目录
[I. 引言:为什么要做 D (R,O) Grasp?](#I. 引言:为什么要做 D (R,O) Grasp?)
[图 1:D (R,O) Grasp 的核心流程](#图 1:D (R,O) Grasp 的核心流程)
[II. 相关工作:我们和前人比强在哪?](#II. 相关工作:我们和前人比强在哪?)
[表 I:主流灵巧抓取方法大比拼](#表 I:主流灵巧抓取方法大比拼)
[III. 方法详解:D (R,O) Grasp 到底怎么工作?](#III. 方法详解:D (R,O) Grasp 到底怎么工作?)
[方法总览(图 2)](#方法总览(图 2))
[III-A. 第一步:构型不变预训练 ------ 让模型 "认手不认姿态"](#III-A. 第一步:构型不变预训练 —— 让模型 “认手不认姿态”)
[图 3:预训练的动机](#图 3:预训练的动机)
[III-B. 第二步:预测 D (R,O) 矩阵 ------ 机器人和物体的 "距离密码"](#III-B. 第二步:预测 D (R,O) 矩阵 —— 机器人和物体的 “距离密码”)
[两步生成 D (R,O)](#两步生成 D (R,O))
[III-C. 第三步:从 D (R,O) 生成抓取姿态 ------ 让机械手动起来](#III-C. 第三步:从 D (R,O) 生成抓取姿态 —— 让机械手动起来)
[III-D. 损失函数:逼着模型学准](#III-D. 损失函数:逼着模型学准)
[IV. 实验验证:D (R,O) Grasp 真的好用吗?](#IV. 实验验证:D (R,O) Grasp 真的好用吗?)
[IV-A. 评价标准](#IV-A. 评价标准)
[IV-B. 数据集](#IV-B. 数据集)
[IV-C. 整体性能:比所有基线都强(Q1)](#IV-C. 整体性能:比所有基线都强(Q1))
[表 II:和主流方法的对比](#表 II:和主流方法的对比)
[图 4:抓取效果可视化对比](#图 4:抓取效果可视化对比)
[IV-D. 多样抓取:能按需求抓不同姿势(Q3)](#IV-D. 多样抓取:能按需求抓不同姿势(Q3))
[图 5:腕部朝向可控](#图 5:腕部朝向可控)
[IV-E. 预训练效果:真的能跨姿态认手(Q4)](#IV-E. 预训练效果:真的能跨姿态认手(Q4))
[图 6:预训练的点匹配可视化](#图 6:预训练的点匹配可视化)
[IV-F. 鲁棒性:缺一点物体点云也能抓(Q5)](#IV-F. 鲁棒性:缺一点物体点云也能抓(Q5))
[表 III:不同条件下的成功率](#表 III:不同条件下的成功率)
[图 9(附录):部分点云抓取示例](#图 9(附录):部分点云抓取示例)
[IV-G. 真实实验:在物理世界也好用(Q6)](#IV-G. 真实实验:在物理世界也好用(Q6))
[图 7:真实实验 setup](#图 7:真实实验 setup)
[图 8(附录):真实抓取示例](#图 8(附录):真实抓取示例)
[IV-H. 零样本泛化:新机械手也能抓(Q7,附录 B)](#IV-H. 零样本泛化:新机械手也能抓(Q7,附录 B))
[表 V:零样本泛化结果](#表 V:零样本泛化结果)
[V. 结论:D (R,O) Grasp 的核心价值](#V. 结论:D (R,O) Grasp 的核心价值)
摘要:核心亮点先知道
这篇文章提出了一个叫D(R,O) Grasp的新框架,专门解决 "不同机械手抓不同形状物体" 的难题 ------ 也就是 "跨机械手灵巧抓取"。
- 输入:机械手的结构描述 + 物体的 3D 点云(可以理解为 "物体表面的一堆 3D 坐标点");
- 输出:机械手能实际做到的、稳定的抓取姿态;
- 效果 :
- 仿真中测试 3 种不同机械手(3 指、4 指、5 指),平均抓取成功率 87.53%,从计算到出结果不到 1 秒;
- 真实实验用 LeapHand 机械手,10 个陌生物体平均成功率 89%;
- 代码 & 视频 :都在项目网站(D(R,O) Grasp)。
I. 引言:为什么要做 D (R,O) Grasp?
灵巧抓取是机器人做复杂任务的第一步(比如捡东西、组装),但一直有个痛点:很难快速生成 "既稳定、又能适配不同机械手和物体" 的抓取方案。
现有方法主要分两类,都有明显缺陷:
- 优化类方法:靠数学优化找抓取姿态,但只关注指尖接触、需要物体完整形状,计算超慢;
- 数据驱动方法 (更主流):
- 机器人中心法:直接学 "观察→机械手关节角度" 的映射,推理快但 "认死手"------ 换个机械手就没用了,而且需要海量数据;
- 物体中心法:学 "物体接触点 / 接触图",能适配不同物体,但需要额外算 "逆运动学"(比如把 "接触点" 转成 "关节怎么动"),计算慢还容易出错。
为了弥补这两类方法的缺点,作者提出了D (R,O) 统一表示------ 它不偏机器人也不偏物体,而是直接捕捉 "机械手抓取姿态" 和 "物体形状" 的交互关系,既能跨机械手,又能跨物体,还快。
图 1:D (R,O) Grasp 的核心流程
这张图直观展示了框架的 3 个关键步骤:
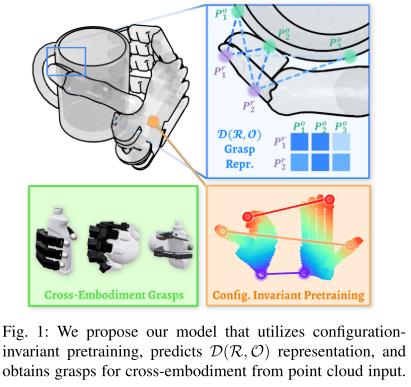
- 构型不变预训练:让模型先 "理解" 不同机械手的 "张开 / 闭合" 等姿态,不管手怎么动,都能找到对应位置(比如 "指尖" 不管张开还是闭合,都能认出来);
- 预测 D (R,O) 表示:用预训练好的模型,分析机器人和物体的点云,输出一个 "距离矩阵"(记录机器人每个点到物体每个点的距离);
- 生成跨机械手抓取:从 D (R,O) 矩阵反推出机械手的抓取姿态,不管是 3 指、4 指还是 5 指手,都能适配。
简单说:输入点云→预训练 "打底"→算距离矩阵→输出任何机械手都能用的抓取方案。
II. 相关工作:我们和前人比强在哪?
这部分主要对比现有方法,突出 D (R,O) Grasp 的优势,核心看表 I和两个研究方向。
表 I:主流灵巧抓取方法大比拼
| 方法 | 抓取表示 | 方法类型 | 能跨机械手? | 推理速度 | 样本效率 | 支持部分点云? | 全手接触?(不只是指尖) | 有抓取偏好接口? |
|---|---|---|---|---|---|---|---|---|
| DFC 2 | 关节值 | 机器人中心 | ✅ | ❌❌(超慢) | - | ❌ | ✅ | ❌ |
| UniDexGrasp++ 8 | 关节值 | 机器人中心 | ❌ | ✅✅(快) | ❌ | ✅ | ✅ | ❌ |
| UniGrasp 9 | 接触点 | 物体中心 | ✅ | ❌(慢) | ✅ | ❌ | ❌ | ❌ |
| GenDexGrasp 12 | 接触图 | 物体中心 | ✅ | ❌(慢) | ✅ | ❌ | ✅ | ❌ |
| DRO-Grasp(本文) | D (R,O) 矩阵 | 交互中心 | ✅ | ✅✅(快) | ✅ | ✅ | ✅ | ✅(手掌朝向) |
从表中能直接看出:D (R,O) Grasp 是唯一兼顾所有优点的方法------ 能跨机械手、推理快、数据需求少、缺一点物体点云也能用、全手接触更稳定,还能让用户指定 "手掌朝哪个方向抓"。
两个关键研究方向的局限
-
基于学习的灵巧抓取:
- 物体中心法:靠接触点 / 图,但转成 "关节动作" 需要额外优化,慢且不准;
- 机器人中心法:直接出关节角,但 "认死手"(换机械手就废),而且从仿真转到真实机器人误差大。
-
机器人手特征学习 :
现有方法(比如用自编码器、3D 体积表示)都 "认死姿态"------ 比如只学了 "张开手" 的特征,换 "闭合手" 就不认了。本文提出的 "构型不变预训练",就是要解决这个问题。
III. 方法详解:D (R,O) Grasp 到底怎么工作?
这是文章的核心,整个流程分 3 步:预训练→预测 D (R,O)→生成抓取姿态 ,结合图 2(方法总览) 一步步看。
方法总览(图 2)
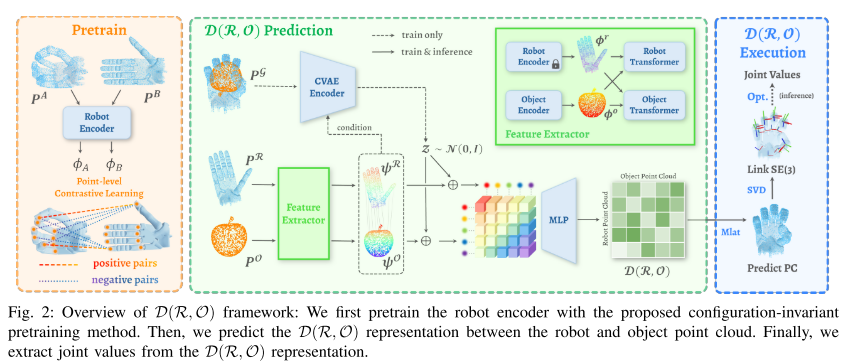
先记住这个流程:
- 左边:用 "对比学习" 做 "构型不变预训练",把机器人编码器练熟;
- 中间:输入机器人和物体的点云,用编码器提特征,再用交叉注意力建立两者联系,最后用 CVAE(一种能生成多样结果的神经网络)输出 D (R,O) 矩阵;
- 右边:从 D (R,O) 反推机器人抓取点云,用 SVD(一种数学方法)算每个连杆的 6D 姿态(平移 + 旋转),最后优化关节值,让机械手能实际动到这个姿态。
III-A. 第一步:构型不变预训练 ------ 让模型 "认手不认姿态"
问题:机械手 "张开" 和 "闭合" 时,同一个部位(比如指尖)的 3D 位置变了,模型容易认不出来,导致抓不准。
解决思路:让模型学习 "不管手怎么动,同一部位的特征都一样"。
具体操作
- 从数据集里找一个成功的抓取姿态(比如 "握杯子" 的 q_A),再找一个腕部姿态相似的 "标准姿态"(比如 "半张开" 的 q_B);
- 给机械手每个连杆(比如手指第一节、第二节)表面均匀采样点,存成 "连杆点云";用 "前向运动学"(简单说就是 "根据关节角度算点位置"),分别算出 q_A 和 q_B 对应的完整机器人点云(P^A 和 P^B,各 512 个点);
- 把两个点云输入编码器,得到每个点的特征(φ^A 和 φ^B);
- 对比学习:让 "同一部位的点"(比如 P^A 的指尖点和 P^B 的指尖点)特征靠得近,"不同部位的点" 特征离得远,用公式(1)(2)计算损失,逼着模型学出 "部位不变" 的特征。
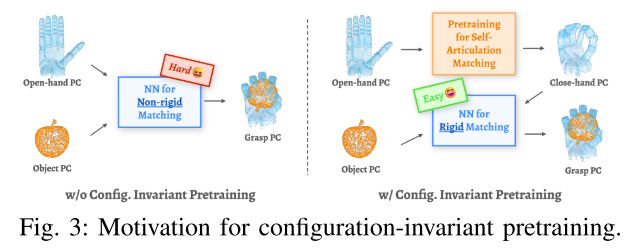
图 3:预训练的动机
这张图想说明:预训练能让模型对齐 "不同姿态的机械手"------ 比如左边张开手和右边闭合手,对应的部位(指尖、掌心)能精准匹配,为后续 "抓物体" 打下基础。
III-B. 第二步:预测 D (R,O) 矩阵 ------ 机器人和物体的 "距离密码"
D (R,O) 是一个N_R×N_O 的矩阵(N_R=512,机器人点云的点数;N_O=512,物体点云的点数),每个元素代表 "抓取姿态下,机器人第 i 个点到物体第 j 个点的距离"。有了这个矩阵,就能反推机器人该怎么摆。
两步生成 D (R,O)
-
提特征 + 建联系:
- 机器人点云(初始张开姿态)和物体点云,分别用编码器提特征(φ^R 和 φ^O)------ 机器人编码器用第一步预训练的参数,冻结不动,保证 "认手" 能力;
- 用 "多头交叉注意力"(类似 "让机器人特征和物体特征互相看"),让两者建立联系(比如 "机器人指尖特征" 会关注 "物体边缘特征"),得到关联后的特征 ψ^R 和 ψ^O。
-
CVAE 预测距离:
- 用 CVAE 捕捉 "机械手 + 物体 + 抓取姿态" 的所有变化(比如不同手抓同一个物体,或同一只手抓不同物体),输入是 "抓取姿态下的点云" 和 ψ^R、ψ^O,输出一个 64 维的 "隐藏变量" z;
- 把 z 和 ψ 拼接,用一个核函数(公式 7)计算每个点对的距离,最终组成 D (R,O) 矩阵。
III-C. 第三步:从 D (R,O) 生成抓取姿态 ------ 让机械手动起来
有了 "距离密码" D (R,O),怎么转成机械手的关节角度?分 3 步:
-
反推机器人抓取点云 :
对机器人每个点(比如 P_i^R),D (R,O) 的第 i 行是它到所有物体点的距离。用 " multilateration 方法"(类似 "通过多个基站的距离定位手机"),解最小二乘问题(公式 9),反推这个点在 "抓取姿态下" 的位置。512 个点都算完,就得到了 "抓取姿态的机器人点云" P^P。
-
算每个连杆的 6D 姿态 :
每个连杆都有之前存的 "连杆点云",把 P^P 里属于这个连杆的点,和原始 "连杆点云" 做 "刚体配准"(用 SVD,公式 10),算出连杆的平移(x_i)和旋转(R_i)------ 也就是 6D 姿态。
-
优化关节值 :
用 CVXPY(一个优化工具)调整关节角度,让每个连杆的实际平移和预测的 6D 姿态对齐,同时满足 "关节不能超过极限"(比如手指不能弯过头)、"每次调整不能太大"(避免动作太猛)。这个优化能并行计算,1 秒内就能收敛,哪怕是 28 个自由度的 ShadowHand(6 个腕部 + 22 个手指关节)也能搞定。
III-D. 损失函数:逼着模型学准
总损失分 4 部分,确保模型输出的抓取 "准、稳、不碰撞":
- D (R,O) 损失:预测的距离矩阵和真实矩阵比,差得越少越好;
- 6D 姿态损失:预测的连杆姿态和真实姿态比,平移差、旋转差都要小(公式 14);
- 防穿透损失:避免机器人手和物体穿在一起(用 "有符号距离函数" 算,负的越多穿透越严重,要惩罚);
- KL 散度损失:让 CVAE 的隐藏变量符合高斯分布,保证生成的抓取多样且合理。
IV. 实验验证:D (R,O) Grasp 真的好用吗?
作者设计了 7 个问题(Q1-Q7),用仿真和真实实验回答,核心看表 II(整体性能) 和各类可视化图。
IV-A. 评价标准
- 成功率:用 IsaacGym 仿真,机械手抓物体后,沿 6 个方向各施 1 秒力,物体位移 < 2cm 算成功;
- 多样性:成功抓取的关节值标准差(越大说明能抓的姿势越多);
- 效率:从计算到出关节角度的总时间。
IV-B. 数据集
用 CMapDataset 的子集,过滤后剩 24764 个有效抓取,3 种机械手:Barrett(3 指)、Allegro(4 指)、ShadowHand(5 指)。
IV-C. 整体性能:比所有基线都强(Q1)
表 II:和主流方法的对比
| 方法 | 成功率(%) | 平均成功率 | 多样性(弧度) | 效率(秒) | ||||
|---|---|---|---|---|---|---|---|---|
| Barrett | Allegro | ShadowHand | ShadowHand | Barrett | Allegro | ShadowHand | ||
| DFC 2(优化类) | 86.30 | 76.21 | 58.80 | 73.77 | 0.435 | >1800 | >1800 | >1800 |
| GenDexGrasp 12(物体中心) | 67.00 | 51.00 | 54.20 | 57.40 | 0.318 | 14.67 | 25.10 | 19.34 |
| ManiFM 13(物体中心) | 42.60 | 42.60 | - | 42.60 | 0.288 | 9.07 | - | - |
| DRO-Grasp(无预训练) | 87.20 | 82.70 | 46.70 | 72.20 | 0.429 | 0.49 | 0.47 | 0.98 |
| DRO-Grasp(本文) | 87.30 | 92.30 | 83.00 | 87.53 | 0.441 | 0.49 | 0.47 | 0.98 |
关键结论:
- 成功率最高:平均 87.53%,比第二名 DFC 高 13 个百分点,比 GenDexGrasp 高 30 个百分点;
- 最快:不到 1 秒出结果,DFC 要半小时以上,GenDexGrasp 要十几秒;
- 预训练有用:去掉预训练后,ShadowHand 成功率从 83% 掉到 46.7%,说明预训练是核心。
图 4:抓取效果可视化对比
这张图能直观看到差距:
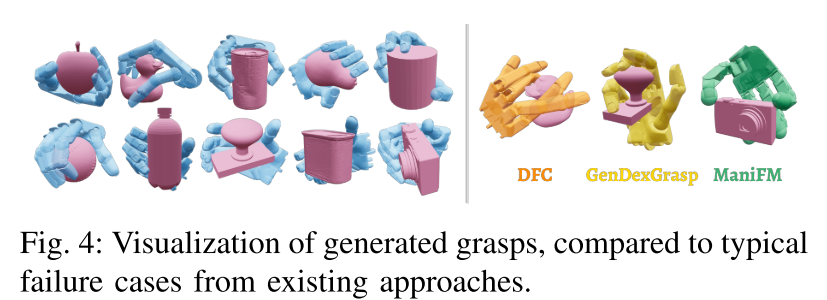
- 本文方法:抓取姿态自然,和物体贴合好;
- DFC:姿态不自然(比如手指弯得奇怪);
- GenDexGrasp:对复杂物体(比如恐龙玩具)有明显穿透(手指穿进物体里);
- ManiFM:看着好看,但只靠指尖接触,一受力就掉,成功率低。
IV-D. 多样抓取:能按需求抓不同姿势(Q3)
抓取多样性有两个维度:腕部朝向可控 + 同一朝向多姿势。
图 5:腕部朝向可控
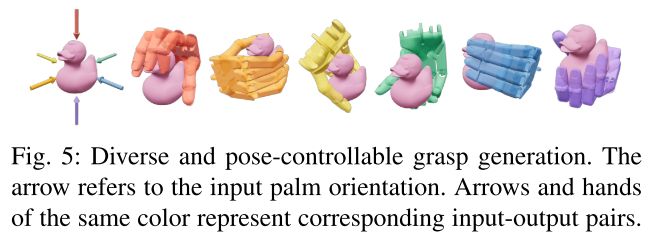
图中箭头是 "用户指定的手掌朝向",同颜色的机械手是模型输出的抓取姿态 ------ 比如指定 "手掌朝右",机械手就会从右侧抓;指定 "手掌朝下",就会从上往下抓。说明模型能按用户需求调整抓取方向。
另外,通过采样 CVAE 的隐藏变量 z,还能在 "同一朝向" 下生成多个不同的手指姿势(比如都从上面抓杯子,手指可以张一点或合一点),满足不同场景需求。
IV-E. 预训练效果:真的能跨姿态认手(Q4)
图 6:预训练的点匹配可视化

图中左边是 "张开手",右边是 "闭合手",每个点的颜色代表 "和对面手哪个点最像"。能看到:
- 同一只手:张开手的指尖点(红色)和闭合手的指尖点(红色)精准匹配,掌心点(蓝色)也对应蓝色,说明模型认得出 "不管手怎么动,部位不变";
- 不同手:比如 Allegro(4 指)和 ShadowHand(5 指),对应的部位也能匹配,说明特征能跨机械手迁移。
表 II 中 "无预训练" 的成功率下降,也证明预训练是必不可少的。
IV-F. 鲁棒性:缺一点物体点云也能抓(Q5)
真实场景中,深度相机可能只能拍到物体的一部分(比如杯子被挡住了一半)。作者做了实验:训练和测试时都去掉物体 50% 的点云(连续区域),看模型还能不能抓。
表 III:不同条件下的成功率
| 方法 | 成功率(%) | 多样性(弧度) | ||||
|---|---|---|---|---|---|---|
| Barrett | Allegro | ShadowHand | Barrett | Allegro | ShadowHand | |
| 单机械手训练(Single) | 84.80 | 88.70 | 75.80 | 0.505 | 0.435 | 0.425 |
| 多机械手训练(Multi) | 87.30 | 92.30 | 83.00 | 0.513 | 0.397 | 0.441 |
| 部分点云(Partial) | 84.70 | 87.60 | 81.80 | 0.511 | 0.401 | 0.412 |
结果:即使只有一半点云,成功率只比完整点云低一点点(比如 Allegro 从 92.30% 到 87.60%),说明模型不依赖 "完整物体形状",鲁棒性强。
图 9(附录):部分点云抓取示例
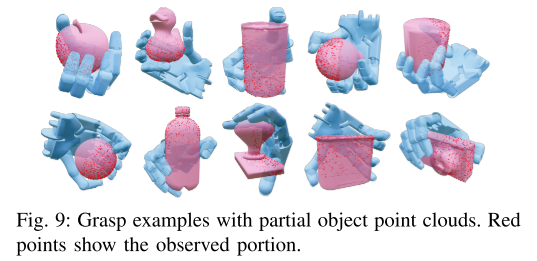
红色点是 "能看到的物体点云",白色是 "看不到的部分"------ 即使只看到杯子的一半、恐龙的后背,模型也能生成稳定的抓取姿态。
IV-G. 真实实验:在物理世界也好用(Q6)
实验平台:uFactory xArm6 机械臂 + LEAP Hand 机械手 + Realsense D435 相机(图 7)。

实验流程
- 用 AR Code 扫描 10 个陌生物体(苹果、包、恐龙玩具等),用相机标定和 FoundationPose 算法算物体的 3D 姿态;
- 给模型输入 "物体点云" 和 "32 个不同手掌朝向的机械手点云"(从顶到侧);
- 选排名前 5 的抓取方案,用 MPLib 规划机械臂运动,PD 控制器控制机械手闭合。
结果
10 个物体,每个试 10 次,平均成功率 89%(表 IV),具体如下:
| 物体 | 成功次数 | 物体 | 成功次数 |
|---|---|---|---|
| 苹果 | 9/10 | 杯子 | 7/10 |
| 包 | 10/10 | 恐龙玩具 | 9/10 |
| 刷子 | 9/10 | 鸭子玩具 | 8/10 |
| 饼干盒 | 10/10 | 茶叶盒 | 8/10 |
| 立方体 | 9/10 | 马桶清洁剂 | 10/10 |
图 7:真实实验 setup
左边是机械臂 + LEAP Hand,中间是桌子上的物体,右边是 overhead 相机,用来拍物体点云。
图 8(附录):真实抓取示例

10 个物体的成功抓取照片,比如 "用 LEAP Hand 抓苹果""抓鸭子玩具的脖子",姿态自然且稳定,证明模型能从仿真落地到真实场景。
IV-H. 零样本泛化:新机械手也能抓(Q7,附录 B)
实验:用 A 机械手训练模型,直接用在没训练过的 B 机械手上,看成功率。
表 V:零样本泛化结果
| 训练机械手 | 测试机械手成功率(%) | ||
|---|---|---|---|
| Barrett | Allegro | ShadowHand | |
| Allegro(4 指) | 83.60 | 88.70(自测试) | 1.10 |
| Barrett(3 指) | 84.80(自测试) | 42.40 | 6.90 |
| ShadowHand(5 指) | 56.90 | 83.70 | 75.80(自测试) |
结论:高自由度手→低自由度手 泛化好(比如用 5 指手训练,用 3 指手测试成功率 56.90%);但低自由度→高自由度 几乎失败(比如 3 指训练,5 指测试只有 6.90%)。
原因:高自由度手的 "姿态变化更多",模型学的 "匹配能力" 更强,能应对简单的低自由度手;反之,低自由度手学的能力太局限,搞不定高自由度手的复杂姿态。
V. 结论:D (R,O) Grasp 的核心价值
- 统一表示:D (R,O) 矩阵打破了 "机器人中心" 和 "物体中心" 的界限,同时解决 "跨机械手" 和 "跨物体" 的问题;
- 预训练赋能:构型不变预训练让模型 "认手不认姿态",大大提升泛化能力;
- 实用高效:仿真和真实实验都证明成功率高、速度快(1 秒内)、鲁棒性强(缺点云也能抓),能落地到实际场景。
附录关键补充(结合剩余图片)
图 10:抓取控制器:为了避免 "静态预测的误差"(比如轻微穿透),作者设计了 "动态控制器"------ 生成两个姿态:q_outer(离物体远一点)和 q_inner(离物体近一点),让机械手从 q_outer 慢慢闭到 q_inner,更贴近真实抓取过程。
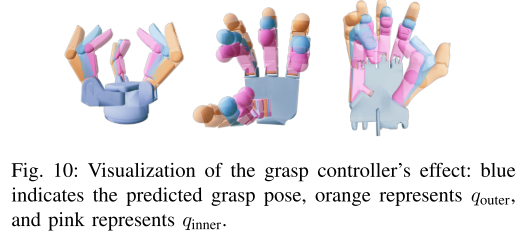
图 11:静态指标的坑:有些抓取在 "静态指标" 下算成功(比如手和物体没穿透),但实际不稳定(比如手指没抓稳)或自穿透(手指互相碰到),作者用的 "动态指标"(施力测试)能过滤掉这些坏抓取,更严谨。

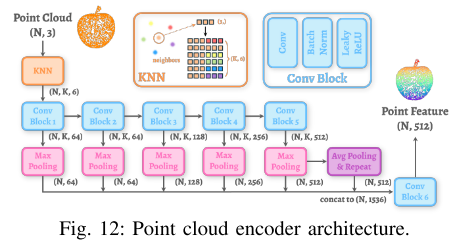
图 12:点云编码器架构:机器人和物体的编码器用 "静态图 CNN"------5 个卷积层,每个点只关注周围 32 个点(局部特征),最后加全局池化(整合整体特征),保证既能抓局部细节,又能理解整体形状。