在人工智能的浪潮中,神经网络 (Neural Networks)无疑是驱动核心技术的引擎,它赋予了计算机前所未有的学习和识别能力。而这一切的起点,是受到生物大脑中基本单元------神经元(Neurons)的深刻启发。从一个微小的生物细胞到复杂的计算模型,神经元与神经网络共同构成了人工智能的强大基石。
生物神经元:计算的原始模型
要理解人工神经网络,我们必须首先回顾其生物学原型。人脑是一个由数十亿个神经元组成的复杂网络,这些神经元通过电化学信号相互交流。
一个典型的生物神经元主要由三部分构成:
- 树突(Dendrites):像一棵树的枝桠,负责接收来自其他神经元的输入信号。
- 细胞体(Soma) :神经元的核心部分,它整合所有树突接收到的输入信号。当这些信号的总和达到一个特定的阈值时,细胞体就会被"激活"。
- 轴突(Axon):一个长长的突起,当细胞体被激活后,它会沿着轴突向其他神经元传递一个输出信号。
信号在神经元之间传递的连接点被称为突触(Synapses)。突触的连接强度不是固定的,而是可塑的,会随着学习和经验而改变。这种并行处理和动态可塑性的特性,正是人脑能够进行复杂认知、学习和记忆的根本原因。
人工神经元(感知机)
人工神经元 ,通常也称为感知机(Perceptron),是对生物神经元功能的数学抽象和模拟。一个感知机的工作原理很简单:
-
输入(Inputs):接收来自外部或上一层神经元的多个输入信号,x1,x2,...,xn。
-
权重(Weights):每个输入都带有一个权重,w1,w2,...,wn。这些权重就像生物突触的连接强度,决定了每个输入的重要性。
-
加权求和(Weighted Sum):将每个输入与其对应的权重相乘,然后将所有结果相加。这个过程可以表示为:
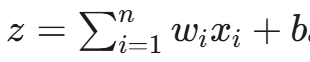
其中,b 是一个**偏置(bias)**项,可以理解为神经元更容易被激活的倾向。
-
激活函数(Activation Function) :将加权求和的结果 z 输入到一个非线性的函数中,得到最终的输出。这个函数模仿了生物神经元的"激活"过程。早期的感知机使用简单的阶跃函数,而现代的神经网络则常使用 ReLU (Rectified Linear Unit)或 Sigmoid 等函数,它们能让网络学习更复杂的模式。
感知机能够解决简单的线性分类问题,但其局限性在于无法处理非线性可分问题,例如著名的"异或"(XOR)问题。
从单个神经元到多层网络:神经网络的诞生
为了解决感知机的局限性,研究者开始将多个神经元组织成多层感知机(Multilayer Perceptron,MLP) ,这标志着现代神经网络的诞生。一个典型的神经网络通常由以下几层组成:
- 输入层(Input Layer):负责接收原始数据,例如一张图片的像素值。
- 隐藏层(Hidden Layers):位于输入层和输出层之间,是网络的"大脑"。它可以有一个或多个隐藏层,每一层都负责从上一层提取更高级、更抽象的特征。
- 输出层(Output Layer):给出网络的最终结果,例如预测的类别或数值。
当一个神经网络拥有多个隐藏层时,我们称之为深度神经网络(Deep Neural Network) 。深度学习(Deep Learning)正是指利用这类深度网络进行学习和训练的方法。
神经网络的学习过程:反向传播算法
神经网络的"学习"过程,即通过数据自动调整权重以达到最优性能的过程,是一个核心难题。这个问题的解决,离不开**反向传播(Backpropagation)**算法的发明。
训练一个神经网络通常包括以下几个步骤:
- 前向传播(Forward Propagation):输入数据从输入层开始,逐层向前传递,直到输出层产生一个预测结果。
- 损失函数(Loss Function):用一个数学函数来衡量网络的预测结果与真实标签之间的差距。这个差距越大,损失值就越高。常见的损失函数包括均方误差(Mean Squared Error)和交叉熵(Cross-Entropy)等。
- 反向传播(Backpropagation) :这是学习的核心。它利用梯度下降(Gradient Descent)的原理,从输出层开始,将损失值逐层反向传播到网络中的每一个神经元。在传播过程中,算法会计算出每个权重对总损失的贡献,即梯度。
- 权重更新(Weight Update):根据反向传播计算出的梯度,使用优化器(如 Adam、SGD 等)来微调网络的权重。调整方向是朝着损失值减小的方向。
这个"前向传播-计算损失-反向传播-更新权重"的循环会重复成千上万次,直到网络在训练数据上的表现达到预设的满意水平。
神经网络的类型与应用
随着研究的深入,出现了多种适应不同任务的神经网络架构,每一种都建立在基本的神经元和层结构之上:
- 卷积神经网络(Convolutional Neural Network, CNN) :特别适用于处理图像、视频等网格状数据。它通过卷积层 和池化层来自动提取图像中的局部特征,并在计算机视觉领域取得了巨大成功。
- 循环神经网络(Recurrent Neural Network, RNN):擅长处理序列数据,如文本、语音和时间序列。它的特点是神经元之间存在循环连接,使得网络能够记住之前的信息。
- 长短期记忆网络(Long Short-Term Memory, LSTM):一种特殊的 RNN,通过"门"机制有效解决了传统 RNN 的长期依赖问题,在自然语言处理中表现出色。
- 生成对抗网络(Generative Adversarial Network, GAN):由两个网络(一个生成器和一个判别器)相互博弈,可以生成逼真的人脸、图像等数据。
挑战与展望
尽管神经网络取得了非凡成就,但挑战依然存在:
- 黑箱问题:深度神经网络的决策过程通常难以解释,我们很难理解模型为何做出某个预测。这在医疗诊断等高风险领域是一个严重问题。
- 数据依赖:神经网络,尤其是深度学习模型,需要海量的高质量标注数据进行训练,这在很多领域是昂贵且耗时的。
- 能耗问题:大型神经网络模型的训练和运行需要巨大的计算资源和电力。