1 前言
YOLO训练时报错
NVIDIA GeForce RTX 5070 Ti with CUDA capability sm_120 is not compatible with the current PyTorch installation.
The current PyTorch install supports CUDA capabilities sm_50 sm_60 sm_61 sm_70 sm_75 sm_80 sm_86 sm_90.
IF you want to use the NVIDIA GeForce RTX 5090 D GPU with PyTorch, please check the instructions at ... 如下图中内容

本文将针对50系使用的NVIDIA的sm_120,也就是Blackwell架构在常用的深度学习环境配置中无法正常训练导致的问题进行一些解决,简单的方式就是使用CUDA12.8及Pytorch2.7.0版本。本文将对于下面几个我的教程中出现的50系(如5060、5070、5080、5090等)无法训练进行统一的解决,确保可以正常训练。
超详细目标检测:YOLOv11(ultralytics)训练自己的数据集,新手小白也能学会训练模型,手把手教学一看就会-CSDN博客
目标检测:YOLOv12训练自己的数据集,手把手教学一看就会-CSDN博客
YOLOv13教程:YOLOv13训练模型,超详细适合0基础小白快速上手-CSDN博客
对于其他的深度学习算法也可以尝试
2 报错自查
如果不确定自己是否存在这个问题,可以运行下面的代码查看是否有上面的报错
python
# 作者:CSDN-笑脸惹桃花 https://xiaolian.blog.csdn.net/
import sys
import platform
import importlib.metadata
from typing import Optional
def check_module_version(module_name: str) -> Optional[str]:
try:
return importlib.metadata.version(module_name)
except importlib.metadata.PackageNotFoundError:
return None
def check_environment():
# 系统信息
print("=" * 50)
print("System and Environment Information")
print("=" * 50)
print(f"Operating System: {platform.system()}")
print(f"Python Version: {sys.version}")
print(f"Python Executable: {sys.executable}")
print("\nPython Sys Path:")
for path in sys.path:
print(f" {path}")
# 分隔线
print("\n" + "=" * 50)
print("Deep Learning Libraries")
print("=" * 50)
# 检查 PyTorch
try:
import torch
print(f"PyTorch Version: {torch.__version__}")
print(f"PyTorch CUDA Version: {torch.version.cuda}")
print(f"PyTorch CUDA Available: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"CUDA Device Count: {torch.cuda.device_count()}")
for i in range(torch.cuda.device_count()):
print(f" GPU {i}: {torch.cuda.get_device_name(i)}")
else:
print("No CUDA-capable GPU detected.")
except ImportError:
print("PyTorch not installed.")
# 检查其他常用库
print("\nOther Dependencies:")
libraries = ["numpy", "opencv-python", "pillow", "matplotlib", "scipy"]
for lib in libraries:
version = check_module_version(lib)
print(f"{lib}: {version if version else 'Not installed'}")
if __name__ == "__main__":
check_environment()3 CUDA卸载并升级
首先如果跟着其他教程安装的CUDA版本低于12.8的,都需要下载CUDA12.8版本,这里我给出下载链接
CUDA Toolkit Archive | NVIDIA Developerhttps://developer.nvidia.com/cuda-toolkit-archive在这个网站挑选下载或者直接点击夸克网盘下载或者点此下载。
对于CUDA版本低于12.8的,50系以上显卡建议卸载,可以参考下面的链接卸载
升级NVIDIA显卡驱动及卸载CUDA_cuda升级-CSDN博客
卸载完成后即可安装CUDA12.8,安装选项里选择自定义就可以
安装好后如下图
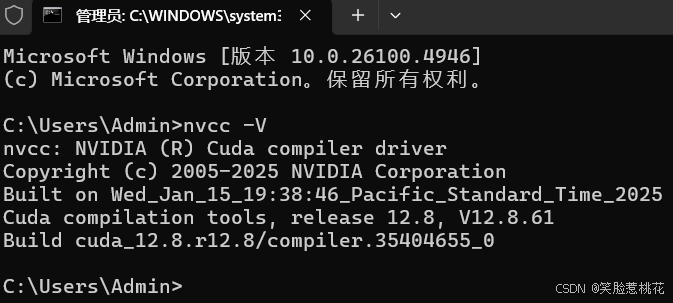
打开cmd,输入 nvcc -V 之后出现下面的内容即正常
安装完CUDA之后,可以选择是否安装cuDNN,需要安装的话在我其他的教程里都有提到,这里只给个CUDA12.8对应的cuDNN版本网盘下载链接 夸克网盘分享
4 conda虚拟环境更新
4.1 删除老环境
之后如果有之前安装的深度学习环境,需要先删除之前装好的环境,使用下面的命令 conda remove -n 环境名 --all
这里我用之前发的YOLOv13环境配置教程做演示,其他算法原理类似
bash
conda remove -n yolov13 --all需要连着输入两次y,确保环境删除干净
4.2 新建新环境
之后重新创建环境,跟之前的创建环境命令一样
python
conda create -n yolov13 python=3.114.3 安装torch
创建完成之后,首先安装torch,选择版本为2.7.0安装
bash
pip install torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --index-url https://download.pytorch.org/whl/cu128
torch库较大,耐心等待
4.4 安装其它所需库
安装完成之后根据教程中的继续安装其它所需库,比如YOLOv13需要安装requirements.txt中所有库,先将下面的内容复制到requirements.txt文件中保存,这一步非常重要,很多错误是因为这里没有替换
bash
#torch==2.2.2
#torchvision==0.17.2
#flash_attn-2.7.3+cu11torch2.2cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
timm==1.0.14
albumentations==2.0.4
onnx==1.14.0
onnxruntime==1.15.1
pycocotools==2.0.7
PyYAML==6.0.1
scipy==1.13.0
onnxslim==0.1.31
onnxruntime-gpu==1.18.0
gradio==4.44.1
opencv-python==4.9.0.80
psutil==5.9.8
py-cpuinfo==9.0.0
huggingface-hub==0.23.2
safetensors==0.4.3
numpy==1.26.4
supervision==0.22.0
thop首先cd到YOLOv13的路径下,输入下面的命令
bash
pip install -r requirements.txt不知道相对路径和绝对路径的可以看下面的教程,这个之前也发过
电脑小白科普------命令行中的相对路径与绝对路径_windows绝对路径和相对路径-CSDN博客
全部安装完成后,如下图所示
4.5 安装flash-attentio
YOLOv13还需要安装flash-attention,需要根据CUDA版本和torch版本以及python版本选择合适的flash-attention版本,下载网站如下
Windows:Releases · kingbri1/flash-attention · GitHub
Linux:Releases · Dao-AILab/flash-attention · GitHub
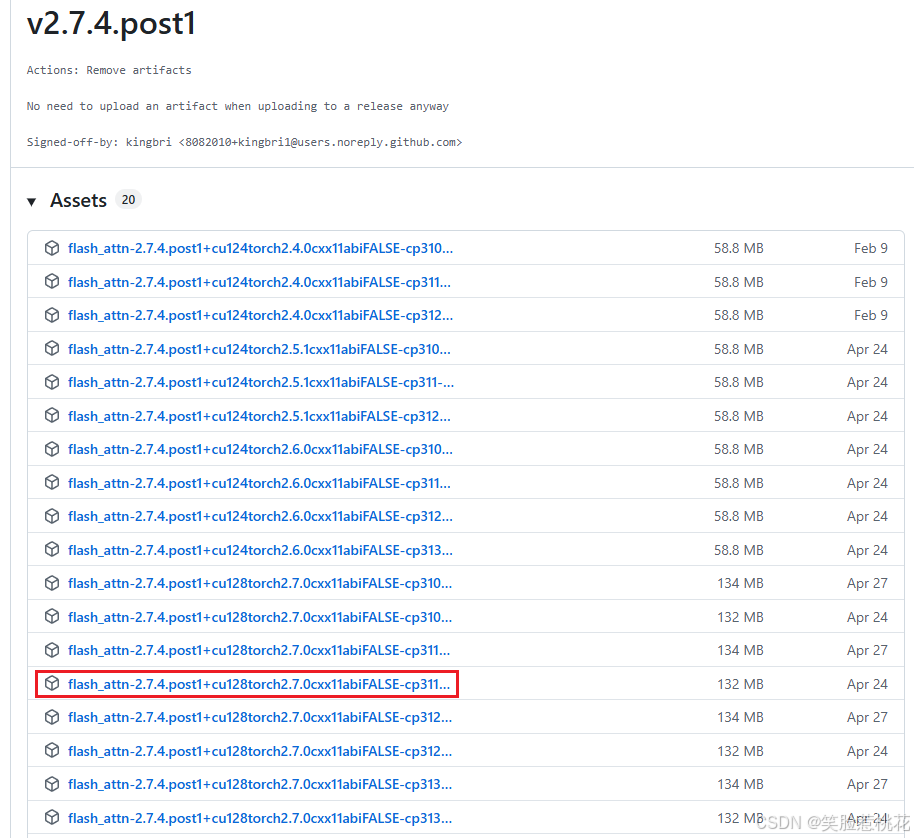
下载红框里的版本即可,也可以点击网盘下载 夸克网盘分享
之后仍然是使用相对路径安装,输入如下命令
bash
pip install flash_attn-2.7.4.post1+cu128torch2.7.0cxx11abiFALSE-cp311-cp311-win_amd64.whl5 训练模型
安装完成就可以训练模型,需要先将pycharm或者其他开发软件的环境删除原有的并添加新的,选择好后仍然使用原本的训练代码就可以
python
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/v13/yolov13n.yaml')
model.load('yolov13n.pt') #注释则不加载
results = model.train(
data='data.yaml', #数据集配置文件的路径
epochs=200, #训练轮次总数
batch=16, #批量大小,即单次输入多少图片训练
imgsz=640, #训练图像尺寸
workers=8, #加载数据的工作线程数
device= 0, #指定训练的计算设备,无nvidia显卡则改为 'cpu'
optimizer='SGD', #训练使用优化器,可选 auto,SGD,Adam,AdamW 等
amp= False, #True 或者 False, 解释为:自动混合精度(AMP) 训练
cache=False # True 在内存中缓存数据集图像,服务器推荐开启
)数据集加载完成后运行训练就可以
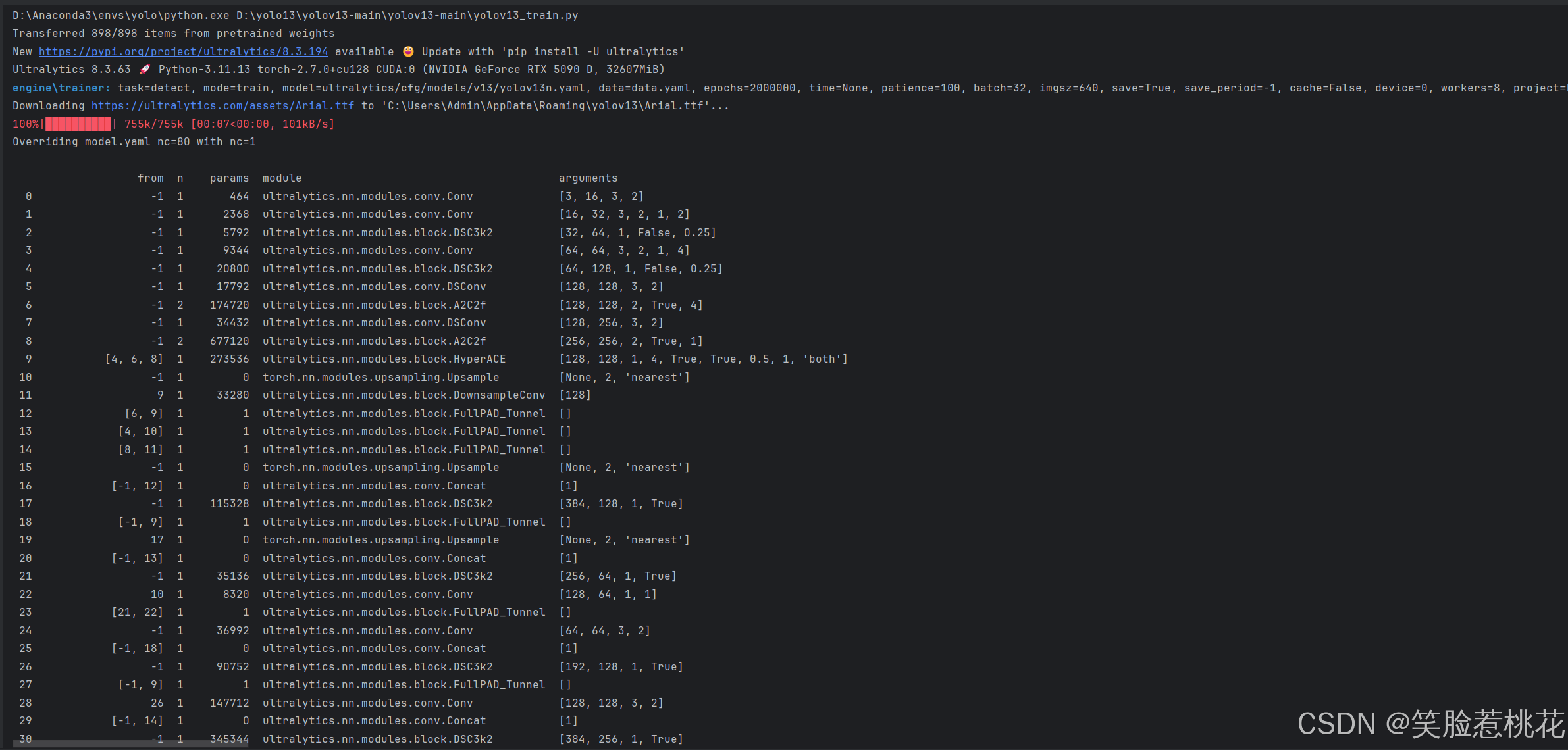
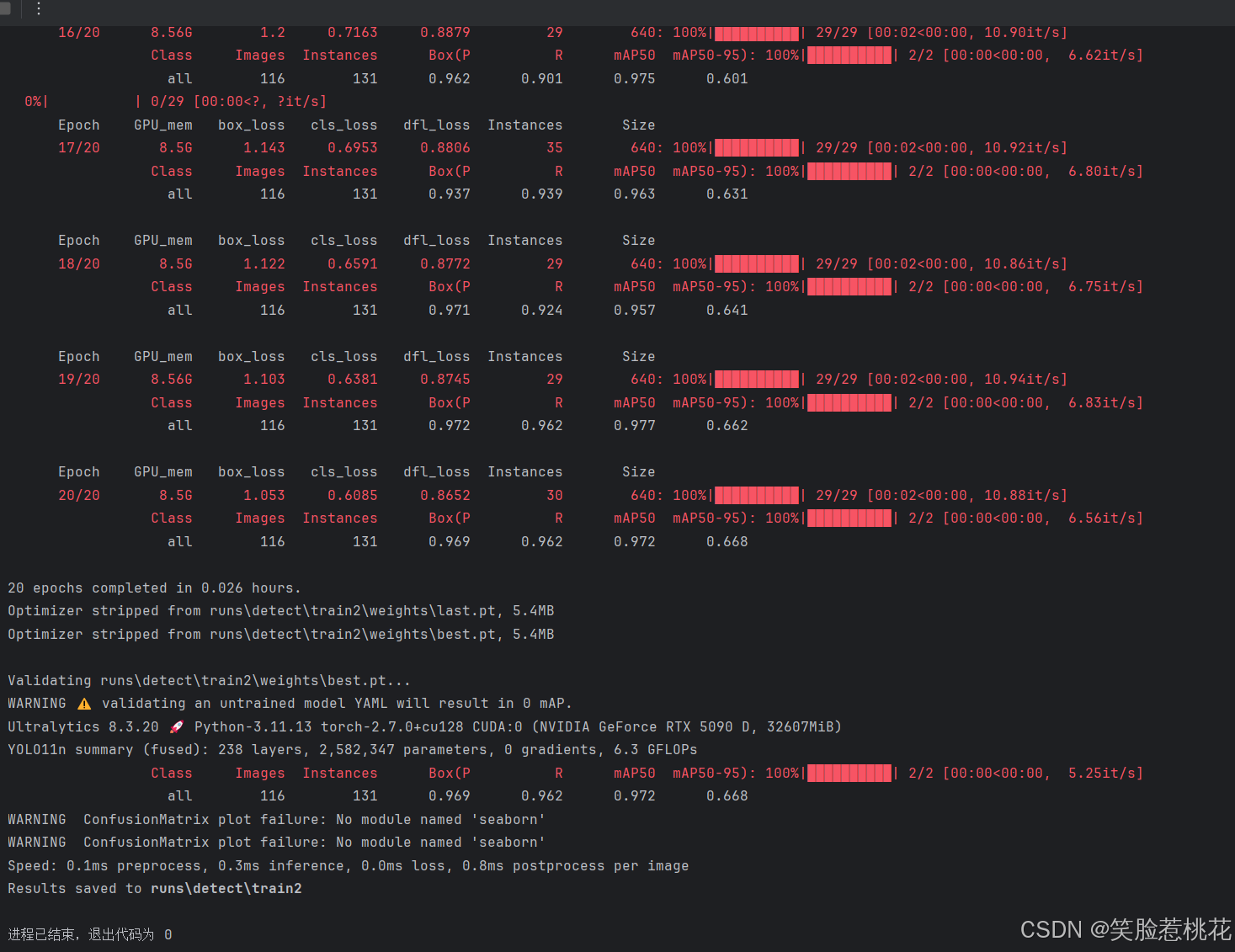
6 训练结果
训练完成后如下图所示
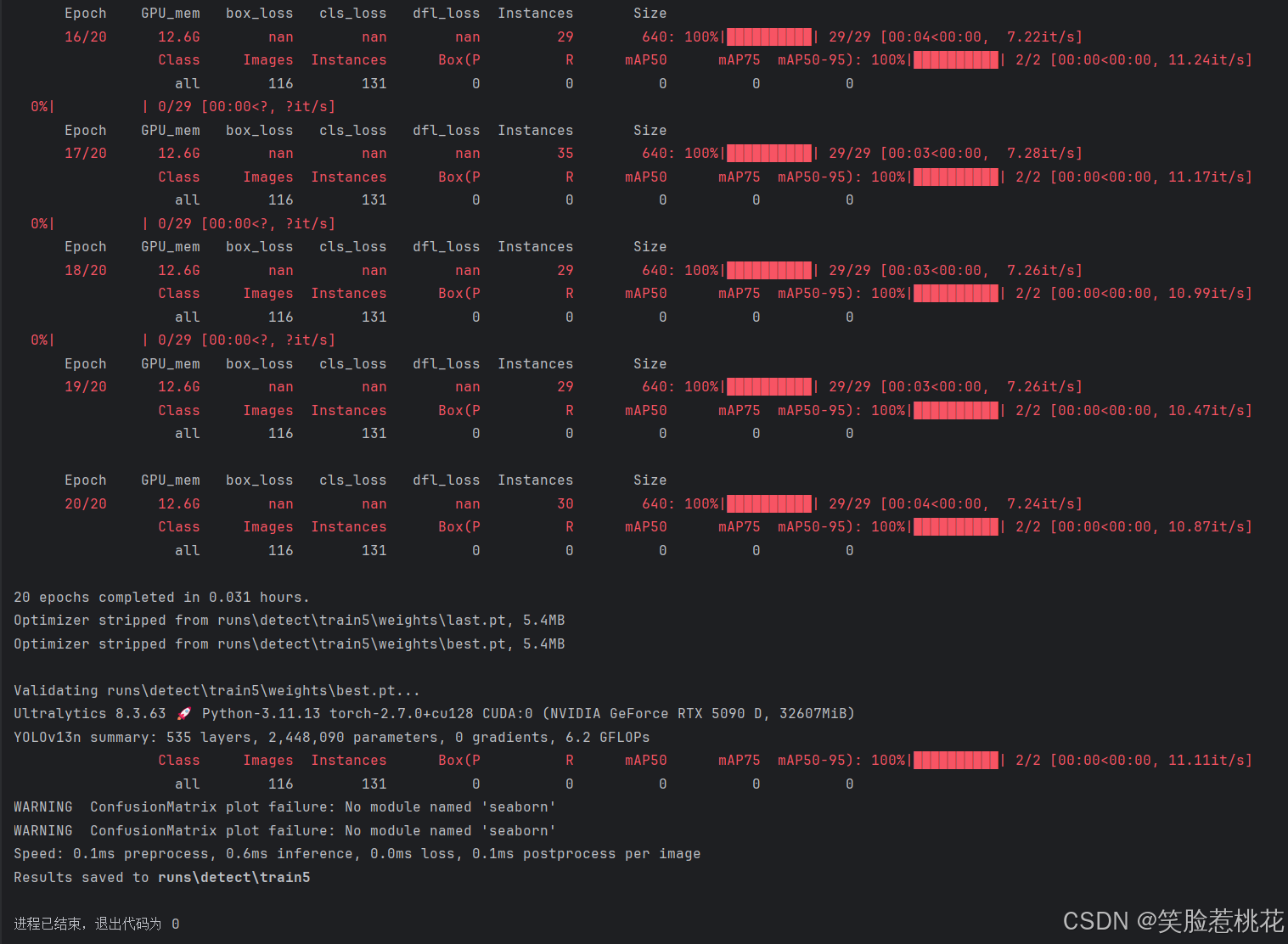
我实测同样的数据集并且都加载n级别的预训练权重,YOLOv13的精度等全是0,而使用YOLOv11训练同样较少的次数就可以得到较高的精度
看了文章之后50系显卡还是无法训练模型可以关注微信公众号-笑脸惹桃花 快速联系我解决
有写论文的大佬可以引用一下我的YOLOv11文章,十分感谢

Zhang Y, Liu J, Li S, et al. ESM-YOLOv11: A lightweight deep learning framework for real-time peanut leaf spot disease detection and precision severity quantification in field conditionsJ. Computers and Electronics in Agriculture, 2025, 238: 110801.