当你对着家用机器人说"把杯子放在笔筒和键盘之间,对齐杯身logo"时,它能精准理解空间关系并执行动作;当多台机器人在超市协作补货时,它们能自主规划轨迹、避免冲突并完成长周期任务------这些曾经出现在科幻电影中的场景,正随着RoboBrain 2.0的诞生加速成为现实。
作为新一代具身视觉-语言基础模型,RoboBrain 2.0由北京人工智能研究院(BAAI)团队研发,旨在打破"数字智能"与"物理智能"的鸿沟。这款模型以70亿和320亿参数的两种规格,实现了感知、推理与规划能力的统一,在空间理解、时间决策等核心任务上超越了现有开源与专有模型,为通用具身智能体的发展奠定了里程碑式的基础。

传统视觉语言模型(VLM)在数字世界表现出色,但面对物理环境时往往力不从心:要么无法精准判断物体间的空间关系,要么难以规划多步骤的长期任务,更遑论在动态环境中通过反馈持续优化行为。RoboBrain 2.0针对性解决了这三大瓶颈:
空间理解能力实现跨越式提升。模型能精准预测物体功能(如"杯子的握持部位")、解析复杂空间指向(如"冰箱右侧第二层的牛奶"),甚至生成符合物理规律的放置轨迹。在RoboSpatial机器人环境基准测试中,32B版本以72.43分的成绩大幅领先于Gemini(59.87分)和Qwen2.5-VL(48.33分),展现出对机器人操作场景的深度适配。
时间决策机制支持闭环交互与长程规划。通过分析视频序列中的时序依赖关系,模型能完成"先打开咖啡机再倒入牛奶"这类多步骤任务,甚至在多机器人协作时协调行动顺序。在EgoPlan2日常活动规划基准中,其57.23分的成绩远超GPT-4o(41.79分)和Claude(41.26分),证明了在复杂时序任务中的优势。
因果推理链条让智能行为可解释。不同于直接输出结果的传统模型,RoboBrain 2.0能生成"观察-思考-行动"(OTA)的完整推理过程。例如在"寻找马克杯并倒咖啡"任务中,模型会先规划搜索路径,再根据反馈调整机器操作,最终完成目标,这种透明化的决策过程大幅提升了任务可靠性。
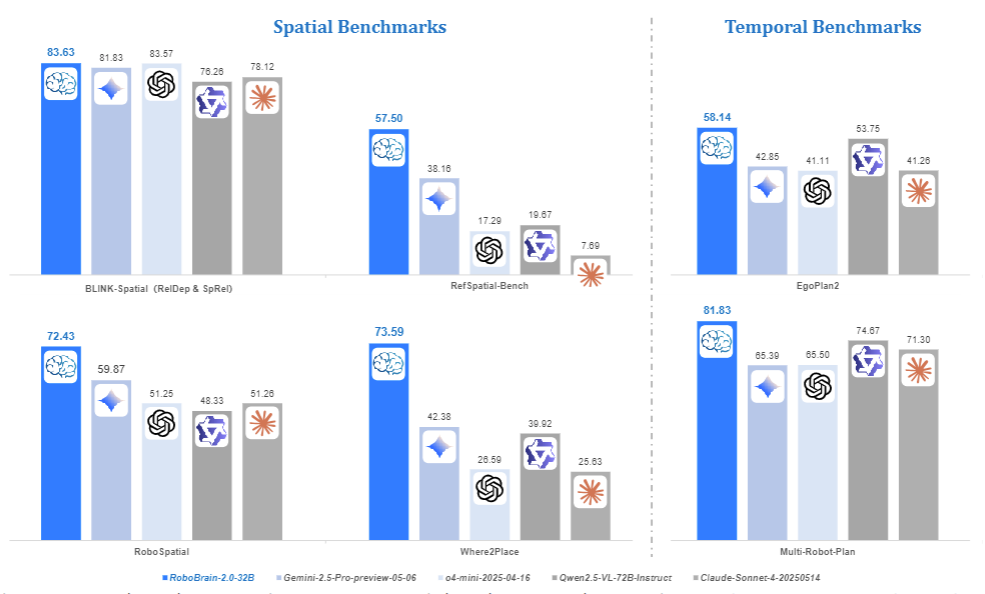
图1 | 几项标准的对比

RoboBrain 2.0的强大能力源于其精心设计的异构架构,通过四大核心组件实现多模态信息的深度融合:
● 视觉编码器:处理高分辨率图像、多视角视频等视觉输入,采用自适应位置编码和窗口注意力机制,高效解析复杂场景的空间特征。
● MLP投影器:将视觉特征精准映射到语言模型的 token 空间,解决跨模态语义对齐难题。
● 语言模型主干:基于Qwen2.5-VL构建的解码器,支持从自然语言指令到空间坐标、轨迹规划等多样化输出。
● 场景图处理器:结构化解析环境中的物体、位置及关系,为推理提供结构化知识支撑。
这种架构设计让模型能同时接收"把红色盒子放在圆桌中心"的语言指令、多摄像头拍摄的厨房画面、以及包含家具位置的场景图数据,通过统一的 token 序列进行联合推理,最终输出精确到像素级的操作坐标。

图2 | 该机器人的能力

RoboBrain 2.0的性能突破离不开大规模高质量数据的支撑。团队构建了涵盖三大类别的训练数据体系,总规模达数百万样本:
通用多模态数据奠定基础能力。整合LLaVA-665K、LRV-400K等数据集,涵盖视觉问答、区域查询、OCR理解等任务,确保模型具备基本的跨模态交互能力。
空间数据强化物理世界感知。包括:
● 152K张高分辨率图像的视觉定位数据,支持精确到 bounding box 的物体定位
● 190K组物体指向样本,训练模型理解"左上角的蓝色杯子"等空间描述
● 826K条3D空间推理数据,涵盖距离、方向等31种空间概念,远超传统数据集的15种
时间数据培养动态决策能力。包含:
● 50K条第一视角规划轨迹,模拟人类日常活动的时序逻辑
● 44K组多机器人协作样本,覆盖家庭、超市、餐厅等场景
● 大规模闭环交互数据,通过模拟随机故障事件,提升模型在动态环境中的鲁棒性
训练过程采用三阶段递进策略:首先通过基础时空学习掌握环境感知能力,再通过具身增强训练适配物理交互场景,最终通过思维链推理训练提升复杂任务的解决能力。这种"从感知到行动"的培养路径,使模型能高效吸收海量数据中的知识。
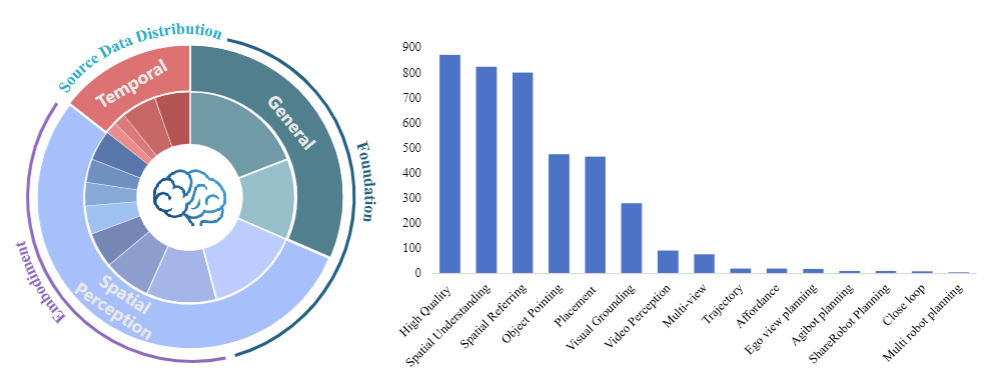
图3 | 训练数据的分布

在12项公开基准测试中,RoboBrain 2.0-32B在6项任务中刷新SOTA(state-of-the-art)成绩,展现出全面的能力优势:
● 空间推理:在BLINK基准的深度感知与空间关系任务中,以83.63分超越GPT-4o(77.90分)和Gemini-2.5(81.83分);在Where2Place物体放置预测任务中,73.59分的成绩是Qwen2.5-VL(39.92分)的1.8倍。
● 时间规划:Multi-Robot-Plan多机器人协作任务中,80.33分大幅领先于Claude(71.30分)和Gemini(65.39分);EgoPlan2日常活动规划中,57.23分显著超越所有对比模型。
● 实际操作:在ShareRobot-Bench的轨迹预测任务中,动态弗雷歇距离(DFD)达到0.2368,远低于Qwen2.5-VL的0.5034,意味着机器人运动轨迹更平滑精准。
值得注意的是,轻量版7B模型在保持紧凑体积的同时,性能仍超越多数开源模型,为资源受限的边缘设备部署提供了可能。这种"大模型保性能、小模型保部署"的双版本策略,大幅降低了具身AI技术的落地门槛。

RoboBrain 2.0的技术突破已展现出广泛的应用前景:
在家庭服务场景中,模型能理解"把阳台的衣服收进衣柜下层"这类包含空间约束的指令,自主规划移动路线并完成操作;在工业协作中,多台机器人可基于模型的规划能力协同完成流水线装配,通过实时更新场景图应对突发状况;在仓储物流中,系统能根据订单需求优化机器人的取货路径,动态调整任务优先级。
更深远的意义在于,团队已开源模型代码、 checkpoint 和基准测试工具(https://superrobobrain.github.io),这将推动整个具身AI领域的发展。正如报告中所言:"我们希望RoboBrain 2.0成为连接视觉-语言智能与物理世界交互的桥梁,为通用具身智能体的研发提供扎实基础。"
未来,随着与Vision-Language-Action(VLA)框架的融合以及机器人操作系统的深度集成,RoboBrain 2.0有望实现"感知-推理-行动"的端到端闭环,让机器人真正理解物理世界的规则,在家庭、工厂、社区中成为可靠的智能助手。
当AI从屏幕走向三维空间,从处理数据转向改造世界,RoboBrain 2.0的出现,或许正是通用人工智能征程上的关键一跃。