
【导读】
3D点云目标跟踪是自动驾驶、机器人等领域的关键任务,但不同类别物体的几何差异让模型难以"一招通吃"。本文介绍的 TrackAny3D,首次提出将大规模预训练3D模型迁移到点云单目标跟踪任务,实现了 类别无关、统一建模,并在多个数据集上取得SOTA成绩。>>更多资讯可加入CV技术群获取了解哦
在自动驾驶、机器人感知、安防监控等领域,三维点云单目标跟踪(3D SOT) 是一项基础且关键的能力。任务的核心,是让系统在一段动态点云序列中持续锁定某个目标物体(例如汽车、行人或自行车),输出其位置和姿态。
相比依赖纹理和颜色的RGB视频跟踪,**基于LiDAR的3D点云跟踪只有稀疏、无序的点作为线索。**这带来两个核心难题:
-
**几何差异巨大:**汽车、行人、骑行者的尺寸、运动模式和结构复杂度差异极大。
-
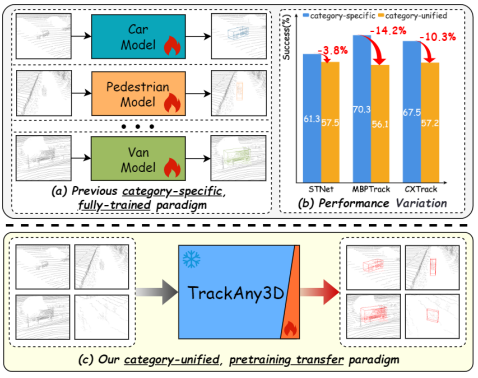
**类别专属瓶颈:**现有方法普遍采用"一个类别一个模型",虽然精度高,但实用性差,既占用算力和存储,又缺乏泛化能力。
研究发现,当这些方法尝试在所有类别上训练一个统一模型时,性能会明显下降。这让"统一建模"长期成为难以跨越的障碍。
与此同时,大规模预训练模型在图像和自然语言处理领域掀起了革命:CLIP、LLaMA 等基础模型展现出极强的迁移与泛化能力。那么,3D点云领域能否借助预训练模型的几何先验,解决类别统一的问题?
这正是本文提出的TrackAny3D的突破所在
在Coovally平台上包括多模态3D检测、目标追踪、目标检测、文字识别、实例分割、关键点检测等全新任务类型。

!!点击下方链接,立即体验Coovally!!
平台链接: https://www.coovally.com
平台汇聚国内外开源社区超1000+ 热门模型,覆盖YOLO系列、Transformer、ResNet等主流视觉算法。同时集成300+公开数据集,一键下载即可投入训练,彻底告别"找模型、配环境、改代码"的繁琐流程!

一、模型方法:TrackAny3D 的核心思路
TrackAny3D 的目标是**用一个统一的模型,追踪任何类别的目标。**为此,作者设计了三大核心模块:
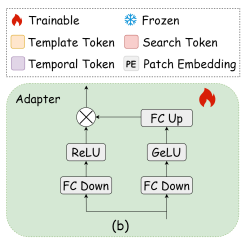
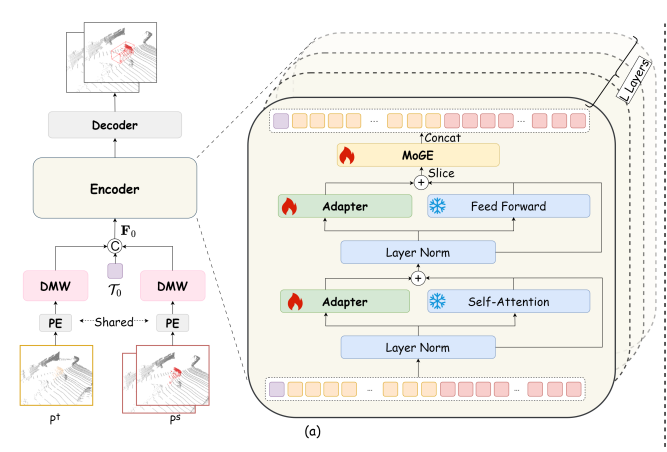
参数高效适配器(Adapter)
在预训练Transformer层中加入"双路径适配器":
-
**特征适配路径:**对预训练特征进行下采样、激活、上采样,实现对齐;
-
**强度调节路径:**通过动态权重控制适配程度。
这样既保留了预训练模型的几何先验,又能高效适配到跟踪任务。
与全量微调相比,这种 参数高效迁移(PEFT) 能显著减少训练开销,并避免覆盖掉已有知识。
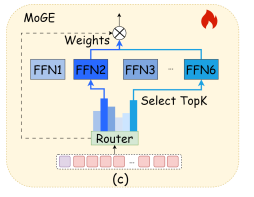
几何专家混合 (MoGE, Mixture-of-Geometry-Experts)
借鉴 Mixture-of-Experts 的思想,引入多个"几何专家"子网络。
模型会根据输入物体的几何特征,自适应选择激活哪些专家:
-
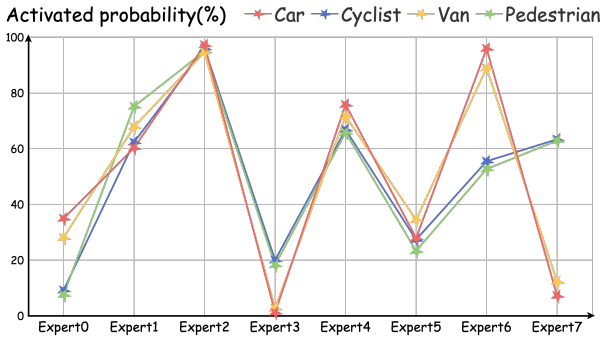
刚体目标(如汽车、货车)更多激活 Expert 0、6;
-
非刚体目标(如行人、自行车)则偏向 Expert 3、7。
这让模型摆脱了对类别标签的依赖,转而从几何形态出发,解决跨类别差异。
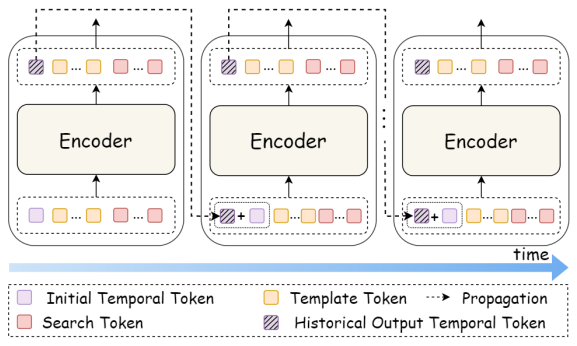
时间上下文优化 (Temporal Context Optimization)
3D跟踪不仅是静态几何匹配,更关乎时间序列的连贯性。为此,作者提出:
-
**时间token传播:**在每一帧中引入可学习时间token,并将历史信息传递到后续帧,减少跟踪漂移。
-
动态掩码加权 (DMW) **:**对模板和搜索区域的点云掩码赋予可学习权重,使模型能自适应区分前景与背景噪声。
实验表明,这一设计能在拥挤场景中保持稳定目标定位。
二、技术创新点总结
TrackAny3D 的贡献主要体现在三个方面:
-
**首次将大规模3D预训练模型迁移到点云跟踪,**避免了传统方法中"每个类别一个模型"的限制。
-
引入几何专家混合(MoGE),通过几何特征自适应选择专家,真正实现"类别无关"的统一模型。
-
提出时间上下文优化,结合时间token和动态掩码,让模型在长期跟踪和复杂场景下依旧稳健。
这三个设计环环相扣,解决了预训练迁移面临的三大难题:分布差异、几何冲突、缺乏时间建模。
三、实验结果与表现
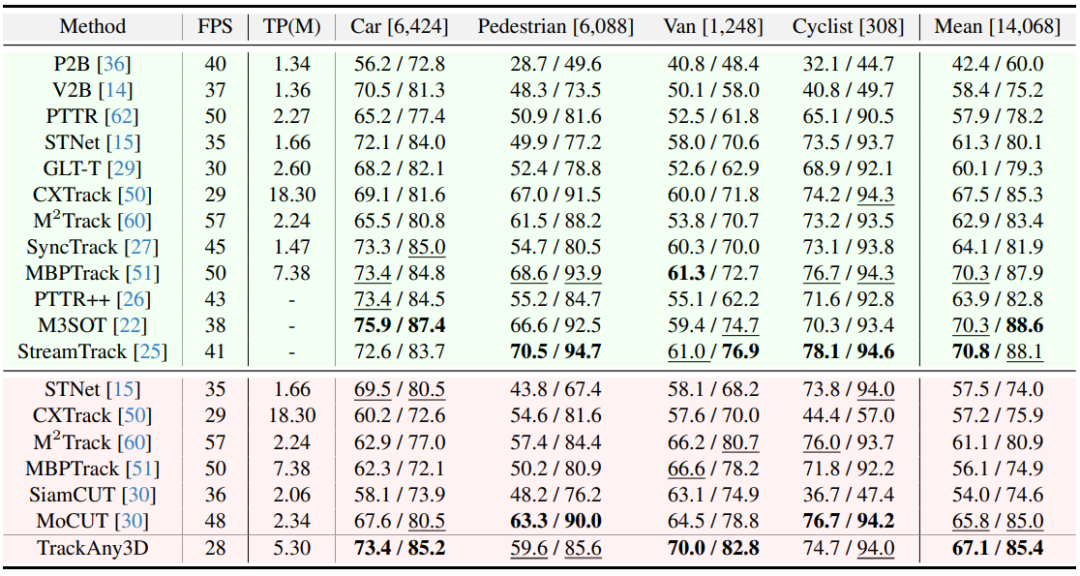
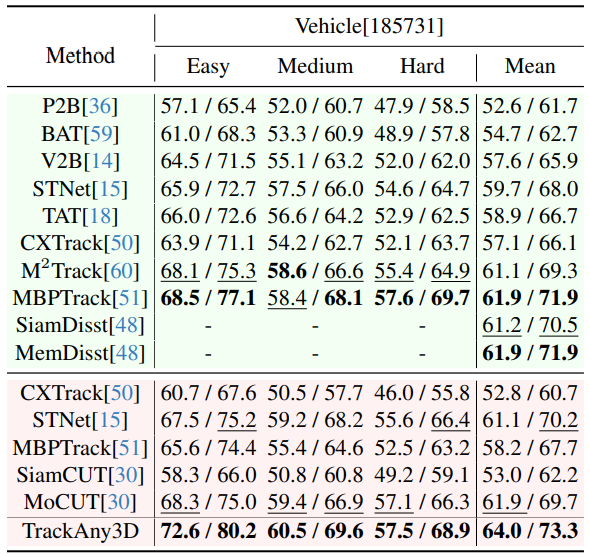
KITTI数据集
类别统一条件下,TrackAny3D 的平均成功率达到67.1%,超越了所有方法,尤其比MoCUT高1.3%。
在Car类别上更是领先6%,证明了其在大规模类别差异下的鲁棒性。
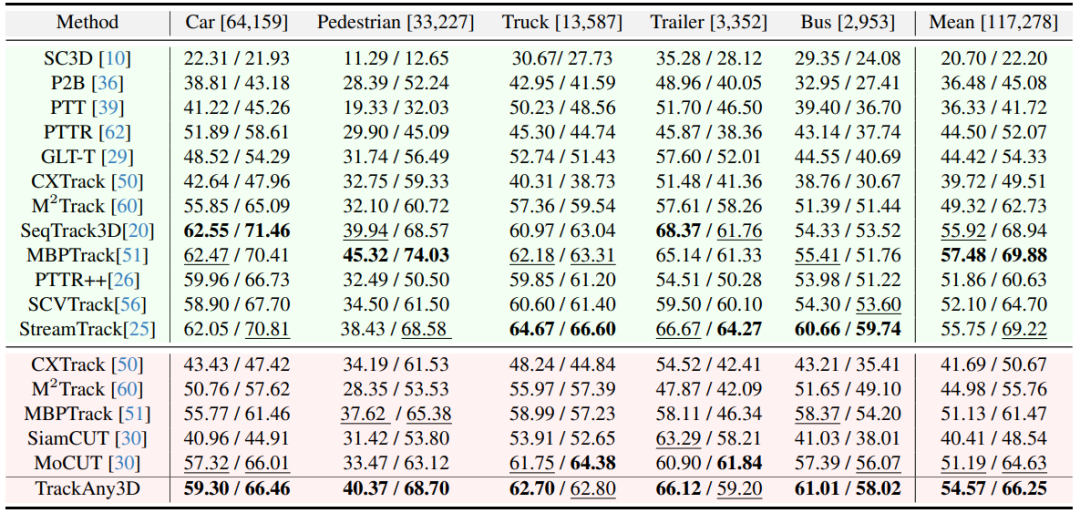
NuScenes数据集
在长尾类别(如Truck、Bus、Trailer)表现尤为突出,甚至超过了类别专属训练的模型。
整体上,TrackAny3D 在统一设置下依旧领先,验证了几何专家机制的有效性。
Waymo Open Dataset
使用在KITTI上训练的模型,直接推理Waymo数据,仍然取得64.0%的领先表现。
说明TrackAny3D不仅跨类别强,还能跨数据集泛化。
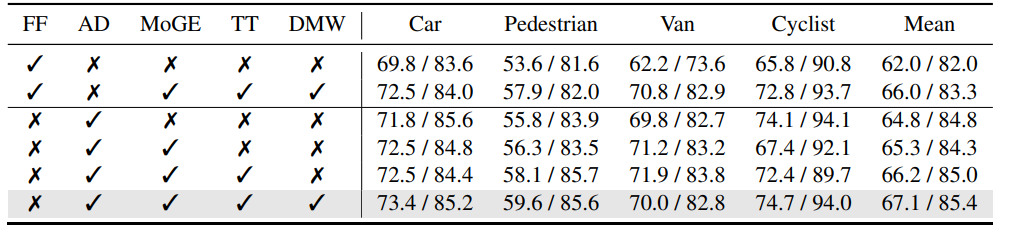
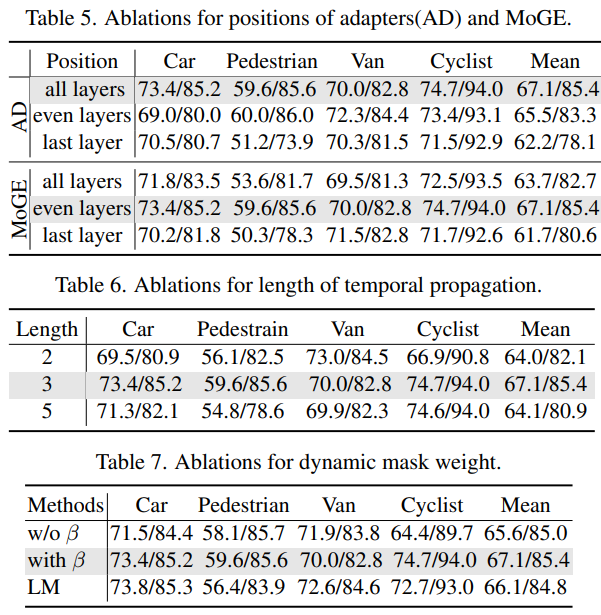
消融实验
Adapter、MoGE、时间token和DMW均被验证为有效模块,逐步提升性能。
实验证明:MoGE不宜过多堆叠,适度插入能避免过拟合。
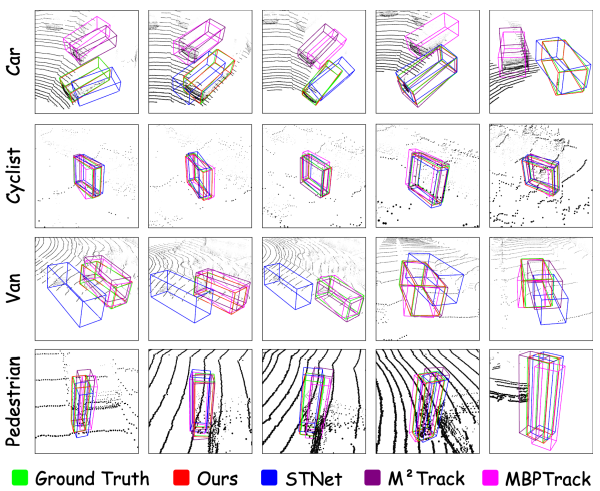
可视化结果
在点云稀疏、背景复杂或人群密集场景下,TrackAny3D 依然能与真实目标高度对齐,而其他方法则出现偏移或丢失。
总结与展望
TrackAny3D 跨越了点云跟踪的长期难题:不再为每个类别单独训练模型,而是用一个统一模型应对所有类别。它不仅性能领先,还降低了实际部署成本,在自动驾驶、机器人、监控等场景中都有直接应用价值。
未来方向:
-
**更大规模的预训练模型:**随着3D数据集扩展,几何先验会更强。
-
**多模态融合:**结合视觉、点云与语义信息,进一步提升复杂环境下的鲁棒性。
-
**开放世界跟踪:**真正做到"遇见任何目标,都能稳定追踪"。
TrackAny3D 的出现,意味着点云跟踪开始走向 "大一统"的新阶段。
