【论文阅读】DeepSeek-LV2:用于高级多模态理解的专家混合视觉语言模型
文章目录
通过两个关键的主要升级,显着改进了其前身DeepSeek-VL
对于视觉组件,采用了dynamic tiling vision encoding strategy 专门用于处理不同长宽比的高分辨率图像
对于语言组件,利用DeepSeekMoE模型和Multi-head Latent Attention机制,将键值缓存压缩为潜在向量,以实现高效推理和高吞吐量
一、介绍
语言模型(VLMs)已经成为人工智能领域的一股变革力量
以解决需要多模态理解的复杂现实世界应用。
DeepSeek-LV2 进步主要集中在三个关键方面:
- 增强视觉理解的动态、高分辨率视觉编码策略
- 显著提高训练和推理效率的优化语言模型架构
- 精细的视觉语言数据构建管道,提高了整体性能,扩展到新的领域
(1)
引入了一种动态平铺视觉编码策略,可以有效地处理不同宽高比的高分辨率图像
- 避免了旧的固定尺寸编码器的限制
- 需要超高分辨率的任务中表现出色,包括视觉接地,文档/表格/图表分析和详细的特征提取
- 保持可管理数量的视觉token
(2)
MLA通过将键值(KV)缓存压缩到潜在向量中来显著降低计算成本,从而加快推理速度并提高吞吐量。
通过DeepSeekMoE框架进一步提高效率
(3)
在质量、数量和多样性方面大大提高了我们的视觉语言训练数据
改进的训练数据还实现了新的能力,如视觉基础 和图形用户界面(GUI)感知
如果说要对其进行图像思路的处理,难道是用提取出的文本token来对语义分割进行辅助吗。
思路1:
文本条件下的token来进行辅助融合。
思路2:
输出的文本,或者说定位信息来优化我们的分割模型的效果。
二、模型结构
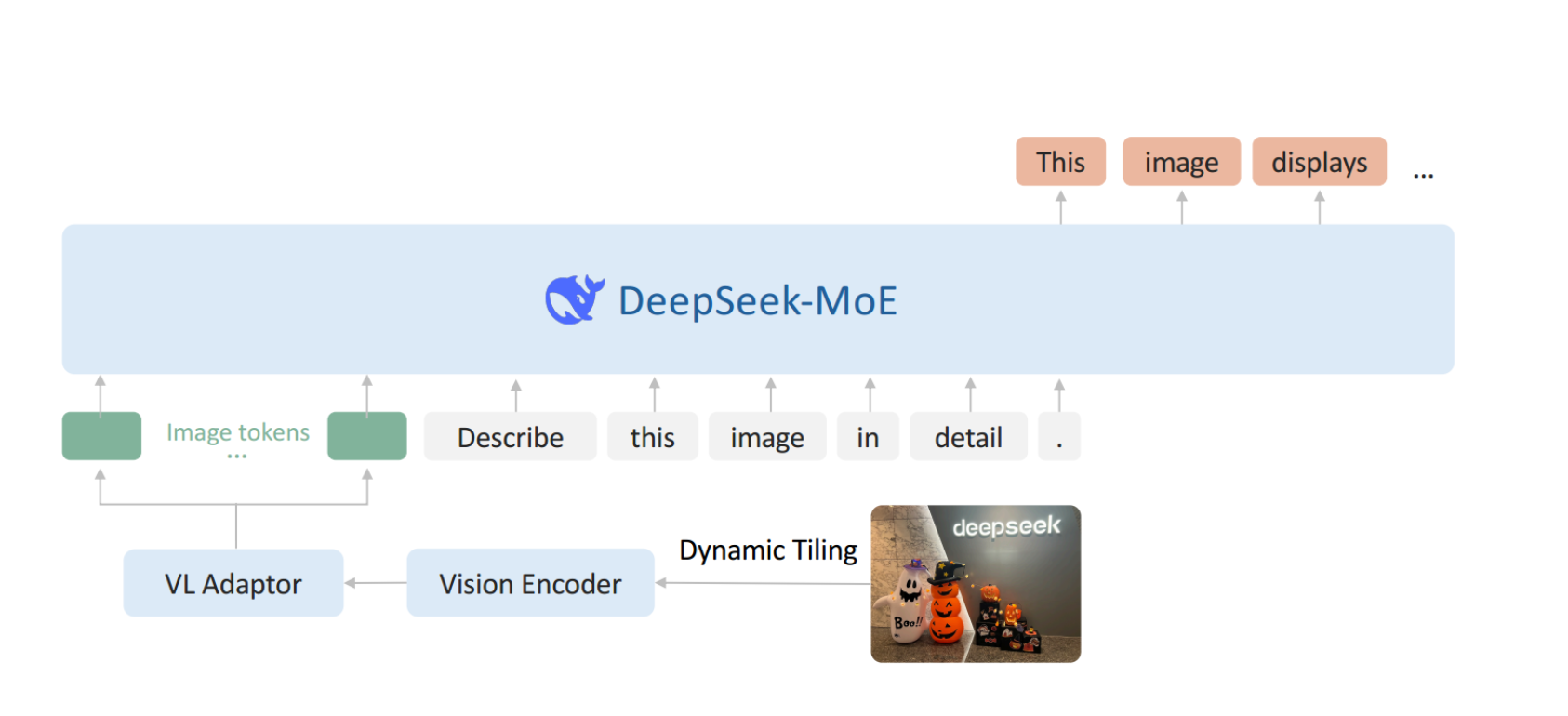
DeepSeek-VL 2由三个核心模块组成:
- 视觉编码器
- 视觉语言适配器
- 专家混合语言模型
这些创新能够更有效地处理高分辨率视觉输入和文本数据。
我觉得主要带来的影响是对图像信息的提取处理能力
动态平铺策略
通过将高分辨率图像分割为瓦片来实现动态瓦片化策略
使用单个SigLIP-SO 400 M-384视觉编码器有效处理具有不同纵横比图像

视觉语言适配器
实现了一个2 × 2像素的洗牌操作,将每个瓦片的视觉令牌从27 × 27压缩到14 × 14 = 196个令牌。
在全局缩略图块和局部块之间插入一个标记
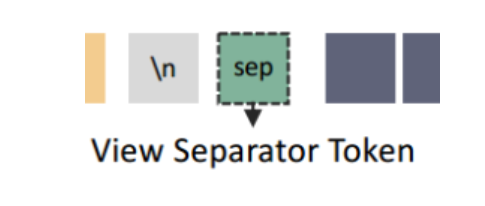
随后使用双层多层感知器(MLP)将其投影到语言模型的嵌入空间中。我们的动态平铺策略的视觉说明如图3所示
DeepSeekMoE LLM
语言模型基于DeepSeekMoE,结合了多头潜在注意力机制53。MLA通过将键值缓存压缩到潜在向量中来提高推理效率,从而提高吞吐量
全局偏差项,以经济高效地改善专家之间的负载平衡
三、数据建设
训练过程分为三个不同的阶段:
- VL对齐
- VL预训练
- 监督微调(SFT)
3.1 对齐
该阶段的重点是训练MLP连接器,以桥接预训练的视觉编码器和LLM
3.2 视觉语言预训练数据
预训练数据将视觉语言(VL)和纯文本数据结合
保持视觉语言(VL)功能和纯文本性能之间的平衡
1)交错的图像-文本数据
DeepSeek-VL 2-Tiny的初步实验确定了这个特定的混合比例
2)图像字幕数据
提供视觉和文本信息之间的直接对齐
开发了一个全面的图像字幕流程 ,该流程考虑:
- OCR提示
- Meta信息(例如,位置,相机设置)
- 相关原始字幕作为提示
实现了一个质量控制管道,以简单地根据其写作质量对所有字幕进行评分以实现过滤低质量字幕
所以deepseek对于图像中的文字信息相对敏感
3)光学字符识别数据
开发OCR功能,我们使用了开源数据
4)视觉问答数据
- General VQA
- Table, chart and document understanding
- Web-to-code and plot-to-Python generation
- QA with visual prompt
5)视觉基础数据
其实我感觉我们能用的部分就是这一块,换个话说,我们应该怎么去利用他的输出信息
定位框出指定的图中物体
6)基础对话数据

3.3 监督微调数据
SFT数据将各种开源数据集与高质量的内部QA对相结合
一般的视觉问答
三个主要限制:
- 简短的回答
- 糟糕的OCR质量
- 幻觉内容
- 偶尔会在中文响应中不适当地插入英语单词
针对存在的问题来补充训练的数据集
- 发了一个内部中文QA数据集
- 额外的内部数据集,以补充现实世界和文化视觉知识
- 成了特定于文档理解的多轮会话QA对
- 原始问题重新生成所有公共数据,增强基于表格的QA数据
- 更详细的推理过程增强了以公共推理为中心的数据集
- 构建了一个专注于教科书的内部数据集
- 扩展了我们内部的Web代码和Python Plot代码数据集
- 开发我们的视觉基础数据集
- 使用62,72构建接地对话数据,以进一步增强模型在预训练阶段建立的能力
- Text-Only datasets
相关能力:
- OCR和文档理解
- 推理,逻辑和数学
- 教科书和学术问题
- Web到代码和Plot到Python生成
- 视觉基础
- Grounded conversation
四、训练方法
三阶段流程进行训练:
- 初始阶段,使用详细描述的图像-文本配对数据训练视觉编码器和视觉语言适配器MLP,同时保持语言模型
- 预训练阶段,使用数据进行视觉语言预训练
- 微调阶段,使用的数据执行监督微调
预训练和微调阶段,所有模型参数同时训练
对齐
主要目标是在视觉特征和语言特征之间建立鲁棒的连接
调整固定分辨率的视觉编码器以适应动态的高分辨率图像,保持语言模型冻结
视觉-语言协调
主要目标是在视觉特征和语言特征之间建立鲁棒的连接
部分计算资源用于视觉语言预训练
解冻所有参数,包括视觉编码器,视觉语言适配器MLP和DeepSeekMoE LLM
监督微调
优化所有参数,同时只监督答案和特殊标记,屏蔽系统和用户提示
联合收割机多模态数据与来自DeepSeek-V2的纯文本对话数据相结合
五、实验结果
该模型在密集图像描述方面表现出色,能够识别常见地标,一般视觉知识,和丰富的文本在英语和中文
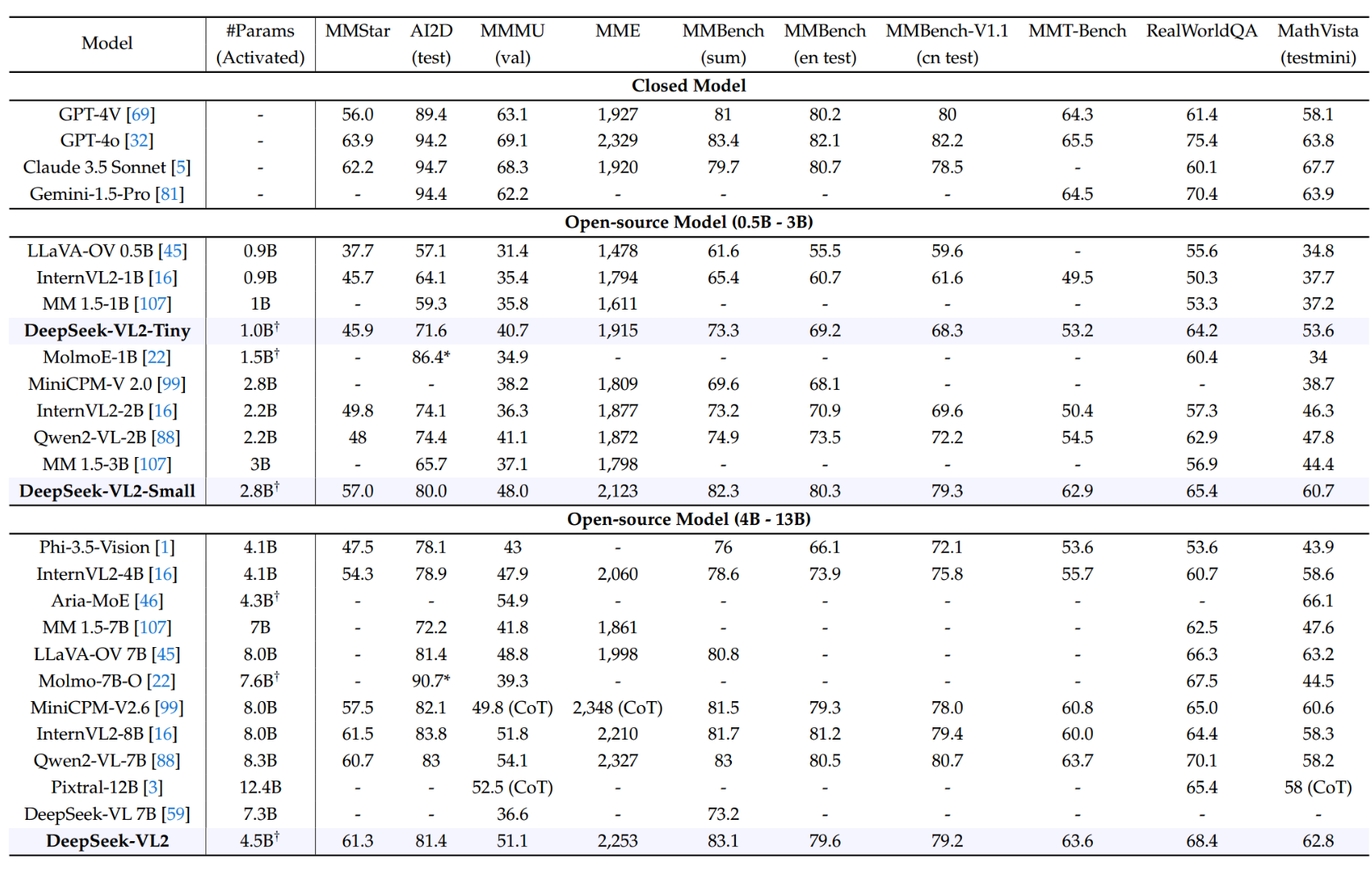
RefCOCO 数据集是一个多模态数据集,它包含了图像和对应的自然语言表达式,这些表达式指向图像中的特定对象
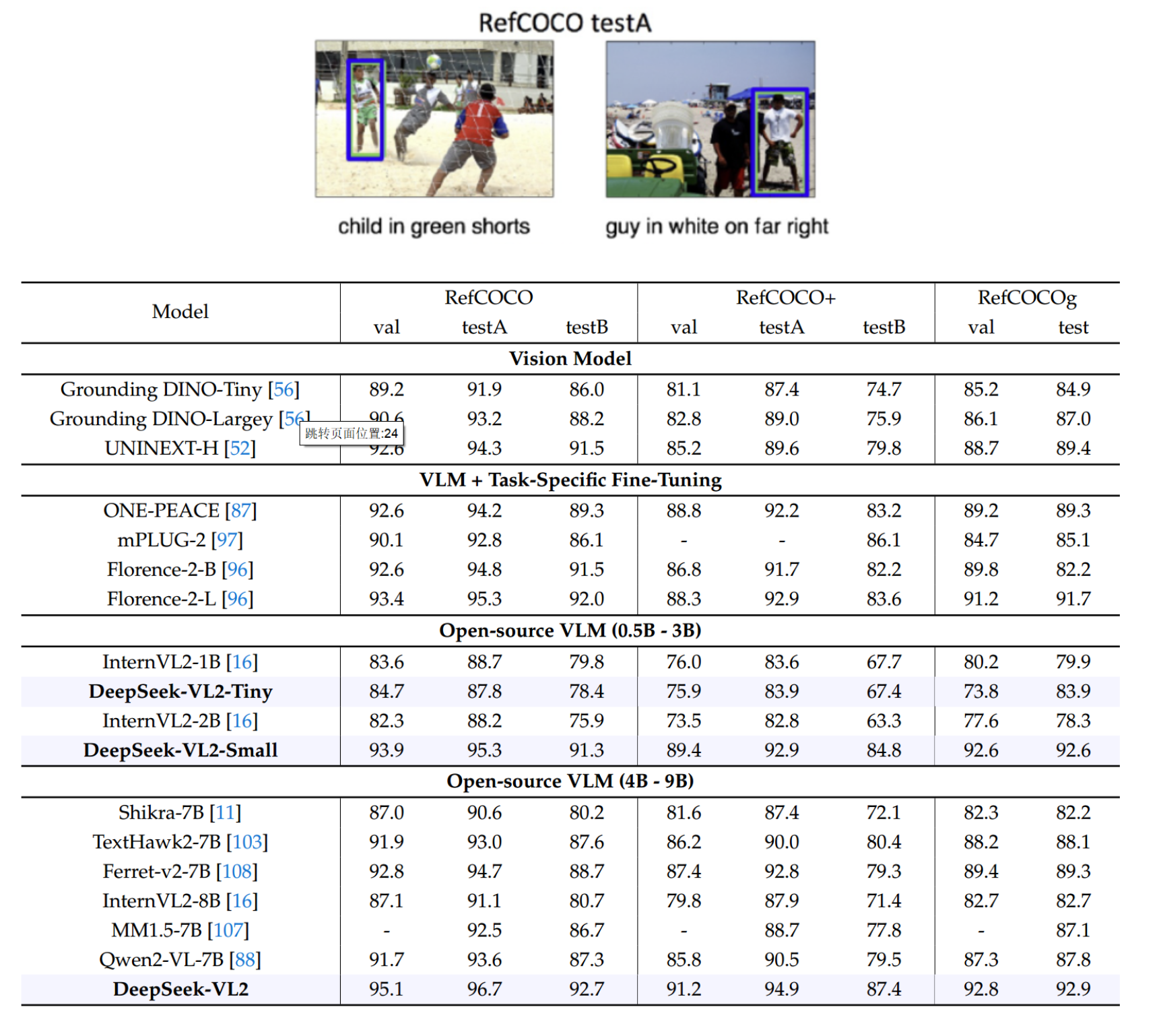
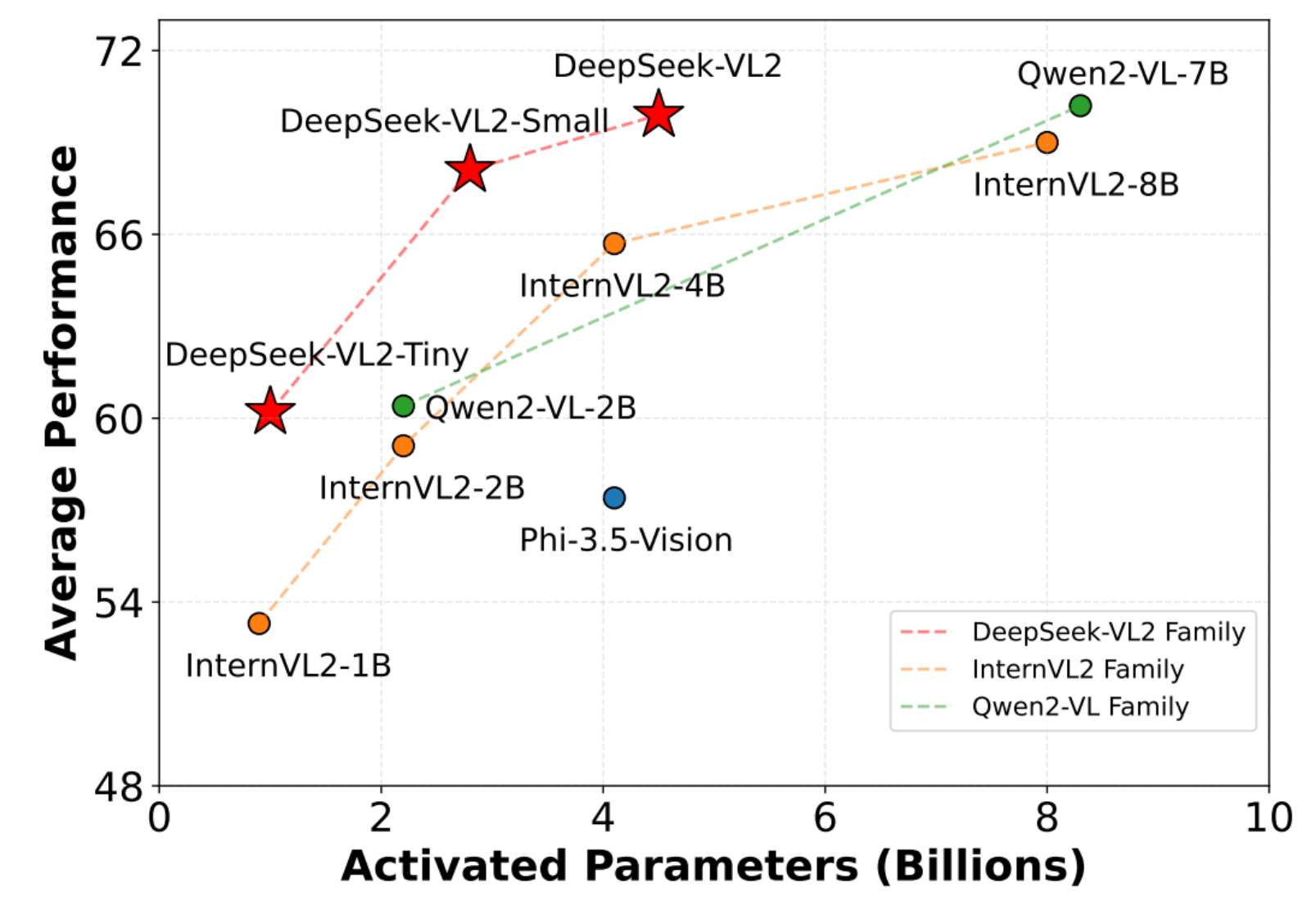
这也有点类似于打天梯图了,在视觉表现上也比如优秀

我们更加去关注DeepSeek对于物体的检索和找到能力