
「【新智元导读】一般人准确率 89.1%,AI 最好只有 13.3%。在新视觉基准 ClockBench 上,读模拟时钟这道「小学题」,把 11 个大模型难住了。为什么 AI 还是读不准表?是测试有问题还是 AI 真不行?」
一图看透全球大模型!新智元十周年钜献,2025 ASI 前沿趋势报告 37 页首发
90% 人都会的读钟题,顶尖 AI 全军覆没!
AI 基准创建者、连续创业者 Alek Safar 推出了视觉基准测试 ClockBench,专注于测试 AI 的「看懂」模拟时钟的能力。
结果让人吃惊:
人类平均准确率 89.1%,而参与测试的 11 个主流大模型最好的成绩仅 13.3%。
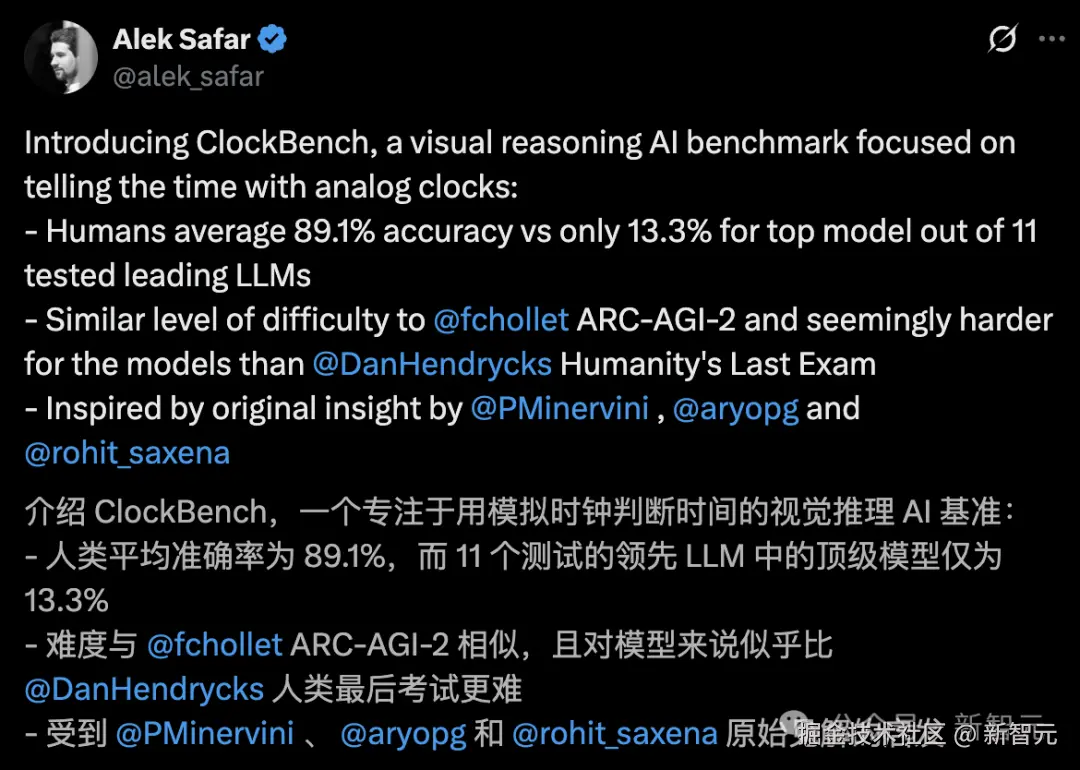
就难度而言,这与「AGI 终极测试」ARC-AGI-2 相当,比「人类终极考试」更难。
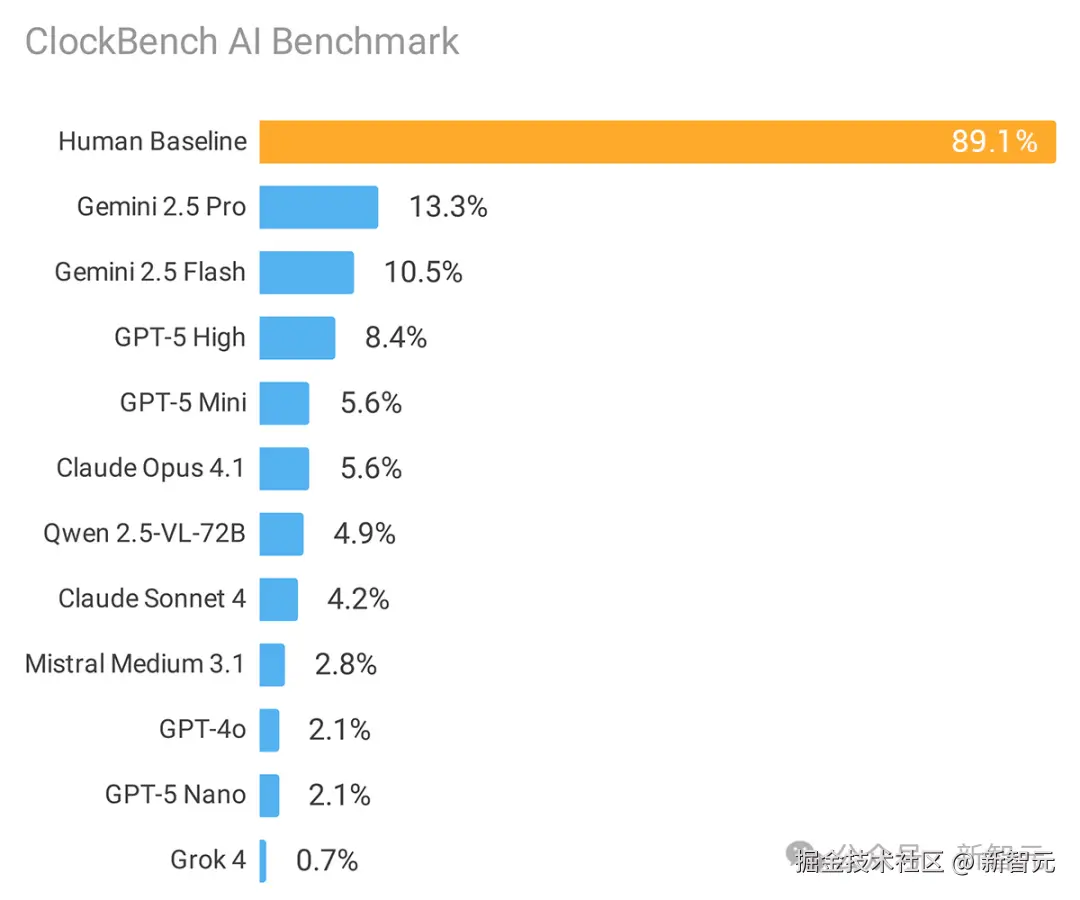
ClockBench 共包含 180 个时钟、720 道问题,展示了当前前沿大语言模型(LLM)的局限性。

论文链接:clockbench.ai/ClockBench....
虽然这些模型在多项基准上展现出惊人的推理、数学与视觉理解能力,但这些能力尚未有效迁移到「读表」。可能原因:
训练数据未覆盖足够可记忆的时钟特征与时间组合,模型不得不通过推理去建立指针、刻度与读数之间的映射。
时钟的视觉结构难以完整映射到文本空间,导致基于文本的推理受限。
也有好消息:表现最好的模型已展现出一定的视觉推理(虽有限)。其读时准确率与中位误差均显著优于随机水平。
接下来需要更多研究,以判定这些能力能否通过扩大现有范式(数据、模型规模、计算 / 推理预算)来获得,还是必须采用全新的方法。

「ClockBench 如何拷打 AI?」
在过去的几年里,大语言模型(LLM)在多个领域都取得了显著进展,前沿模型很快在许多流行基准上达到了「饱和」。
甚至是那些专门设计来同时考察「专业知识与强推理能力」的最新基准,也出现了快速突破。
一个典型例子是 Humanity's Last Exam):
在该基准上,OpenAI GPT-4o 的得分仅 2.7% ,而 xAI Grok 4 却提升到 25.4%;
结合工具使用等优化手段后,结果甚至能进入 40--50% 区间。
然而,我们仍然发现一些对人类而言轻而易举的任务,AI 表现不佳。
因此,出现了 SimpleBench 以及 ARC-AGI 这类基准,它们被专门设计为:对普通人来说很简单,但对 LLM 却很难。
ClockBench 正是受这种「人类容易,****「AI」 **困难」**的思路启发而设计。
研究团队基于一个关键观察:「对推理型和非推理型模型来说,读懂模拟时钟同样很难」。
因此,ClockBench 构建了一个需要高度视觉精度和推理能力的稳健数据集。
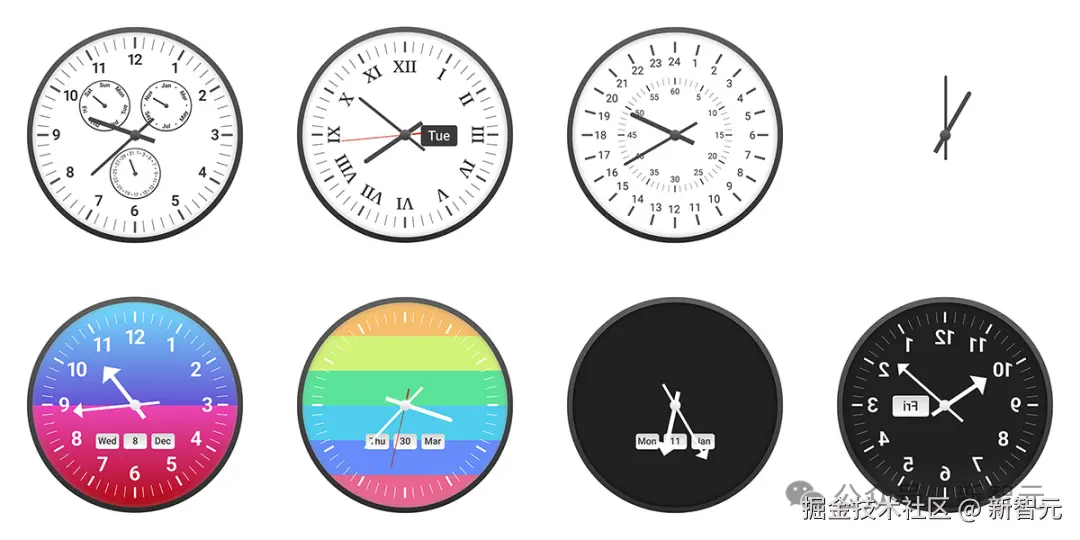
ClockBench 究竟包含什么?
- 36 个全新设计的定制表盘,每个表盘生成 5 个样本时钟
- 总计 180 个时钟,每个时钟设置 4 个问题,共 720 道测试题
- 测试了来自 6 家实验室的 11 个具备视觉理解能力的模型,并招募 5 名人类参与者对比
问题分为 4 大类:
「1. 判断时间是否有效」
有一个时钟🕰️,大模型需要判断这个时钟显示的时间是不是有效的。
如果时间是合法的,大模型需要把它分解成几个部分,并以 「JSON」 格式输出:
小时 (Hours)、分钟 (Minutes)、秒 (Seconds)、日期 (Date)、月份 (Month)、 星期几 (Day of the week)
只要表盘包含上述信息,就要求 LLM 一并输出。
「2. 时间的加减」
该任务要求 LLM 对给定时间进行加减,得到新时间。
「3. 旋转时钟指针」
这个任务是关于**「操作时钟的指针」**。该任务要求模型选择时 / 分 / 秒针,并按指定角度顺时针或逆时针旋转。
「4. 时区转换」
这个任务是关于**「不同地方的时间」🌍。比如,给定「纽约的夏令时,模型需推算不同地点的当地时间。」**
「结果出乎意料」
结果有哪些出乎意料的发现?
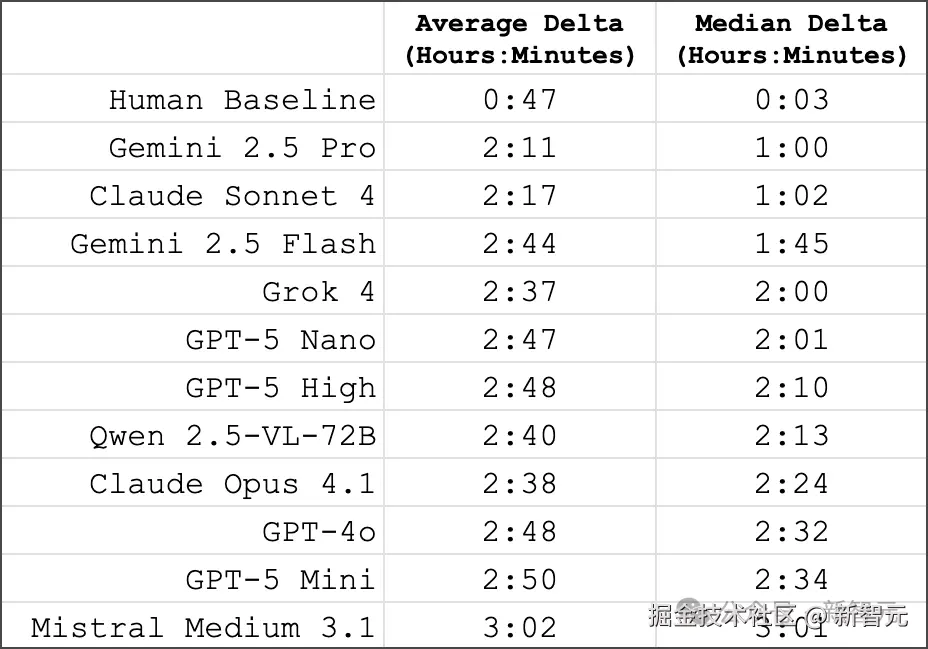
模型与人类不仅正确率差距巨大,错误模式也截然不同:
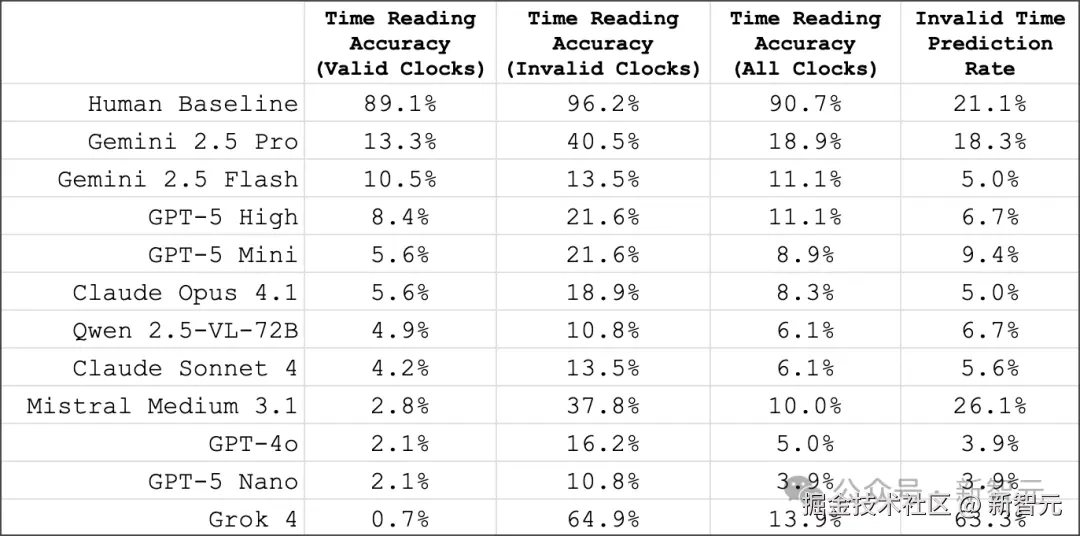
- 人类误差中位数仅 3 分钟,最佳模型却高达 1 小时
- 较弱模型的误差约 3 小时,结合 12 小时制表盘循环特性,相当于随机噪声
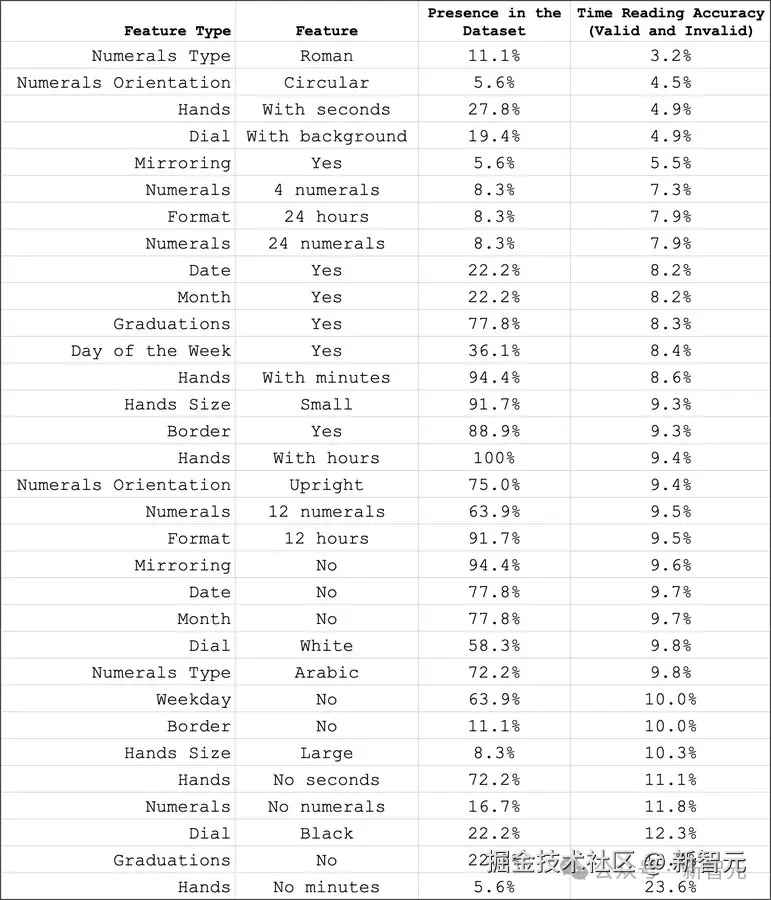
另一个有趣发现是,某些钟表特征的读取难度存在显著差异:
- 在读取非常见的复杂钟表及高精度要求场景时,模型表现最差
- 罗马数字与环形数字的朝向最难识别,其次是秒针、杂乱背景和镜像时钟
除了读时,其他问题对模型而言反而更简单:
- 表现最佳的模型能高精度回答时间加减、指针旋转角度或时区转换问题,部分场景准确率可达 100%
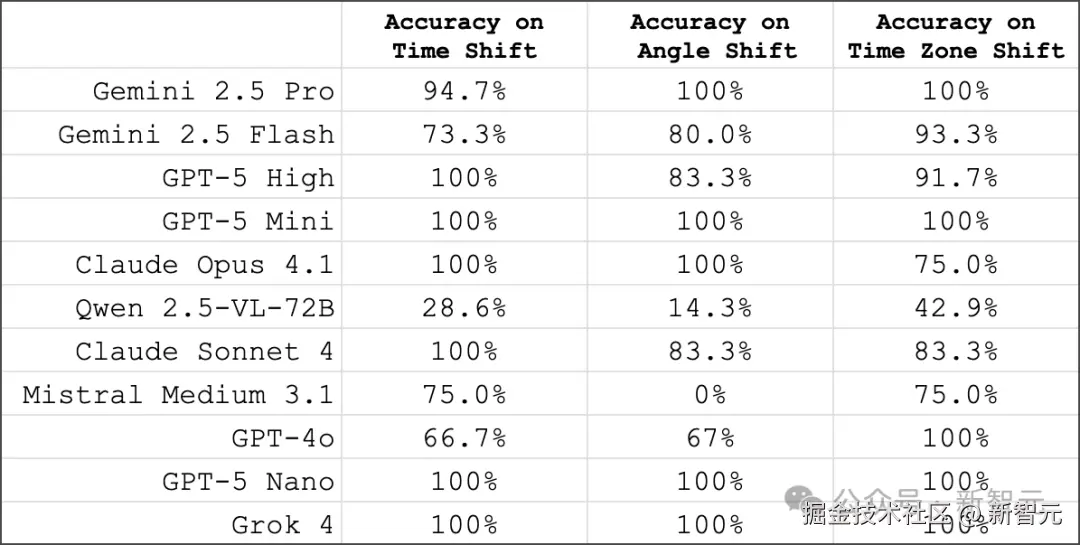
在不同模型的表现对比中,总体趋势是:「规模更大的推理型模型普遍优于规模较小或非推理型模型」。
不过,也出现了一些值得注意的现象:
- **「谷歌的 Gemini 2.5 系列模型」**在各自类别中往往领先于其他模型;
- **「Anthropic 系列模型」**则普遍落后于同类模型;
- 「Grok 4」 的表现远低于预期,与其规模和通用能力并不相称。
GPT-5 排名第三,且推理预算对结果影响不大(中等与高预算得分高度接近)值得思考的是:何种因素制约了 GPT-5 在此类视觉推理任务的表现?
在原始数据集中,「180 个时钟里有 37 个属于无效(不可能存在)的时间」。无论是人类还是模型,在识别「无效时间」时的成功率都更高:
- 「人类差异不大」 :在无效时钟上的准确率为 「96.2%」 ,而在有效时钟上为 「89.1%」;
- 「模型差异明显」 :在无效时钟上的准确率平均高出 「349%」,并且所有模型在这类任务中的表现都更好;
- 「Gemini 2.5 Pro」 依旧是总体最佳模型,准确率达到 「40.5%」;
- 「Grok 4」 则是一个异常值:它在识别无效时钟上的准确率最高,达到 「64.9%」 ,但问题在于,它把整个数据集里 「63.3% 的时钟都标记为无效」,这意味着结果很可能是「随机撞对」。
在模型能够正确读时的钟面上,存在明显的重叠现象:
- 「61.7%」 的时钟没有被任何模型正确读出;
- 「38.3%」 的时钟至少被 1 个模型读对;
- 「22.8%」 的时钟至少被 2 个模型读对;
- 「13.9%」 的时钟至少被 3 个模型读对;
- 「8.9%」 的时钟至少被 4 个或以上的模型读对。
整体来看,分布情况和有效性数据表明:模型的正确答案集中在某一小部分时钟上,而不是均匀分布。
参考资料: