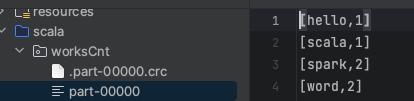
文件名为 words.txt
spark scala
hello spark
word word
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{DataFrame, SQLContext, SparkSession}
object SparkSqlHelloWorld {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[1]").setAppName("sql")
val session: SparkSession = SparkSession.builder().config(conf).getOrCreate()
val sc: SparkContext = session.sparkContext
val sqlContext: SQLContext = session.sqlContext
val rdd: RDD[String] = sc.textFile("/Users/yolo/IdeaProjects/SparkStudy/src/main/scala/works.txt")
import session.implicits._
val df: DataFrame = rdd.flatMap(_.split(" ")).toDF("wd")
df.createTempView("words")
val sql = sqlContext.sql("select wd,count(1) from words group by wd")
sql.show()
sql.rdd.repartition(1).saveAsTextFile("/Users/yolo/IdeaProjects/SparkStudy/src/main/scala/worksCnt")
session.close()
}
}