一、昇腾910 AI处理
1. 昇腾910技术参数
昇腾910芯片,是当前计算密度最大的单芯片,适用于AI模型训练,采用7nm制作工艺。其性能接近英伟达 A100(40GB),半精度(FP16)算力达到 320 TFLOPS,整数精度(INT8)算力达到 640TOPS,最大功耗为310瓦。
**注:**算力是衡量AI芯片最核心的指标,通常用每秒能执行多少次浮点运算(FLOPS)或整数运算(OPS)来表示。FP16: 是一种浮点数格式,占用16位(2字节)存储空间。AI训练中的许多计算并不需要非常高的数值精度,使用FP16可以大幅提升计算速度并减少内存占用,同时基本保持模型精度。320 TFLOPS: 即每秒执行320万亿(10^12)次浮点运算。这是一个极其庞大的数字,展现了其处理海量AI数据的强大能力。INT8: 是一种整数格式,占用8位(1字节)存储空间。常用于AI推理阶段,在某些场景下也可用于训练。640 TOPS: 即每秒执行640万亿(10^12)次整数运算。通常INT8算力是FP16算力的两倍,这与640 TOPS正好是320 TFLOPS的两倍相符,符合芯片设计预期。
此外,昇腾 910 还集成了 HCCS、PCIe 4.0 和 RoCE v2 接口,为构建横向扩展(Scale Out)和纵向扩展(Scale Up)系统提供了灵活高效的方法,互联能力突出。
**优势:**强大的连接和组网能力,这对于将多个芯片组合成一个更强大的整体至关重要。
**核心接口技术:**HCCS、PCIe 4.0 和 RoCE v2 接口
HCCS (华为自定义芯片间互联技术): 主要用于同一台服务器内部,多个昇腾910芯片之间的直接高速连接。它 bypasses(绕过)了标准PCIe通道的瓶颈,提供了更高的带宽和更低的延迟,使得多个芯片可以像一个大芯片一样协同工作。
PCIe 4.0: 这是一种行业标准的通用高速接口,是芯片与服务器主板上的CPU(中央处理器)进行通信的主要通道。PCIe 4.0比上一代PCIe 3.0带宽翻倍,确保了芯片能从CPU和系统内存高效地获取数据,也可以连接其他支持PCIe的设备,如网卡、存储卡等。
RoCE v2 (RDMA over Converged Ethernet v2): RDMA远程直接内存访问是一种网络技术,允许一台计算机直接访问另一台计算机的内存,无需对方操作系统的参与。这极大地降低了延迟和CPU开销。RoCE就是让RDMA技术跑在标准的以太网上。主要用于多台服务器之间的高速网络通信。通过RoCEv2,一台服务器中的昇腾910可以直接、高速地访问另一台服务器中昇腾910的内存,这对于分布式训练至关重要。
纵向扩展 (Scale Up): 通过HCCS技术,将一台服务器内部的多个昇腾910芯片紧密地连接起来,整合成一个更大的、统一的计算资源。解决单个芯片无法处理的大型任务,降低多芯片间的通信延迟。
横向扩展 (Scale Out): 通过RoCE v2网络技术,将多台配备了昇腾910的服务器连接成一个集群。处理极其庞大的AI训练任务,将任务分解到成千上万个芯片上并行计算。
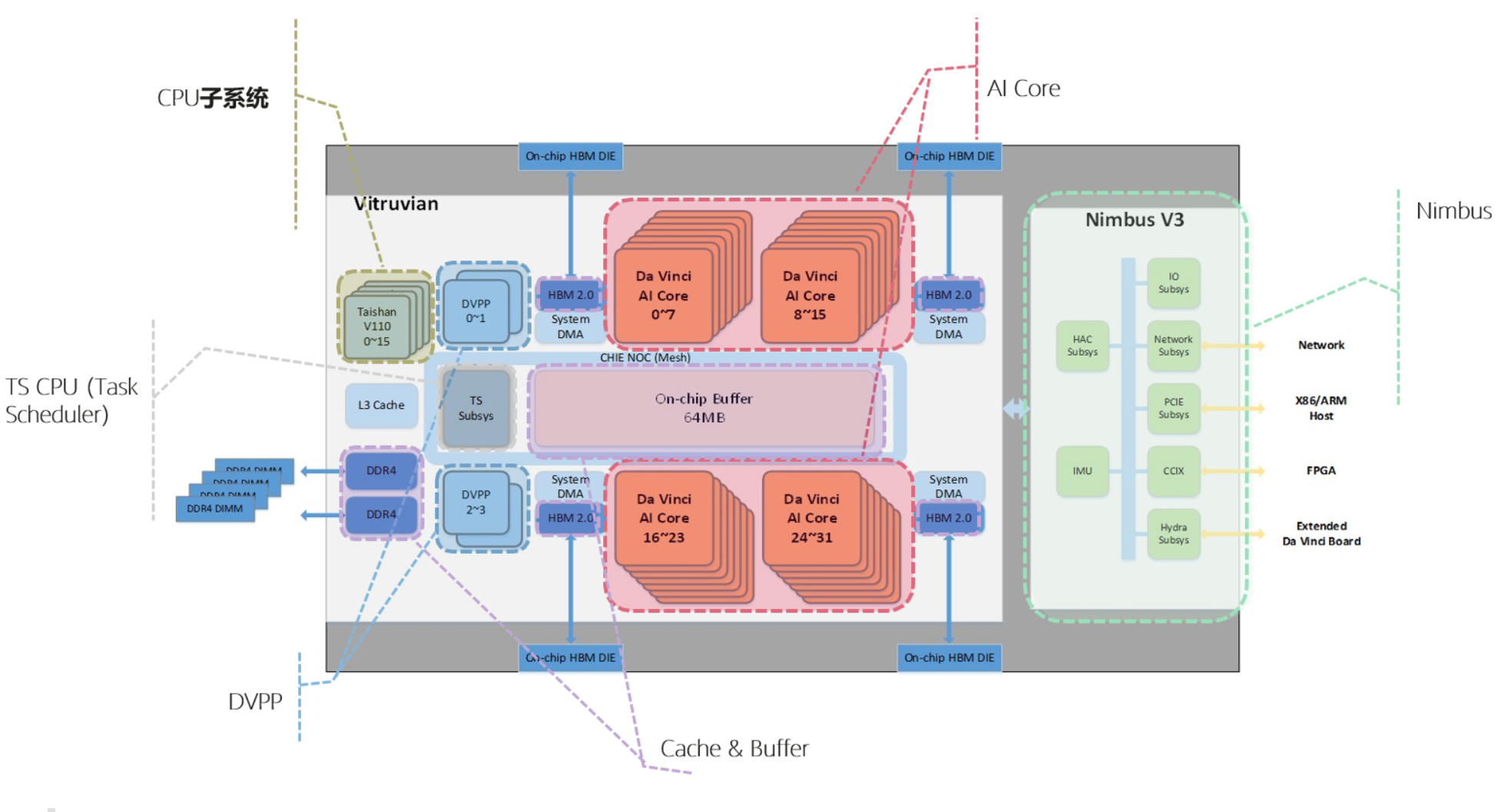
上图展示了昇腾910的硬件逻辑架构图。从图上可以看出,昇腾910包含多个关键组件,如AI Core、CPU子系统、DVPP等,这些组件协同工作,确保高效的计算和数据处理能力。
AI Core 是昇腾910的计算核心,采用达芬奇架构,主要负责执行矩阵、向量计算密集的算子任务,比如卷积神经网络的运算。 根据不同型号,昇腾910集成了32/30个AI Core。
CPU子系统集成了16个TaishanV110 Core(4个Core构成一个Cluster)。这些Taishan Core一部分部署为AI CPU,承担部分AI计算功能,执行CPU类算子,包括控制算子、标量和向量等通用计算;一部分部署为Ctrl CPU,负责SoC的控制功能。两类CPU占用的CPU核数由软件分配。
**注:**CPU子系统 在昇腾910这种大型SoC(片上系统)芯片中,除了负责核心AI计算的NPU(神经网络处理器)单元,还会集成一些传统的CPU核心,形成一个CPU子模块。这个模块负责处理不适合NPU执行的通用任务和芯片的控制管理工作。TaishanV110 Core是华为自研的ARM架构的CPU核心。这表明昇腾910没有使用通用的商用CPU核心,而是采用了自家设计的、更适合与AI加速单元协同工作的核心。(4个Core构成一个Cluster)是芯片设计中的一个常见拓扑结构。Cluster是一个集群或簇。将16个核心分成4组,每组4个。这种设计有助于:优化内存访问, 同一个Cluster内的核心可以共享某些缓存或内存通路,降低访问延迟。提升能效和管理效率, 可以以Cluster为单位进行电源管理。
DVPP(数字视觉预处理模块)提供了对视频和图像的解码、编码和预处理功能,是多媒体处理的关键组件。
**注:**在AI任务中,尤其是处理图像和视频时,原始数据并不能直接扔给神经网络(NPU)进行计算。原因如下:①格式不匹配: 神经网络需要的是原始的、规整的像素数据。而我们存储和传输的媒体文件为了节省空间,都是经过压缩编码的,需要先解码。②尺寸不匹配: 神经网络的输入层尺寸是固定的。但原始图片/视频帧的尺寸千变万化,这就需要缩放。③数据排布不匹配: 解码出来的数据排布可能不符合NPU计算引擎的最高效要求,这就需要进行格式转换。如果所有这些工作都交给主机的CPU来完成,会大量消耗CPU资源,并且数据需要在主机内存和加速卡内存之间来回传输,造成额外的延迟和带宽瓶颈。DVPP就是为了解决这些问题而生的专用硬件模块。
TS CPU(Task Scheduler)是一个独立的4核A55 Cluster(ARMv8 64位架构),负责任务调度,把算子任务切分之后,通过硬件调度器(HWTS),分发给AI Core或AI CPU。
对外接口提供x16 PCIe 4.0接口,和Host CPU对接,提供100G NIC(支持ROCE V2协议)用于跨服务器传递数据。还集成了1个A53 CPU核,执行启动、功耗控制等硬件管理任务。
注:"对外接口提供x16 PCIe 4.0接口,和Host CPU对接",意思是芯片与所在服务器主板进行连接和通信的主要通道。PCIe 4.0: 是当前服务器领域标准的高速串行计算机扩展总线标准。第4代比第3代带宽翻倍。x16: 表示使用了16条PCIe通道,这是为显卡和加速卡提供的最大带宽配置。和Host CPU对接: "Host CPU"指的是服务器中的主CPU。这条高速公路连接了昇腾910和主CPU。
Cache & Buffer:芯片内有层次化的memory结构,AI Core内部有两级memory buffer,SOC片上还有64MB L2 buffer。芯片连接4个HBM 2.0颗粒,总计32GB容量。芯片还集成了DDR 4.0控制器,为芯片提供DDR内存。
注:"AI Core内部有两级memory buffer" 位置 在每个AI计算核心的内部,是距离计算单元最近的存储器,速度极快,但容量很小。第一级 (L1 Buffer): 速度最快,容量最小。用于存放计算单元立即需要的极少数据。第二级 (L2 Buffer): 速度比L1稍慢,但容量更大一些。作为L1的补给站,存放下一批即将被送入L1进行计算的数据。 减少计算核心的直接等待,计算核心速度极快,如果每次都去远处拿数据,大部分时间都会在等待。"SOC片上还有64MB L2 buffer" 位置 在昇腾910这个芯片(SoC) 的内部,但在所有AI Core之外。它是被所有AI Core共享的, 这是一块容量更大(64MB)的片上高速缓存。 作为AI Core私有缓存的共享补给库。它从更慢、更大的主存(HBM)中预取数据,然后根据需求分发给各个AI Core的内部缓存。"芯片连接4个HBM 2.0颗粒,总计32GB容量。"在芯片外部,但通过先进封装技术与芯片封装在同一个基板上,物理距离非常近。 HBM(高带宽存储器) 是当前最先进的内存技术之一。HBM 2.0: 是其第二代标准。4个颗粒,32GB: 通过堆叠多个DRAM芯片(3D堆叠)并通过硅通孔(TSV)连接,实现了极高的带宽和较大的容量。这是昇腾910的主内存(VRAM)。"芯片还集成了DDR 4.0控制器,为芯片提供DDR内存。" DDR 是我们电脑和服务器中最常见的主内存(系统内存)标准。DDR4.0控制器是芯片内部的一个硬件模块,专门用于读写外部的、插在主板上的DDR4内存条。提供更大容量但速度相对较慢的存储空间。
二、昇腾310 AI处理器
1. 昇腾310技术参数
昇腾310是高能效比推理型AI处理器,基于达芬奇架构,采用12nm工艺制造,功耗只有8瓦。其本质上是一块SoC,集成了多个运算单元,包括CPU(8个a55)、AI Core、数字视觉预处理子系统等,实现高通量、大算力和低功耗的推理能力。
目前该芯片能对整型数(INT8、INT4) 或对浮点数(FP16)提供强大的算力,FP16算力为8TOPS,INT8算力16TOPS。
2. 昇腾310硬件逻辑构架
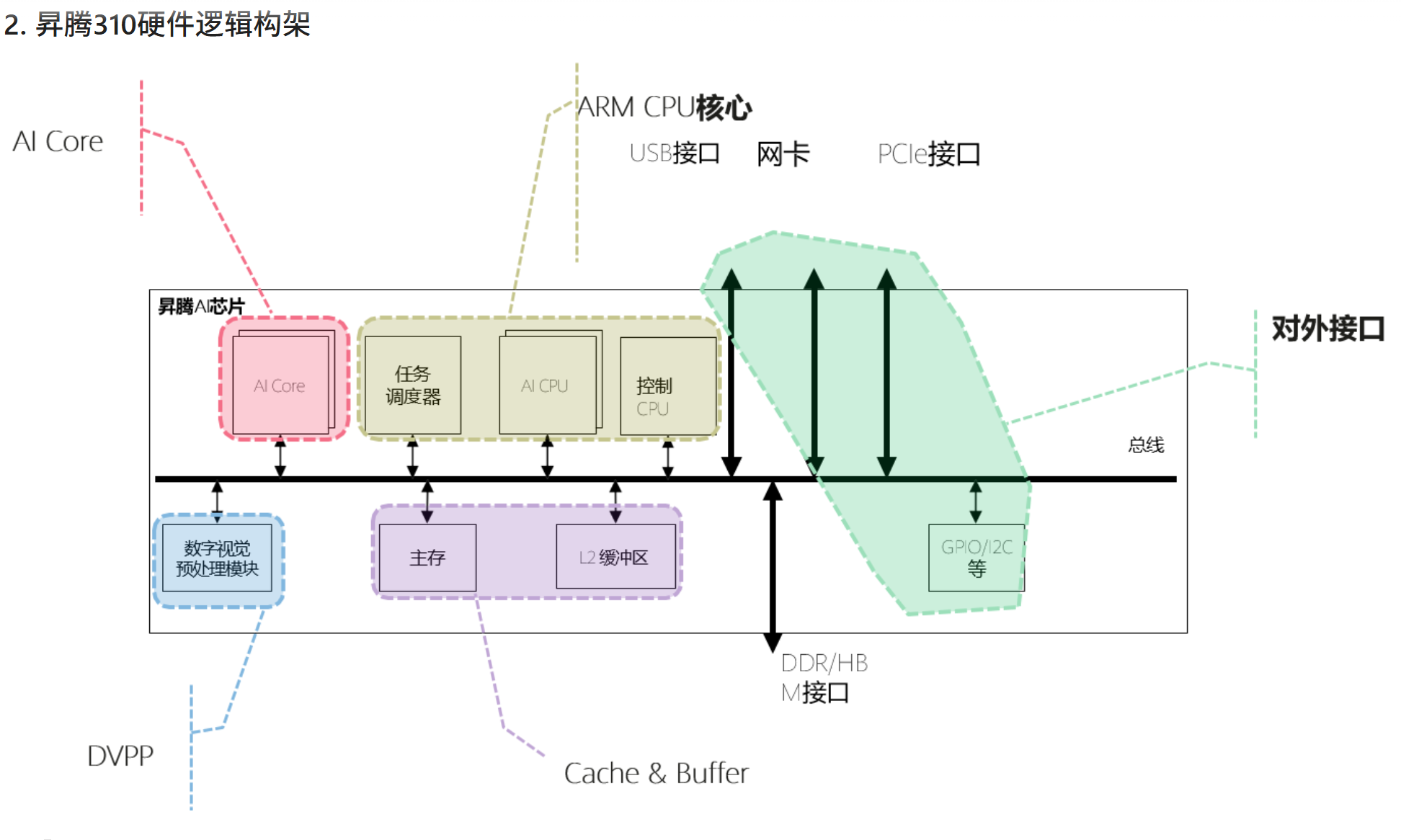
上图展示了昇腾310的硬件逻辑架构图。与昇腾910类似,昇腾310的组成部分包括AI Core、ARM CPU核心、DVPP、Cache & Buffer等。
-
AI Core 是昇腾310的计算核心,负责执行矩阵、向量、标量计算密集的算子任务,采用达芬奇架构。 昇腾 310集成了2个AI Core。
-
ARM CPU核心集成了8个ARM A55。其中一部分部署为AI CPU,负责执行不适合跑在AI Core上的算子(非矩阵类计算),一部分部署为专用于控制芯片整体运行的控制CPU。两类任务占用的 CPU核数可由软件根据系统实际运行情况动态分配。此外,还部署了一个专用CPU作为任务调度器(Task Scheduler,TS),以实现计算任务在AI Core上的高效分配和调度。该CPU专门服务于AI Core和AI CPU,不承担任何其他的事务和工作。
-
对外接口支持PCIE3.0、RGMII、USB3.0等高速接口、以及GPIO、UART、 I2C、SPI等低速接口。
-
DVPP数字视觉预处理子系统,完成图像视频的编解码。用于将从网络或终端设备获得的 视觉数据,进行预处理以实现格式和精度 转换等要求,之后提供给AI计算引擎。
-
Cache & Buffer:SOC片内有层次化的memory结构,AI core内部有两级memory buffer,SOC片上还有8MB L2 buffer,专用于AI Core、AI CPU,提供高带宽、低延迟的memory访 问。芯片还集成了LPDDR4x控制器,为芯片提供更大容量的DDR内存。