点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年09月01日更新到: Java-113 深入浅出 MySQL 扩容全攻略:触发条件、迁移方案与性能优化 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

章节内容
上节我们完成了如下的内容:
- Spark 学习 WordCount 程序
- Scala & Java 的方式分别编写 WordCount 程序

计算圆周率
需求背景
我们要实现一个程序来实现圆周率的计算,将利用下面的公式: 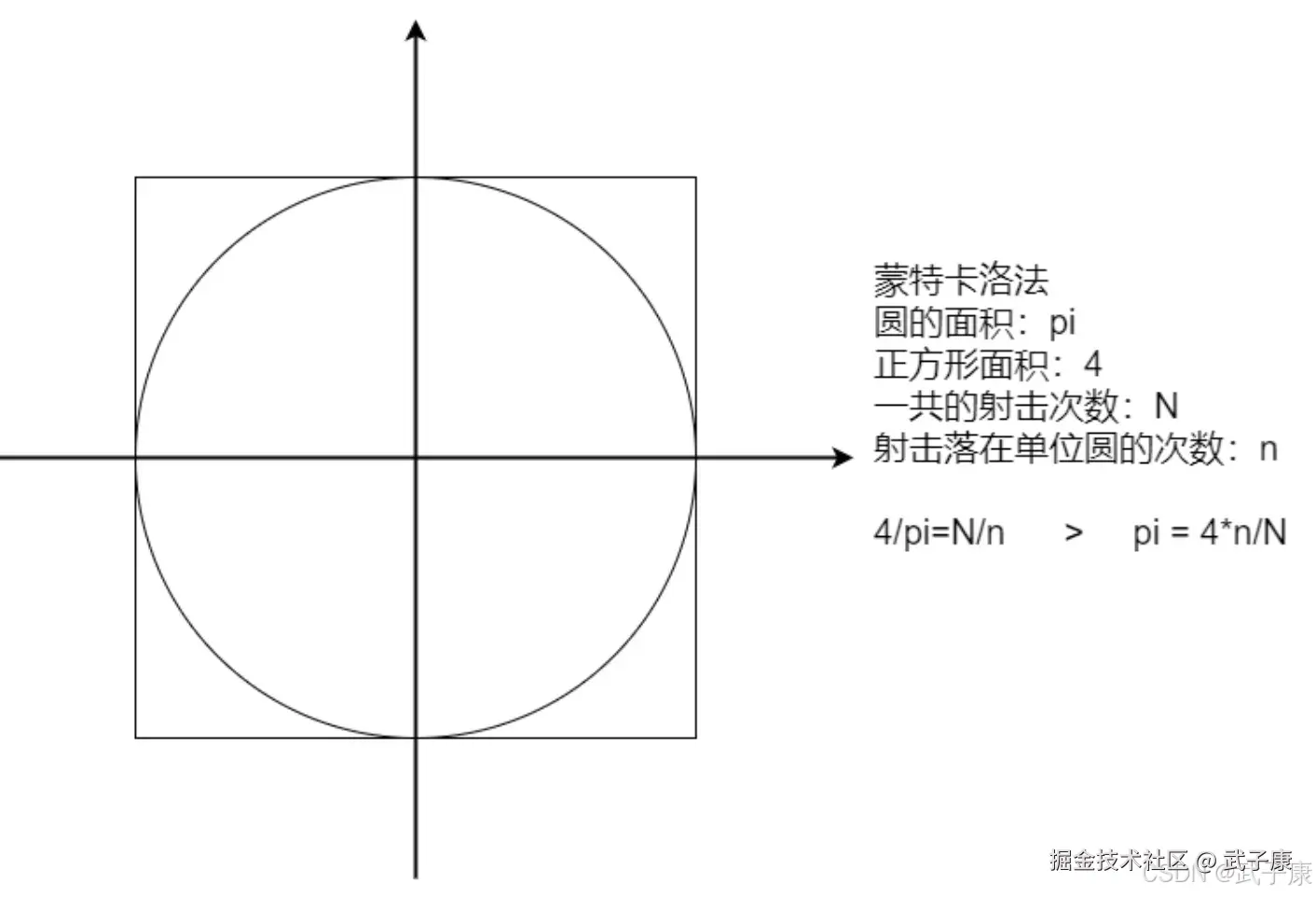
编写代码
scala
package icu.wzk
import org.apache.spark.{SparkConf, SparkContext}
import scala.math.random
object SparkPi {
def main(args: Array[String]): Unit = {
var conf = new SparkConf()
.setAppName("ScalaSparkPi")
.setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val slices = if (args.length > 0) {
args(0).toInt
} else {
0
}
val N = 100000000
val count = sc.makeRDD(1 to N, slices)
.map(idx => {
val (x, y) = (random, random)
if (x*x + y*y <= 1) {
1
} else {
0
}
}).reduce(_ + _)
println(s"Pi is ${4.0 * count / N}")
}
}代码部分截图如下所示: 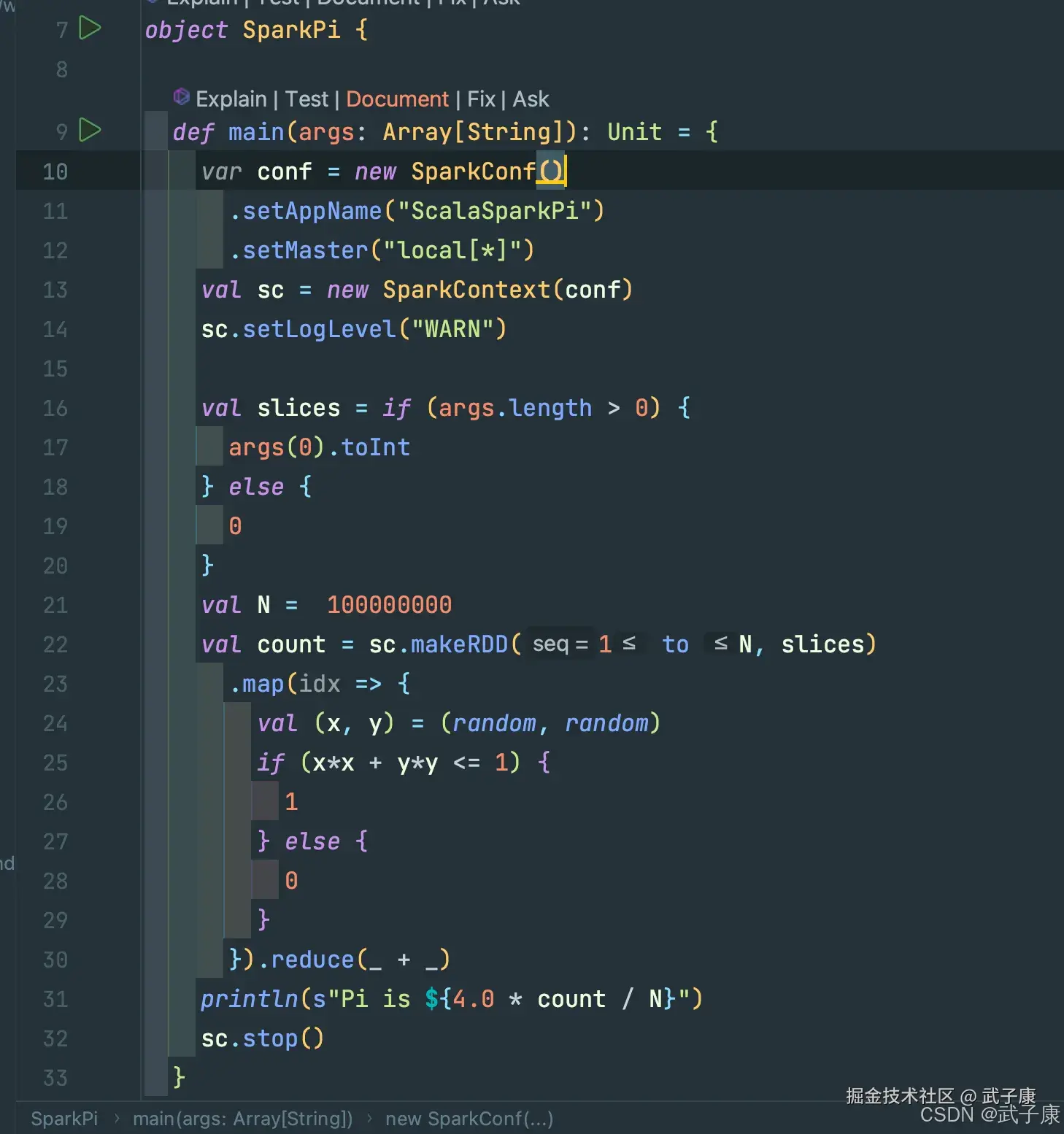
代码解释
object SparkPi { ... }
这个对象定义了一个 Scala 应用程序的入口。Scala 的 object 关键字用于定义一个单例对象,这意味着 SparkPi 只能有一个实例。
def main(args: ArrayString): Unit = { ... }
main 方法是 Scala 应用程序的入口点,类似于 Java 中的 main 方法。args 是传递给程序的命令行参数,类型为 ArrayString。Unit 表示该方法没有返回值。
var conf = new SparkConf().setAppName("ScalaSparkPi")
- SparkConf() 是 Spark 的配置类,用于设置应用程序的各种参数。在创建 SparkConf 实例后,可以通过链式调用的方式配置多个参数。
- setAppName("ScalaSparkPi") 方法为应用程序设置了一个可识别的名称,这个名称会显示在 Spark Web UI 和日志中,便于监控和调试。例如,在集群环境中运行多个应用时,管理员可以通过这个名称区分不同的应用。
- setMaster("local\*") 方法指定了 Spark 的运行模式:
- "local" 表示本地运行模式
- "\*" 表示使用所有可用的 CPU 核心
- 如果需要限制核心数,可以使用 "local4" 表示只使用4个核心
- 在生产环境中,通常会设置为 "spark://master:7077" 这样的集群地址
val sc = new SparkContext(conf)
SparkContext 是 Spark 功能的核心入口点,具有以下重要功能:
- 连接 Spark 集群:通过传入的 conf 配置对象建立与集群的连接
- 资源管理:负责申请和管理集群资源(CPU、内存等)
- 任务调度:协调任务的分配和执行
- 创建 RDD:提供了创建弹性分布式数据集(RDD)的各种方法
- 广播变量:支持广播变量的创建和使用
- 累加器:提供累加器功能
创建 SparkContext 时需要注意:
- 一个 JVM 中只能有一个活跃的 SparkContext
- 在 Spark 2.0+ 中,可以使用 SparkSession 替代 SparkContext
- 使用完毕后需要调用 sc.stop() 来释放资源
sc.setLogLevel("WARN")
设置日志的级别为 "WARN"。这意味着只会记录警告级别及以上的日志信息,减少不必要的日志输出。
val slices = if (args.length > 0) { ... }
这段代码用来处理传递给程序的第一个参数,如果有参数传递过来,则将其转换为整数,作为分片数 slices。如果没有参数,则默认值为 0。
val N = 100000000
定义一个常量 N,表示将进行一亿次随机点的生成,以此来估算 \pi 值。
val count = sc.makeRDD(1 to N, slices)
sc.makeRDD(1 to N, slices)是使用 SparkContext 创建一个弹性分布式数据集(RDD)的核心操作。这个 RDD 包含从 1 到 N 的整数序列,其中 N 是模拟的总点数。参数slices指定了数据的分区数量,即并行计算的并行度。例如,当 slices=8 时,数据会被分成 8 个分区,分布在集群的不同节点上进行并行处理,这能显著提高大规模数据计算的效率。map(idx => { ... })是一个转换操作,它对 RDD 中的每个元素(这里是 idx)应用给定的函数。在这个蒙特卡洛模拟中:- 对于每个 idx,生成两个在 [0,1) 区间内均匀分布的随机数 x 和 y,分别表示点在单位正方形内的坐标位置。例如,可能生成 x=0.3,y=0.7。
if (x*x + y*y <= 1)是判断点是否落在单位圆内的条件。这个条件利用了圆的方程 x² + y² = 1。当点在圆内时(如 x=0.5,y=0.5),返回 1;否则(如 x=0.9,y=0.9),返回 0。- 最后,每个点会被映射为 1(在圆内)或 0(在圆外),形成一个新的 RDD。
reduce(_ + _)
reduce(_ + _)是一个聚合操作,它使用指定的函数(这里是加法)将 RDD 中的所有元素合并:- 这个操作会将所有分区的 1 和 0 进行汇总。例如,如果有 1000 个点在圆内,reduce 操作会将这 1000 个 1 相加,得到总数 1000。
- 在 Spark 的执行过程中,reduce 操作会先在每个分区本地进行部分聚合(本地 reduce),然后将各分区的部分结果传到驱动节点进行最终聚合,这种两阶段聚合大大减少了网络传输的数据量。
- 最终结果
count就是落在单位圆内的点的总数,这个值将用于后续的圆周率计算(π ≈ 4 * count / N)。
println(s"Pi is ${4.0 * count / N}")
- 计算 \pi 的估计值:使用公式 \pi \approx 4 \times (\text{圆内点的数量} / \text{总点数})。
- 输出计算结果。
打包上传
shell
mvn clean package打包完成上传Jar包: 
运行项目
shell
spark-submit --master local[*] --class icu.wzk.SparkPi spark-wordcount-1.0-SNAPSHOT.jar 15运行等待结果 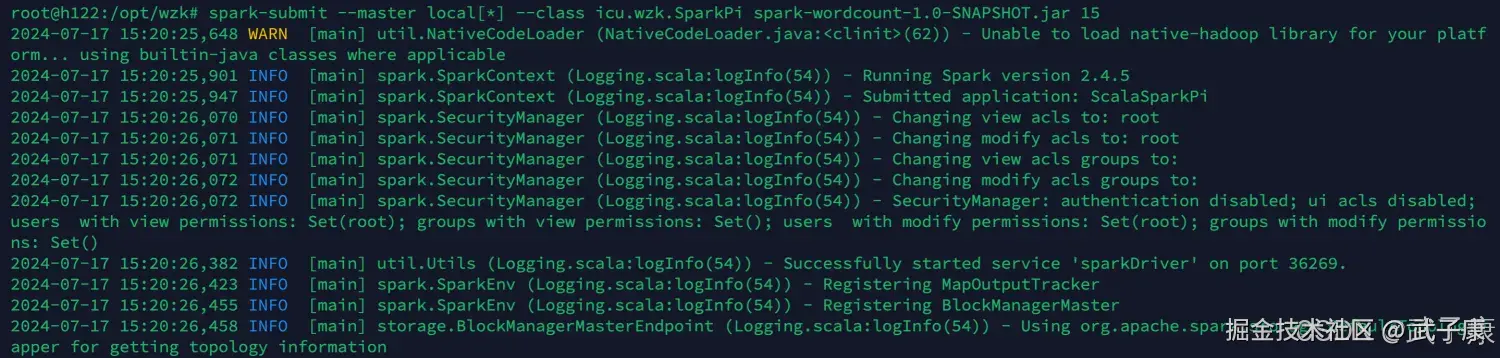 运行完毕的结果如下:
运行完毕的结果如下: 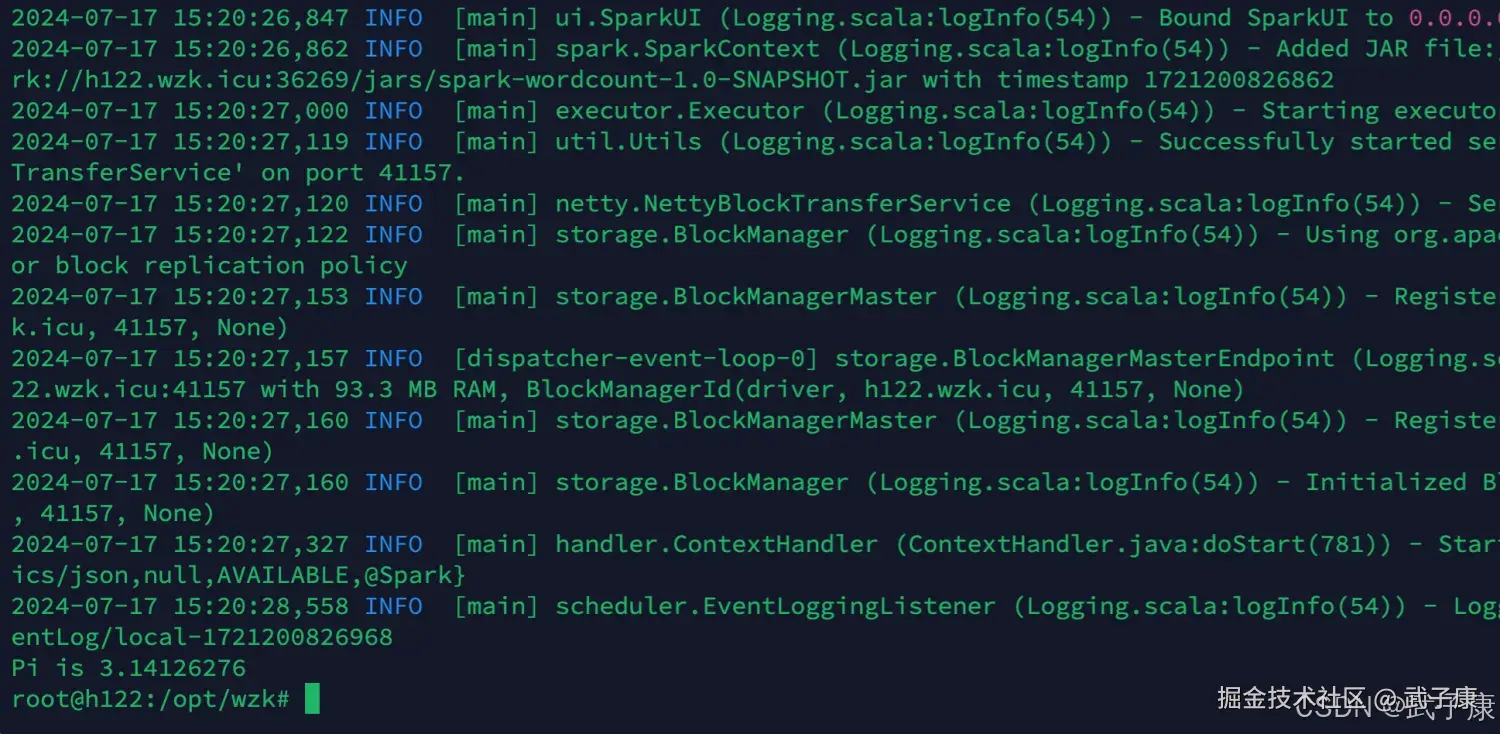
找共同好友
需求背景
目前有一组数据
shell
100, 200 300 400 500 600
200, 100 300 400
300, 100 200 400 500
400, 100 200 300
500, 100 300
600, 100第一列表示用户,后边的数字表示该用户的好友,我们要对上面的这几列进行分析计算,得出共同的好友。 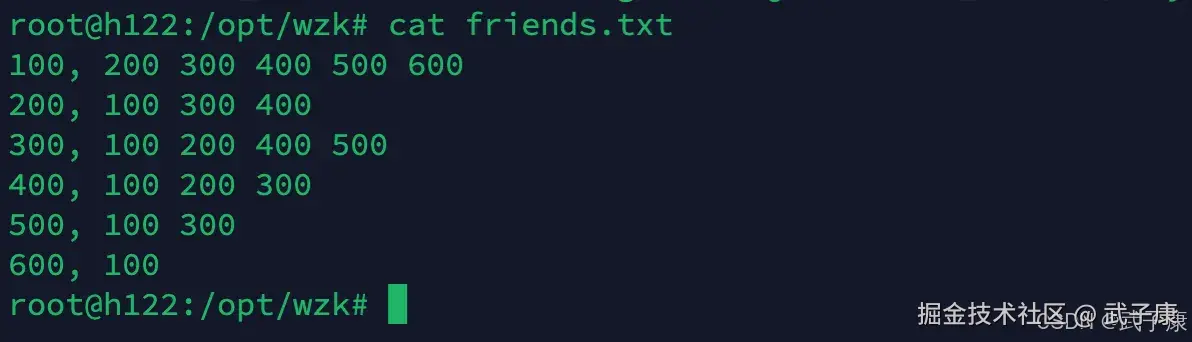
编写代码
方法一
核心思想利用笛卡尔积求两两之间的好友 然后去除多余的数据
scala
package icu.wzk
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object FindFriends {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("SparkFindFriends")
.setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val lines: RDD[String] = sc.textFile(args(0))
val friendsRDD: RDD[(String, Array[String])] = lines.map{
line =>
val fields: Array[String] = line.split(",")
val userId = fields(0).trim
val friends: Array[String] = fields(1).trim.split("\\s+")
(userId, friends)
}
friendsRDD
.cartesian(friendsRDD)
.filter({
case ((id1, _), (id2, _)) => id1 < id2
})
.map{
case ((id1, friends1), (id2, friends2)) => ((id1, id2), friends1.intersect(friends2).sorted.toBuffer)
}
.sortByKey()
.collect()
.foreach(println)
sc.stop()
}
}方法二
消除笛卡尔积 核心思想是:将数据变形,找到两两的好友,再执行数据的合并
scala
package icu.wzk
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object FindFriends2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("SparkFindFriends")
.setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val lines: RDD[String] = sc.textFile(args(0))
val friendsRDD: RDD[(String, Array[String])] = lines.map{
line =>
val fields: Array[String] = line.split(",")
val userId = fields(0).trim
val friends: Array[String] = fields(1).trim.split("\\s+")
(userId, friends)
}
friendsRDD
.flatMapValues(friends => friends.combinations(2))
.map{
case (k, v) => (v.mkString(" & "), Set(k))
}
.reduceByKey(_ | _)
.sortByKey()
.collect()
.foreach(println)
sc.stop()
}
}打包上传
运行项目
方法一
shell
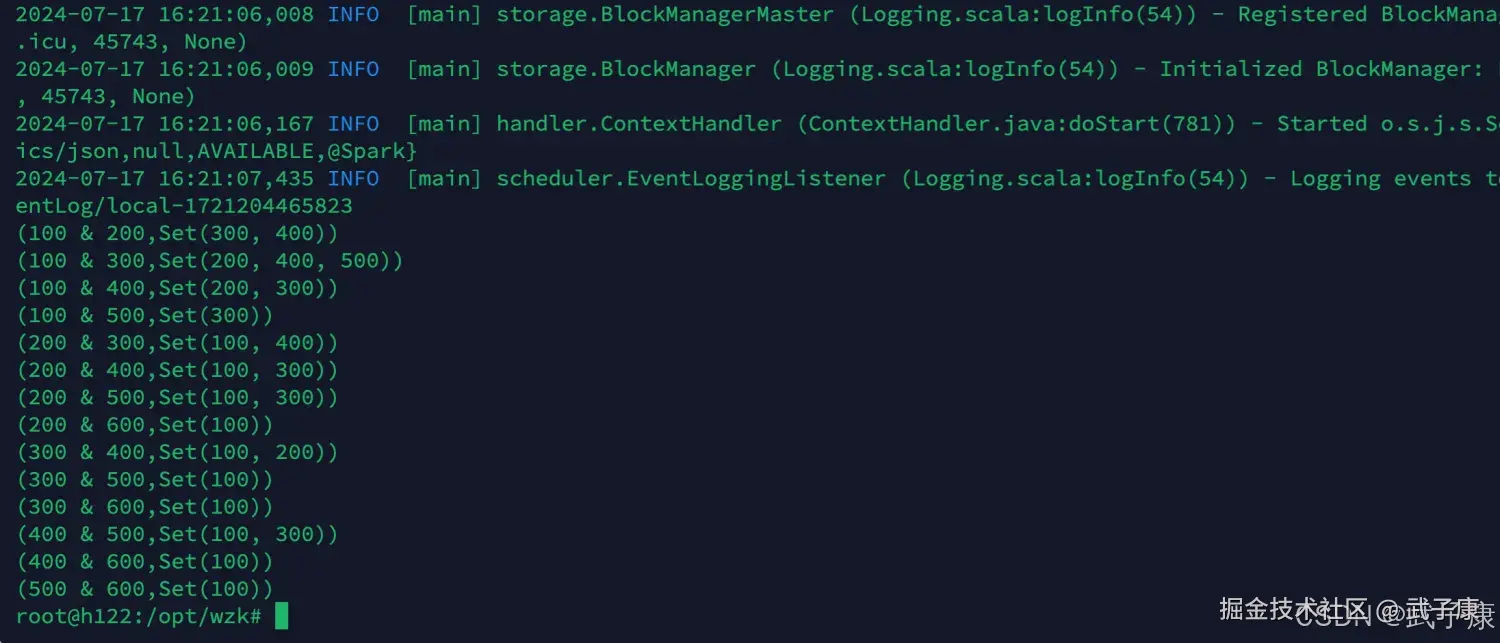
spark-submit --master local[*] --class icu.wzk.FindFriends spark-wordcount-1.0-SNAPSHOT.jar /opt/wzk/friends.txt运行结果如下图: 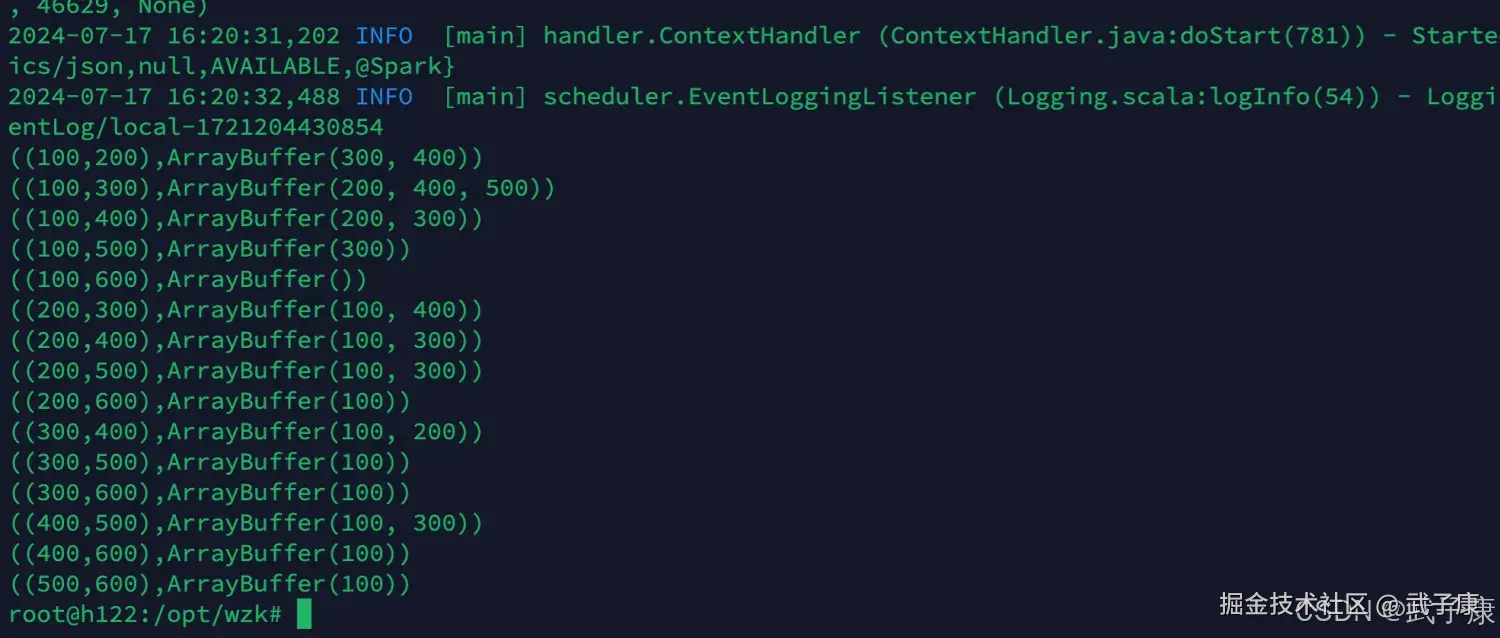
方法二
shell
spark-submit --master local[*] --class icu.wzk.FindFriends2 spark-wordcount-1.0-SNAPSHOT.jar /opt/wzk/friends.txt运行结果如下图所示: