当前,大型语言模型(LLM)在复杂推理任务上取得长足进步,一个重要趋势是"测试时缩放"(Test-time scaling),即让模型生成更长的思维链(Chain-of-Thought, CoT),本质上是在鼓励模型"思考更长时间"。诸如OpenAI的o3、DeepSeek-R1等前沿模型都证明了这种方法的有效性。
然而,"更长"并不总是意味着"更聪明"。对于极其复杂、容易在中间步骤出错或需要创造性转换思路的问题,冗长的思维链也常常无能为力。模型依赖的内部自我反思机制,往往难以发现自身的根本性错误。
那么,能否让模型像人类一样,学会利用外部工具来辅助思考、验证想法、并从工具反馈中学习,从而"更聪明地思考"呢?这就是智能体强化学习(Agentic Reinforcement Learning) 的核心思想。让模型成为一个主动的智能体,与外部环境(如Python解释器)交互,根据环境的反馈来调整自己的推理策略。

-
论文:rStar2-Agent: Agentic Reasoning Technical Report
微软研究院的这篇论文正是这一领域的重磅成果。他们成功地将一个仅有140亿(14B)参数 的预训练模型,通过其创新的智能体强化学习框架,训练成了数学推理领域的"顶尖高手",其性能媲美甚至超越了拥有6710亿(671B)参数的DeepSeek-R1模型 。更令人惊叹的是,如此强大的能力,仅需64块GPU训练一周、510个RL步数便炼成,堪称"四两拨千斤"的典范。
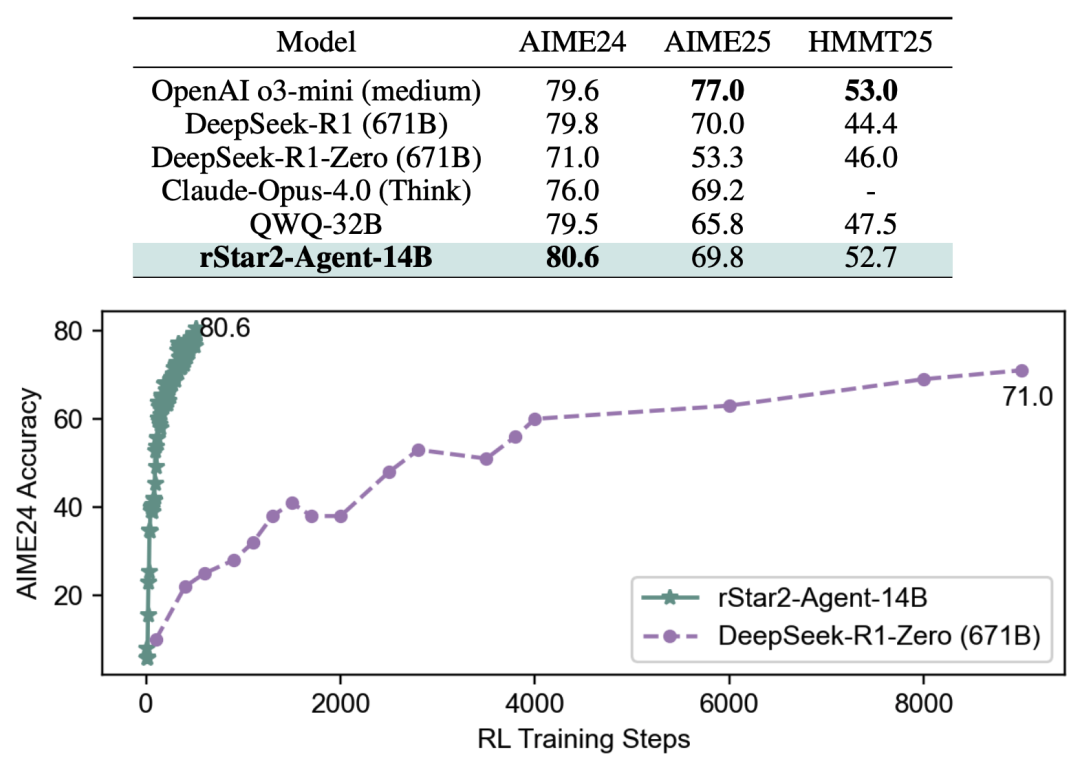
接下来,我们将深入解读这项研究是如何实现的,它究竟有何过人之处。
核心创新点一:GRPO-RoC算法------在嘈杂环境中高效学习
让模型使用代码工具进行推理,听起来很美,但实践起来第一个拦路虎就是环境噪声 。想象一下,一个学生刚开始学用计算器解题,他很可能按错键,计算器则会报错。他的注意力就从"解题"本身,被分散到了"弄清计算器怎么用"上。对于模型也是如此,它生成的代码可能有语法错误、逻辑错误(如死循环),导致Python环境返回的是错误信息(Traceback)而非有用的结果。这些错误反馈与解题推理无关,构成了强烈的环境噪声。
在传统的强化学习(RL)中,通常只根据最终答案的对错(outcome-only reward)来给予奖励。这会产生一个严重问题:一条推理轨迹,即使中间工具调用全错了,但只要最终答案蒙对了,它就能获得满分奖励。这无异于告诉模型:"中间出错没关系,只要结果对就行"。这会导致模型产生大量冗长、低质、充满错误的推理过程,学习效率低下。
如何在不修改奖励函数、避免奖励黑客(reward hacking)的前提下,解决噪声问题?
rStar2-Agent 给出了一个简洁而高效的答案:GRPO-RoC(Group Relative Policy Optimization with Resample-on-Correct) 算法。它的核心是一个叫做 "正确重采样"(Resample-on-Correct, RoC) 的策略。
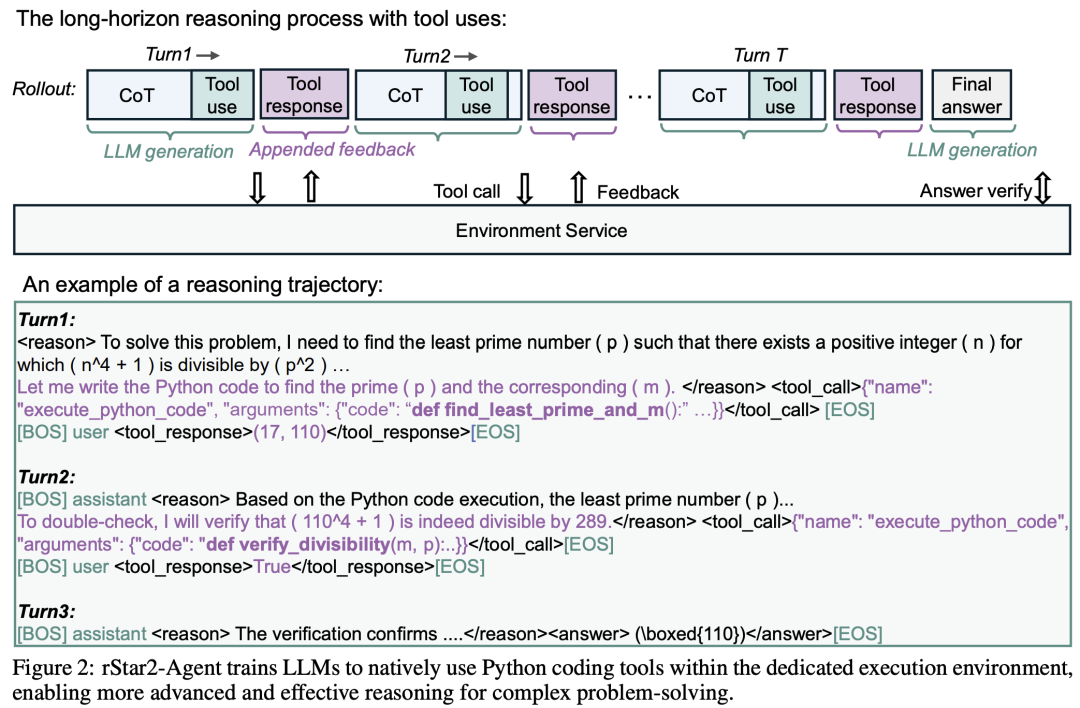
RoC策略的工作流程如下:
-
超量采样(Oversample) :对于每个问题,先用当前模型生成 2G 条推理轨迹(Rollout),而不是标准的G条。
-
分类与不对称降采样(Asymmetric Downsampling):
-
工具错误率(p_err):轨迹中出错工具调用所占的比例。错误越多,分数越高,质量越差。
-
格式违规率(p_format) :例如,在最终答案(
<answer>)之后又出现了推理(<reason>)这种不符合规定的格式。违规越严重,分数越高。
-
将这些轨迹按最终答案正确与否分为正样本 (答案正确)和负样本(答案错误)。
-
对于负样本:我们随机均匀地降采样至一半数量。目的是保留各种各样失败的方式,让模型知道"什么是错的",从而避免再犯。
-
对于正样本 :这是关键!我们不是随机选择,而是优先选择那些"质量更高"的成功轨迹。如何衡量质量?论文定义了两种 penalties(惩罚分):
-
计算总惩罚分
p_total = p_err + p_format,然后按惩罚分从低到高(即质量从高到低)的概率进行降采样。这意味着,那些工具用得又准、格式又规范的成功轨迹,有更大概率被选中用来指导模型更新。
-
策略更新:最终,我们用降采样后的G条轨迹(包含高质量正样本和多样负样本)来计算优势函数(Advantage)并更新模型。
-

这个算法的精妙之处在于 :它没有改变"最终答案正确才给奖励"这个简单可靠的奖励原则,而是通过在数据筛选层面动手脚,巧妙地"喂"给模型更多高质量的正面榜样和多样化的反面教材。这相当于老师批改作文,不仅看最后得分,还会把高分作文里字迹工整、文笔流畅的范文拿出来重点表扬,同时也会收集各种典型的错例进行讲解。这样,学生(模型)就能更高效地学习到如何写出(推理出)高质量的内容。
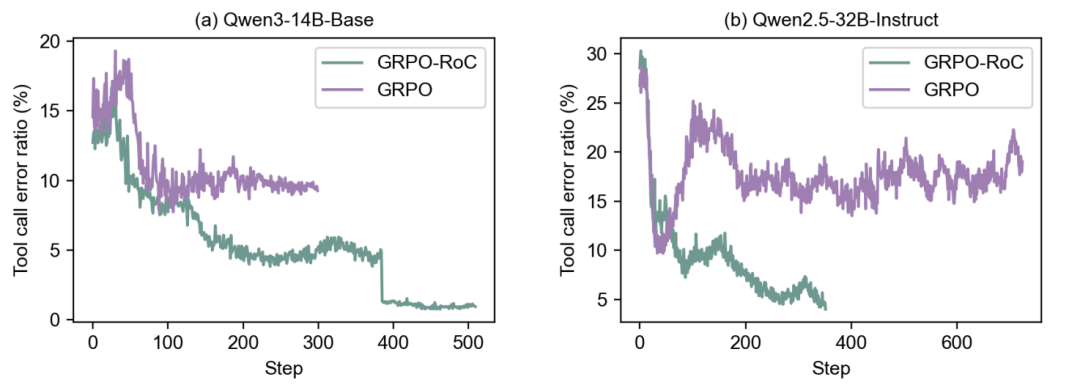
如图所示,在原始GRPO算法下,成功轨迹中的工具错误率会稳定在一个较高的水平(10%-15%),这意味着模型始终在产生大量噪声。而采用了GRPO-RoC后,工具错误率被持续地、显著地压低了,证明了该策略的有效性。
核心创新点二:大规模智能体RL基础设施------支撑高效训练
有了好的算法,还需要强大的基础设施来支撑。智能体RL的训练成本极高,因为它涉及模型与环境的频繁交互。论文揭示了两大工程挑战:
-
海量并发工具调用:一次训练迭代(step)可能产生数万个Python代码执行请求。如果直接在本地用Python解释器运行,会瞬间压垮CPU,并且让GPU空等,造成巨大的资源浪费和效率瓶颈。更危险的是,模型生成的代码不可控,可能包含死循环、恶意代码或难以杀死的进程,威胁训练主机的稳定性。
-
高度不平衡的多轮Rollout :在智能体RL中,一次完整的推理由多轮对话组成(模型输出->工具执行->模型再输出...)。每个问题的难度不同,每轮生成的token数量、工具调用次数都极不均衡。如果像传统RL那样静态地将任务平均分配给所有GPU,必然会导致某些GPU提前完工后长时间空闲,等待那些"慢吞吞"的GPU,造成严重的负载不均 和同步延迟。
针对挑战一,rStar2-Agent构建了一个高吞吐、隔离的代码环境服务。
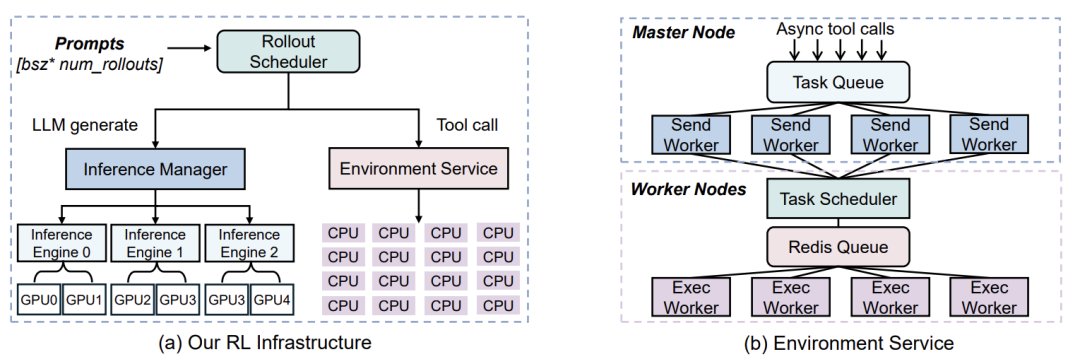
这个服务的设计非常精巧。它与主训练进程隔离,独立部署在计算集群的CPU上。有一个中央任务队列接收所有代码执行请求,由多个"发送 worker"将它们打包成批,分发给众多"执行 worker"去实际运行。运行结果再返回给发送worker,最终传回RL进程。这套架构就像一个高效的"代码执行云服务",专门处理海量、不可信的代码任务,保证了主训练流程的稳定和高吞吐。
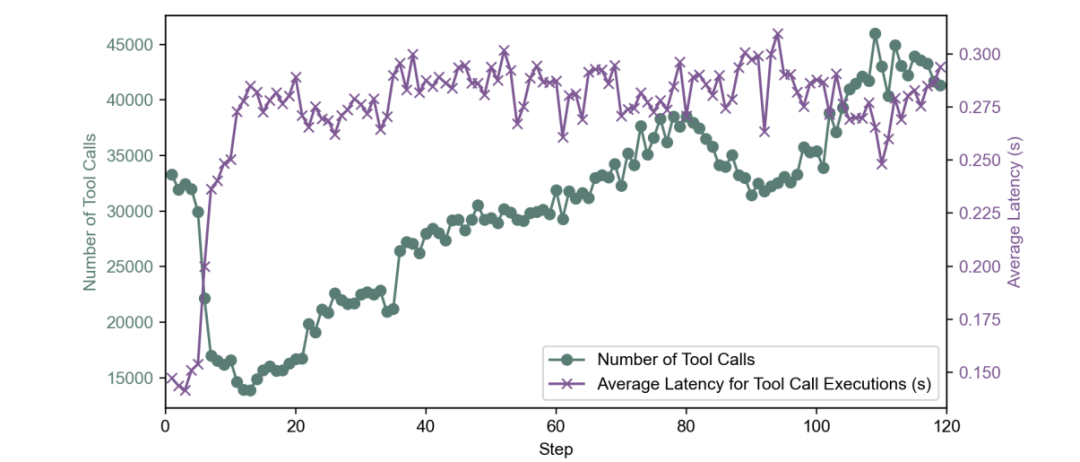
性能数据显示,该环境服务每秒可处理超过4.5万次工具调用,且平均延迟低至0.3秒,完美满足了大规模训练的需求。
针对挑战二,rStar2-Agent设计了一个动态负载均衡的Rollout调度器。
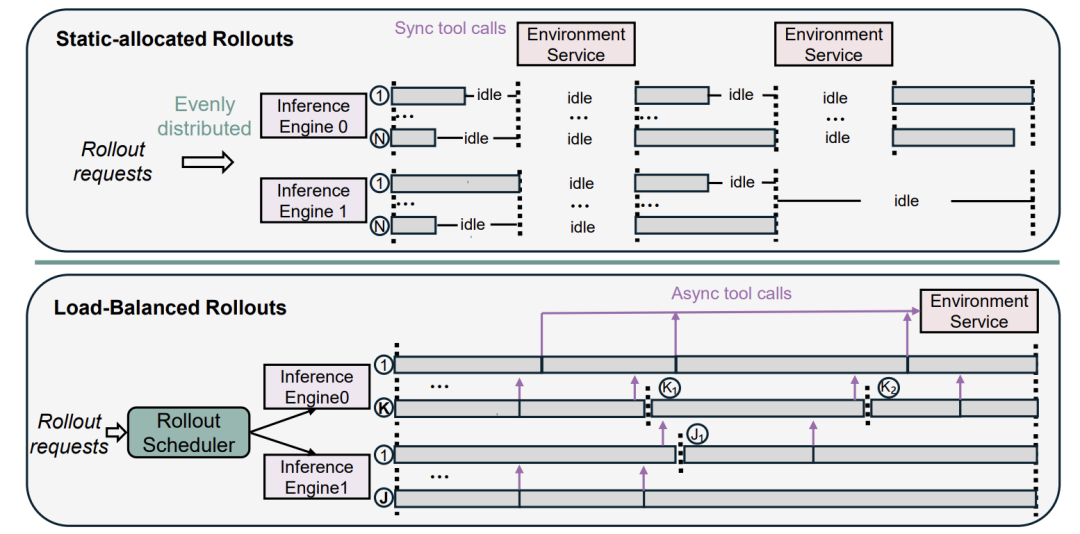
传统的静态分配(上图)问题百出。rStar2-Agent的调度器(下图)则非常智能:它不再给每个GPU静态分配固定数量的任务,而是实时监测每个GPU上KV缓存(KV Cache)的剩余容量。KV缓存可以理解为GPU为正在生成的文本预留的内存。调度器会估算每个GPU当前还能安全地承担多少新的生成任务,然后动态地将等待队列中的任务分配给它。这样,总能保证所有GPU都"忙而不崩",最大限度地利用了计算资源,避免了因KV缓存溢出而导致的计算浪费和等待。
核心创新点三:高效训练------低成本炼就最强大脑
有了算法和基础设施,最后一步是如何设计训练流程,用最小的代价获得最好的性能。rStar2-Agent的训练配方同样别具匠心,与主流方法迥然不同。
第一步:"非推理"监督微调(Non-Reasoning SFT)
通常,在做RL之前,大家会用包含详细推理链的数据对模型进行SFT,这叫"推理SFT",相当于给学生一本带详细解法的习题集让他模仿。但rStar2-Agent反其道而行之,它只进行 "非推理SFT" 。目的 :不是教模型如何推理 ,而是教模型如何遵守指令、如何使用工具接口(JSON格式)、如何规范地输出答案(
<reason>,<answer>,\boxed{}) 。用于SFT的数据主要是工具调用、指令遵循和对话数据,几乎不包含数学推理数据 。好处:-
避免了模型在SFT阶段对某种固定的推理模式产生"过拟合",为后续RL探索更优解保留了空间。
-
经过这种SFT后,模型初始的响应长度很短(~1K token),为后续RL在更短的上下文长度内进行高效训练奠定了基础。

如表所示,经过"非推理SFT"后,模型在工具使用(BFCL)、指令遵循(IFEval)和对话(Arena-Hard)能力上大幅提升,而数学推理能力(MATH-500, AIME)与基础模型相比变化不大,这印证了该阶段的目标已达成。
第二步:多阶段智能体RL训练
接下来,使用前文介绍的GRPO-RoC算法和基础设施进行强化学习。整个过程分为三个阶段,如同游戏闯关:
-
阶段1( concise RL, 8K长度) :在全部42K个数学题上训练,但将模型最大响应长度限制在8K token。虽然早期会有超过10%的轨迹因超长而被截断,但这迫使模型在有限的"篇幅"内更高效、更精准地使用工具进行推理,而不是漫无目的地"瞎试"。模型很快适应,响应长度稳定在4K左右,性能大幅提升。
-
阶段2(12K长度):当模型在8K限制下性能趋于平稳时,将长度上限提升至12K,给予模型更多空间处理更复杂的问题。平均响应长度增至6K,性能进一步上涨。
-
阶段3(困难样本聚焦, 12K长度) :此时,模型对很多简单题已经能100%做对了。为了持续提升,主动筛选出那些模型仍然会出错的"难题"(约17.3K道),只在这些难题上进行训练。平均响应长度增至8K,最终将模型推向了性能的顶峰。
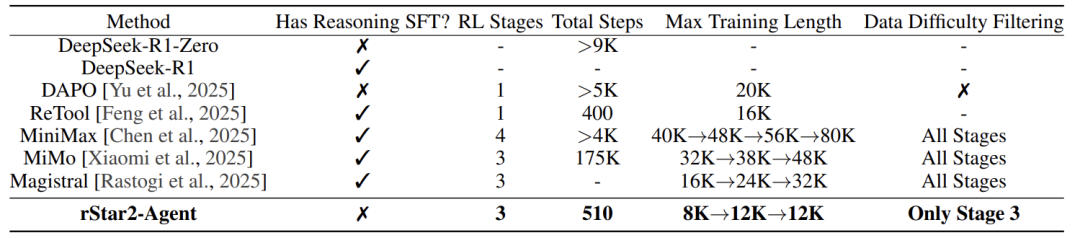
表格对比了rStar2-Agent与其他主流模型的训练配方。其最突出特点是:无推理SFT、总RL步数极少(510步)、训练长度极短(8K->12K)。这与动辄数万步、16K+训练长度的其他方法形成鲜明对比,其效率优势一目了然。
实验结果与性能表现------全面领先,泛化能力强
经过上述高效训练,rStar2-Agent-14B模型展现出了极其强悍的性能。
数学推理,超越巨头
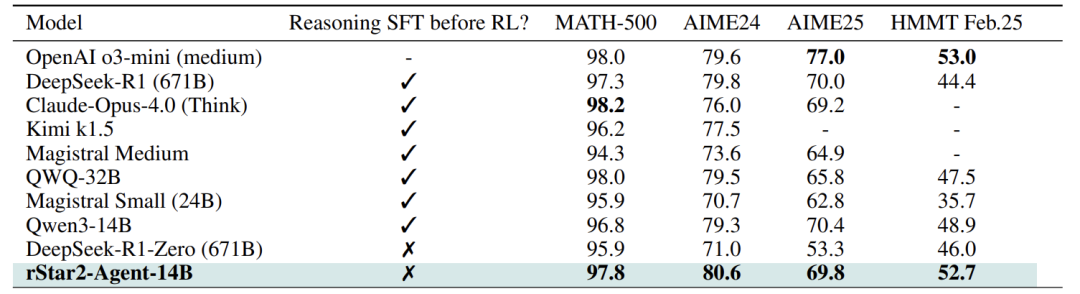
在最具挑战性的数学竞赛基准AIME2024和2025上,rStar2-Agent-14B取得了80.6% 和69.8% 的平均通过率(pass@1),一举超越了OpenAI o3-mini (medium)、DeepSeek-R1 (671B)、Claude Opus 4.0等众多庞然大物。这不仅证明了智能体RL的有效性,更开创了"小模型超越大模型"的先河。
高效推理,更短更强
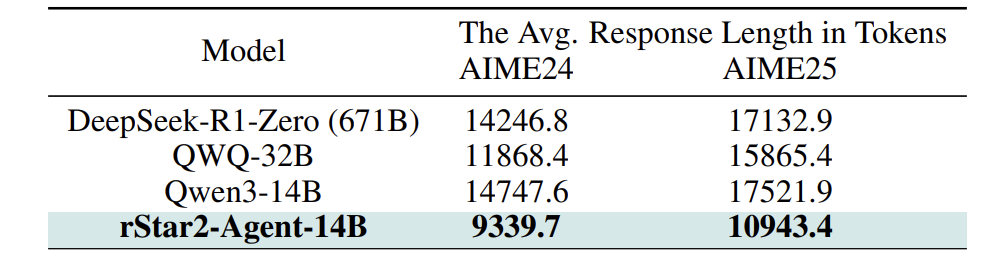
更令人称奇的是,性能的提升并非靠"暴力堆料"(生成长文本)。如表4所示,rStar2-Agent-14B的平均响应长度(~9K-10K tokens)远低于对比模型(~14K-17K tokens)。这意味着它学会了更智能、更精准地使用工具,用更少的"话"办成了更难的"事"。
强大泛化,一通百通
最有力的证据莫过于其强大的泛化能力 。rStar2-Agent仅在数学数据上进行了RL训练,但在其他领域的测试中表现惊人。

-
科学推理(GPQA-Diamond):准确率从SFT后的42.1%**跃升至60.9%**,甚至超过了专门训练的DeepSeek-V3 (59.1%)。这表明从数学中学习到的推理模式可以迁移到一般的科学推理中。
-
工具使用(BFCL v3)与对齐(IFEval, Arena-Hard) :在这些非推理任务上,性能与SFT后水平基本持平,说明数学RL训练没有损害模型原有的其他能力。
深度分析:智能体如何"更聪明"地思考?
为了探究模型变得"聪明"的内在机理,论文从token熵的角度进行了分析。熵越高,代表模型在生成该token时越不确定、选择的余地越多,这通常发生在决策和反思的关键时刻。
研究者们发现了两种关键的高熵模式:
-
分岔Token(Forking Tokens) :这类高熵token通常出现在模型自我反思、提出疑问、计划验证 的时候,例如:"但是..."(
But before)、"让我再检查一遍"(double-check)、"重新运行"(rerun)。这种模式在传统的CoT RL中也常见,它驱动模型进行探索,避免一条路走到黑。 -
反思Token(Reflection Tokens) :这是智能体RL所独有的 !当模型收到代码环境的反馈(无论是成功输出还是错误信息)后 ,会产生一连串高熵token来分析、解读、应对这个反馈。
-
一个成功执行的例子:模型看到工具返回的结果后,生成高熵token来策划如何进行验证("
To verify"),体现出谨慎的思考。
-
一个更精彩的错误处理例子:模型执行代码出错后,它没有放弃或瞎猜,而是产生大量高熵token来分析错误原因 ("
The error occurred because...")、构思解决方案 ("an easier workaround is to..."、 "Alternatively")、并最终生成修正后的代码。这像极了一个程序员在调试,展现了高级的认知能力。
结论是 :智能体RL不仅保留了传统CoT中的自我反思能力,更重要的是,它新增了针对环境反馈进行深度反思并调整行为的能力。这正是它比单纯"长思维链"更"聪明"的本质原因。
一些讨论
论文也坦诚地分享了一些失败的尝试,这些经验同样宝贵:
-
过度长度过滤(Overlong Filtering):直接丢弃因超长而被截断的轨迹(而不给予负面奖励),本意是避免惩罚那些只是写得长但推理正确的轨迹。结果却发现,这反而导致模型更频繁地产生冗长重复的文本,因为缺少了负反馈信号。最终,保留截断并给予负面奖励的效果更好。
-
N-gram重复检测 :试图用规则过滤掉含有重复n-gram的成功轨迹以提升质量,却发现这常常会误伤 那些出于验证目的而进行的合理、相似的工具调用。这表明,过于复杂精细的规则式奖励或过滤机制在LLM RL中可能弊大于利。
这些教训再次印证了其简约奖励设计 (只依赖最终答案正确性)和RoC数据层面筛选 策略的优越性:减少偏见,保持探索,实现鲁棒学习。
此外,实验发现RL提升存在天花板 。在训练后期,性能达到峰值后继续训练会导致崩溃,各种调参方法均无效。这表明,RL主要是在激发模型在预训练阶段已获得的内在潜力,而无法赋予其超越本身容量(capability)的新能力。因此,如何用最少的RL计算成本高效地触及这个天花板,就显得至关重要。rStar2-Agent成功地做到了这一点。
结论
rStar2-Agent的工作是一项融合了算法创新、系统工程和训练技巧的杰出成果。它的核心贡献在于:
-
GRPO-RoC算法:巧妙地通过"正确重采样"策略,在保持简约奖励的前提下,有效克服了代码环境中的噪声问题,引导模型产生高质量推理。
-
高性能基础设施:构建了能支撑海量并发工具调用和动态负载均衡的训练系统,让大规模智能体RL变得可行且高效。
-
高效训练配方:"非推理SFT"与"多阶段RL"的结合,以极小的计算成本(510步,64 GPUs一周),将一个小模型推向了数学推理的顶尖水平。
这项研究有力地证明了,让模型"更聪明地思考"的智能体之路,远比简单地"更长时间地思考"更有效、更高效。它开创了小模型超越巨模型的先例,为AI社区提供了宝贵的算法、系统和洞见。其代码和配方已开源,必将推动整个领域在高效、智能推理模型方面的探索。未来,将这一范式扩展到数学之外更广泛的推理领域和工具使用场景,前景令人无比期待。


-