前言
Flink中的Rebalance是一种分区算子,主要用于实现数据流的负载均衡。其核心机制是通过Round-Robin轮询策略将输入数据均匀分配到下游算子的所有并行任务中。
遇到的问题
发现上游kafka source中数据相差几毫秒的数据,在通过计算,最终下发到sink出现于实际业务不能对齐的问题。
排查问题
发现近期加了一个filter算子,用于过滤不必要的数据,但他的算子链接方式为rebalance
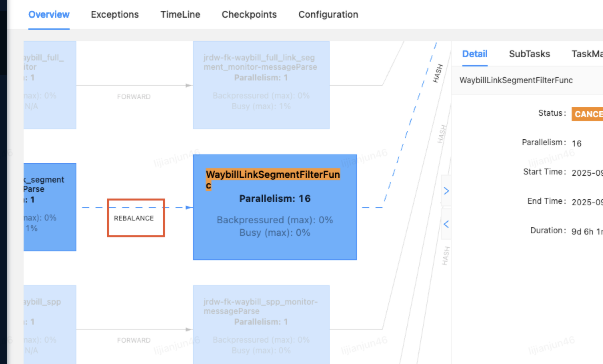
解决问题
将算的连接方式改为hash,根据唯一键keyby,解决问题。
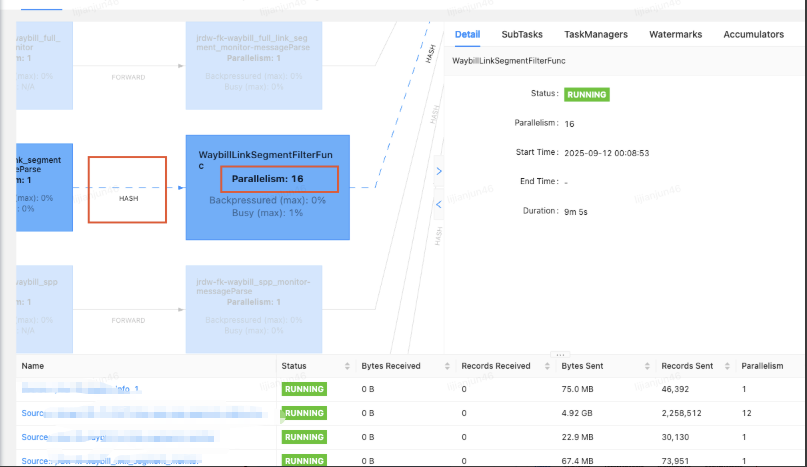
Flink中的Rebalance是一种分区算子,主要用于实现数据流的负载均衡。其核心机制是通过Round-Robin轮询策略将输入数据均匀分配到下游算子的所有并行任务中。
发现上游kafka source中数据相差几毫秒的数据,在通过计算,最终下发到sink出现于实际业务不能对齐的问题。
发现近期加了一个filter算子,用于过滤不必要的数据,但他的算子链接方式为rebalance
将算的连接方式改为hash,根据唯一键keyby,解决问题。