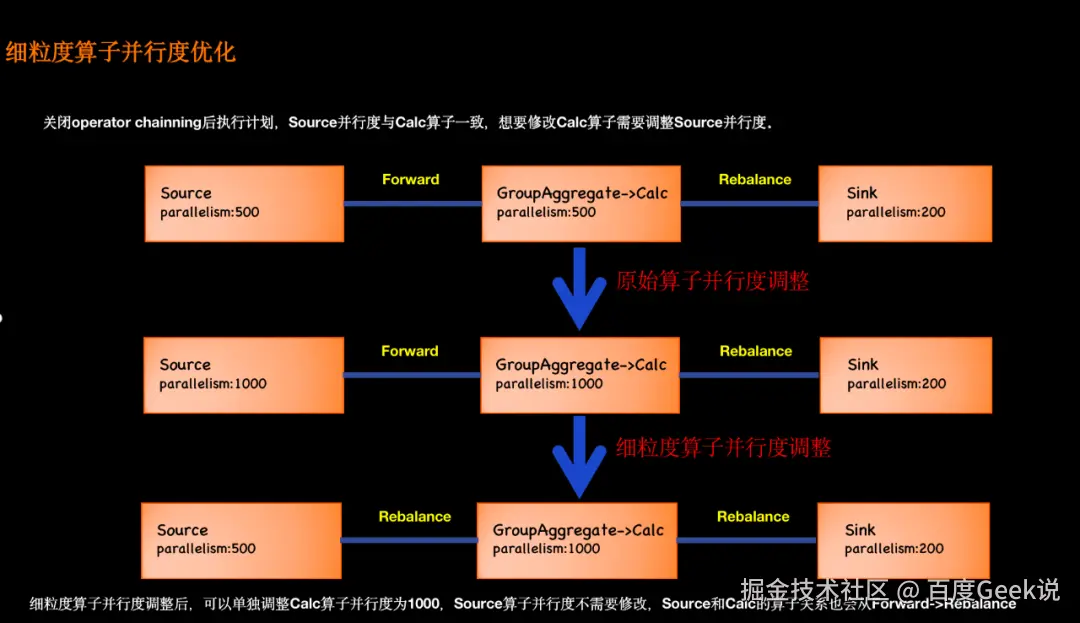
△ 细粒度算子并行度优化
Tiangong计算引擎本质基于 Flink SQL+Table API+DataStream API做的混合计算引擎,其本质相当于 Flink SQL,因此一旦定义好Source和Sink并行度后,其任务所涉及的计算、清洗、聚合等算子都与Source端并行度一致,从而导致如果想要增加清洗等算子的并行度需要把Source的并行度也增加,从而造成资源浪费、性能降低等问题。
3.3.2 分区关系优化

△ 分区关系优化
作业内上下游算子连接数过多,会占用较大的 Network buffer 内存,从而影响作业的正常启停,基于自定义SQL执行计划能力,我们可以手动将 Rebalance 边修改为 Rescale。
比如上图的示例,左边上游算子有 500 个并发,而下游的 Sink 算子只有 200 个并发。在这种场景下,Flink SQL 会默认生成 Rebalance 的连接方式,共需 500*200,共 10 万个逻辑连接。
通过自定义SQL执行计划能力,我们手动将 Rebalance 设置为 Rescale 后,它只需要 500 个连接,大大降低了 Network buffer 的内存需求。
3.3.3 资源共享策略优化
3.3.3.1 资源共享
-
默认情况下,flink允许subtask共享slot,即使是不同task的subtask,这样的结果是一个slot可以保存作业的整个管道。
-
如果是同一步操作的并行subtask需要放到不同的slot,如果是先后发生的不同的subtask可以放在同一个slot中,实现slot的共享。
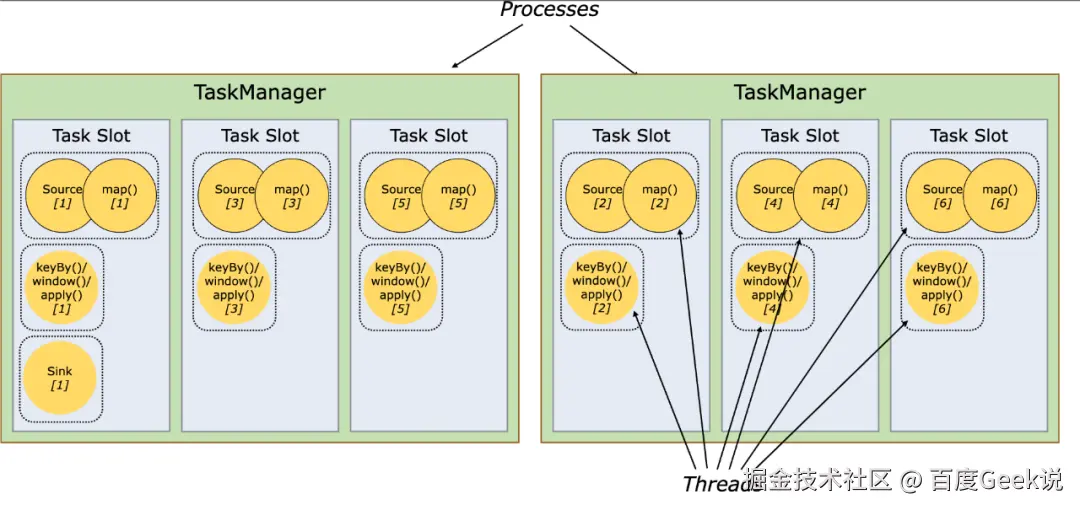
△ Slot与Task的关系
3.3.3.2 自定义共享策略
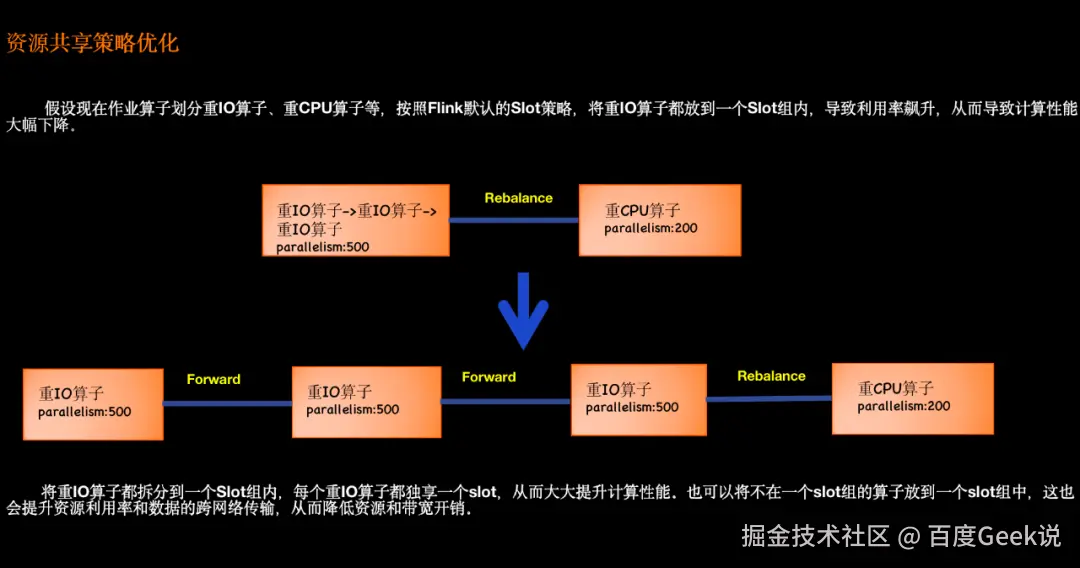
△ 资源共享策略优化
支持按照算子类型将算子划分到一个slot group中,从而来减少数据的跨网络传输、提升资源利用率以及提升计算性能等。
3.3.4 算子名称优化
Flink SQL不支持为每个算子自定义名称,从而导致算子名是根据系统规则来生成的,从而导致算子名称不能够通俗的表示其具体含义。为了便于作业维护和管理,自定义作业执行计划支持算子名称优化。
04 未来展望
△ 未来展望
4.1 实时计算平台化
目前Tiangong计算引擎的使用方式主要在公共代码库提交任务配置和UDF代码 的方式接入,使用方需要拥有Tiangong计算引擎的代码库权限 ,存在代码安全和任务隔离性差等问题,后续我们计划基于Tiangong计算引擎搭建网盘自己的实时化计算平台,实现页面低代码方式快速接入实时任务。
4.2 实时DTS平台
目前网盘主要使用厂内DTS平台,通过增量binlog和全量select快照方式采集数据至下游AFS,整体链路为DTS->AFS->UDW,一旦上游表格式变化下游的采集任务就会失败,因此整体稳定性、维护成本和性能都过差。因此我们计划基于Tiangong计算引擎构建实时DTS平台,具体架构如下:
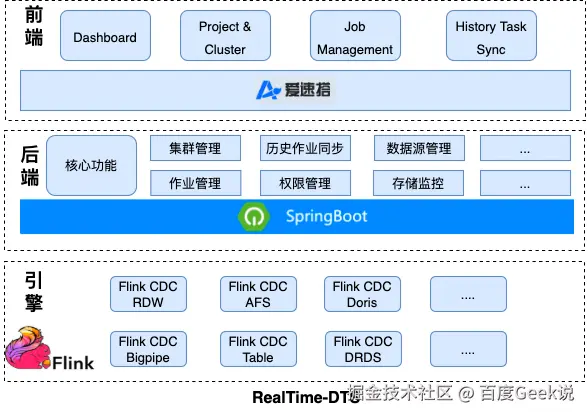
△ RealTime-DTS架构