Transformer实战(17)------微调Transformer语言模型进行多标签文本分类
0. 前言
与单标签分类不同,多标签分类要求模型能够为同一文本分配多个相关标签,这在新闻分类、文献标注、内容推荐等场景中尤为重要。本节以 PubMed 数据集为例,微调 DistilBERT 模型,介绍多标签文本分类的完整实现流程。探讨如何从数据预处理、模型微调、损失函数选择到性能评估,构建一个高效的多标签分类模型,并针对标签不均衡问题提出优化策略。
1. 多标签文本分类
我们已经学习了如何解决多类别文本分类问题,在该问题中每个文本仅分配一个标签。在本节中,我们将讨论多标签分类问题,在该问题中一个文本可以有多个标签。这在自然语言处理 (Natural Language Processing, NLP) 应用中非常常见,例如新闻分类,一条新闻可能同时与体育和健康相关。下图展示了多标签分类的概念:

2. 数据加载与处理
在本节中,我们将深入了解如何实现一个用于多标签分类的流程。使用 PubMed 数据集,该数据集包含约 50000 篇研究文章,每篇文章具有多个标签。数据集由生物医学专家使用 MeSH 标签手动标注,并且每篇文章都基于 14 个 MeSH 标签的组合进行描述。
(1) 首先,导入所需库:
python
import torch, numpy as np, pandas as pd
from datasets import Dataset
from datasets import load_dataset
from transformers import (AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer)(2) PubMed 数据集已经由 Hugging Face Hub 托管,首先从 Hub 下载数据集。为了快速训练,我们仅使用训练数据集的 10%:
python
path="owaiskha9654/PubMed_MultiLabel_Text_Classification_Dataset_MeSH"
dataset = load_dataset(path, split="train[:10%]")
train_dataset=pd.DataFrame(dataset)
text_column='abstractText' # text field
label_names= list(train_dataset.columns[6:])
num_labels=len(label_names)
print('Number of Labels:' , num_labels)
train_dataset[[text_column]+ label_names]如下表所示,数据集中包含一个 abstractText 字段和 14 个可能的标签,其中 1 和 0 分别表示标签是否存在。
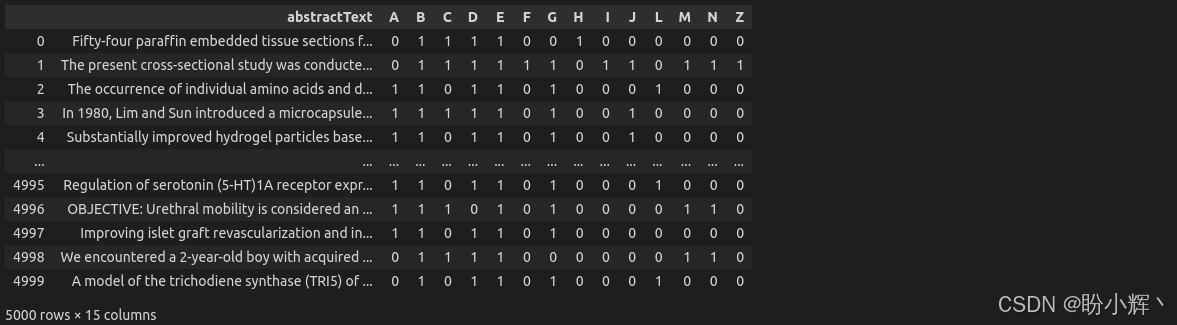
(3) 计算标签分布并进行分析:
python
train_dataset[label_names].apply(lambda x: sum(x), axis=0).plot(kind="bar", figsize=(10,6))可视化结果如下所示:
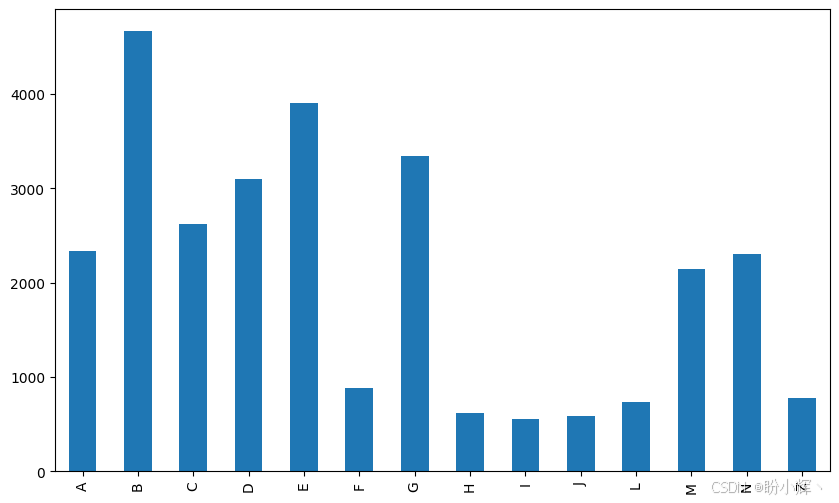
可以看到标签的分布并不平衡,有些标签较少,如 F、H、I、J、L 和 Z。对于整个数据集而言,标签的分布也是类似的。
(4) 将标签列转换为单个列表:
python
train_dataset["labels"]=train_dataset.apply(lambda x: x[label_names].to_numpy(), axis=1)
train_dataset[[text_column, "labels"]]转换后,数据示例如下所示 (abstractText-> labels):
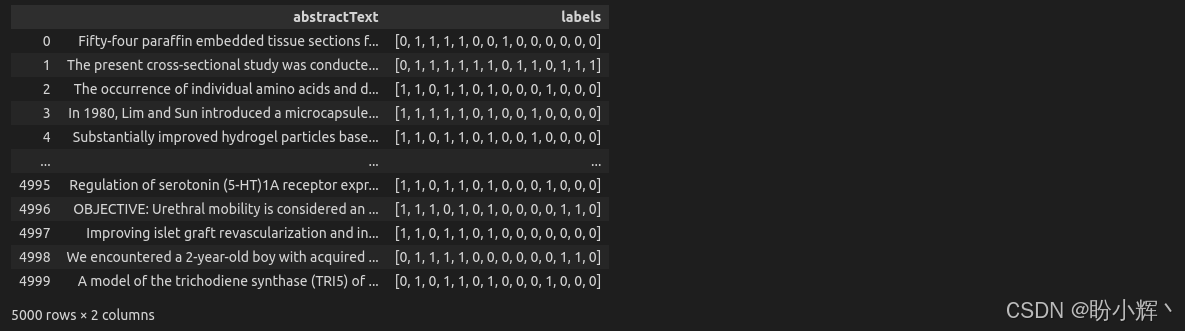
3. 模型微调
(1) 微调 distilbert-base-uncased 模型。由于需要对文本进行分词处理,首先加载 Distilbert 分词器:
python
model_path="distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_path)
def tokenize(batch):
return tokenizer(batch[text_column], padding=True, truncation=True)(2) 将数据集划分为三个子集( 50% 用于训练,25% 用于验证,25% 用于测试),并相应地对它们进行分词处理:
python
q = train_dataset[[text_column, "labels"]].copy()
CUT= int((q.shape)[0]*0.5)
CUT2= int((q.shape)[0]*0.75)
train_df= q[:CUT] # training set
val_df= q[CUT:CUT2] # validations set
test_df= q[CUT2:] # test set
train=Dataset.from_pandas(train_df) #Cast to Dataset object
val=Dataset.from_pandas(val_df)
test=Dataset.from_pandas(test_df)
train_encoded = train.map(tokenize, batched=True, batch_size=None)
val_encoded = val.map(tokenize, batched=True, batch_size=None)
test_encoded = test.map(tokenize, batched=True, batch_size=None)数据集(包含训练集、验证集和测试集)已经通过分词器完成编码,可以输入 Transformer 模型进行处理。接下来,定义函数处理 Transformer 模型最后一层 (logits) 的激活值,生成预测向量。在单标签分类任务中,由于每个样本仅对应一个输出类别,使用 softmax 函数是最合适的选择。然而,在多标签分类任务中,同一输入可能存在多个标签并且相互独立,因此我们采用 sigmoid 函数对每个标签进行独立处理。通过这种方式,模型可以同时预测多个标签,或者完全不选择任何标签。具体而言,我们通过设定阈值 (>0.5) 对 sigmoid 输出进行二值化判断。
(3) 定义 compute_metric() 函数,在训练过程中监控模型性能。通过使用 sklearn 库,计算标签存在性的精确度、召回率和 F1 分数。需要注意的是,在 f1_score() 函数中,设置 pos_label=1,因为我们只关注标签存在的情况。如果同时考虑标签的存在和不存在,可能会导致评估结果虚高,尤其在标签稀疏的场景下,模型性能监控将变得困难:
python
from sklearn.metrics import (f1_score,precision_score, recall_score)
def compute_metrics(eval_pred):
y_pred, y_true = eval_pred
y_pred = torch.from_numpy(y_pred)
y_true = torch.from_numpy(y_true)
y_pred = y_pred.sigmoid() >0.5
y_true=y_true.bool()
r=recall_score(y_true, y_pred,
average='micro', pos_label=1)
p=precision_score(y_true, y_pred,
average='micro', pos_label=1)
f1=f1_score(y_true, y_pred,
average='micro', pos_label=1)
result={"Recall":r,"Precision":p,"F1":f1}
return result(4) 对于单标签多分类任务,我们使用 softmax 激活函数,后接交叉熵损失函数。然而,对于多标签任务,需要使用不同的激活和损失函数。在实现过程中,我们保持原始 Trainer 的所有功能不变,但必须调整损失函数。具体来说,将 Trainer 类原始损失函数 torch.nn.CrossEntropyLoss() 函数替换为 torch.nn.BCEWithLogitsLoss()。如以下类定义所示,torch.nn.BCEWithLogitsLoss() 函数计算真实标签与原始 logits 之间的损失。损失函数首先通过将原始输出 (logits) 传递给 sigmoid 函数来生成预测,并相应地计算损失:
python
class MultilabelTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False, num_items_in_batch=None):
labels = inputs.pop("labels")
outputs = model(**inputs)
logits = outputs.logits
loss_fct = torch.nn.BCEWithLogitsLoss()
preds_=logits.view(-1,self.model.config.num_labels)
labels_=labels.float().view(-1, self.model.config.num_labels)
loss = loss_fct(preds_,labels_)
return (loss, outputs) if return_outputs else loss在此阶段,Trainer 实例和 TrainingArguments 实例与多分类模式大致相同:
python
batch_size=16
num_epoch=3
args = TrainingArguments(
output_dir="/tmp",
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=num_epoch,
do_train=True,
do_eval=True,
load_best_model_at_end=True,
save_steps=100,
eval_steps=100,
save_strategy="steps",
evaluation_strategy="steps")(5) 加载 Distilbert 模型,将模型的输出层大小设置为 14 (即 num_labels):
python
model = AutoModelForSequenceClassification.from_pretrained(model_path, num_labels=num_labels)(6) 开始训练:
python
multi_trainer = MultilabelTrainer(model, args,
train_dataset=train_encoded,
eval_dataset=val_encoded,
compute_metrics=compute_metrics,
processing_class=tokenizer)
multi_trainer.train()(7) 训练完成后,在测试数据集上测试模型:
python
res=multi_trainer.predict(test_encoded)
pd.Series(compute_metrics(res[:2])).to_frame()输出结果如下所示:

我们已经完成了多标签分类模型的训练,需要注意的是,为了快速训练,我们仅使用了部分数据集,使用完整数据集进行训练会获得更高的 F1 分数。
小结
本节针对多标签文本分类任务,介绍了如何使用 DistilBERT 在 PubMed 数据集上微调完成标签预测。为了适应多标签场景,模型输出层激活函数采用 sigmoid,损失函数采用 BCEWithLogitsLoss,并通过自定义 MultilabelTrainer 类将其集成到 Trainer 流程中。在评估阶段,采用微平均方式计算 Precision、Recall 和 F1 分数,最终在测试集上实现了约 0.836 的 F1 分数。
系列链接
Transformer实战(1)------词嵌入技术详解
Transformer实战(2)------循环神经网络详解
Transformer实战(3)------从词袋模型到Transformer:NLP技术演进
Transformer实战(4)------从零开始构建Transformer
Transformer实战(5)------Hugging Face环境配置与应用详解
Transformer实战(6)------Transformer模型性能评估
Transformer实战(7)------datasets库核心功能解析
Transformer实战(8)------BERT模型详解与实现
Transformer实战(9)------Transformer分词算法详解
Transformer实战(10)------生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)------从零开始构建GPT模型
Transformer实战(12)------基于Transformer的文本到文本模型
Transformer实战(13)------从零开始训练GPT-2语言模型
Transformer实战(14)------微调Transformer语言模型用于文本分类
Transformer实战(15)------使用PyTorch微调Transformer语言模型
Transformer实战(16)------微调Transformer语言模型用于多类别文本分类