
多尺度的transformer网络IQA:MUSIQ:Multi-scale Image Quality Transformer(2021 ICCV)
- 专题介绍
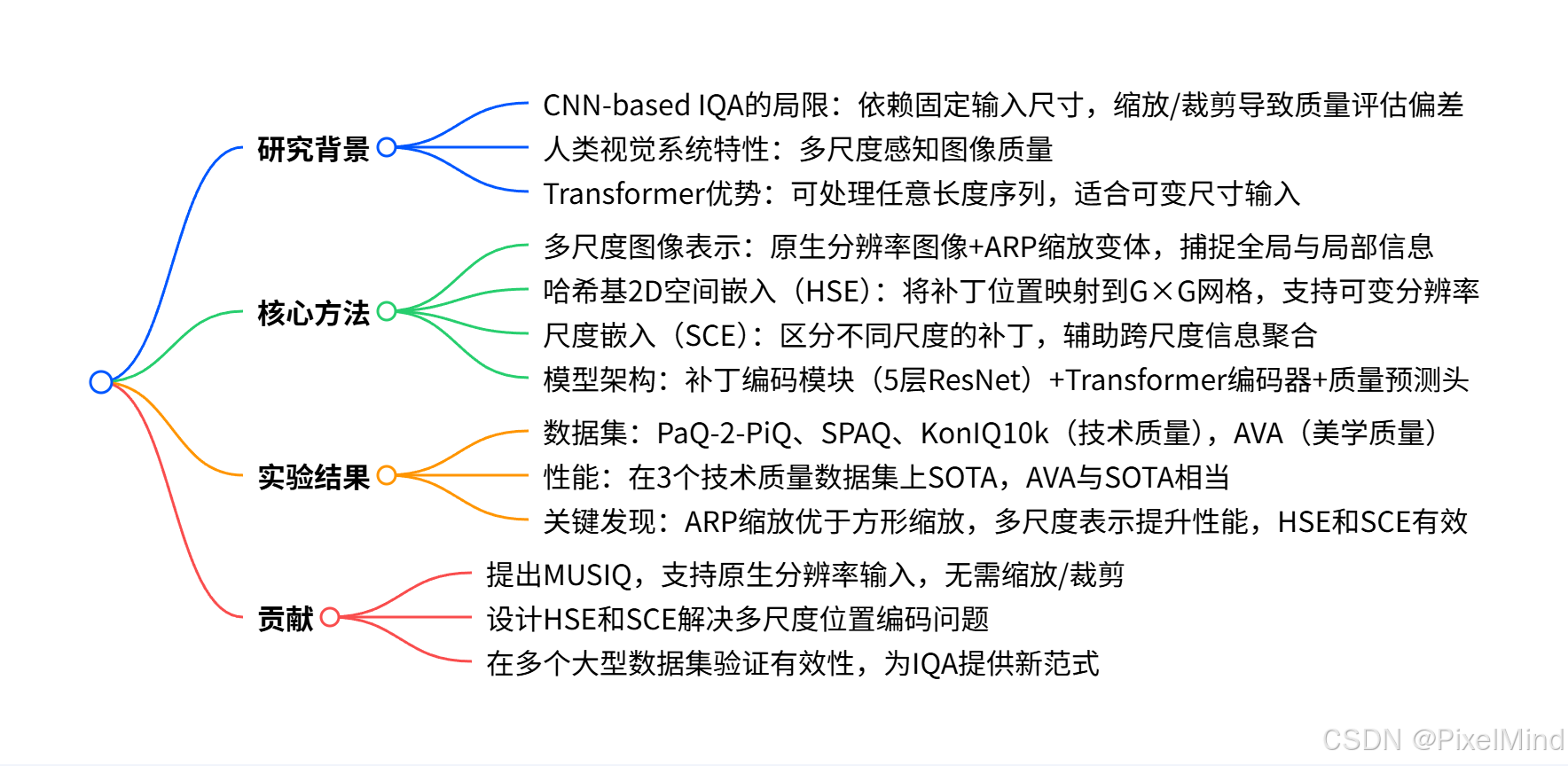
- 一、研究背景
- 二、MUSIQ方法
-
- [2.1 Multi-scale Patch Embedding](#2.1 Multi-scale Patch Embedding)
- [2.2 Hash-based 2D Spatial Embedding](#2.2 Hash-based 2D Spatial Embedding)
- [2.3 Scale Embedding](#2.3 Scale Embedding)
- [2.4 预训练和微调](#2.4 预训练和微调)
- 三、实验
- 四、总结
本文将围绕《MUSIQ:Multi-scale Image Quality Transformer》展开完整解析。该文章设计的指标在很多图像复原算法的测评中会看到,MUSIQ的特点在于其可以解决卷积神经网络(CNN)在图像质量评估(IQA)中因固定输入尺寸限制导致的图像质量失真问题。参考资料如下:
1. 论文地址
2. 代码地址
论文整体结构思维导图如下:
专题介绍
图像质量评价(Image Quality Assessment, IQA)是图像处理、计算机视觉和多媒体通信等领域的关键技术之一。IQA不仅被用于学术研究,更在影像相关行业内实现了完整的商业化应用,涉及影视、智能手机、专业相机、安防监控、工业质检、医疗影像等。IQA与图像如影随形,其重要程度可见一斑。
但随着算法侧的能力不断突破,AIGC技术发展火热,早期的IQA或已无法准确评估新技术的能力。另一方面,千行百业中各类应用对图像质量的需求也存在差异和变化,旧标准也面临着适应性不足的挑战。
本专题旨在梳理和跟进IQA技术发展内容和趋势,为读者分享有价值、有意思的IQA。希望能够为底层视觉领域内的研究者和从业者提供一些参考和思路。
系列文章如下:
【1】🔥IQA综述
【2】PSNR&SSIM
【3】Q-Insight
【4】VSI
【5】LPIPS
【6】DISTS
【7】Q-align
【8】GMSD
【9】NIQE
一、研究背景
研究动机在于,CNN 在 IQA 中存在局限性:传统 CNN-based IQA 模型需将输入图像缩放或裁剪为固定尺寸(如 224×224)以适应批量训练,这会改变图像构图或引入失真,影响质量评估准确性。当然也有一些解决方法,例如:
- 多裁剪集成方法,这会显著增加推理成本。
- MNA-CNN 一次仅处理单张图像,训练效率低。MNA-CNN是作者引用中提到的一个方法,这个方法通过自适应池化将不同的分辨率图像转换为fixed-size的特征图,但是这导致训练时每次只能处理一张图像,因此作者说其训练效率低。
- 自适应卷积(adaptive fractional dilated convolution),可以减小因宽高比变换引入的失真,但是其仍需缩放,会改变原有的分辨率。
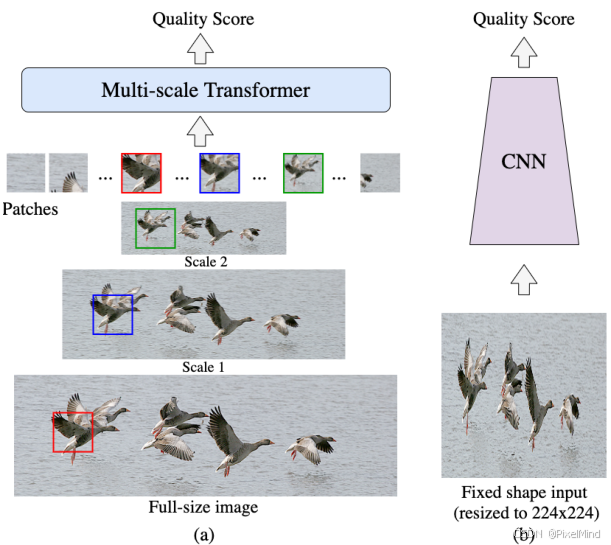
这就提到了本文的基于Transformer的IQA方法,基于patch的 Transformer 可处理任意数量的patch(受内存限制),无需固定输入分辨率,适合原生尺寸图像的 IQA 任务。本文和传统方法的对比可见下图,图(a)是本文的方法。
二、MUSIQ方法
学习该论文中,需要有VIT模型结构的前置知识,这里简单给大家回忆下:假设VIT的输入是224x224,patch_size设置为16,那么VIT会将输入打成224/16*224/16=196个patch,tensor整体的一个变换情况是:
原始图像:(1, 224, 224, 3) --------------> patch打平:(1, 196, 768) --------------> embedding:(1, 196, 768) --------------> 添加位置编码以及分类token:(1, 197, 768) --------------> encoder,一些transformer经典结构:(1, 197, 768) --------------> 取出分类token:(1, 1, 768) --------------> 获取最终的分类分数:(1, 1, 1)。
本文的整体结构如下,论文方法是不修改VIT整体结构的,只对embedding进行了修改,包含原有的位置编码和新加入了一个尺度的编码:
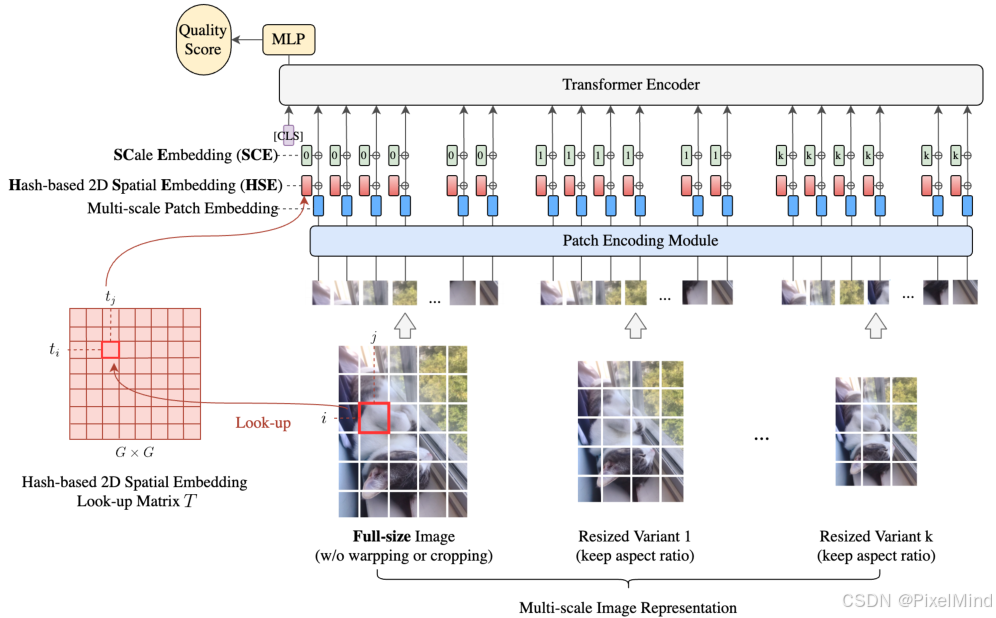
MUSIQ 通过多尺度表示、空间嵌入和尺度嵌入处理可变尺寸输入,由三部分组成:
- 多尺度补丁嵌入:生成原生分辨率图像及其纵横比保持(ARP)缩放变体的补丁序列;就是最下面一行,多个不同尺寸的保持宽高比的图像序列,作者总共生成了k个,实际使用时k=3,即有3个不同大小相同宽高比的图像被打成序列输入进网络。
- 哈希基 2D 空间嵌入:编码补丁的 2D 空间位置;此模块是为了优化原有VIT的位置编码功能,由于我们进行了resize调整了绝对位置,如果还是用绝对位置编码应用到各个不同分辨率输入上显然是不合理的,此为一个hash-based的2D编码,可以解决这个问题。
- 尺度嵌入(SCE):区分不同尺度的补丁;此为了将我们resize的倍数作为信息也编码进去,因为这也是一个重要的先验信息。
最终通过 Transformer 编码器聚合信息,输出质量评分。下面分点进行讲解。
2.1 Multi-scale Patch Embedding
ARP resize出一系列keep_ratio的图,使用一个长宽相同的缩放因子进行缩放,至于ARP resize是一个用高斯核的下采样方法,如下式所示: α k = L k / max ( H , W ) , h k = α k H , w k = α k W \alpha_{k} = {L_{k}}/{\max(H, W)}, \quad h_{k} = \alpha_{k} H, \quad w_{k} = \alpha_{k} W αk=Lk/max(H,W),hk=αkH,wk=αkW其中 L k L_k Lk是最长边的大小, k k k代表第 k k k次的结果,然后作用到当前的宽高上就可以得到现有的宽高了。
接着就是要将图像转为patch,在每个图上裁size为 P P P的正方形,如果 P P P不够,会使用zero padding将不够的位置进行填充,接着对这个token进行encoding,使用的网络是一个5层的ResNet,使用到的权重是全局共享的,不像原始的VIT,是各个位置使用一个不同的权重。
针对于原始图像,计算出的序列为 H ∗ W / P / P H*W/P/P H∗W/P/P,当然这里更合适的描述是 c e i l ( H / P ) ∗ c e i l ( W / P ) ceil(H/P)*ceil(W/P) ceil(H/P)∗ceil(W/P),对于降采样的图像自然是 c e i l ( h / P ) ∗ c e i l ( w / p ) ceil(h/P) * ceil(w/p) ceil(h/P)∗ceil(w/p),由于分辨率可变,意味着这里的序列长度会变化,这里是用于0填充来填充不够的位置,由于有0填充的存在,针对于自注意力求取attention_weight时的mask需要改变,保证这部分0填充不会影响到结果。
对于缩小后的图像,他的序列长度一定会小于原长度,即: n k ≤ L k 2 / P 2 = m k n_k \leq {L_k^2}/{P^2} = m_k nk≤Lk2/P2=mk其中 L k L_k Lk和 P P P是刚才讲过的最长边和patch size,显然这个公式成立,缩小后的图像转换后的序列长度不可能大于这个值,对于任何采样输入,可以限制到 m k m_k mk。作者提出这个点只是为了说设置网络时,可以使用一个随意大小的序列长度,最简单的就是设计一个多倍的最大长度即可,这样可以统一不同的分辨率输入。
2.2 Hash-based 2D Spatial Embedding
传统的方法简单粗暴,存在两个问题,一是无法应用于可变尺寸的图像,二是无法应用于多尺度的图像,毕竟同一个位置,可能代表着不同的东西。作者提供了一个思路:哈希映射,如下式所示: t i = i × G H / P , t j = j × G W / P t_{i} = \frac{i \times G}{H / P}, \quad t_{j} = \frac{j \times G}{W / P} ti=H/Pi×G,tj=W/Pj×G其中, i i i和 j j j是当前patch的位置, G G G是哈希表的大小,哈希表实际大小是 (G, G, D),也就是这个操作进行了一个简单的round映射,没有其他复杂的设定。
显然G如果选的太小,会使得很多位置使用同样的embedding,太大会浪费性能,作者设定的是G=10
2.3 Scale Embedding
由于哈希embedding没有区分不同尺度,通过上述描述可以发现其不同尺度映射的位置都是一样的,所以额外加了一个scale embedding,尺寸是 (K+1,D)K是指降采样图像个数。
2.4 预训练和微调
作者对模型进行了预训练,因为Transformer模型通常需要在大型数据集(例如ImageNet)上进行预训练,并对下游任务进行微调。在预训练过程中,使用随机裁剪作为增强,生成不同大小的图像。并且没有像图像分类中常见的做法那样进行方形大小调整,而是故意跳过大小调整来为具有不同分辨率和纵横比的输入启动模型。另外还使用其他常见的增强,如RandAugment和mixup。
当对IQA任务进行微调时,不调整输入图像的大小或裁剪以保持图像的组成和比例。只使用随机水平翻转来增强。评估中可以直接应用于原始图像,而不需要聚合多个增强(例如multi-crop采样)。
训练使用的损失有两个部分:L1和EMD损失,EMD损失形式如下: EMD ( p , p ^ ) = ( 1 N ∑ m = 1 N ∣ CDF p ( m ) − CDF p ^ ( m ) ∣ r ) 1 r \text{EMD}(p, \hat{p}) = \left( \frac{1}{N} \sum_{m=1}^{N} \left| \text{CDF}{p}(m) - \text{CDF}{\hat{p}}(m) \right|^{r} \right)^{\frac{1}{r}} EMD(p,p^)=(N1m=1∑N∣CDFp(m)−CDFp^(m)∣r)r1
其中EMD损失中的 p p p是指归一化的分数分布,CDF指累计分布函数,EMD损失跟L1损失的区别在于,L1损失是对一个单一分数进行优化,EMD则是对整体的评分分布进行优化。
三、实验
论文训练了一个单尺度和一个三尺度的网络,即第一步不进行下采样和进行2次下采样。首先都会预训练ImageNet再微调。
定量实验如下:
在 4 个大型数据集上验证,结果如下:
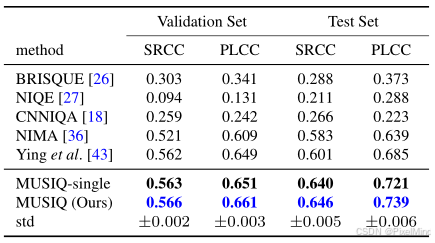
在PaQ-2-PiQ数据集上,MUSIQ 的 SRCC=0.646、PLCC=0.739,显著优于现有方法。
在KonIQ-10k数据集上,MUSIQ SRCC=0.916、PLCC=0.928,超过 BIQA 等 SOTA。
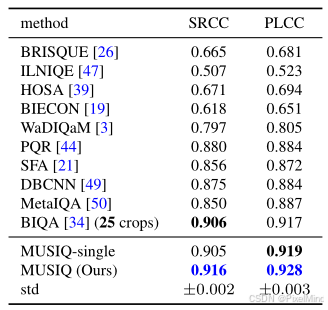
在SPAQ数据集上,整体性能最优,SRCC 和 PLCC 均领先。
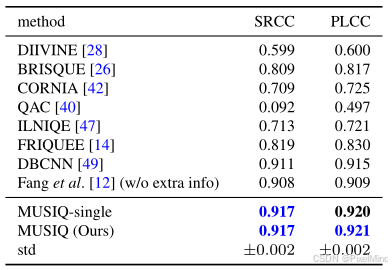
在AVA美学评估上,MSE 最佳,SRCC 和 PLCC 与 SOTA 相当。
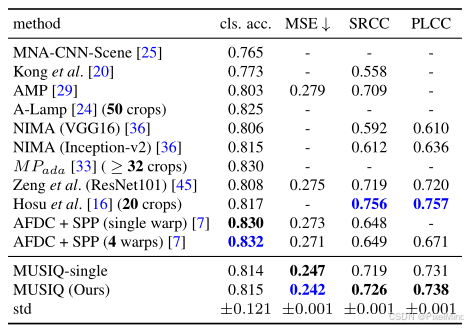
消融实验如下:
ARP 缩放的重要性:ARP 缩放(SRCC=0.726)优于方形缩放(SRCC=0.707),能检测非自然缩放导致的质量下降。
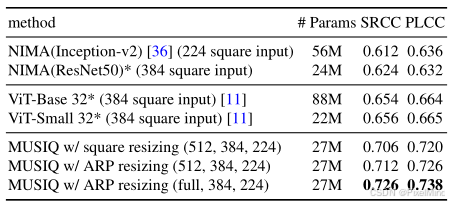
多尺度的增益:在前面定量实验中可以看到,4个数据集多尺度比单尺度都要好。作者还进行了不同尺寸的组合结果。
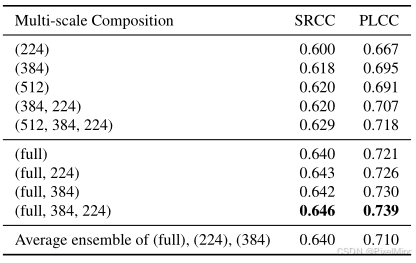
最后的结果就是选择full,384和224,原生 + 384+224 尺度组合(SRCC=0.646)优于单尺度(SRCC=0.640)。
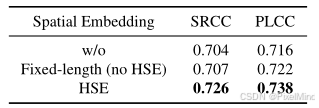
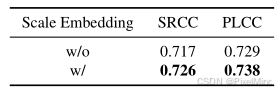
HSE 和 SCE 的有效性:HSE(SRCC=0.722)优于固定长度嵌入(SRCC=0.707),SCE 可提升 SRCC 至 0.726,如下图所示。
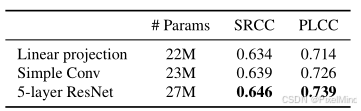
patch encodeing 的选择:选择一个合适的patch编码器,作者尝试的最后结论是一个5层的resnet。
四、总结
该论文提出 MUSIQ,通过设计的哈希位置编码和尺度编码支持原生分辨率输入,解决 CNN 的固定尺寸限制,并且在多个数据集上验证 SOTA 性能。很好的解决了卷积神经网络(CNN)在图像质量评估(IQA)中因固定输入尺寸限制导致的图像质量失真问题。
感谢阅读,欢迎留言或私信,一起探讨和交流,如果对你有帮助的话,也希望可以给博主点一个关注,谢谢。