目录
[2、传统时序统计方法(小样本 / 高可解释性场景)](#2、传统时序统计方法(小样本 / 高可解释性场景))
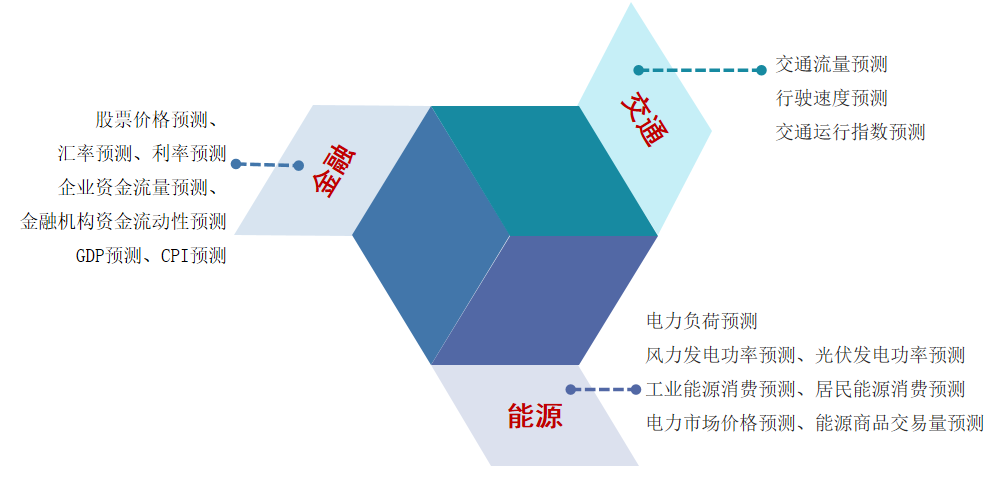
一、时间序列预测
(一)什么是时间序列预测
时间序列预测是一种根据历史时间序列数据来预测未来值的方法。
(二)时序预测任务场景分类
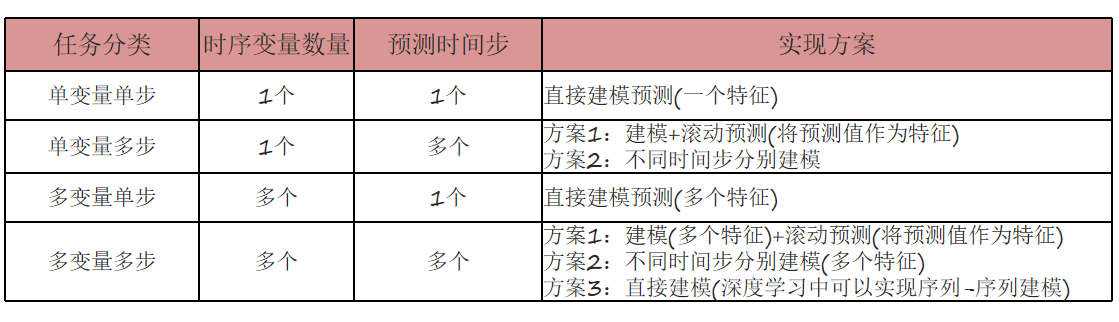
1、分类
--- 单变量单步:根据一个时间序列 变量的历史数据来预测该变量未来一个时间步 的值
例如:股票价格预测 :仅使用"昨日收盘价"这一个变量 的历史数据,来预测"明日收盘价"这一个值。
--- 单变量多步:根据一个时间序列 变量的历史数据来预测该变量未来多个时间步 的值
例如:天气预报 :仅依据"历史气温"这一个变量 ,预测未来3天(3个时间点) 的每日最高气温。
--- 多变量单步:根据多个时间序列 变量的历史数据来预测目标变量未来一个时间步 的值
例如:股票价格预测 :使用"开盘价"、"最高价"、"最低价"、"成交量"多个变量 的历史数据,共同预测"明日收盘价"这一个值。
--- 多变量多步:根据多个时间序列 变量的历史数据来预测目标变量未来多个时间步 的值
例如:综合天气预报:使用"历史温度"、"湿度"、"气压"、"风速"多个变量,预测未来5天每天的"最高温"和"最低温"(多变量输出+多步)。
2、时间步
时间步是序列中单个观测值 的时间索引单位,代表数据采集或建模的最小时间间隔。
- 示例:若数据每小时记录一次,每个时间步对应1小时;若按天记录,时间步为1天。
3、滚动预测
**滚动预测(Rolling Forecast)**是时间序列预测中的核心策略,通过动态更新训练数据或预测起点来提升模型适应性。
核心模式:
**固定窗口滚动:**保持训练集长度(窗口)固定,随时间推进逐步丢弃旧数据。
**扩展窗口滚动:**逐步增加训练集长度,保留所有历史数据。
**混合滚动:**结合固定窗口与扩展窗口,例如限制最大训练长度。
(三)时序预测算法选择
不论是传统机器学习算法还是深度学习算法,解决方案主要是将时序数据处理成二维的结构化数据集,训练机器学习模型进行预测。
-
基于统计学的经典时序预测算法 :简单平均、指数平滑、AR、MA、ARIMA...
-
传统统计模型
- ARIMA (自回归积分滑动平均)
- 适用线性关系、平稳性数据
- 参数:(p,d,q)分别代表自回归阶数、差分次数、移动平均阶数
- SARIMA (季节性ARIMA)
- 增加季节性参数(P,D,Q,s)
- VAR (向量自回归)
- 处理多变量时间序列
- ARIMA (自回归积分滑动平均)
-
-
传统机器学习 算法:回归模型均可,如线性回归、决策树、随机森林、XGBoost、LightGBM、SVM...
- 机器学习方法
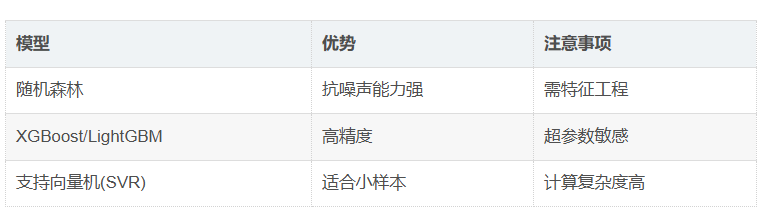
- 机器学习方法
-
深度学习 算法:RNN类算法、基于大模型的iTransformer...
-
深度学习模型
- RNN/LSTM:处理长序列依赖
- Transformer:基于注意力机制(如Informer、Autoformer)
- TCN:因果卷积结构
- Hybrid Models:CNN-LSTM等组合
-
二、电力负荷预测案例背景介绍
(一)背景
1、重要性突出
电力工业是国民经济发展中的重要基础性能源产业,是保证国民经济和社会持续、稳定、健康的发展的关键。电力工业的发展建设对国家各行业起到至关重要的作用。随着改革开放后中国经济的高速发展,各领域的用电需求在不断激增,推动着电力系统向数字化、智能化转型发展。
2、任务复杂艰巨
随着全球对可再生能源的日益重视以及电力系统结构的转型,传统的负荷预测和电力平衡技术面临着新的挑战和机遇。全球范围内,人们对电力系统的可靠性、经济性和环境友好性的要求日益增加,而这些要求往往受到可再生能源波动性和不确定性的影响。
因此,急需解决的关键问题之一是如何准确预测负荷需求,实现电力供需的平衡,并有效整合可再生能源,满足日益增长的电力需求,同时降低碳排放并确保电网稳定运行。
3、大面积停电紧急预案标准
链接:

4、南方电网 ------ 网省一体化AI负荷预测生态系统
南方电网电力调度控制中心(以下简称"南网总调")牵头研发了国内首个适用于区域电力现货市场的网省一体化AI负荷预测生态系统。https://zhuanlan.zhihu.com/p/694562189

① 主要创新性包括以下几点:
(1)研发了国内首个适用于区域电力现货市场的网省一体化Al负荷预测生态系统
(2)构建了一套面向大数据的负荷预测影响因素量化分析技术
(3)构建了基于人工智能深度学习自校正技术的新一代负荷预测模型和算法
(4)设计了科学公正的负荷预测评价考核体系
② 取得成效:

③ 项目的经济效益分为负荷预测准确率的提升、建设运维费用降低、人员使用提质增效。

(二)需求分析

三、电力负荷项目开发步骤


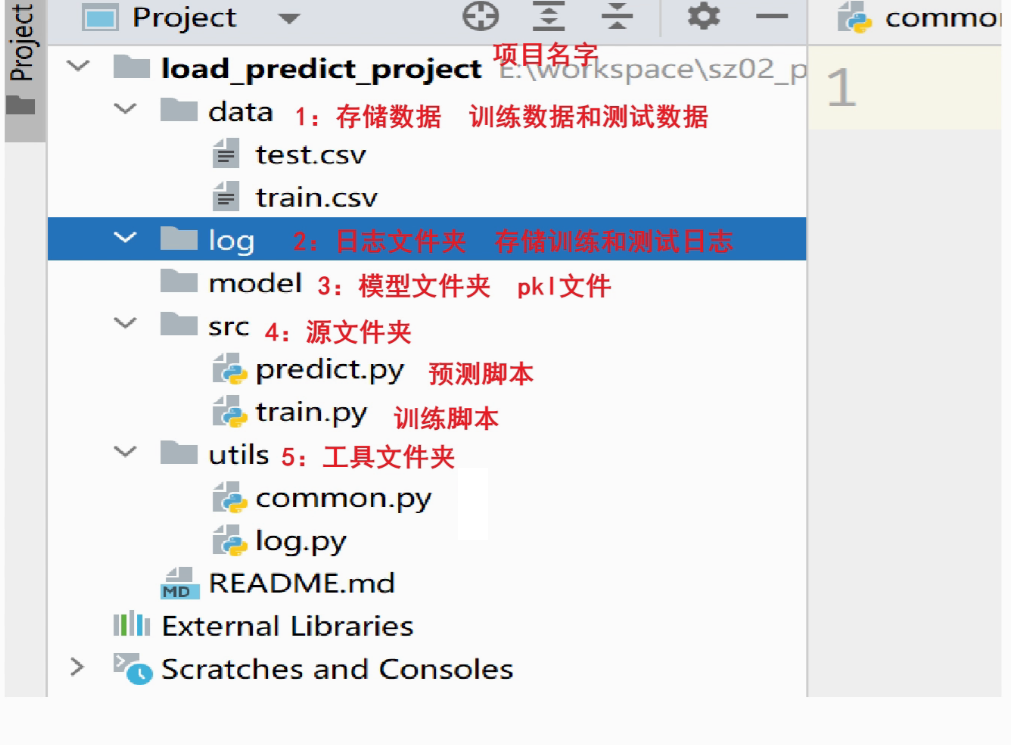
项目结构分析
四、代码
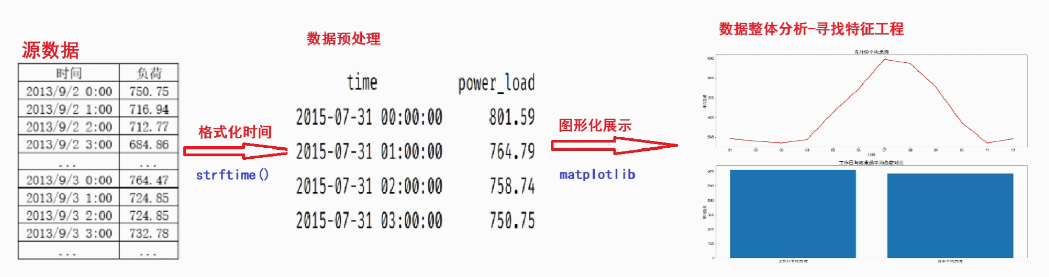
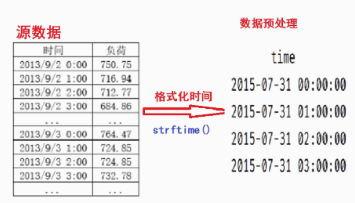
1、数据预处理:转变数据格式
python
#数据预处理函数
"""
1、获取数据源
2、时间格式化,转化为 2015-07-31 00:00:00
3、按照时间升序排序
4、去重
"""
def preprocess(path):
# 获取数据源
data = pd.read_csv(path)
# 使用pandas的to_datetime函数将time列解析为datetime类型
# 然后通过strftime方法格式化为'YYYY-MM-DD HH:MM:SS'字符串格式
data['time'] = pd.to_datetime(data['time']).dt.strftime('%Y-%m-%d %H:%M:%S')
# 时间排序
data.sort_values(by='time', inplace=True)
# 去重
data.drop_duplicates(inplace=True)
return data2、数据分析:查看数据整体分布情况
(业务专家提出)
1.查看数据整体情况
2.负荷整体的分布情况
3.各个小时的平均负荷趋势,看一下负荷在一天中的变化情况
4.各个月份的平均负荷趋势,看一下负荷在一年中的变化情况
5.工作日与周末的平均负荷情况,看一下工作日的负荷与周末的负荷是否有区别
python
def ana_data(data):
ana_data = data.copy()
# ana_data.info()
fig = plt.figure(figsize=(13, 10))
# 添加子图, 参数为行数,列数,子图编号
ax1 = fig.add_subplot(2, 2, 1)
ax1.hist(ana_data['power_load'], bins=100)
ax1.set_title('负荷整体分布情况')
ax1.set_xlabel('负荷')
ana_data['hour'] = ana_data['time'].str[11:13]
hour_load_mean = ana_data.groupby('hour', as_index=False)['power_load'].mean()
ax2 = fig.add_subplot(2, 2, 2)
ax2.plot(hour_load_mean['hour'], hour_load_mean['power_load'])
ax2.set_title('每小时平均负荷')
ax2.set_xlabel('小时')
ana_data['month'] = ana_data['time'].str[5:7]
month_load_mean = ana_data.groupby('month', as_index=False)['power_load'].mean()
ax3 = fig.add_subplot(2, 2, 3)
ax3.plot(month_load_mean['month'], month_load_mean['power_load'])
ax3.set_title('每月平均负荷')
ax3.set_xlabel('月份')
# 判断工作日和休息日
ana_data['weekday'] = ana_data['time'].apply(lambda x: pd.to_datetime(x).weekday())
ana_data['is_holiday'] = ana_data['weekday'].apply(lambda x: 1 if x in [5, 6] else 0) # 5,6为周六和周日
# print(ana_data.head(10))
holiday_load_mean = ana_data[ana_data['is_holiday'] == 1].power_load.mean()
workday_load_mean = ana_data[ana_data['is_holiday'] == 0].power_load.mean()
ax4 = fig.add_subplot(2, 2, 4)
ax4.bar(['工作日', '休息日'], [workday_load_mean, holiday_load_mean])
ax4.set_title('工作日和休息日平均负荷')
ax4.set_xlabel('是否为工作日')
plt.savefig("../data/train_data_analysis.png")
plt.show()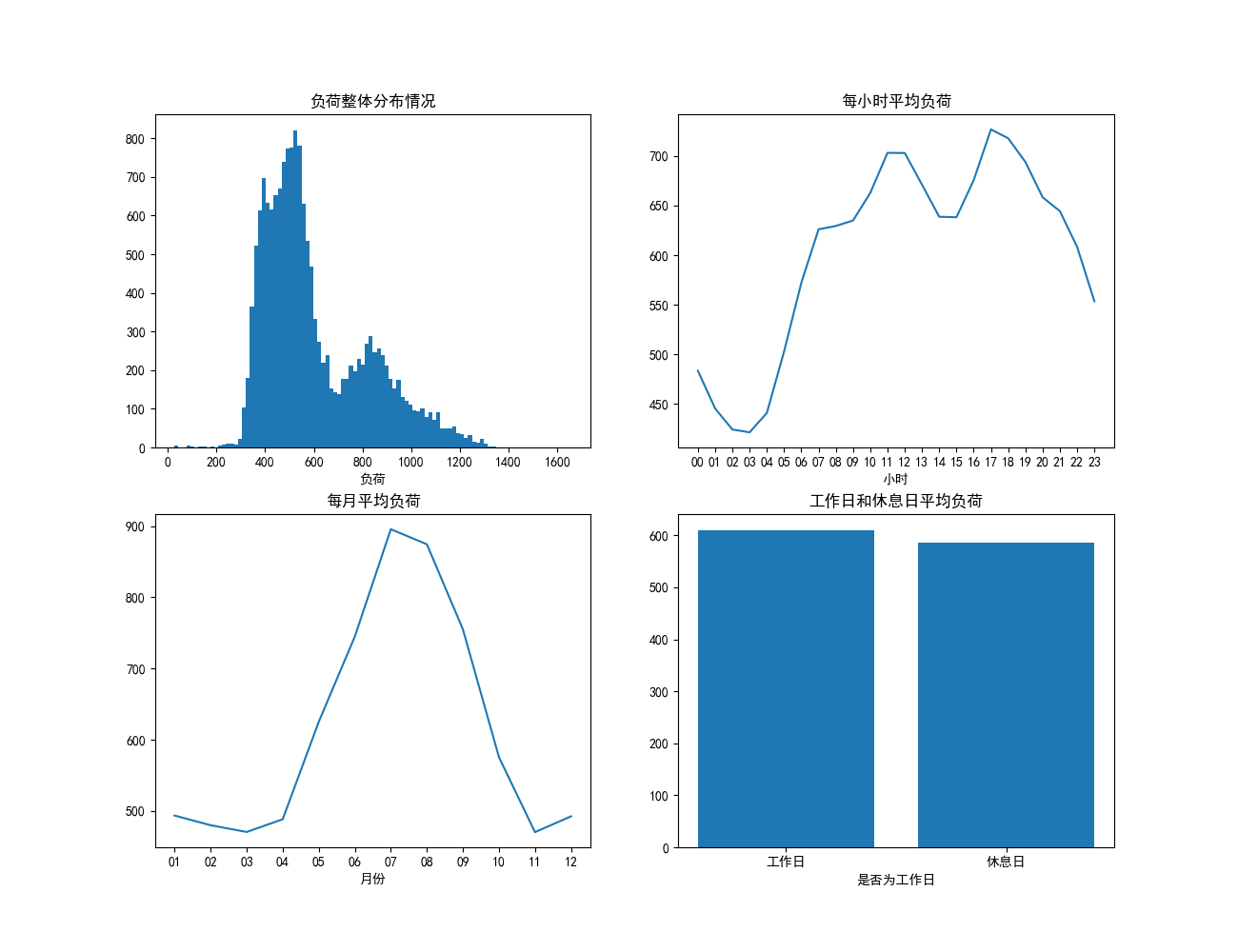
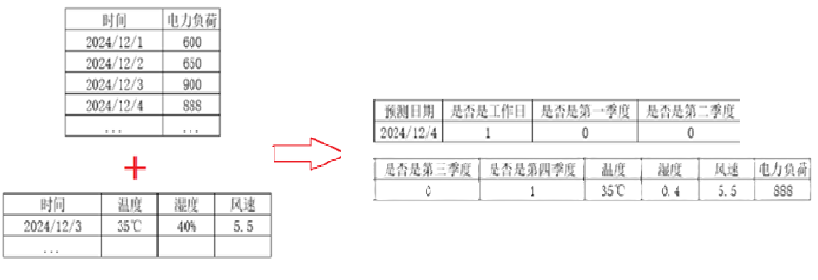
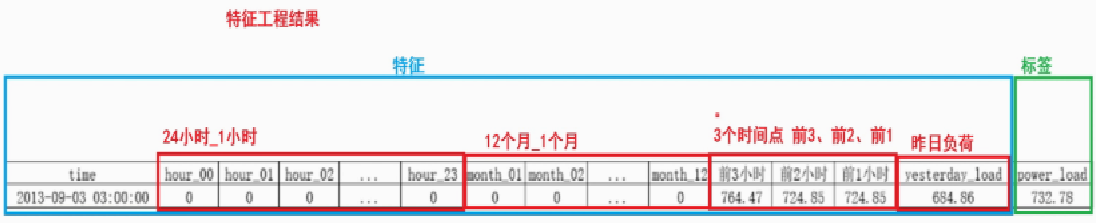
3、数据的特征工程
目的:要获取一下数据集dataframe
python
def feature_engineering(data):
feature_data = data.copy()
# 提取时间特征:小时,月份
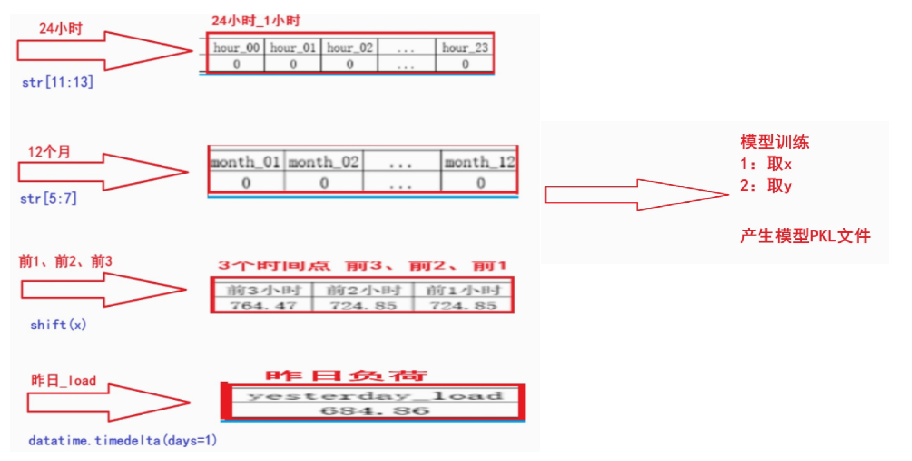
feature_data['hour'] = feature_data['time'].str[11:13]
feature_data['month'] = feature_data['time'].str[5:7]
# print(feature_data.head())
# 热编码
hour_month_data = pd.get_dummies(feature_data[['hour', 'month']])
# print(hour_month_data.head()) 36列,24小时+12个月
# 合并特征
feature_data = pd.concat([feature_data, hour_month_data], axis=1)
# print(feature_data.head()) 40列,原特征+新增的{'hour', 'month'}+24小时+12个月
#计算前期的负荷
load_1h_data = feature_data['power_load'].shift(1, fill_value=0)
load_2h_data = feature_data['power_load'].shift(2, fill_value=0)
load_3h_data = feature_data['power_load'].shift(3, fill_value=0)
load_shift_data = pd.concat([load_1h_data, load_2h_data, load_3h_data], axis=1)
load_shift_data.columns = ['前1小时', '前2小时', '前3小时']
feature_data = pd.concat([feature_data, load_shift_data], axis=1)
# 计算昨天同时刻的负荷
feature_data['yesterday_load'] = \
(feature_data['time'].apply(
lambda x: (pd.to_datetime(x) - datetime.timedelta(days=1)).strftime('%Y-%m-%d %H:%M:%S')))
# print(feature_data.head())
# 把所有日期和负荷拼接成字典,方便查找
# 格式:{'2018-01-01 00:00:00': 0.0}
time_load_dict = feature_data.set_index('time')['power_load'].to_dict()
# print(time_load_dict)
feature_data['yesterday_load'] = feature_data['yesterday_load'].apply(lambda x: time_load_dict.get(x))
# 剔除空样本
feature_data = feature_data.dropna()
# print(feature_data.head())
feature_colums = list(hour_month_data.columns) + list(load_shift_data.columns) + ['yesterday_load']
return feature_data, feature_colums运行结果

4、模型训练,保存模型
python
def train_model(data, feature, logger):
x = data[feature]
y = data['power_load']
# print(x.shape, y.shape)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
# 网格搜索和交叉验证
logger.info("--网格搜索和交叉验证--")
logger.info("开始网格搜索,时间:" + str(datetime.datetime.now()))
es = XGBRegressor()
param_grid = {'n_estimators': [100, 150, 50],
'max_depth': [5, 8, 10, 15],
'learning_rate': [0.1, 0.01, 0.001], }
gs = GridSearchCV(estimator=es, param_grid=param_grid, cv=3)
gs.fit(x_train, y_train)
start_time = datetime.datetime.now()
logger.info("结束网格搜索,时间:" + str(start_time))
# 打印最佳参数和最佳得分
logger.info("最佳参数:%s", gs.best_params_)
logger.info("最佳得分:%s", gs.best_score_)
# 训练模型实例化
es = XGBRegressor(n_estimators=150, max_depth=5, learning_rate=0.1)
es.fit(x_train, y_train)
y_pre = es.predict(x_test)
# 模型评估
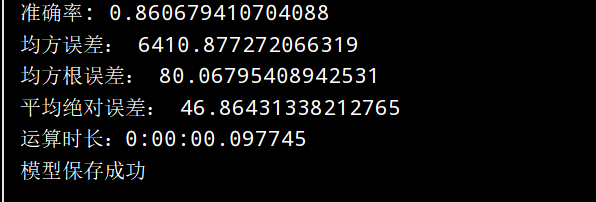
print(f"准确率: {es.score(x_test, y_test)}")
print(f'均方误差:', mean_squared_error(y_true=y_test, y_pred=y_pre))
print(f"均方根误差:", np.sqrt(mean_squared_error(y_true=y_test, y_pred=y_pre)))
print(f'平均绝对误差:', mean_absolute_error(y_true=y_test, y_pred=y_pre))
# 运算时长
print(f'运算时长:{datetime.datetime.now() - start_time}')
joblib.dump(es, '../model/power_load_model.pkl')
print('模型保存成功')运行结果
日志结果

输出
5、开发预测模块
实现流程:
1.导包、配置绘图字体
2.定义电力负荷预测类(PowerLoadPredict),配置日志,获取数据源、历史数据转为字典(避免频繁操作dataframe,提高效率)
3.加载模型
4.模型预测(重点)
4.1 确定要预测的时间段(2015-08-01 00:00:00及以后的时间)
4.2 为了模拟实际场景的预测,把要预测的时间以及以后的负荷都掩盖掉,因此新建一个数据字典,只保存预测时间以前的数据字典
4.3 预测负荷
4.3.1 解析特征(定义解析特征方法)
4.3.2 利用加载的模型预测
4.4 保存预测时间对应的真实负荷
4.5 结果保存到evaluate_list,三个元素分别是预测时间、真实负荷、预测负荷,方便后续进行预测结果评价
4.6 循环结束后,evaluate_list转为DataFrame
5.预测结果评价
5.1 计算预测结果与真实结果的MAE
5.2 绘制折线图(预测时间-真实负荷折线图,预测时间-预测负荷折线图),查看预测效果
1、导包,定义电力负荷预测类
python
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import datetime
from utils.log import Logger
from utils.common import preprocess
from xgboost import XGBRegressor
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_squared_error, mean_absolute_error, root_mean_squared_error
import joblib
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
class PowerLoadPredict(object):
def __init__(self, file_path):
# 配置日志记录
logfile_name = 'predict'+datetime.datetime.now().strftime('%Y%m%d%H%M%S')
Logger('../', logfile_name).get_logger()
# 获取数据源
self.data_source = preprocess(file_path)
# 数据转化为字典,key为时间,value为负荷,目的避免频繁调用DataFrame
# 实际开发,缓存到数据库radis中
self.time_load_dict = self.data_source.set_index('time').power_load.to_dict()2、模型预测(获取时间)
python
# 加载训练模型
es = joblib.load('../model/power_load_model.pkl')
# 取预测时间,预测时间段为2015-08-01 00:00:00之后的数据
pre_times = plp.data_source['time'][plp.data_source['time'] >= '2015-08-01 00:00:00']
# print(pre_time)
# 获取预测时间点之前的数据
# 写法一:时间写死了
time_load_dict_masked = {key: value for key, value in plp.time_load_dict.items() if key < '2015-08-01 00:00:00'}
print(time_load_dict_masked)
# 写法二:时间动态获取
for pre_time in pre_times:
print(f'正在预测时间{pre_time}的负荷')
plp.logger.info(f'正在预测时间{pre_time}的负荷')
time_load_dict_masked = {key: value for key, value in plp.time_load_dict.items() if key < pre_time}
print(time_load_dict_masked)3、解析特征(定义解析特征方法)
python
# 预测数据解析特征。保持与模型训练的数据一致
def pre_features_extract(data_dict, time, logger):
"""
预测数据解析特征,保持与模型训练时的特征列名一致
1.解析时间特征
2.解析时间窗口特征
3.解析昨日同时刻特征
:param data_dict:历史数据,字典格式,key:时间,value:负荷
:param time:预测时间,字符串类型,格式为2024-12-20 09:00:00
:param logger:日志对象
:return:
"""
logger.info(f'=======解析时间为{time}所对应的特征=======')
feature_name = ['hour_00', 'hour_01', 'hour_02', 'hour_03', 'hour_04', 'hour_05', 'hour_06', 'hour_07', 'hour_08',
'hour_09', 'hour_10', 'hour_11', 'hour_12', 'hour_13', 'hour_14', 'hour_15', 'hour_16', 'hour_17',
'hour_18', 'hour_19', 'hour_20', 'hour_21', 'hour_22', 'hour_23', 'month_01', 'month_02',
'month_03','month_04', 'month_05', 'month_06', 'month_07', 'month_08', 'month_09',
'month_10', 'month_11','month_12', '前1小时', '前2小时', '前3小时', 'yesterday_load']
# 解析时间特征
# 获取要预测的小时信息 2015-08-01 00:00:00
pre_hour = time[11:13]
hour_list = []
# feature_name前24项
for i in range(24):
if pre_hour == feature_name[i][5:7]:
hour_list.append(1)
else:
hour_list.append(0)
# print(hour_list)
# 获取要预测的月份信息 2015-08-01 00:00:00
pre_month = time[5:7]
month_list = []
for i in range(24, 36):
if pre_month == feature_name[i][6:8]:
month_list.append(1)
else:
month_list.append(0)
# print(month_list)
# 解析时间窗口的特征
last_1h_time = (pd.to_datetime(time)-pd.to_timedelta('1h')).strftime('%Y-%m-%d %H:%M:%S')
last_1h_time = data_dict.get(last_1h_time, 500) # 填充500
last_2h_time = (pd.to_datetime(time)-pd.to_timedelta('2h')).strftime('%Y-%m-%d %H:%M:%S')
last_2h_time = data_dict.get(last_2h_time, 500) # 填充500
last_3h_time = (pd.to_datetime(time) - pd.to_timedelta('3h')).strftime('%Y-%m-%d %H:%M:%S')
last_3h_time = data_dict.get(last_3h_time, 500) # 填充500
yesterday_time = (pd.to_datetime(time)-pd.to_timedelta('1d')).strftime('%Y-%m-%d %H:%M:%S')
yesterday_time = data_dict.get(yesterday_time, 500) # 填充500
# 拼接特征数据
feature_data = hour_list + month_list + [last_1h_time, last_2h_time, last_3h_time, yesterday_time]
# 转化成df
feature_df = pd.DataFrame([feature_data], columns=feature_name)
# print(feature_df.head())
return feature_df4、模型预测
python
y_pre = es.predict(feature_df)
true_value = plp.time_load_dict.get(pre_time, 500)
evaluate_list.append([pre_time, true_value, y_pre[0]])
plp.logger.info("预测时间:{},真实值:{},预测值:{}".format(pre_time, true_value, y_pre[0]))5、预测结果评价
python
# 模型评估
def predict_plot(data):
# 创建图形对象并设置画布大小
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot()
# 绘制真实负荷和预测负荷曲线
ax.plot(data['预测时间'], data['真实负荷'], label='真实负荷', color='blue')
ax.plot(data['预测时间'], data['预测负荷'], label='预测负荷', color='red')
# 设置图表标题、坐标轴标签和网格
ax.set_title('真实值负荷与预测值负荷的关系图', fontsize=30)
ax.set_xlabel('时间')
ax.set_ylabel('负荷')
ax.grid(True, linestyle='--', alpha=0.5)
# 设置图例,位置自动选择最佳位置,字体大小为20
ax.legend(loc='best', fontsize=20)
# 设置x轴主刻度间隔为50
ax.xaxis.set_major_locator(mick.MultipleLocator(50))
# 设置x轴刻度标签旋转55度,防止标签重叠
plt.xticks(rotation=55)
# 保存图表到指定路径,文件名为"真实值负荷与预测值负荷的关系图.png"
plt.savefig("../data/真实值负荷与预测值负荷的关系图.png")
plt.show()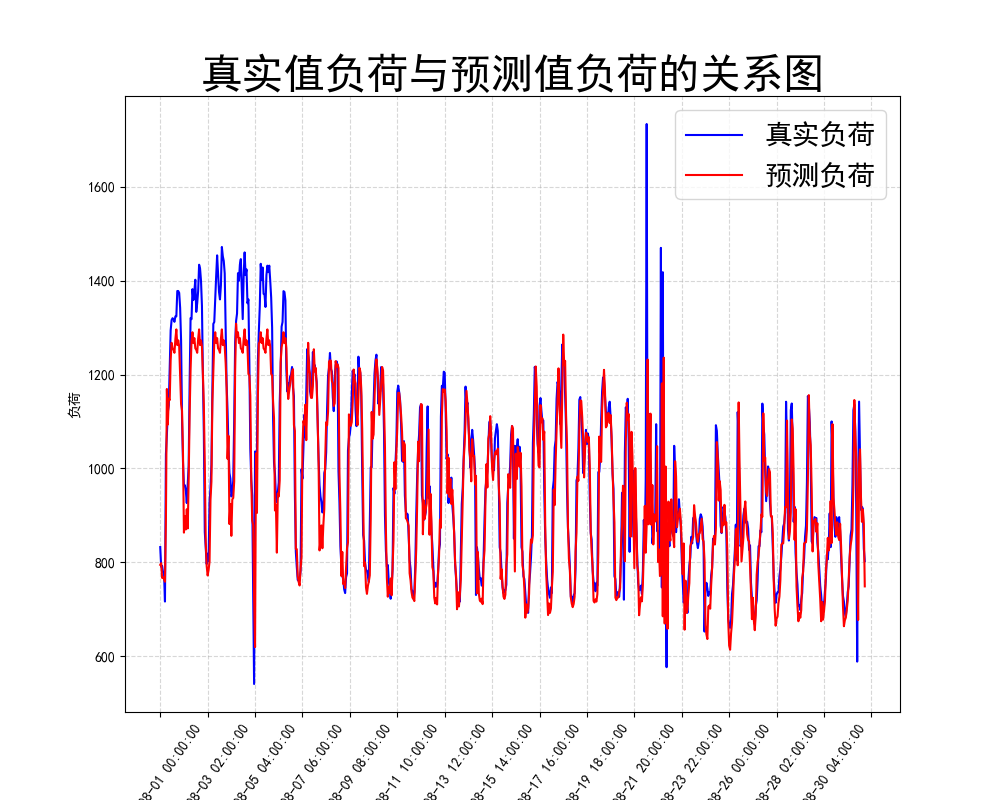
6、主程序
python
if __name__ == '__main__':
plp = PowerLoadPredict('../data/test.csv')
# print(plp.time_load_dict)
# 加载训练模型
es = joblib.load('../model/power_load_model.pkl')
# 取预测时间,预测时间段为2015-08-01 00:00:00之后的数据
pre_times = plp.data_source['time'][plp.data_source['time'] >= '2015-08-01 00:00:00']
# print(pre_time)
evaluate_list = []
# 获取预测时间点之前的数据
# 写法一:时间写死了
# time_load_dict_masked = {key: value for key, value in plp.time_load_dict.items() if key < '2015-08-01 00:00:00'}
# print(time_load_dict_masked)
# 写法二:时间动态获取
for pre_time in pre_times:
# print(f'正在预测时间{pre_time}的负荷')
plp.logger.info(f'正在预测时间{pre_time}的负荷')
time_load_dict_masked = {key: value for key, value in plp.time_load_dict.items() if key < pre_time}
# print(time_load_dict_masked)
# 预测负荷
# 解析特征(定义解析特征的方法)
feature_df = pre_features_extract(time_load_dict_masked, pre_time, plp.logger)
# 预测
y_pre = es.predict(feature_df)
true_value = plp.time_load_dict.get(pre_time, 500)
evaluate_list.append([pre_time, true_value, y_pre[0]])
plp.logger.info("预测时间:{},真实值:{},预测值:{}".format(pre_time, true_value, y_pre[0]))
# 循环结束后,封装evaluate_list为DataFrame
evaluate_df = pd.DataFrame(evaluate_list,columns=["预测时间", "真实负荷", "预测负荷"])
# 预测结果评估
print(f"平均绝对误差:{mean_absolute_error(evaluate_df['真实负荷'], evaluate_df['预测负荷'])}")
predict_plot(evaluate_df)五、案例改进
1、特征工程角度
- 优化时间窗口
- 提取更有效的历史负荷特征
- 扩展外部特征,比如温度、湿度、风速、历史工业用电量、历史居民用电量等
2、算法角度
- 样本分群然后分别建模,比如分地区或者借助聚类算法先进行分群,然后针对不同分区分别训练模型,提升模型的适用性
- 寻找更优的算法,比如LightGBM、RNN类、iTransformer等算法
- 寻找更优的算法组合,比如bagging方式或stacking方式进行模型组合
3、预测(推理)速度角度
- 预测时也需要特征工程处理,历史负荷可以缓存到redis,使用时直接查询
4、扩展性角度
- 扩展通用的工具包,适用于各种数据源的输入输出,如mysql、pgsql、oracle、ES、redis、Hive等数据库的支持
- 项目打包成容器,适配各种服务器环境
- 预测模块与项目解耦,预测模块封装出接口,接收web传过来的参数,根据参数获取数据并进行预测
六、算法对比
XGBoost 的核心局限是 "无法原生捕捉时序长依赖""长周期预测精度不足",而:
- 若需提升长周期 / 复杂波动预测精度,优先选 LSTM/Transformer;
- 若需平衡效率与精度(海量数据) ,优先选 LightGBM;
- 若需高可解释性 / 小样本稳定预测,优先选 ARIMA/Prophet;
- 若需融合多类型特征(含类别特征) ,优先选 CatBoost/TFT。
1、深度学习类方法(最主流的进阶方向)
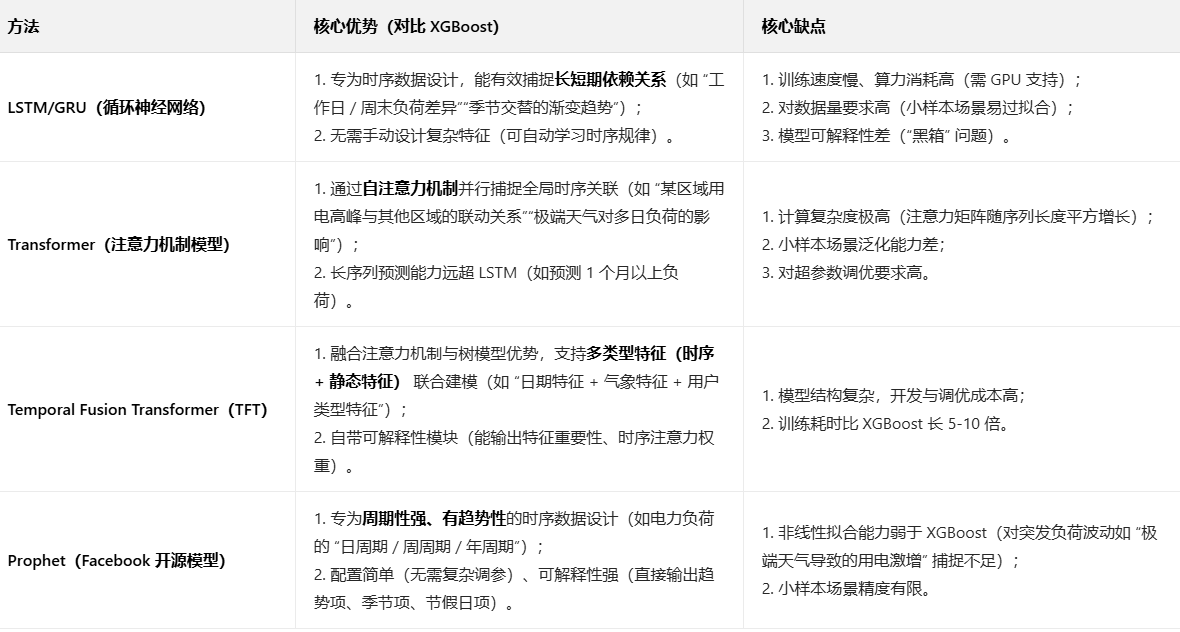

2、传统时序统计方法(小样本 / 高可解释性场景)
传统时序方法基于统计理论建模,虽非线性拟合能力弱于 XGBoost,但在小样本数据、高可解释性需求、短期简单预测场景中更实用,且计算成本低。


3、其他集成学习方法(平衡精度与效率)
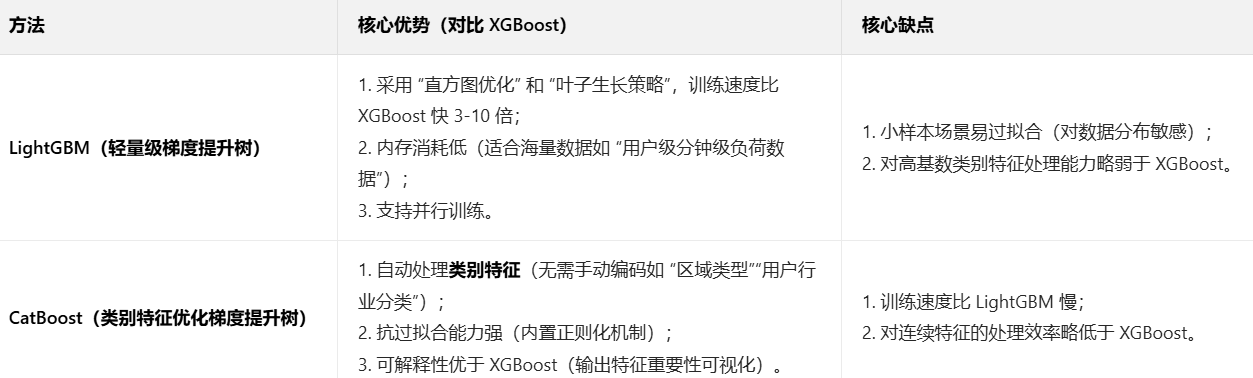

4、方法选择决策指南(关键维度)
-
预测周期:
- 超短期(1-6 小时):指数平滑法、LightGBM(效率优先);
- 短期(1-7 天):XGBoost、CatBoost(平衡精度与效率);
- 中长期(7 天 - 1 年):LSTM/GRU、Prophet(时序依赖 / 周期性优先);
- 超长期(1 年以上):Transformer、TFT(全局关联优先)。
-
数据条件:
- 小样本(<1 万条):ARIMA、指数平滑法(统计稳定性优先);
- 中样本(1 万 - 100 万条):XGBoost、LightGBM(集成效率优先);
- 大样本(>100 万条):LSTM、Transformer(深度学习捕捉复杂规律)。
-
业务需求:
- 可解释性优先(如调度汇报、合规要求):ARIMA、Prophet、CatBoost;
- 精度优先(如电网规划、成本控制):Transformer、TFT、LSTM;
- 效率优先(如实时预测、高频更新):LightGBM、指数平滑法。