上期总结了顺序表,这其总结单链表,考虑到频繁使用指针,难度比顺序表略多一点。
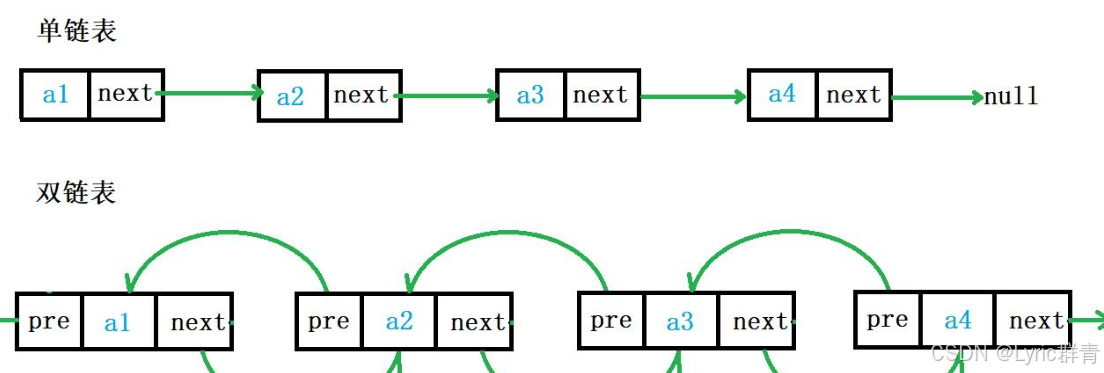
一.定义和初始化
为了不让各位在一些写法方面的问题晕菜,先看这样一个例子:
cpp
typedef struct Student{
int age;
string name;
}Stu,*Student1;
Student *S1;
Student1 S2;注意,上述的S1和S2均为Student类型的指针变量!也即*Student1直接用来声明的就是一个指针变量------即变量名之前不用加星号!换句话说,Student1只是出于某种考虑取的别名而已,参考鲁迅和周树人的区别。
再回到正文,我们定义的是一个单链表的节点,而并不是一个单链表------或者你也可以理解为一个只有一个节点的单链表~
cpp
typedef struct LinkNode{//定义一个单链表的节点类型
int data;
LinkNode *next;
}LNode,*LinkList;LNode只是LinkNode的简写,而*LinkList直接可以声明一个LinkNode的指针变量,效果上和*LinkNode一样,这么写是为了区别节点和单链表存在性质------类比马原中同一内容的不同表现形式。如下,两者均为LinkNode的指针类型变量。
cppLinkNode *L1; LinkList L2;
另外还有一个初学者或者基础不牢固的人很容易犯晕的地方:既然声明的是LNode的指针变量,为什么不是LinkList*,而是*LinkList呢?实际上这里的*和指针变量没关系,* 是绑定到标识符 而不是类型的。这里注意认得就行,不需要太深究为什么。
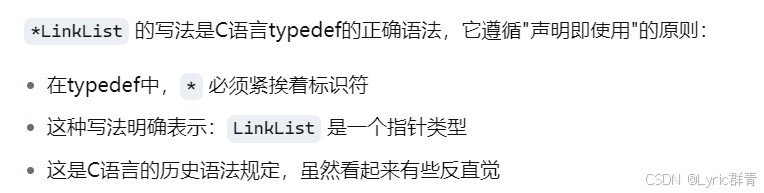
所以当我们执行下面的语句时,实际上是声明了一个指向头结点的指针,也即LinkNode*类型的变量,即便在我们看来似乎是声明了一个LinkList型的链表,这种写法使得语义较强。
cpp
LinkList L;然后就是初始化,老套路还是引用传参:
cpp
void InitList(LinkList &L){
L=(LNode*)malloc(sizeof(LNode));
L->next=NULL;
return;
}博主用的是C++,记得引入头文件:
cpp#include <cstdlib>
书上是上面的写法,实际上下面这种写法意思一样,只不过语义上更好------表达了"为链表分配内存"的意图,体现我们操作的是一个链表对象。当然各人有各自的习惯,看各位怎么用吧,这是小问题:
cpp
void InitList(LinkList &L){
L=(LinkList)malloc(sizeof(LNode));
L->next=NULL;
return;
}二.遍历和计算长度
首先实现两个常用操作,用于后续调用,首先是遍历单链表:
cpp
void PrintList(LinkList &L){
LNode *p=L->next;//从头结点的后一位开始遍历
while(p!=NULL)
{
cout<<p->data<<" ";
p=p->next;
}
}然后计算链表长度:
cpp
int CountLength(LinkList &L){
int length=0;
LNode *p=L;//注意,长度是要包含头结点的!
while(p!=NULL){
p=p->next;
length++;
}
return length;
}三.添加元素
本帖均使用带头节点的链表,因此0号节点并不是存储数据的真正节点,1号开始才是。
cpp
void Insert(LinkList &L,int loc,int value){
//注意,该链表带表头节点,所以在loc号位置插入,实际上是在有效节点的loc-1号位置插入
LNode *p=L;//指针p用来扫描,初始设置在表头
int i=0;//
while (p!=NULL&&i<=loc-2){//找到 loc-1号的前一个节点loc-2!
p=p->next;
i++;
}
if(p==NULL)
return;
LNode *s=(LNode*)malloc(sizeof(LNode));
s->data=value;
s->next=p->next;
p->next=s;
return;
}然后测试一下,注意用于遍历的temp要指向头结点的下一个节点------即从真正的数据节点开始遍历,不然会额外输出一个很大的数------实际上就是链表的起始地址,这个地址每次编译都会重新分配一次~(测试的main函数见文末一起给出最终版本~)
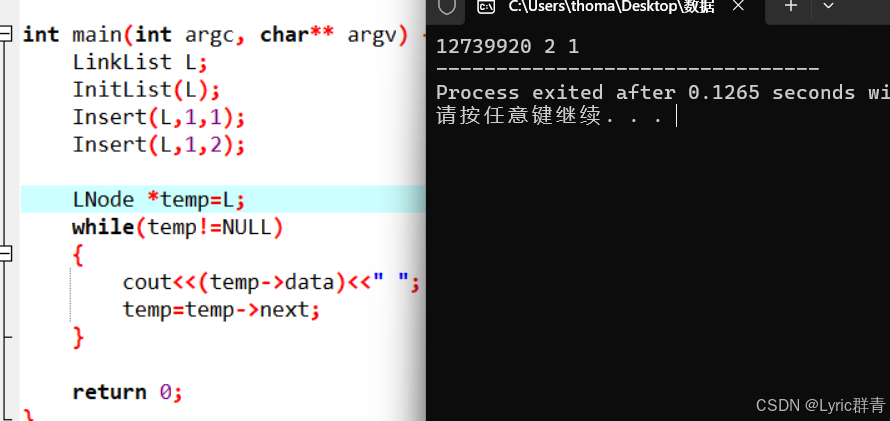
这里博主给出打印了头结点的效果,没什么问题。此外这是头插法,如果是尾插法应该找到loc的后一个位置,在链表中即有效节点的loc位置,这里不过多赘述了~
四.删除元素
还是先找到Loc的前一个节点(即有效位置loc-1的前一个loc-2):
cpp
void DeleteByLoc(LinkList &L,int loc){
int length=CountLength(L);
if(loc>length-1||loc==0)
return;//不能删除头结点,也不能删除范围外的位置
LNode *p=L;//删掉loc号节点即有效节点的loc-1号
int i=0;
while (p!=NULL&&i<=loc-2){//同理,找到 loc-1号的前一个节点loc-2!
p=p->next;
i++;
}
LNode *q=p->next;
p->next=q->next;
free(q);
return;
}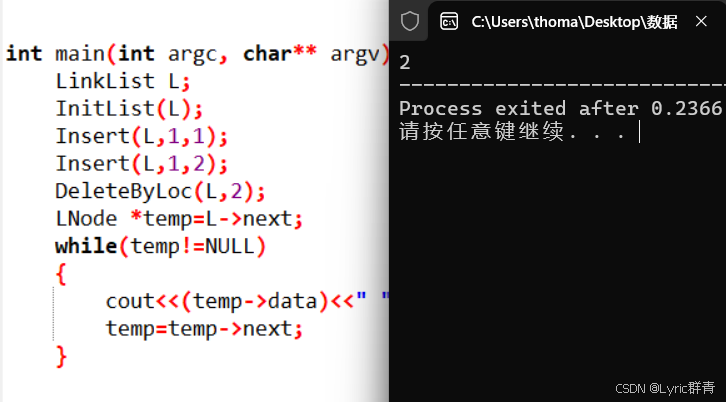
上一个例子里面的2号位置元素1被干掉了~
然后还可以按值删除,这里我们删掉第一个出现的value:
cpp
void DeleteByValue(LinkList &L,int value){
LNode *p=L;
LNode *q=p->next;
while(q->data!=value&&q!=NULL){
p=p->next;
q=q->next;
} //q是第一个value出现的位置,而p是前一个位置!
p->next=q->next;
free(q);
}依旧没什么问题:
五.修改元素
由于不能随机访问,因此按位置修改也需要我们自己实现:
cpp
void AlterByLoc(LinkList &L,int loc,int value){
int length=CountLength(L);
if(loc>length-1||loc==0)
return;//不能修改头结点,也不能修改范围外的位置
LNode *p=L;
int i=0;
while (p!=NULL&&i<=loc-1){//这和之前不同,要直接找到有效的i-1号节点
p=p->next;
i++;
}
p->data=value;
return;
}以及按元素修改(修改第一个value值元素):
cpp
void AlterByValue(LinkList &L,int former,int value){
LNode *p=L;
while(p!=NULL&&p->data!=former)
p=p->next;
p->data=value;
} 过于简单,最后一遍给出测试用例吧。
六.查询元素
同样由于失去了随机访问的特性,需要按位查找和按值查找:
cpp
int SearcheByValue(LinkList &L,int value){
LNode *p=L;
int i=0;//由于第一个头结点实际上是不存在的(非有效节点),因此从1开始统计
while(p!=NULL&&p->data!=value){
p=p->next;
i++;
}
return i;
}
cpp
int SearcheByLoc(LinkList &L,int loc){
int length=CountLength(L);
if(loc>length-1||loc==0)
return;//不能查询头结点,也不能查询范围外的位置
LNode *p=L;
int i=0;
while(p!=NULL&&i<=loc-1)//loc号插入实际上就是有效节点的loc-1号(相当于头节点充当了数组的0号下标)
{
p=p->next;
i++;
}
return p->data;
}最后给出博主自己的测试用例,各位也可以自行编写:
cpp
int main(int argc, char** argv) {
LinkList L;
InitList(L);
Insert(L,1,1);
Insert(L,1,2);
Insert(L,3,3);
DeleteByLoc(L,2);
DeleteByValue(L,2);
AlterByLoc(L,1,100);
AlterByValue(L,100,13);
PrintList(L);
cout<<endl;
for(int j=1;j<=5;j++)
Insert(L,1,j);
PrintList(L);
cout<<endl;
cout<<SearcheByValue(L,13)<<endl;
cout<<SearcheByLoc(L,3)<<endl;
cout<<CountLength(L)<<endl;
return 0;
}