-
Google 发布了 Gemma 3 ,包括一个新的 270M 模型 ,以及之前的 1B、4B、12B 和 27B 模型。
-
其中 270M 和 1B 是仅文本模型,更大的模型支持文本 + 视觉。

- 注:GGUF无法微调,专为高效、本地推理设计
1 官方推荐推理设置
根据 Gemma 团队的官方推荐:
-
Temperature = 1.0
-
Top_K = 64
-
Top_P = 0.95
-
Min_P = 0.0(可选,0.01 效果也好;llama.cpp 默认是 0.1)
-
Repetition Penalty = 1.0(在 llama.cpp/transformers 中,1.0 表示禁用)
2 聊天模板
原始格式(带换行符 \n)
<bos><start_of_turn>user\nHello!<end_of_turn>\n
<start_of_turn>model\nHey there!<end_of_turn>\n
<start_of_turn>user\nWhat is 1+1?<end_of_turn>\n<start_of_turn>model\n渲染换行后的格式
<bos><start_of_turn>user
Hello!<end_of_turn>
<start_of_turn>model
Hey there!<end_of_turn>
<start_of_turn>user
What is 1+1?<end_of_turn>
<start_of_turn>model \n3 在手机上运行 Gemma 3
-
推荐使用能运行 GGUF 的本地应用,例如:
-
AnythingLLM 移动端(Android 可下载)
-
ChatterUI
-
-
建议使用 Gemma 3 270M 或 Gemma 3n(轻量版本),因为手机 RAM 有限且可能过热。
-
流程:微调 → 导出 GGUF → 移动端加载。
4 用unsloth微调gemma3
4.1 Unsloth 微调修复方案
包含三部分:
-
将所有中间激活保持在 bfloat16 格式(也可以是 float32,但这会多用 2 倍显存/内存,Unsloth 通过异步梯度检查点解决)。
-
所有矩阵乘法都在 float16 上用 Tensor Cores 执行,但手动进行上下转型,不依赖 PyTorch 的混合精度自动转换。
-
将其他不需要矩阵乘法的操作(如 LayerNorm )上转为 float32。
4.1.1 Gemma 3 修复分析
- 对 Gemma 3(1B--27B)进行微调或运行之前,发现如果使用 float16 混合精度 ,梯度和激活会变成无穷大 。
- 这在 T4 GPU、RTX 20 系列、V100 上都会出现,因为它们只有 float16 Tensor Cores。
- 而在 RTX 30 系列或更高、A100、H100 等新 GPU 上,就没有这个问题,因为它们支持 bfloat16 Tensor Cores。
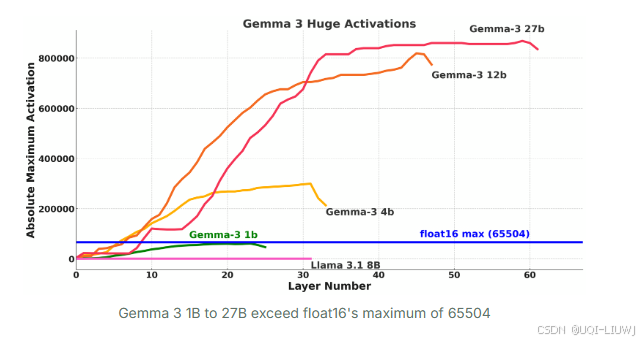
原因分析
-
float16 最大值是 65504 ,而 bfloat16 最大值可表示到 10^38。
-
两者都只有 16 位!
-
float16:更多位数给小数 → 精度高,但范围小。
-
bfloat16:更多位数给指数 → 精度差,但范围大。
-
所以 大模型在 float16 下容易溢出 ,但 bfloat16 可以避免。
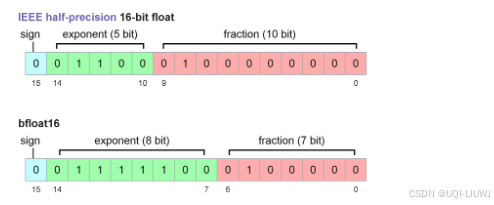
为什么不用 float32?
float32 确实能解决溢出问题,但在 GPU 上做矩阵乘法时会慢 4--10 倍,因此不可行。
5 unsloth 微调Gemma
5.1 导入库
python
from unsloth import FastModel
import torch
'''
🦥 Unsloth: Will patch your computer to enable 2x faster free finetuning.
🦥 Unsloth Zoo will now patch everything to make training faster!
'''5.2 加载模型
python
model, tokenizer = FastModel.from_pretrained(
model_name = "unsloth/gemma-3-4b-it",
max_seq_length = 2048, # 设置 模型能处理的最大序列长度(上下文长度)
load_in_4bit = True, # 打开 4-bit 量化:把模型参数从 16/32-bit 压缩成 4-bit 存储。
load_in_8bit = False, #不启用 8-bit 量化
full_finetuning = False, #是否允许 全参数微调;默认 False:只会加载成 LoRA 或 QLoRA 这种参数高效微调方式
# token = "hf_...", # 某些需要的huggingface的api
)
5.3 给模型套上PEFT
python
model = FastModel.get_peft_model(
model,
finetune_vision_layers = False,
# 如果模型是多模态(text+vision),这里可以决定要不要微调视觉部分
finetune_language_layers = True,
# 是否在语言层(Transformer encoder/decoder block 里的语言部分)插 LoRA。
#一般必须开着,否则 LoRA 只挂在注意力/MLP,微调效果会差。
finetune_attention_modules = True,
#LoRA 是否插到 注意力模块 (Q/K/V projection)。
#打开会增强模型对任务的快速适应(尤其对 RLHF/GRPO、指令跟随类任务有帮助)。
finetune_mlp_modules = True,
#LoRA 是否插到 前馈 MLP 层。
#官方推荐一直开,因为只在 attention 上加 LoRA 效果有限;MLP 对生成质量和泛化也很关键。
'''
LoRA 参数
'''
r = 8,
#LoRA 的秩 (rank),也就是低秩分解的维度。
#越大,模型能学到的表达能力越强,但参数量也会上升,容易过拟合。
lora_alpha = 8,
# 缩放因子,控制 LoRA 矩阵更新的强度。
#一般推荐 lora_alpha ≥ r
#如果设得太小,LoRA 的更新效果会被稀释;太大则可能训练不稳定。
lora_dropout = 0,
#在 LoRA 层里加不加 dropout。
#设成 0 表示完全不用 dropout(适合数据量较大或模型稳定的情况)。
#如果数据特别少,适当加一点(如 0.05~0.1)能防过拟合。
bias = "none",
#LoRA 是否也学习 bias 项。
"none" 表示只改权重矩阵,不动 bias。
#一般保持 "none",能减少不必要的开销。
random_state = 3407,
#随机种子,保证可复现性。
)5.4 给tokenizer套上聊天格式模板
- 不同的开源大模型(LLaMA、Mistral、Gemma...)各自对「聊天 prompt」的格式有不同要求
- 如果直接喂模型「用户问题」,可能效果差甚至出错;加上正确的 template 才能保证训练/推理一致性。
python
from unsloth.chat_templates import get_chat_template
tokenizer = get_chat_template(
tokenizer,
chat_template = "gemma-3",
)
'''
把原始的 tokenizer 包了一层,得到一个支持对话模板的新 tokenizer
chat_template="gemma-3":指定使用 Gemma-3 官方的对话格式
这样设置后,你就可以直接给 tokenizer 一个「列表格式的对话」,而不用手动拼 prompt。
'''目前支持的模板包括:zephyr、chatml、mistral、llama、alpaca、vicuna、vicuna_old、phi3、llama3、phi4、qwen2.5、gemma3 等。
5.5 导入数据
5.5.1 从datasets导入数据
python
from datasets import load_dataset
dataset = load_dataset("mlabonne/FineTome-100k", split = "train")
'''
数据集可能包含多个分片(train/test/validation)。
这里直接指定只要 train 部分
'''
dataset[0]
5.5.2 整理成标准化聊天数据集
好把你前面拿到的 FineTome-100k 原始格式 (带有 conversations 列、text 列、source、score 等杂项)整理成 标准化的聊天数据集。
python
from unsloth.chat_templates import standardize_data_formats
dataset = standardize_data_formats(dataset)
dataset[0]
5.5.3 把标准化的对话转换成 纯文本 prompt+response,以便后续送进模型做微调。
python
def formatting_prompts_func(examples):
convos = examples["conversations"]
#从批量样本中取出对话字段。
texts = [
tokenizer.apply_chat_template(
convo,
tokenize = False, # 直接生成字符串,不做 token 化
add_generation_prompt = False # 不在最后额外加 Assistant 的起始符
).removeprefix('<bos>') # 去掉开头的 <bos>
for convo in convos
]
'''
每条 convo 都是一个 list:
[
{"role": "user", "content": "Explain boolean operators."},
{"role": "assistant", "content": "Boolean operators are ..."}
]
tokenizer.apply_chat_template(...)把这轮对话按照 gemma-3 的 chat 格式拼接成文本
【前面已经get_chat_template(tokenizer, chat_template="gemma-3") 设置好了】
输出会是类似这样的字符串
<bos><start_of_turn>user
Explain boolean operators.<end_of_turn>
<start_of_turn>assistant
Boolean operators are ...
.removeprefix('<bos>')
训练时 只需要一个 <bos> 开头 token。
Hugging Face 的 Trainer / Unsloth Processor 会在真正送进模型前自己加 <bos>。
所以这里提前把拼出来的 <bos> 删掉,避免重复。训练时 只需要一个 <bos> 开头 token。
'''
return { "text" : texts, }
'''
给每条样本生成一个新的 "text" 字段,存放清理好的对话字符串。
格式化后的 dataset 就能直接用于微调。
'''
python
dataset = dataset.map(formatting_prompts_func, batched=True)-
Hugging Face Datasets 的
map会对整个数据集执行上面的函数,生成一个新的"text"列。 -
原始的
"conversations"仍然在,只是又多了"text"。

5.6 创建Trainer
python
from trl import SFTTrainer, SFTConfig
#SFTTrainer = 用于 指令微调 (Instruction Tuning) 的 Trainer。
trainer = SFTTrainer(
model = model,
#前面用LoRA包裹的Gemma-3
tokenizer = tokenizer,
#用gemma-3的chat_temple包装过的tokenizer
train_dataset = dataset,
#处理过的 dataset(带 "text" 字段)。
#训练时,Trainer 会取 example["text"] 来作为训练样本。
eval_dataset = None,
# 没有设置验证集
args = SFTConfig(
dataset_text_field = "text",
#告诉 Trainer 用哪个字段作为输入
per_device_train_batch_size = 2,
#每个 GPU 上一次 forward 的 batch size。
gradient_accumulation_steps = 4,
# 梯度累积,等价于 有效 batch size = 2 × 4 = 8。
warmup_steps = 5,
#前 5 步采用线性升高学习率,从 0 到设定的 learning_rate
output_dir = "training_checkpoints", # 存放检查点的目录(early stopping 需要)
save_strategy = "steps", # 每 N 步保存模型(或者"epoch")
save_steps = 10, # 间隔多少步保存一次
save_total_limit = 3, # 只保留 3 个最新检查点,节省磁盘
# num_train_epochs = 1
# 如果设定,会跑完整个数据集 1 遍。
# 现在没启用,而是用 max_steps 控制。
max_steps = 30,
#最多训练 30 步,然后停下来
learning_rate = 2e-4,
# 学习率
logging_steps = 1,
# 每 1 步输出一次 loss。
optim = "adamw_8bit",
# 使用 8-bit AdamW 优化器(来自 bitsandbytes),显存更省。
# 如果你的环境不支持 8bit,可以改 "adamw_torch"。
weight_decay = 0.01,
#L2 正则项,防止过拟合。
lr_scheduler_type = "linear",
#学习率调度器,用线性下降
seed = 3407,
# 随机种子
report_to = "none"
#不上传日志。
#如果想用 WandB 或 TensorBoard,可以改 "wandb" 或 "tensorboard"。
),
)5.6.1 Trainer的dataset
相比于送入trainer之前多'input_ids', 'attention_mask', 'labels'
python
tokenizer.decode(trainer.train_dataset[0]['input_ids'])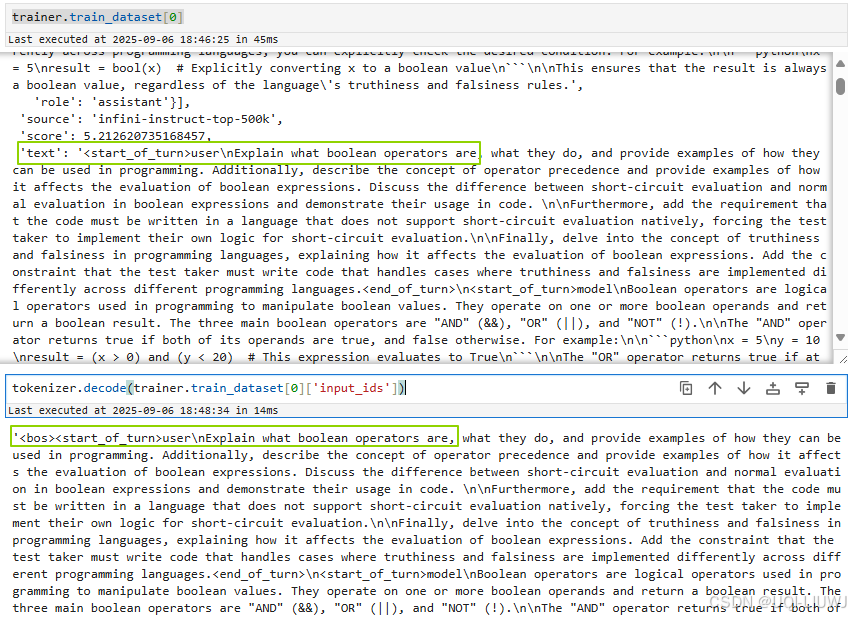 进入trainer之后的text相当于多了一个<bos>
进入trainer之后的text相当于多了一个<bos>
5.6.2 给 Trainer 套上一个"只训练在助手回复部分"的过滤逻辑
在指令微调 (SFT) 时,训练数据通常是 用户指令 + 助手回答 拼在一起:
python
<start_of_turn>user
Explain what boolean operators are ...<end_of_turn>
<start_of_turn>model
Boolean operators are ...如果直接算 loss,模型会被迫"学习"用户输入的 token
这其实没意义,反而会浪费算力,还可能让模型生成"用户风格的输入"而不是回答。
所以unsloth可以多这一步
python
from unsloth.chat_templates import train_on_responses_only
trainer = train_on_responses_only(
trainer,
instruction_part = "<start_of_turn>user\n",
response_part = "<start_of_turn>model\n",
)
'''
会对数据里的每个训练样本做 label masking:
用户部分 → label 设为 -100(在 CE loss 里被忽略)
助手部分 → 保留 label,参与 loss 计算
instruction_part:用来标记用户输入开始的分隔符(这里是 <start_of_turn>user\n)
response_part:用来标记助手输出开始的分隔符(这里是 <start_of_turn>model\n)
(FineTome-100k 用 model 代替 assistant 角色)
这样 Trainer 就能精确识别"从哪里开始计算 loss"
'''
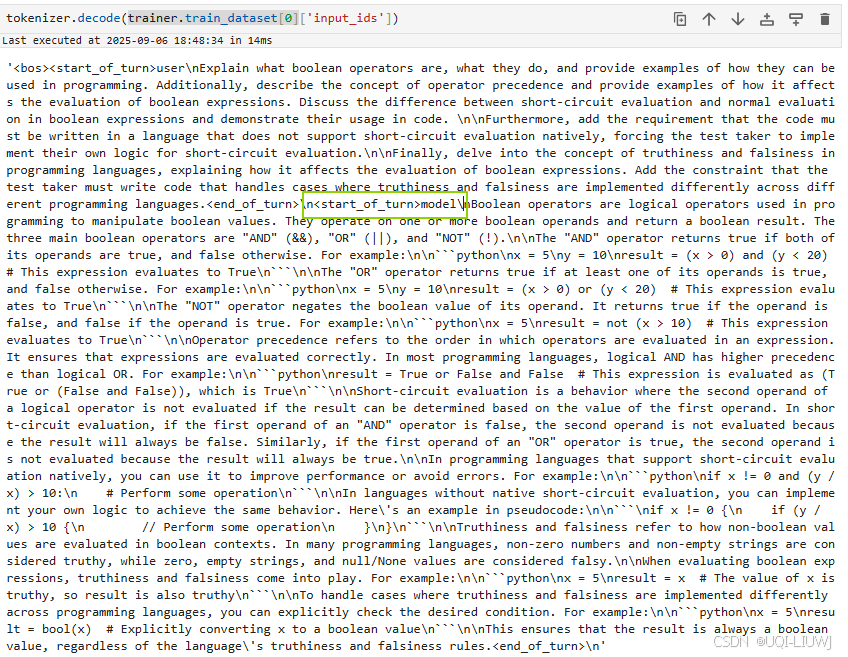
labeldecode的结果:可以看到前面一堆pad
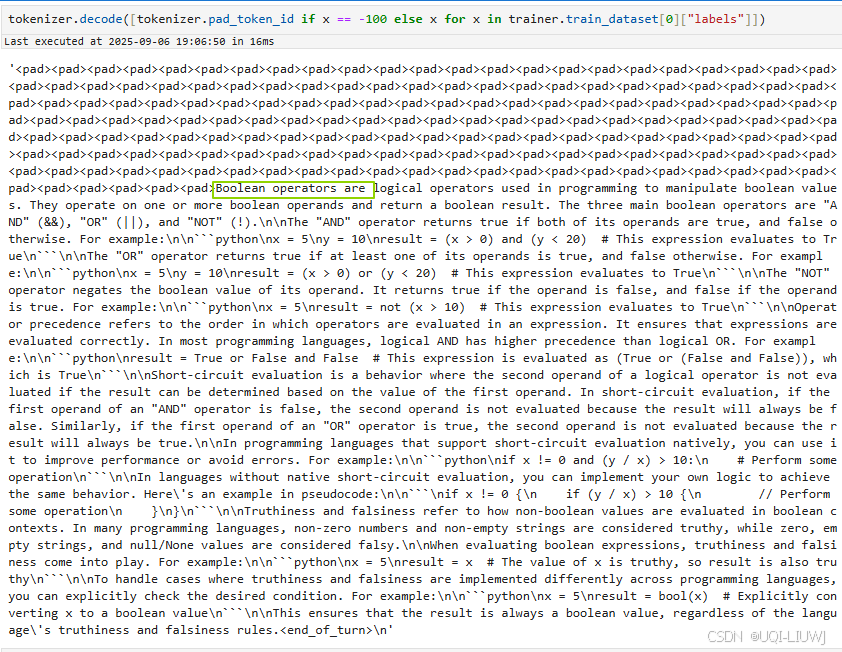
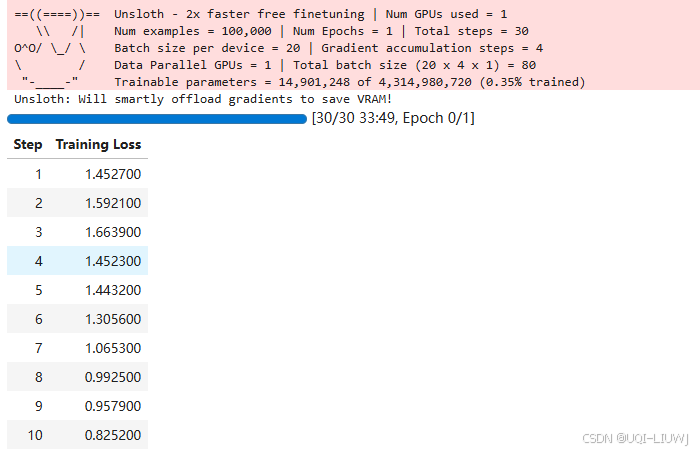
5.7 真正开始训练
python
trainer_stats = trainer.train()trainer.train()
-
Hugging Face
Trainer/trl.SFTTrainer的标准方法。 -
会遍历你传进去的
train_dataset,执行前向传播 + 反向传播 + 参数更新。 -
根据你之前配置的
max_steps=30,这里只会训练 30 个 step,就会停下来。 -
如果换成
num_train_epochs=1,则会把整个数据集完整训练一遍。
resume_from_checkpoint=True
-
如果你上次训练被中断,可以从保存的 checkpoint 目录继续训练。
-
默认会在
output_dir(比如./outputs/)下找最近的 checkpoint。
返回值 trainer_stats
-
一个包含训练过程信息的字典,里面有:
-
train_loss:最终训练损失 -
metrics:训练时的统计信息 -
train_runtime:总运行时间 -
train_samples_per_second:吞吐量
-
5.8 查看训练过程的显存和耗时
python
gpu_stats = torch.cuda.get_device_properties(1)
#gpu_stats = torch.cuda.get_device_properties(1)
start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
#返回 当前已被 PyTorch allocator 保留的显存最大值(字节数)
#也即训练前的内存占用
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)
#显卡的总显存
print(f"GPU = {gpu_stats.name}. Max memory = {max_memory} GB.")
#GPU = NVIDIA RTX A5000. Max memory = 23.673 GB.
print(f"{start_gpu_memory} GB of memory reserved.")
#4.359 GB of memory reserved.
# @title Show final memory and time stats
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
#整个训练过程 GPU 上最大显存占用量。
used_memory_for_lora = round(used_memory - start_gpu_memory, 3)
#训练本身额外消耗的显存
used_percentage = round(used_memory / max_memory * 100, 3)
#训练期间显存最高占用 / 总显存,转百分比
lora_percentage = round(used_memory_for_lora / max_memory * 100, 3)
#LoRA 训练本身新增的显存 / 总显存,转百分比。
print(f"{trainer_stats.metrics['train_runtime']} seconds used for training.")
#2140.7552 seconds used for training.
print(
f"{round(trainer_stats.metrics['train_runtime']/60, 2)} minutes used for training."
)
#35.68 minutes used for training.
print(f"Peak reserved memory = {used_memory} GB.")
#Peak reserved memory = 19.129 GB.
print(f"Peak reserved memory for training = {used_memory_for_lora} GB.")
#Peak reserved memory for training = 14.77 GB.
print(f"Peak reserved memory % of max memory = {used_percentage} %.")
#Peak reserved memory % of max memory = 80.805 %.
print(f"Peak reserved memory for training % of max memory = {lora_percentage} %.")
#Peak reserved memory for training % of max memory = 62.392 %.5.9 推理
python
from unsloth.chat_templates import get_chat_template
tokenizer = get_chat_template(
tokenizer,
chat_template = "gemma-3",
)
#和前面一样,给tokenizer套上gemma的模板
#这样你可以用类似 {"role": "user", "content": ...} 的结构输入,而不用自己手动拼 prompt。
messages = [{
"role": "user",
"content": "Continue the sequence: 1, 1, 2, 3, 5, 8,",
}]
#需要推理生成的message
python
text = tokenizer.apply_chat_template(
messages,
add_generation_prompt = True, # 推理时必须加,告诉模型"现在轮到助手说话了"
)
text
#'<bos><start_of_turn>user\nContinue the sequence: 1, 1, 2, 3, 5, 8,<end_of_turn>\n<start_of_turn>model\n'
tokenizer.apply_chat_template(
messages
)
#'<bos><start_of_turn>user\nContinue the sequence: 1, 1, 2, 3, 5, 8,<end_of_turn>\n'
#不加就是这个样子
python
outputs = model.generate(
**tokenizer(text, return_tensors = "pt").to("cuda"),
max_new_tokens = 64, # Increase for longer outputs!
# Recommended Gemma-3 settings!
temperature = 1.0, top_p = 0.95, top_k = 64,
)
# 解码输出
print(tokenizer.batch_decode(outputs)[0])
'''
<bos><start_of_turn>user
Continue the sequence: 1, 1, 2, 3, 5, 8,<end_of_turn>
<start_of_turn>model
2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2
'''5.9.1 流式推理
这样就不用等到所有token都生成完才有输出了,直接一个一个token蹦出来
python
from transformers import TextStreamer
outputs = model.generate(
**tokenizer([text], return_tensors = "pt").to("cuda"),
max_new_tokens = 64, # Increase for longer outputs!
# Recommended Gemma-3 settings!
temperature = 1.0, top_p = 0.95, top_k = 64,
streamer = TextStreamer(tokenizer, skip_prompt = True), #多了这一行
)
print(tokenizer.batch_decode(outputs)[0])
'''
13, 21, 34...
This is the Fibonacci sequence, where each number is the sum of the two numbers before it.
<end_of_turn>
'''5.10 保存lora权重
python
model.save_pretrained("gemma-3") # 本地保存 LoRA adapters
tokenizer.save_pretrained("gemma-3") # 保存 tokenizer 相关文件-
注意 :这里保存的并不是完整的
gemma-3-4b模型,而是你训练得到的 LoRA adapter 权重。 -
本地目录
"gemma-3"会包含:-
adapter_model.bin(LoRA 权重) -
adapter_config.json(LoRA 配置) -
tokenizer.json等文件
-
5.11 加载Lora权重
python
from unsloth import FastModel
model, tokenizer = FastModel.from_pretrained(
model_name = "lora_model", # 你保存的目录名,例如 "gemma-3"
max_seq_length = 2048,
load_in_4bit = True,
)
'''
model_name = "lora_model" 要改成你保存的目录,比如 "gemma-3"。
这样加载后,Unsloth 会自动:
下载基础模型 unsloth/gemma-3-4b-it
再把你保存的 LoRA 权重 合并进来 → 恢复到训练后的模型。
'''- 在
Unsloth.FastModel.from_pretrained里,传的model_name如果是你本地保存的 LoRA 目录 (例如"gemma-3"),Unsloth 会做两件事:- 读取本地目录
- 自动识别 & 下载基础模型
-
FastModel.from_pretrained("gemma-3")会先加载目录里的 adapter 配置。 -
看到
base_model_name_or_path后,就会自动去 Hugging Face Hub 拉取对应的 基础模型 (比如unsloth/gemma-3-4b-it)。 -
加载完基础模型后,再把
adapter_model.bin合并进去 → 得到你微调后的完整模型
-
- 读取本地目录

