🍊作者:计算机毕设匠心工作室
🍊简介:毕业后就一直专业从事计算机软件程序开发,至今也有8年工作经验。擅长Java、Python、微信小程序、安卓、大数据、PHP、.NET|C#、Golang等。
擅长:按照需求定制化开发项目、 源码、对代码进行完整讲解、文档撰写、ppt制作。
🍊心愿:点赞 👍 收藏 ⭐评论 📝
👇🏻 精彩专栏推荐订阅 👇🏻 不然下次找不到哟~
Java实战项目
Python实战项目
微信小程序|安卓实战项目
大数据实战项目
PHP|C#.NET|Golang实战项目🍅 ↓↓文末获取源码联系↓↓🍅
这里写目录标题
- 基于大数据的大气和海洋动力学数据分析与可视化系统-功能介绍
- 基于大数据的大气和海洋动力学数据分析与可视化系统-选题背景意义
- 基于大数据的大气和海洋动力学数据分析与可视化系统-技术选型
- 基于大数据的大气和海洋动力学数据分析与可视化系统-视频展示
- 基于大数据的大气和海洋动力学数据分析与可视化系统-图片展示
- 基于大数据的大气和海洋动力学数据分析与可视化系统-代码展示
- 基于大数据的大气和海洋动力学数据分析与可视化系统-结语
基于大数据的大气和海洋动力学数据分析与可视化系统-功能介绍
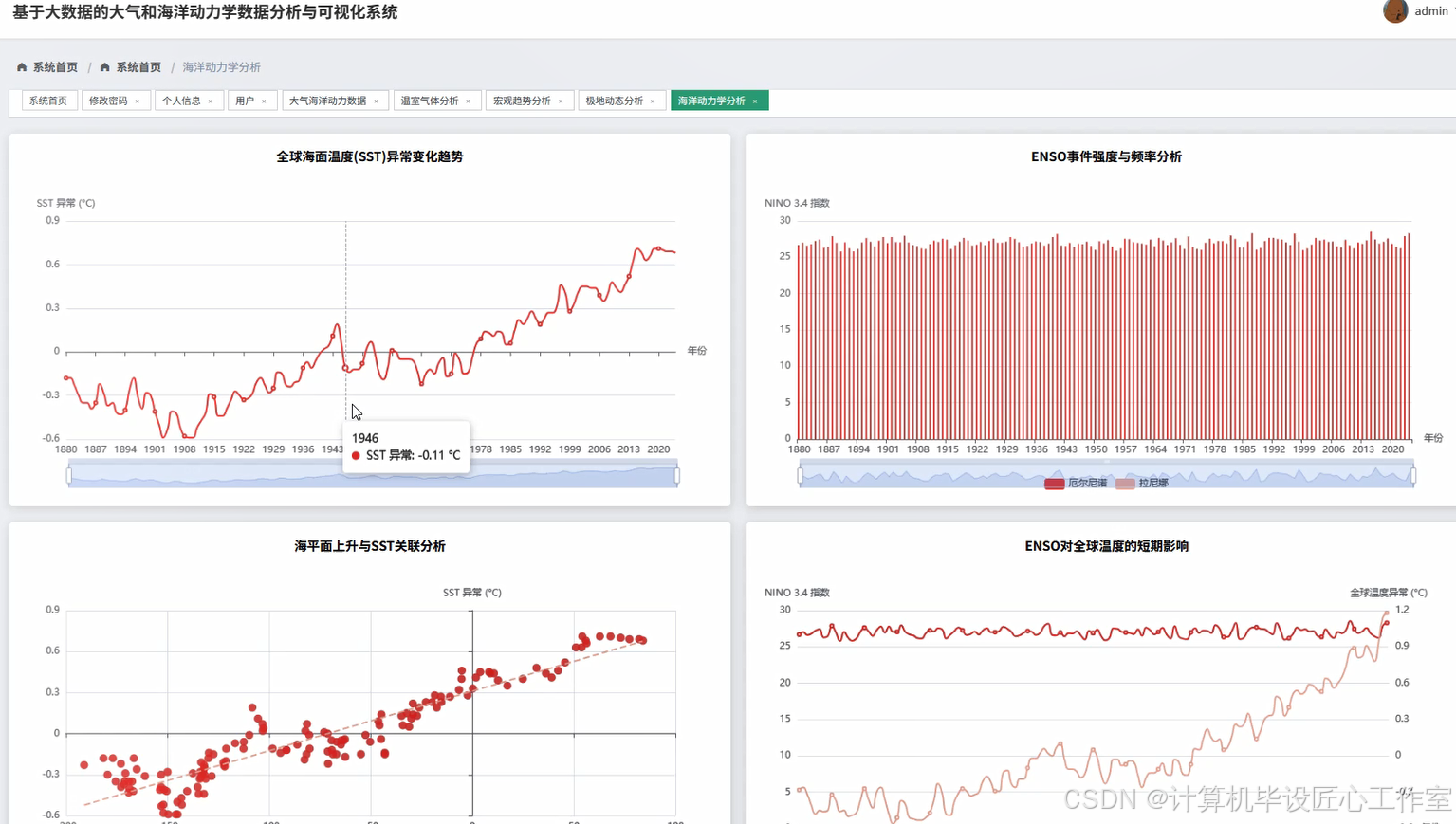
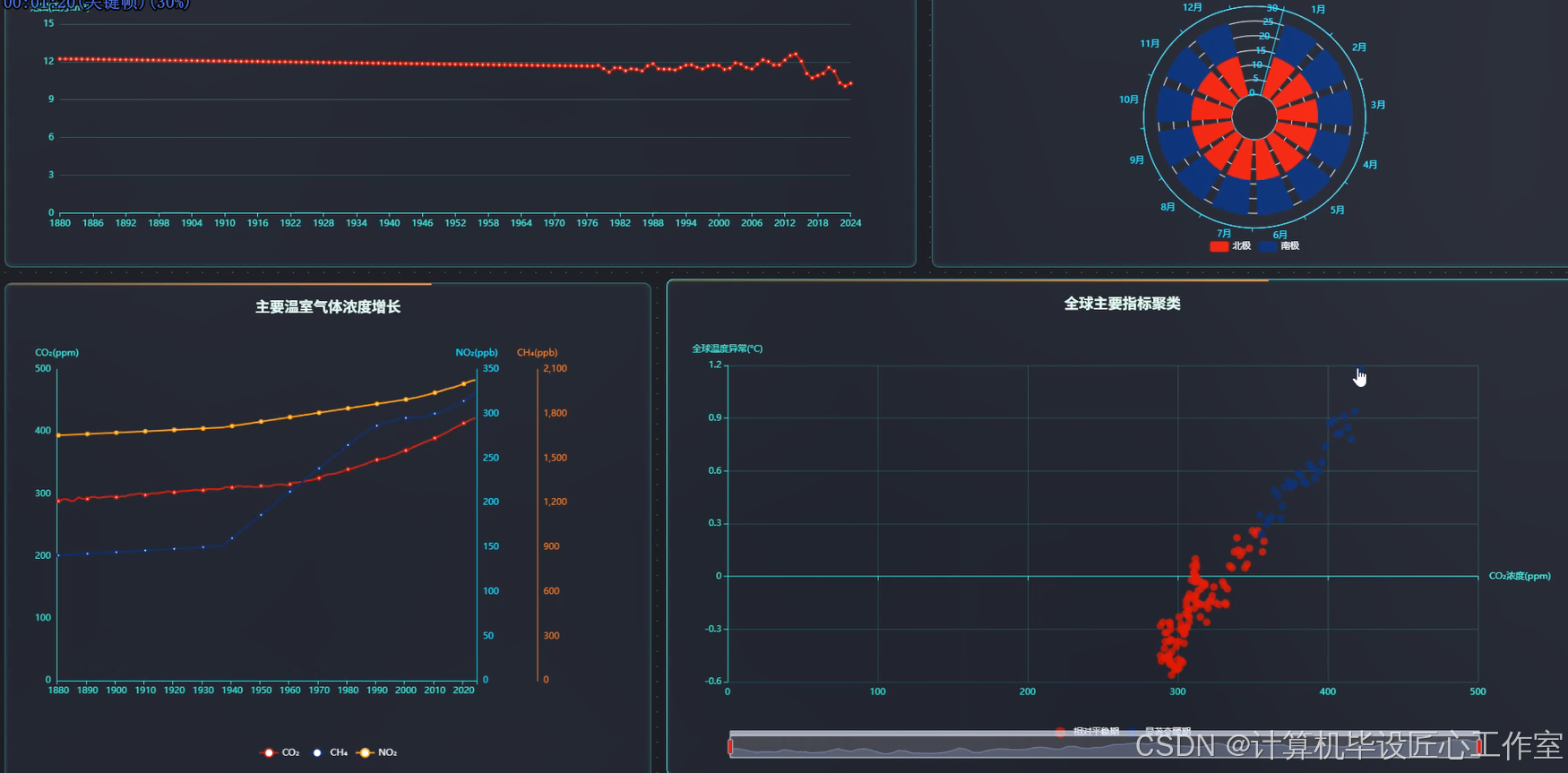
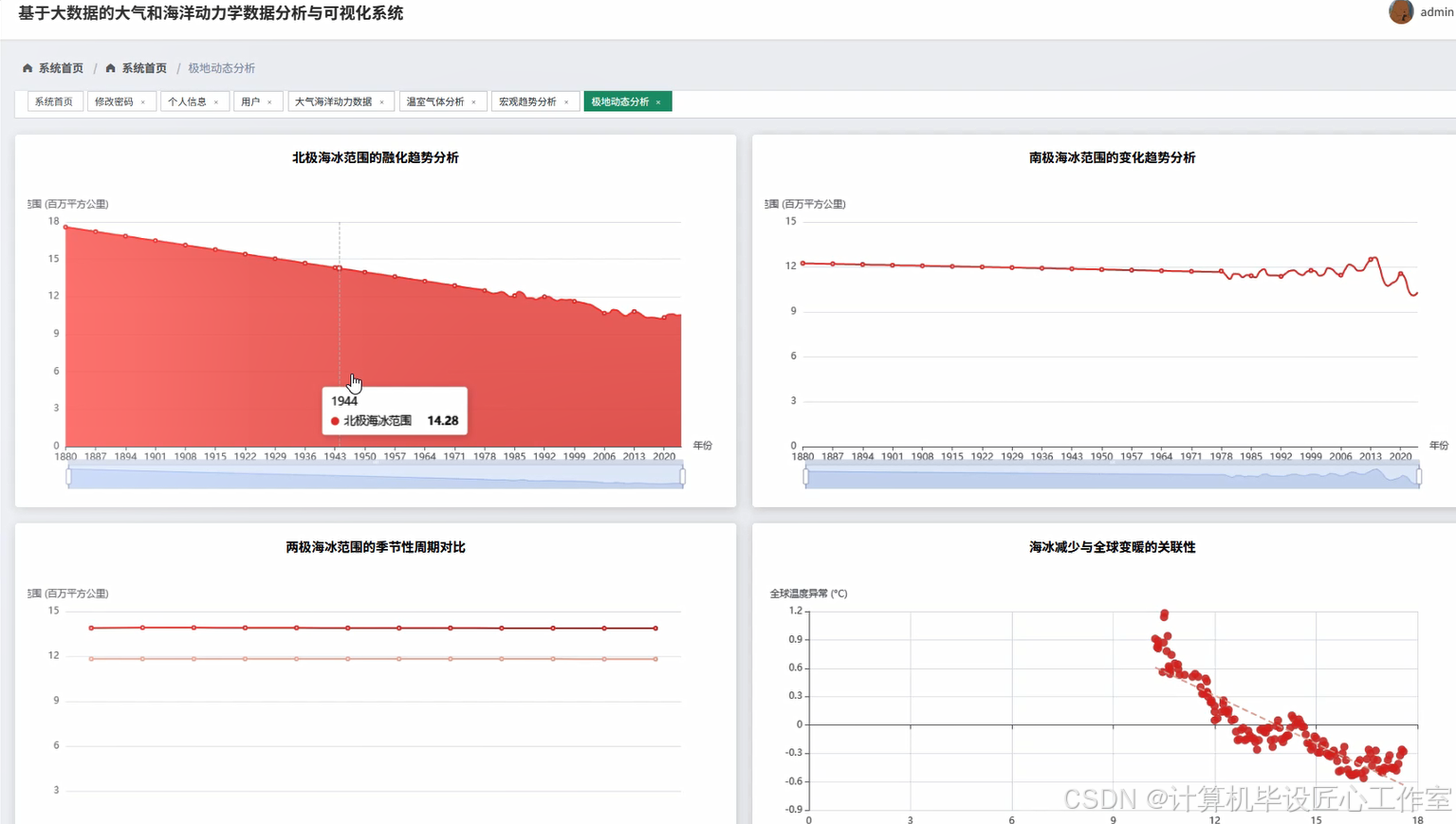
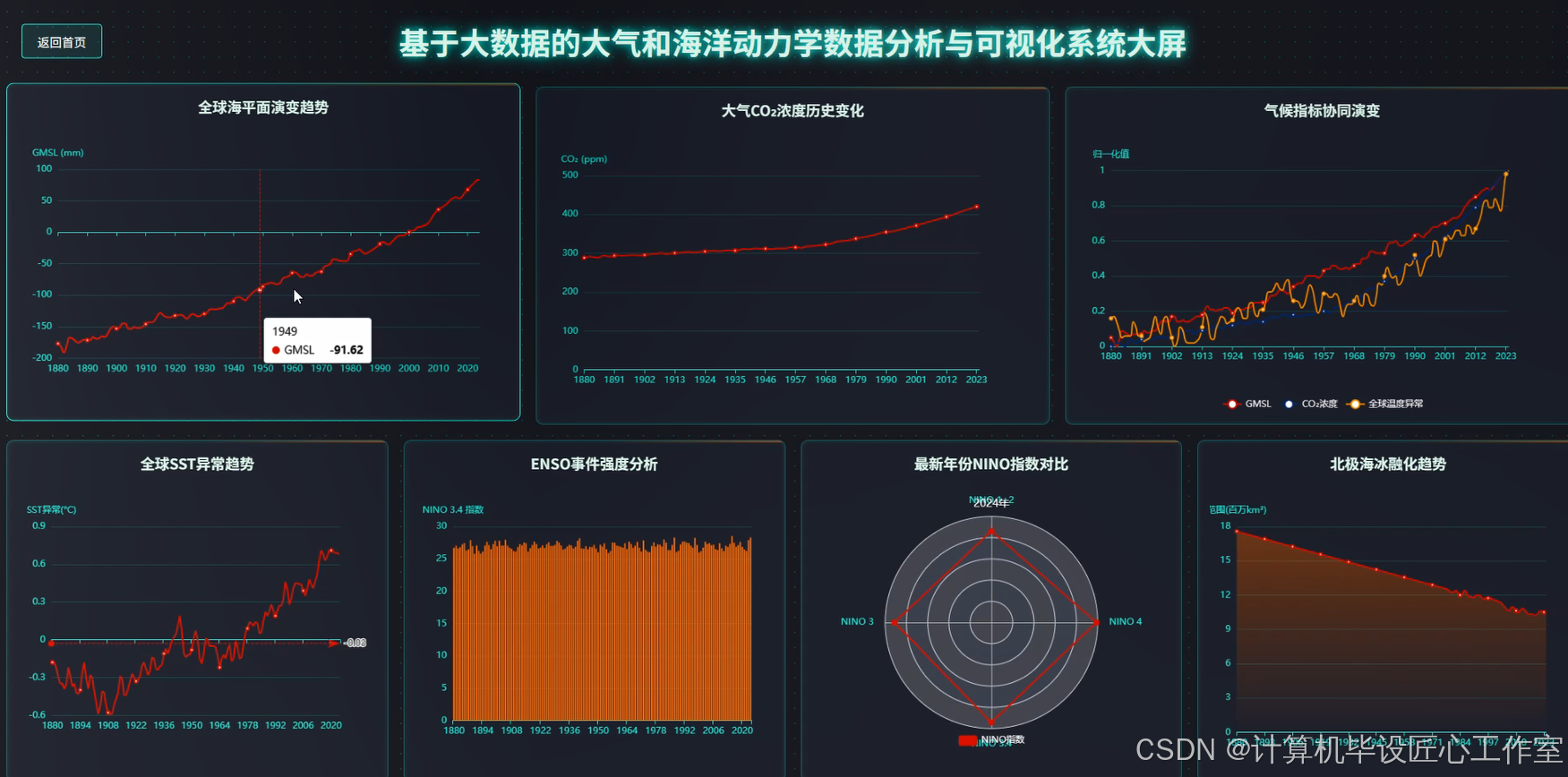
《基于大数据的大气和海洋动力学数据分析与可视化系统》是一个专门针对海洋气象领域海量数据处理与深度分析的综合性平台。系统采用Hadoop分布式存储架构结合Spark大数据计算引擎,能够高效处理包含全球海平面、大气CO₂浓度、海面温度异常、厄尔尼诺指数、极地海冰范围等多维度的历史气候数据。通过集成Spark SQL进行复杂的数据查询与统计分析,利用Pandas和NumPy进行科学计算处理,系统实现了从数据采集、存储、清洗到深度分析的全流程自动化。前端采用Vue框架搭配ElementUI组件库和Echarts可视化工具,为用户提供直观的交互式图表展示,包括时间序列分析图、散点图、聚类分析图等多种可视化形式。系统支持全球气候变化宏观趋势分析、海洋动力学核心指标监测、极地海冰演变追踪、温室气体构成变化研究等四个主要分析维度,能够有效揭示气候变化的规律性特征和内在关联性,为海洋气象研究提供可靠的数据支撑和分析工具。
基于大数据的大气和海洋动力学数据分析与可视化系统-选题背景意义
选题背景
随着全球气候变化问题日益凸显,海洋作为地球气候系统的重要组成部分,其动力学变化对全球气候模式产生着深远影响。传统的海洋气象数据分析方法在面对日益增长的多源异构数据时显得力不从心,特别是处理跨越140多年的长时序气候数据时,常规的数据库和分析工具已无法满足大规模数据存储和高效计算的需求。当前海洋气象研究领域急需能够处理PB级数据量的分布式计算平台,以支撑对全球海平面变化、大气温室气体浓度演变、海面温度异常波动、厄尔尼诺现象周期性变化等复杂气候要素的深入研究。现有的气象数据分析系统多数局限于单一数据源或特定区域的分析,缺乏对多维度海洋动力学要素的综合性分析能力,也缺乏有效的大数据技术支撑来处理海量的时空数据。
选题意义
本系统的构建对海洋气象数据分析领域具有重要的实际价值和技术推进意义。从技术角度而言,通过引入Hadoop和Spark等成熟的大数据处理框架,系统能够突破传统数据分析在存储容量和计算性能方面的瓶颈,为处理海量气候数据提供了可行的技术路径,同时为相关研究人员展示了大数据技术在海洋科学领域的应用前景。从科学研究价值来看,系统整合了多个关键的海洋动力学指标,通过统一的分析平台实现了跨要素、跨时空尺度的综合性分析,有助于研究人员更全面地理解海洋与大气系统的相互作用机制。从实用性角度考虑,系统提供的可视化分析功能能够将复杂的数据关系以直观的图表形式展现,降低了专业数据分析的门槛,为教学和科研工作提供了便利的工具支撑。虽然作为一个毕业设计项目,系统的规模和功能相对有限,但其技术架构和分析思路为后续的深入研究和系统扩展奠定了基础,对推动海洋气象数据分析技术的发展具有一定的参考价值。
基于大数据的大气和海洋动力学数据分析与可视化系统-技术选型
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
开发语言:Python+Java(两个版本都支持)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
数据库:MySQL
基于大数据的大气和海洋动力学数据分析与可视化系统-视频展示
数据量太大处理不了?Hadoop+Spark轻松解决海洋气象大数据分析难题
基于大数据的大气和海洋动力学数据分析与可视化系统-图片展示
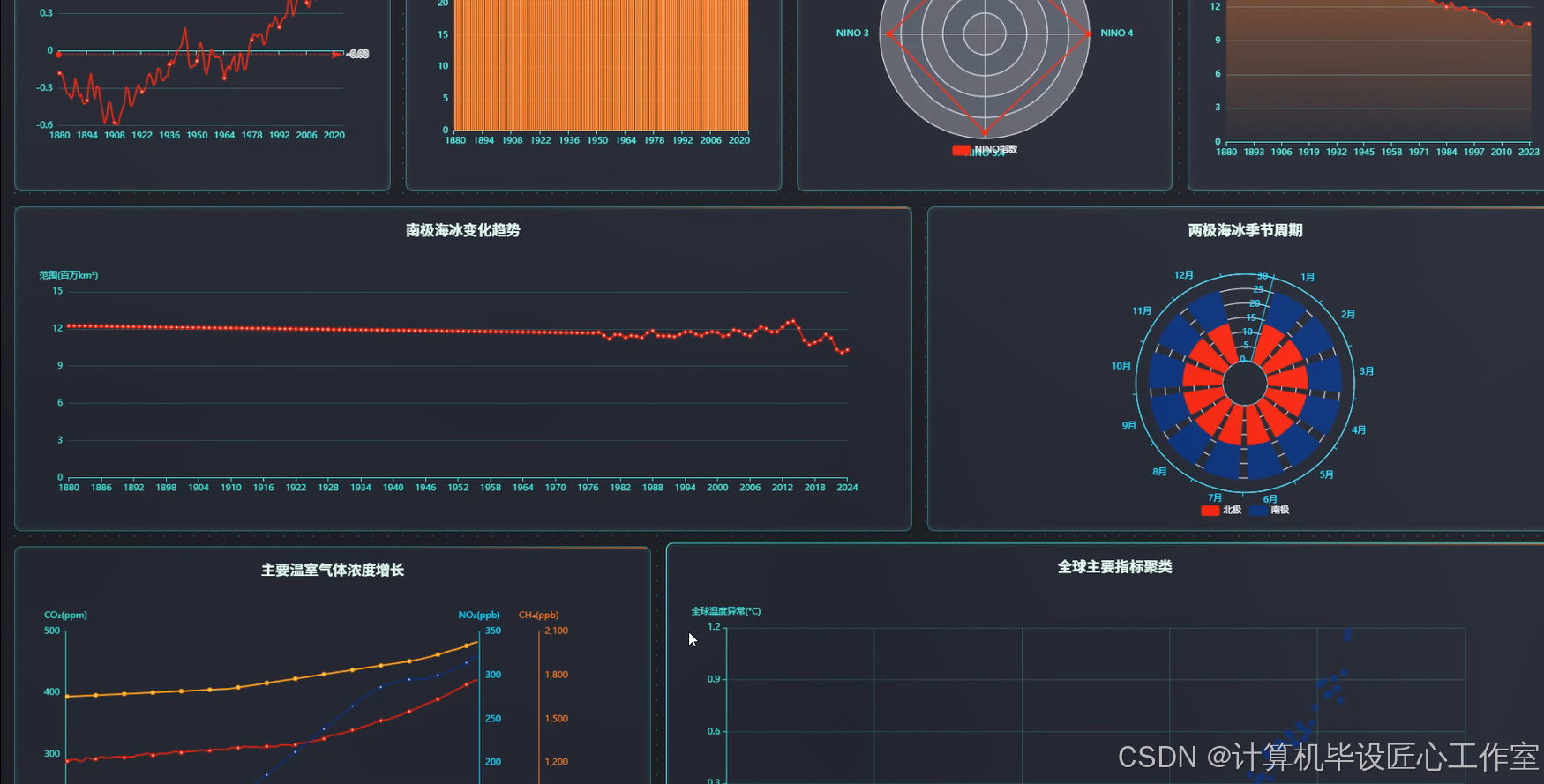
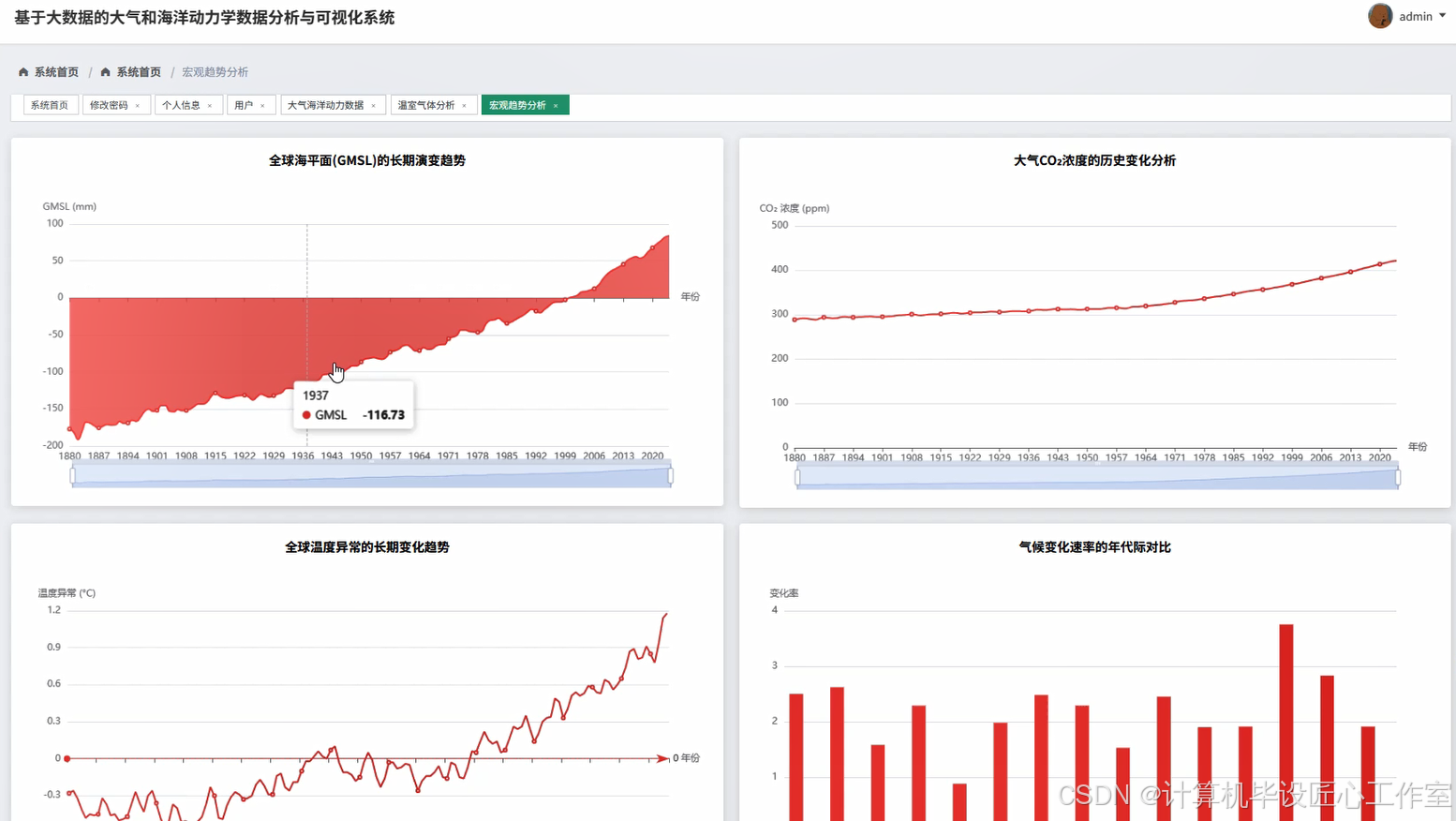
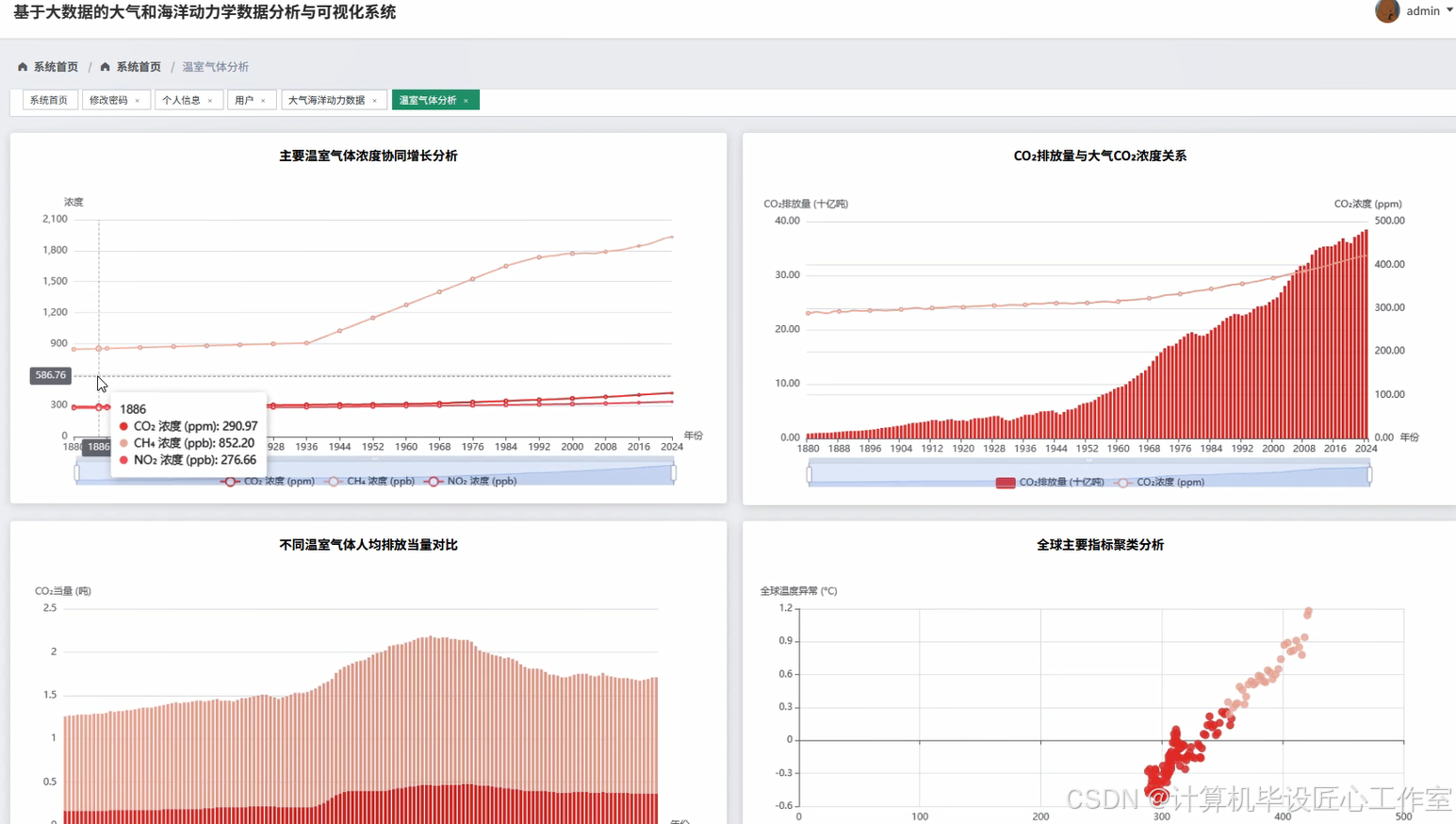
基于大数据的大气和海洋动力学数据分析与可视化系统-代码展示
python
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, year, month, desc, asc, max as spark_max, min as spark_min
from pyspark.ml.clustering import KMeans
from pyspark.ml.feature import VectorAssembler
import pandas as pd
import numpy as np
spark = SparkSession.builder.appName("OceanAtmosphereAnalysis").config("spark.sql.adaptive.enabled", "true").config("spark.sql.adaptive.coalescePartitions.enabled", "true").getOrCreate()
def analyze_global_climate_trends(data_path):
df = spark.read.option("header", "true").option("inferSchema", "true").csv(data_path)
df_with_year = df.withColumn("year", year(col("Date")))
gmsl_trends = df_with_year.groupBy("year").agg(avg("GMSL").alias("avg_gmsl"))
co2_trends = df_with_year.groupBy("year").agg(avg("CO2_conc").alias("avg_co2"))
temp_trends = df_with_year.groupBy("year").agg(avg("Global_avg_temp_anomaly_relative_to_1961_1990").alias("avg_temp_anomaly"))
combined_trends = gmsl_trends.join(co2_trends, "year").join(temp_trends, "year")
combined_trends_normalized = combined_trends.withColumn("gmsl_normalized", (col("avg_gmsl") - combined_trends.select(spark_min("avg_gmsl")).collect()[0][0]) / (combined_trends.select(spark_max("avg_gmsl")).collect()[0][0] - combined_trends.select(spark_min("avg_gmsl")).collect()[0][0]))
combined_trends_normalized = combined_trends_normalized.withColumn("co2_normalized", (col("avg_co2") - combined_trends.select(spark_min("avg_co2")).collect()[0][0]) / (combined_trends.select(spark_max("avg_co2")).collect()[0][0] - combined_trends.select(spark_min("avg_co2")).collect()[0][0]))
combined_trends_normalized = combined_trends_normalized.withColumn("temp_normalized", (col("avg_temp_anomaly") - combined_trends.select(spark_min("avg_temp_anomaly")).collect()[0][0]) / (combined_trends.select(spark_max("avg_temp_anomaly")).collect()[0][0] - combined_trends.select(spark_min("avg_temp_anomaly")).collect()[0][0]))
decadal_analysis = combined_trends.withColumn("decade", (col("year") / 10).cast("int") * 10)
decadal_rates = decadal_analysis.groupBy("decade").agg(avg("avg_gmsl").alias("decade_avg_gmsl"), avg("avg_temp_anomaly").alias("decade_avg_temp"))
decade_list = [row.decade for row in decadal_rates.select("decade").distinct().collect()]
gmsl_rate_changes = []
temp_rate_changes = []
for i in range(1, len(decade_list)):
prev_decade_data = decadal_rates.filter(col("decade") == decade_list[i-1]).collect()[0]
curr_decade_data = decadal_rates.filter(col("decade") == decade_list[i]).collect()[0]
gmsl_rate = (curr_decade_data.decade_avg_gmsl - prev_decade_data.decade_avg_gmsl) / 10
temp_rate = (curr_decade_data.decade_avg_temp - prev_decade_data.decade_avg_temp) / 10
gmsl_rate_changes.append({"decade": decade_list[i], "gmsl_rate": gmsl_rate})
temp_rate_changes.append({"decade": decade_list[i], "temp_rate": temp_rate})
acceleration_analysis = spark.createDataFrame(pd.DataFrame(gmsl_rate_changes)).join(spark.createDataFrame(pd.DataFrame(temp_rate_changes)), "decade")
correlation_data = combined_trends.select("avg_gmsl", "avg_co2", "avg_temp_anomaly").toPandas()
correlation_matrix = np.corrcoef([correlation_data["avg_gmsl"], correlation_data["avg_co2"], correlation_data["avg_temp_anomaly"]])
return combined_trends_normalized.orderBy("year"), acceleration_analysis.orderBy("decade"), correlation_matrix
def analyze_ocean_dynamics_enso(data_path):
df = spark.read.option("header", "true").option("inferSchema", "true").csv(data_path)
df_with_year = df.withColumn("year", year(col("Date")))
sst_annual_trends = df_with_year.groupBy("year").agg(avg("Sea_surface_temperature_anomaly").alias("avg_sst_anomaly"))
nino34_annual_trends = df_with_year.groupBy("year").agg(avg("Nino_3_4").alias("avg_nino34"))
enso_threshold = 0.5
enso_events = nino34_annual_trends.withColumn("enso_type", when(col("avg_nino34") > enso_threshold, "El Nino").when(col("avg_nino34") < -enso_threshold, "La Nina").otherwise("Neutral"))
enso_intensity = enso_events.withColumn("enso_intensity", when(col("avg_nino34") > 1.5, "Very Strong").when(col("avg_nino34") > 1.0, "Strong").when(col("avg_nino34") > 0.5, "Moderate").when(col("avg_nino34") < -1.5, "Very Strong La Nina").when(col("avg_nino34") < -1.0, "Strong La Nina").when(col("avg_nino34") < -0.5, "Moderate La Nina").otherwise("Weak"))
enso_frequency = enso_events.groupBy("enso_type").count().orderBy(desc("count"))
gmsl_sst_correlation = df_with_year.groupBy("year").agg(avg("GMSL").alias("avg_gmsl"), avg("Sea_surface_temperature_anomaly").alias("avg_sst"))
correlation_data_ocean = gmsl_sst_correlation.select("avg_gmsl", "avg_sst").toPandas()
thermal_expansion_correlation = np.corrcoef(correlation_data_ocean["avg_gmsl"], correlation_data_ocean["avg_sst"])[0, 1]
nino_regions_comparison = df_with_year.groupBy("year").agg(avg("Nino_1_2").alias("avg_nino12"), avg("Nino_3").alias("avg_nino3"), avg("Nino_3_4").alias("avg_nino34"), avg("Nino_4").alias("avg_nino4"))
regional_variance = nino_regions_comparison.select([variance(col(c)).alias(f"{c}_variance") for c in ["avg_nino12", "avg_nino3", "avg_nino34", "avg_nino4"]])
enso_temp_impact = nino34_annual_trends.join(df_with_year.groupBy("year").agg(avg("Global_avg_temp_anomaly_relative_to_1961_1990").alias("avg_global_temp")), "year")
enso_temp_correlation = np.corrcoef(enso_temp_impact.select("avg_nino34").toPandas().values.flatten(), enso_temp_impact.select("avg_global_temp").toPandas().values.flatten())[0, 1]
strong_enso_years = enso_events.filter((col("avg_nino34") > 1.0) | (col("avg_nino34") < -1.0)).orderBy(desc("avg_nino34"))
return sst_annual_trends.orderBy("year"), enso_events.orderBy("year"), enso_frequency, thermal_expansion_correlation, enso_temp_correlation, strong_enso_years
def analyze_polar_sea_ice_dynamics(data_path):
df = spark.read.option("header", "true").option("inferSchema", "true").csv(data_path)
df_with_date = df.withColumn("year", year(col("Date"))).withColumn("month", month(col("Date")))
north_ice_trends = df_with_date.groupBy("year").agg(avg("North_Sea_Ice_Extent_Avg").alias("avg_north_ice"))
south_ice_trends = df_with_date.groupBy("year").agg(avg("South_Sea_Ice_Extent_Avg").alias("avg_south_ice"))
polar_ice_comparison = north_ice_trends.join(south_ice_trends, "year")
seasonal_north_ice = df_with_date.groupBy("month").agg(avg("North_Sea_Ice_Extent_Avg").alias("seasonal_avg_north"))
seasonal_south_ice = df_with_date.groupBy("month").agg(avg("South_Sea_Ice_Extent_Avg").alias("seasonal_avg_south"))
seasonal_ice_patterns = seasonal_north_ice.join(seasonal_south_ice, "month").orderBy("month")
annual_ice_extremes = df_with_date.groupBy("year").agg(spark_min("North_Sea_Ice_Extent_Min").alias("north_min"), spark_max("North_Sea_Ice_Extent_Max").alias("north_max"), spark_min("South_Sea_Ice_Extent_Min").alias("south_min"), spark_max("South_Sea_Ice_Extent_Max").alias("south_max"))
ice_range_analysis = annual_ice_extremes.withColumn("north_range", col("north_max") - col("north_min")).withColumn("south_range", col("south_max") - col("south_min"))
ice_decline_rates = polar_ice_comparison.orderBy("year")
years = [row.year for row in ice_decline_rates.select("year").collect()]
north_ice_values = [row.avg_north_ice for row in ice_decline_rates.select("avg_north_ice").collect()]
south_ice_values = [row.avg_south_ice for row in ice_decline_rates.select("avg_south_ice").collect()]
north_decline_rate = np.polyfit(years, north_ice_values, 1)[0]
south_decline_rate = np.polyfit(years, south_ice_values, 1)[0]
global_temp_ice_correlation = polar_ice_comparison.join(df_with_date.groupBy("year").agg(avg("Global_avg_temp_anomaly_relative_to_1961_1990").alias("avg_global_temp")), "year")
ice_temp_data = global_temp_ice_correlation.select("avg_north_ice", "avg_global_temp").toPandas()
albedo_feedback_correlation = np.corrcoef(ice_temp_data["avg_north_ice"], ice_temp_data["avg_global_temp"])[0, 1]
critical_ice_years = polar_ice_comparison.filter((col("avg_north_ice") < polar_ice_comparison.select(avg("avg_north_ice")).collect()[0][0] - polar_ice_comparison.select(stddev("avg_north_ice")).collect()[0][0]) | (col("avg_south_ice") < polar_ice_comparison.select(avg("avg_south_ice")).collect()[0][0] - polar_ice_comparison.select(stddev("avg_south_ice")).collect()[0][0]))
return polar_ice_comparison.orderBy("year"), seasonal_ice_patterns, ice_range_analysis.orderBy("year"), north_decline_rate, south_decline_rate, albedo_feedback_correlation, critical_ice_years.orderBy("year")基于大数据的大气和海洋动力学数据分析与可视化系统-结语
👇🏻 精彩专栏推荐订阅 👇🏻 不然下次找不到哟~
Java实战项目
Python实战项目
微信小程序|安卓实战项目
大数据实战项目
PHP|C#.NET|Golang实战项目🍅 主页获取源码联系🍅