使用的是ollama
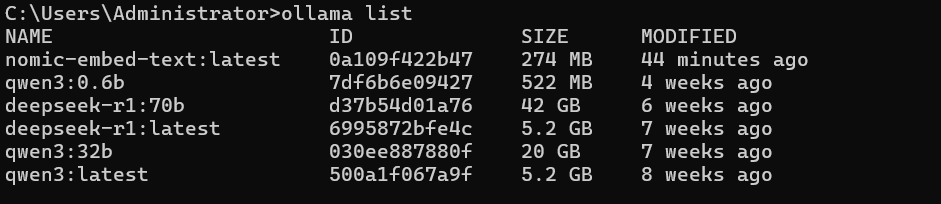
在跑ollama run deepseek-r1:latest时cpu100%,说明没有用到gpu
添加命令:
set CUDA_VISIBLE_DEVICES=0运行正常
但在跑70b的时候,cpu又百分比
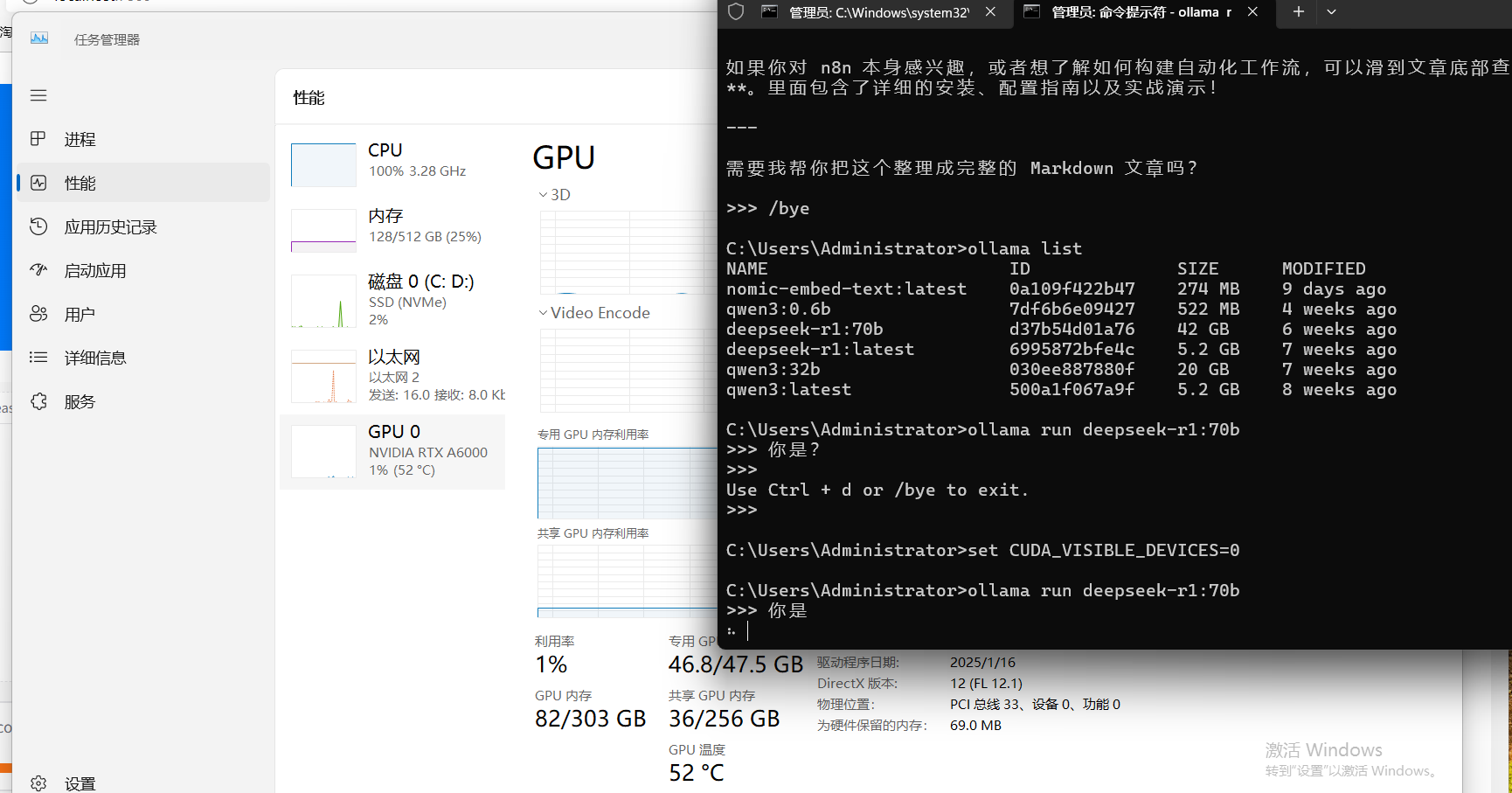
后续问ai解释到



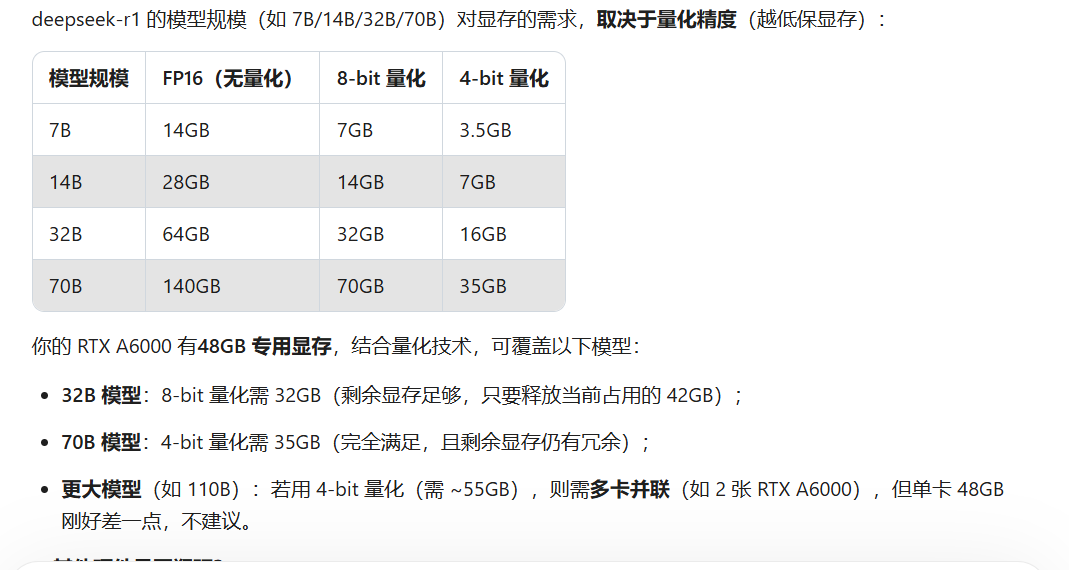 说白了就是GPU硬件不支持,如果要运行70b的
说白了就是GPU硬件不支持,如果要运行70b的


我重启了电脑 gpu直接
哈哈,于是我又运行了ollama run deepseek-r1:70b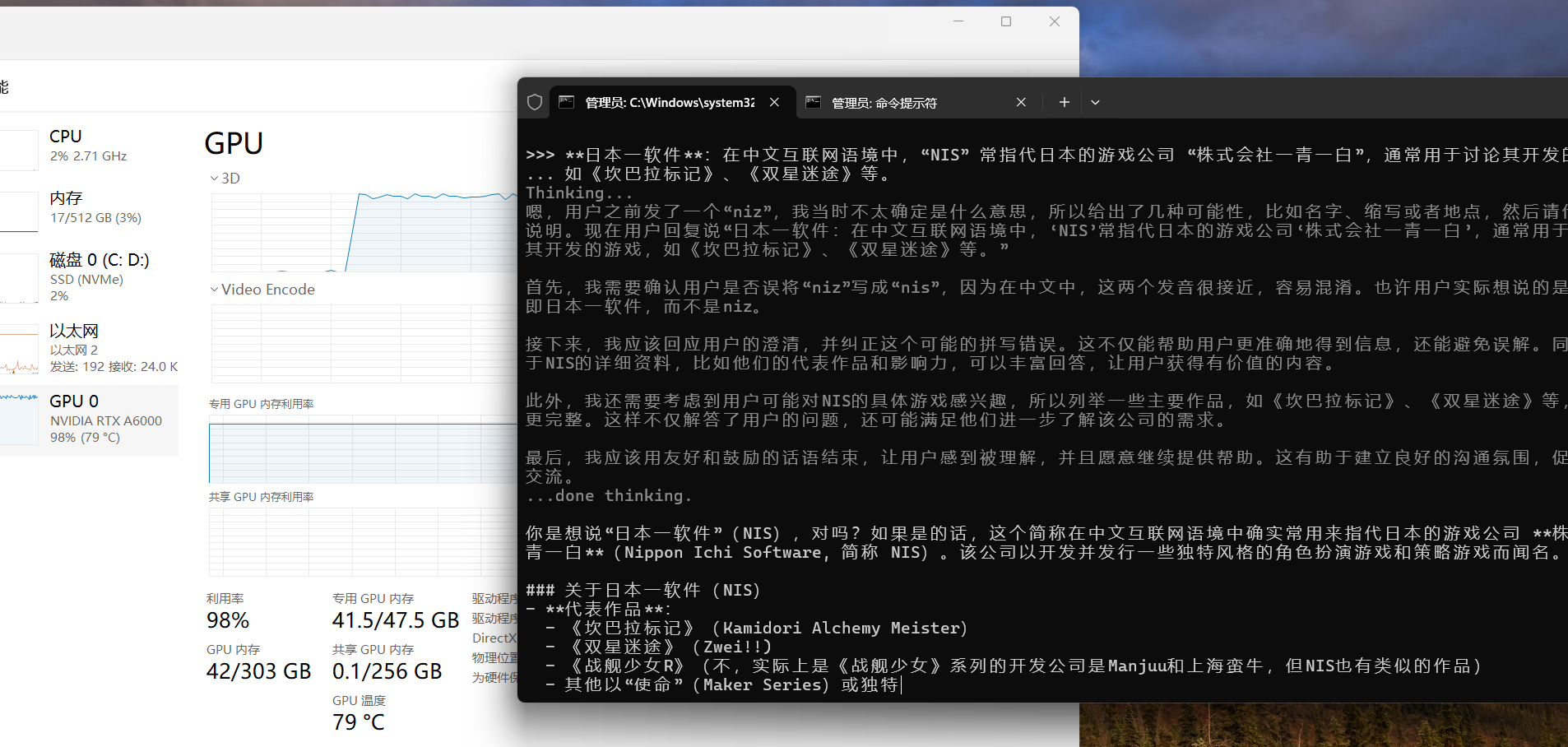
可以了,然后不用了的话
所以说专用内存占用太多,nvidia-smi也看不到(前序进程未释放显存(显存泄漏)),直接重启,然后运行完不用的话要stop
哈哈哈,好好好好好