1. Spark框架及特点
Apache Spark 是一个专为大规模数据处理而设计的快速、通用的计算引擎 。最初由加州大学伯克利分校的 AMP 实验室(Algorithms, Machines, and People Lab)开发,并于 2010 年开源,2014 年成为 Apache 顶级项目。Spark 的诞生旨在突破传统 Hadoop MapReduce 在迭代计算和内存利用上的局限性,与 MapReduce 不同,Spark 可以将作业中间结果缓存于内存中,减少对磁盘的读写操作,因此在需要多次迭代计算的数据处理场景(如数据挖掘和机器学习)中表现出色。
Spark官网地址:https://spark.apache.org/。
Spark计算框架具备以下特点:
- 处理数据速度快
与 MapReduce 每个任务都需要将中间结果写入磁盘不同,Spark 能够将作业中间数据缓存于内存中,得益于内存计算和优化的查询执行方式,Spark 在内存中的运算速度比 Hadoop 的 MapReduce 快 100 倍,在磁盘上的速度也快 10 倍。
- 简单易用
Spark在处理数据过程中提供了几十个丰富的高级API(算子操作),这些高级API大大降低了编程的复杂度。
- 多语言支持
Spark 底层使用 Scala 编写,开发者可以使用 Scala、Java、Python、SQL 和 R 等语言进行编程,满足不同开发者的需求。
- 丰富的生态系统
Spark 拥有多个功能强大的模块,通过这些模块可以处理结构/非结构数据、API/SQL处理批量/流式数据、机器学习、图计算,使 Spark 能够处理多种复杂数据处理任务。
- 支持多模式运行部署
Spark 可以在单机、小型集群甚至上千节点的分布式环境中高效运行。它能够与多种集群管理器(如 Standalone、YARN、Mesos、Kubernetes)和分布式存储系统(如 HDFS、Amazon S3 等)无缝集成,适应不同规模的数据处理需求。
2. Spark生态模块
Spark 生态模块包括:SparkCore、SparkSQL、SparkStreaming、StructuredStreaming、MLlib 和 GraphX。与 Hadoop 相关的整个技术生态如下图所示:
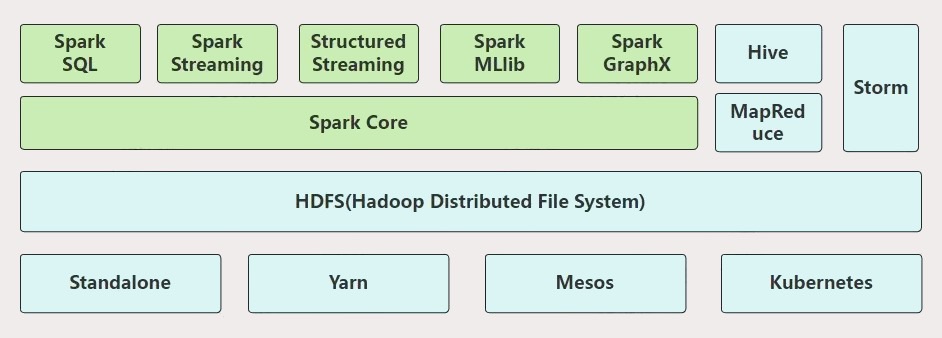
下面分别介绍Spark各个模块功能。
- SparkCore
Spark Core 是 Spark 的核心模块,提供了基本的功能和 API,包括任务调度、内存管理、故障恢复等,它实现了弹性分布式数据集(RDD)的概念,支持对分布式数据集的并行操作,Spark其他模块都是基于 Spark Core 构建。
- SparkSQL
Spark SQL 模块用于处理结构化数据,支持使用标准SQL 进行数据分析、查询,SparkSQL中还提供了 DataFrame 和 Dataset API,方便开发者以声明式方式操作数据。此外,Spark SQL 还支持与 Hive 的集成,可以直接查询 Hive 仓库中的数据。
- SparkSteaming
SparkStreaming 是基于 SparkCore 模块实现的,用于实时处理流数据的模块。它将实时数据流分成小批次,然后通过类似于 Spark Core 的 API 进行准实时数据处理。
- StructuredStreaming
StructuredStreaming 是基于 SparkSQL 模块构建的可扩展且容错的流处理模块。它提供了一种统一的编程模型,使开发者能够以 SQL 方式编写流式计算操作,可以轻松地对流数据进行转换、聚合和分析。
- MLlib
MLlib 模块是 Spark 的机器学习库,提供了常用的机器学习算法和工具,如分类、回归、聚类、协同过滤等。它利用 Spark 的分布式计算能力,能够处理大规模数据集上的机器学习任务。
- GraphX
GraphX 模块用于图计算,提供了用于表示图和执行图操作的 API。它支持常见的图算法,如 PageRank、连接组件等,方便开发者进行复杂的图数据分析。
3. spark运行架构
下图展示了Spark Standalone基本运行架构(Master-Slave架构),图中包含Master、Worker、Driver及数据流动关系,下面对Spark任务运行过程涉及的名词及作用进行介绍。
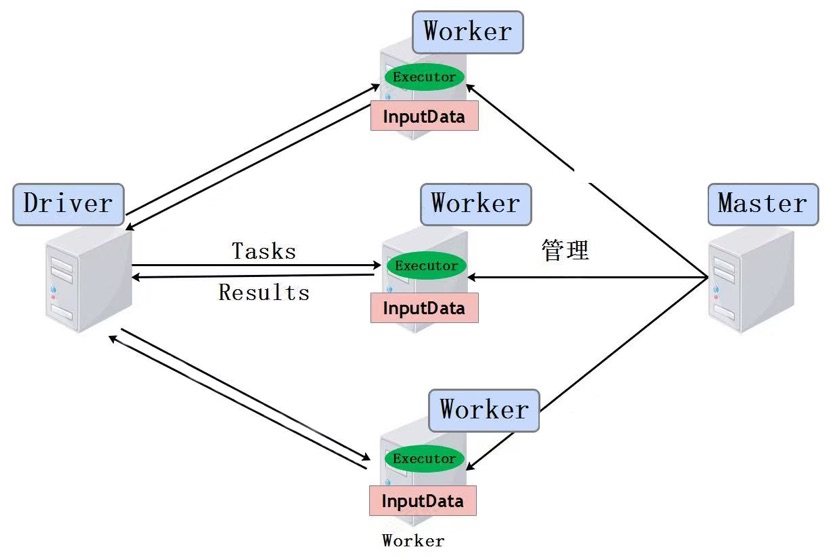
- Master:Spark集群中资源管理主节点,负责管理Worker节点。
- Worker:Spark集群中资源管理的从节点,负责任务的运行。
- Application:Spark用户运行程序,包含Driver端和在各个Worker运行的Executor端。
- Driver:用来连接Worker的程序,Driver可以将Task发送到Worker节点处理这些数据。每个Spark Application都有独立的Driver,Driver负责任务(Tasks)的分发和结果回收。如果task的计算结果非常大就不要回收了,可能会造成oom。
- Executor :Worker节点上运行的进程,负责执行Task,将数据存储在内存或者磁盘中,并将结果返回给Driver。每个Application都有各自独立的一批Executors。
- Task:被发送到某个Executor上的工作单元。
4. Spark&MapReduce区别
Apache Spark 和 Hadoop MapReduce 都是用于大规模数据处理的分布式计算框架,但它们在架构设计、数据处理方式和应用场景等方面存在显著差异。以下是两者的主要区别:
1) 数据处理方式
MapReduce:采用基于磁盘的处理方式,每个任务的中间结果需要写入磁盘,然后再读取进行下一步处理。这种方式增加了磁盘 I/O 操作,导致处理速度较慢。
Spark:利用内存进行数据处理,将中间结果存储在内存中,减少了磁盘读写操作,从而显著提高了处理速度。特别是在需要多次迭代计算的场景下,Spark 的性能优势更加明显。
2) 编程模型
MapReduce:提供了相对低级的编程接口,主要包含 Map 和 Reduce 两个操作,开发者需要编写较多的代码来实现复杂的数据处理逻辑。
Spark:提供了更高级的编程接口,如 RDD(弹性分布式数据集)和 DataFrame,支持丰富的操作算子,使得开发者可以以更简洁的方式编写复杂的处理逻辑。此外,Spark支持SQL处理批/流数据。
3) 任务调度
MapReduce:采用多进程模型,每个Task任务作为一个独立的JVM进程运行。
Spark:采用多线程模型,在同一个进程中管理多个Task任务,资源调度更为高效。
4) 资源申请
MapReduce:采用细粒度资源调度,每个 MapReduce Job 运行前申请资源,Job运行完释放资源。如果一个Application中有多个 MapReduce Job,每个Job独立申请和释放资源。
Spark:采用粗粒度资源调度。Application运行前,为所有的Spark Job申请资源,所有Job执行完成后,统一释放资源。
5) 数据处理能力
MapReduce:主要用于批处理任务,不适合实时数据处理。
Spark:适用于批量/实时数据处理。通过 SparkStreaming 和 StructuredStreaming 模块,支持实时数据流处理。
6) 容错机制
MapReduce:通过将中间结果写入磁盘,实现任务失败后的重试和恢复。
Spark:采用 RDD 的血统(lineage)机制,记录数据集的生成过程。当节点发生故障时,Spark 可以根据血统信息重新计算丢失的数据分区,实现高效的容错。
5. RDD介绍
在 Apache Spark 编程中,RDD(Resilient Distributed Dataset,弹性分布式数据集)是 Spark Core 中最基本的数据抽象,代表一个不可变、可分区、可并行计算的元素集合。RDD 允许用户在集群上以容错的方式执行计算。
5.1 五大特性
1) RDD由一系列Partition组成(A list of partitions)
RDD由多个Partition组成,这些Partition分布在集群的不同节点上。如果读取的是HDFS中的数据,每个partition对应一个Split,每个Split大小默认与每个Block大小一样,。
2) 函数是作用在每个Partition(Split)上的(A function for computing each split)
RDD 定义了在每个分区上进行计算的函数,例如 flatMap、map 等操作,这些函数对每个分区中的数据进行处理。
3) RDD之间有依赖关系(A list of dependencies on other RDDs)
RDD之间存在依赖关系,上图中RDD2可以基于RDD1生成,RDD1叫做父RDD,RDD2叫做子RDD。
4) 分区器作用在K,V格式的RDD上(Optionally, a Partitioner for key-value RDDs)
Spark分区器作用是决定数据发往下游RDD哪个Partition中,分区器只能作用在这种K,V格式的RDD中,默认根据Key的hash值与下游RDD的Partition个数取模决定该条数据去往下游RDD的哪个Paritition中。
5) RDD提供一系列最佳的计算位置(Optionally, a list of preferred locations to compute each split on)
RDD 提供每个分区的最佳计算位置,通常是数据所在的节点,这样可以将计算task调度到数据所在的位置,减少数据传输,提高计算效率(计算移动,数据不移动原则)。
关于RDD的注意点如下:
- textFile底层读取文件方式与MR读取文件方式类似,首先对数据split,默认Split是一个block大小。
- 读取数据文件时,RDD的Paritition个数默认与Split个数相同,也可以在创建RDD的时候指定,Partition是分布在不同节点上的。
- RDD虽然叫做数据集,但实际上不存储数据,RDD类似迭代器,对象不可变,处理数据时,下游RDD会依次向上游RDD获取对应数据,这就是RDD之间为什么有依赖关系的原因。
- 如果RDD中数据类型为二元组对象,那么这种RDD我们称作K,V格式的RDD。
- RDD的弹性体现在RDD中Partition个数可以由用户设置、RDD可以根据依赖关系基于上一个RDD按照迭代器方式计算出下游RDD。
- RDD提供最佳计算位置,task发送到相应的partition节点上处理数据,体现了"计算移动,数据不移动"的理念。
5.2 RDD创建方式
在Spark中创建RDD可以通过读取集合、读取文件方式创建,还可以基于已有RDD转换创建,主要使用第三种方式
5.2.1 java api
java
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("generateRDD");
JavaSparkContext sc = new JavaSparkContext(conf);
//1.从集合中创建RDD,并指定并行度为3,默认并行度为1
JavaRDD<String> rdd1 = sc.parallelize(Arrays.asList("a", "b", "c", "d"),3);
System.out.println("rdd1并行度为:"+rdd1.getNumPartitions());
rdd1.foreach(new VoidFunction<String>() {
@Override
public void call(String s) throws Exception {
System.out.println(s);
}
});
//2.从集合创建K,V格式RDD
JavaPairRDD<String, Integer> rdd2 = sc.parallelizePairs(Arrays.asList(
new Tuple2<String, Integer>("a", 1),
new Tuple2<String, Integer>("b", 2),
new Tuple2<String, Integer>("c", 3),
new Tuple2<String, Integer>("d", 4)
));
rdd2.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> tp) throws Exception {
System.out.println(tp._1 + " " + tp._2);
}
});
//3.从文件中创建RDD,并指定并行度为3,默认并行度为1
JavaRDD<String> rdd3 = sc.textFile("./data/data.txt",3);
System.out.println("rdd3并行度为:"+rdd3.getNumPartitions());
rdd3.foreach(new VoidFunction<String>() {
@Override
public void call(String s) throws Exception {
System.out.println(s);
}
});5.2.2 scala api
Scala
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("GenerateRDDTest")
val sc = new SparkContext(conf)
//1.从集合创建RDD,并指定并行度为3,默认并行度为1
val rdd1 =sc.parallelize(1 to 20,3)
println(s"rdd1 并行度为:${rdd1.getNumPartitions}")
rdd1.foreach(println)
//2.从集合创建K,V格式RDD
val rdd1KV:RDD[(String,Int)] = sc.parallelize(Array(("a",1),("b",2),("c",3),("d",4),("e",5)))
println(s"rdd1KV 并行度为:${rdd1KV.getNumPartitions}")
rdd1KV.foreach(println)
//3.从集合创建RDD,并指定并行度为3,默认并行度为1
val rdd2 =sc.makeRDD(1 to 20,3)
println(s"rdd2 并行度为:${rdd2.getNumPartitions}")
rdd2.foreach(println)
//4.从文件创建RDD,并指定并行度为3,默认并行度为1
val rdd3 = sc.textFile("./data/data.txt",3)
println(s"rdd3 并行度为:${rdd2.getNumPartitions}")
rdd3.foreach(println)